Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Pomocí aktivity Tok dat můžete transformovat a přesouvat data prostřednictvím mapování toků dat. Pokud s toky dat začínáte, podívejte se na přehled mapování Tok dat
Vytvoření aktivity Tok dat pomocí uživatelského rozhraní
Pokud chcete v kanálu použít aktivitu Tok dat, proveďte následující kroky:
Vyhledejte Tok dat v podokně Aktivity kanálu a přetáhněte Tok dat aktivitu na plátno kanálu.
Pokud ještě není vybraná, vyberte novou aktivitu Tok dat na plátně a na kartě Nastavení upravte podrobnosti.
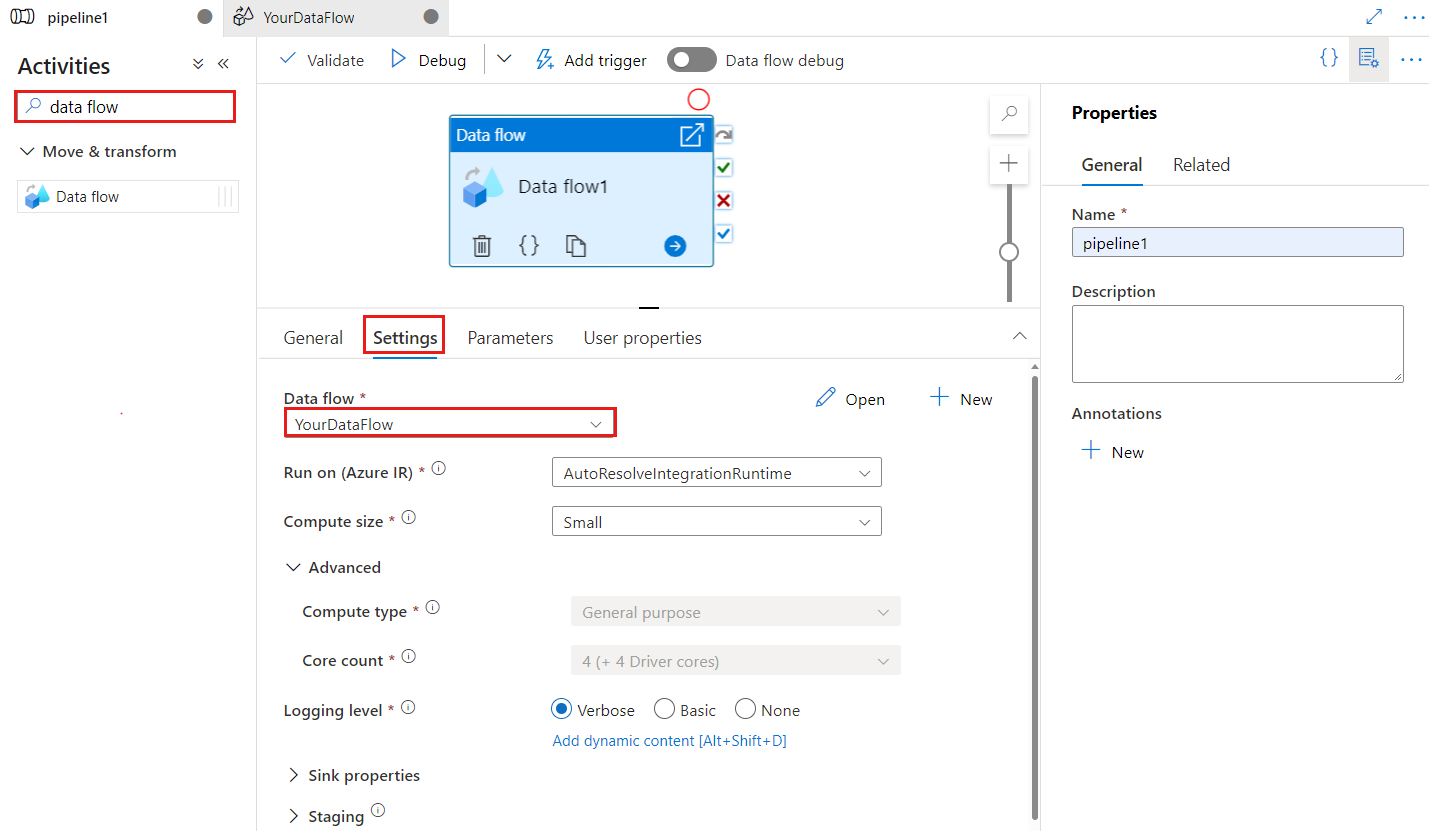
Klíč kontrolního bodu slouží k nastavení kontrolního bodu při použití toku dat ke změně zachytávání dat. Můžete ho přepsat. Aktivity toku dat používají jako klíč kontrolního bodu hodnotu guid místo názvu kanálu + název aktivity, aby bylo možné vždy sledovat stav zachytávání dat změn zákazníka, i když dojde k přejmenování akcí. Všechny stávající aktivity toku dat používají starý klíč vzoru pro zpětnou kompatibilitu. Možnost klíče kontrolního bodu po publikování nové aktivity toku dat s povoleným prostředkem toku dat změn je znázorněna níže.
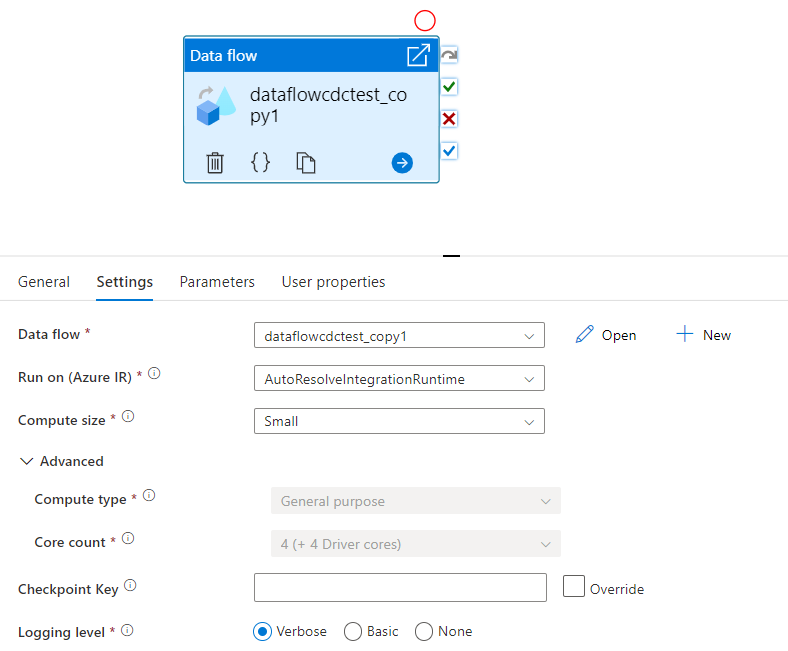
Vyberte existující tok dat nebo vytvořte nový pomocí tlačítka Nový. Vyberte další možnosti podle potřeby pro dokončení konfigurace.
Syntaxe
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Vlastnosti typu
| Vlastnost | Popis | Povolené hodnoty | Požaduje se |
|---|---|---|---|
| Dataflow | Odkaz na spuštěný Tok dat | DataFlowReference | Ano |
| integrationRuntime | Výpočetní prostředí, na kterém tok dat běží. Pokud není zadaný, použije se modul runtime integrace Azure autoresolve. | IntegrationRuntimeReference | No |
| compute.coreCount | Počet jader použitých v clusteru Spark. Je možné zadat pouze v případě, že se používá modul runtime integrace Azure autoresolve. | 8, 16, 32, 48, 80, 144, 272 | No |
| compute.computeType | Typ výpočetních prostředků používaných v clusteru Spark. Je možné zadat pouze v případě, že se používá modul runtime integrace Azure autoresolve. | "Obecné" | No |
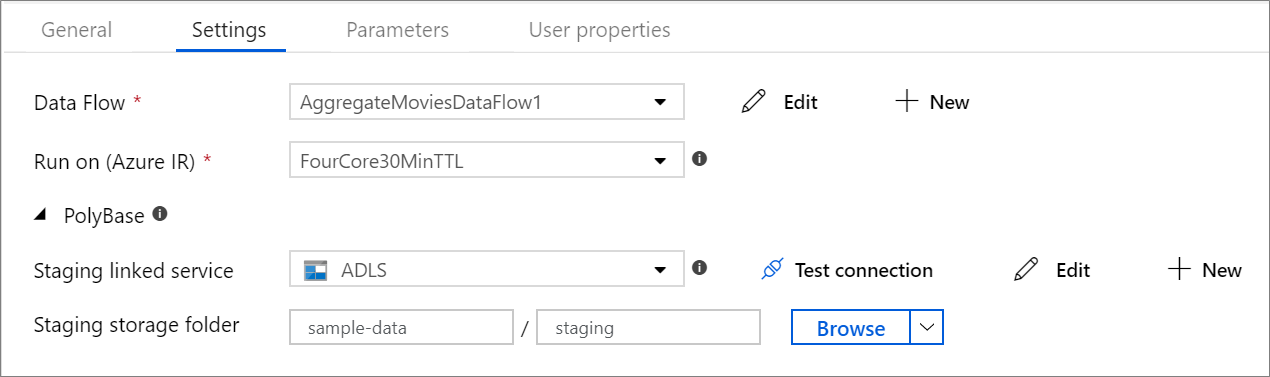
| staging.linkedService | Pokud používáte zdroj nebo jímku Azure Synapse Analytics, zadejte účet úložiště použitý pro přípravu PolyBase. Pokud je služba Azure Storage nakonfigurovaná s koncovým bodem služby virtuální sítě, musíte pro účet úložiště použít ověřování spravované identity s povolenou možností Povolit důvěryhodnou službu Microsoftu, projděte si dopad používání koncových bodů služeb virtuální sítě s úložištěm Azure. Seznamte se také s potřebnými konfiguracemi pro Azure Blob a Azure Data Lake Storage Gen2 . |
LinkedServiceReference | Pouze pokud tok dat čte nebo zapisuje do Azure Synapse Analytics. |
| staging.folderPath | Pokud používáte zdroj nebo jímku Azure Synapse Analytics, cesta ke složce v účtu úložiště objektů blob použitá pro přípravu PolyBase | String | Pouze v případě, že tok dat čte nebo zapisuje do Azure Synapse Analytics |
| traceLevel | Nastavení úrovně protokolování provádění aktivit toku dat | Jemné, Hrubé, Žádné | No |
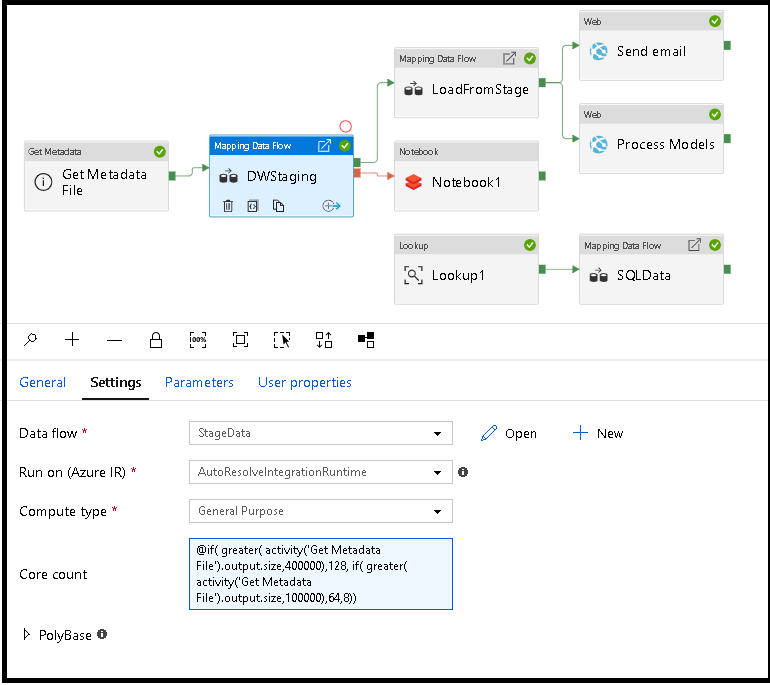
Dynamická velikost výpočetních prostředků toku dat za běhu
Vlastnosti základního počtu a typu výpočetního výkonu je možné dynamicky nastavit tak, aby se přizpůsobily velikosti příchozích zdrojových dat za běhu. K vyhledání velikosti zdrojových dat datové sady použijte aktivity kanálu, jako je vyhledávání nebo získání metadat. Potom ve vlastnostech aktivity Tok dat použijte přidat dynamický obsah. Můžete zvolit malé, střední nebo velké výpočetní velikosti. Volitelně vyberte Vlastní a nakonfigurujte typy výpočetních prostředků a počet jader ručně.
Tady je stručný videokurz vysvětlující tuto techniku.
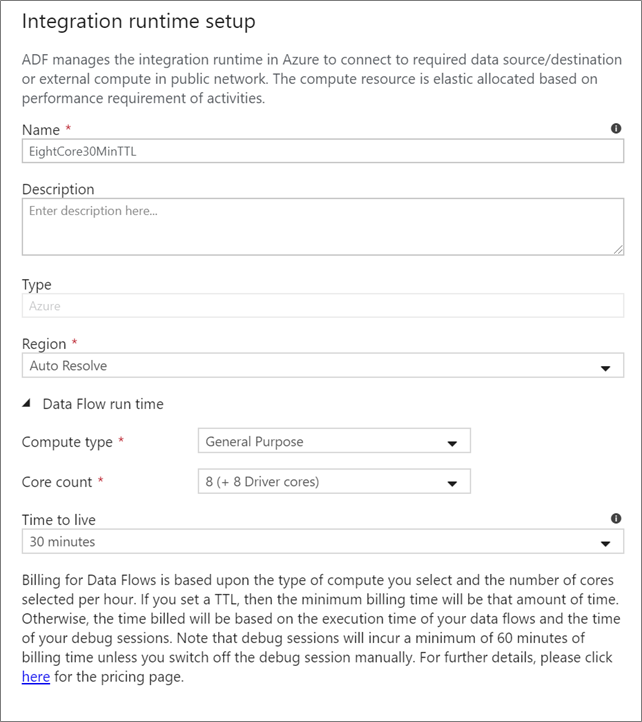
Tok dat Integration Runtime
Vyberte, které prostředí Integration Runtime se má použít pro provádění aktivit Tok dat. Ve výchozím nastavení služba používá modul Azure Integration Runtime s automatickým řešením se čtyřmi pracovními jádry. Toto prostředí IR má typ výpočetního prostředí pro obecné účely a běží ve stejné oblasti jako vaše instance služby. Pro zprovozněné kanály důrazně doporučujeme vytvořit vlastní prostředí Azure Integration Runtime, které definují konkrétní oblasti, typ výpočetních prostředků, počty jader a hodnotu TTL pro provádění aktivit toku dat.
Minimální výpočetní typ pro obecné účely s konfigurací 8+8 (16 celkového počtu virtuálních jader) a 10minutovým typem TTL (Time to Live) je minimální doporučení pro většinu produkčních úloh. Když nastavíte malou hodnotu TTL, azure IR může udržovat teplý cluster, který nebude mít několik minut od spuštění studeného clusteru. Další informace najdete v modulu Azure Integration Runtime.
Důležité
Výběr prostředí Integration Runtime v aktivitě Tok dat se vztahuje pouze na aktivované spuštění kanálu. Ladění kanálu s toky dat běží v clusteru určeném v relaci ladění.
PolyBase
Pokud jako jímku nebo zdroj používáte Azure Synapse Analytics, musíte pro dávkové načtení PolyBase zvolit pracovní umístění. PolyBase umožňuje dávkové načítání hromadně místo načítání datového řádku po řádku. PolyBase výrazně zkracuje dobu načítání do Azure Synapse Analytics.
Klíč kontrolního bodu
Při použití možnosti zachytávání změn pro zdroje toků dat služba ADF udržuje a spravuje kontrolní bod automaticky. Výchozí klíč kontrolního bodu je hodnota hash názvu toku dat a názvu kanálu. Pokud používáte dynamický vzor pro zdrojové tabulky nebo složky, možná budete chtít tuto hodnotu hash přepsat a nastavit tady vlastní hodnotu klíče kontrolního bodu.
Úroveň protokolování
Pokud k úplnému protokolování všech podrobných protokolů telemetrie nevyžadujete každé spuštění kanálu aktivit toku dat, můžete volitelně nastavit úroveň protokolování na Úroveň Základní nebo Žádná. Při provádění toků dat v režimu Podrobné (výchozí) požadujete, aby služba během transformace dat plně protokoluje aktivitu na jednotlivých úrovních oddílů. Může to být náročná operace, takže pouze povolení podrobného řešení potíží může zlepšit celkový tok dat a výkon kanálu. Režim "Základní" protokoluje pouze doby trvání transformace, zatímco hodnota None poskytuje pouze souhrn dob trvání.

Vlastnosti jímky
Funkce seskupení v tocích dat umožňuje nastavit pořadí provádění jímek i seskupit jímky pomocí stejného čísla skupiny. Pokud chcete pomoct se správou skupin, můžete požádat službu, aby spouštěla jímky paralelně ve stejné skupině. Skupinu jímky můžete také nastavit tak, aby pokračovala i po výskytu chyby v jedné z jímek.
Výchozím chováním jímek toku dat je postupné spouštění jednotlivých jímek sériovým způsobem a selhání toku dat v případě, že dojde k chybě v jímce. Kromě toho jsou všechny jímky ve výchozím nastavení stejné skupiny, pokud nezajdete do vlastností toku dat a nenastavíte pro jímky různé priority.

Pouze první řádek
Tato možnost je dostupná jenom pro toky dat, které mají povolené jímky mezipaměti pro "Výstup do aktivity". Výstup toku dat, který se vloží přímo do kanálu, je omezený na 2 MB. Nastavení "pouze prvního řádku" vám pomůže omezit výstup dat z toku dat při vkládání výstupu aktivity toku dat přímo do kanálu.
Parametrizace Tok dat
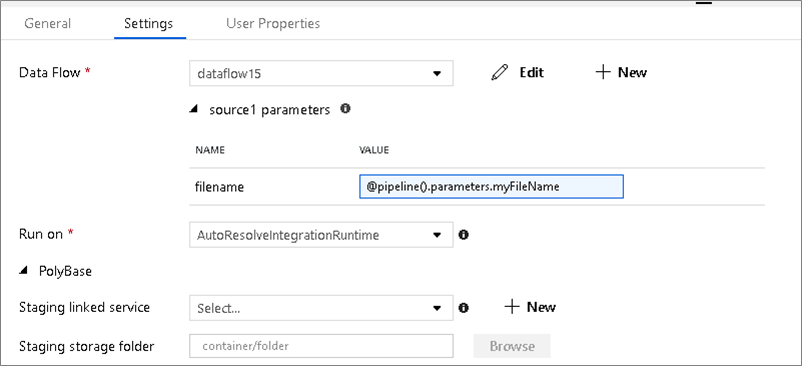
Parametrizované datové sady
Pokud váš tok dat používá parametrizované datové sady, nastavte hodnoty parametrů na kartě Nastavení .
Parametrizované toky dat
Pokud je tok dat parametrizovaný, nastavte dynamické hodnoty parametrů toku dat na kartě Parametry . K přiřazení dynamických nebo literálových hodnot parametrů můžete použít jazyk výrazu kanálu nebo jazyk výrazu toku dat. Další informace najdete v tématu Tok dat Parametry.
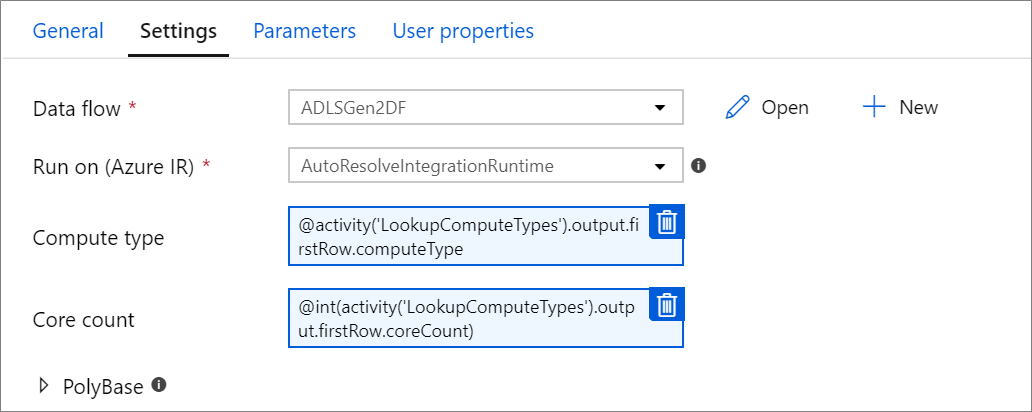
Parametrizované výpočetní vlastnosti
Parametrizovat počet jader nebo typ výpočetních prostředků můžete, pokud použijete modul runtime integrace Azure autoresolve a zadáte hodnoty pro compute.coreCount a compute.computeType.
Ladění kanálu aktivity Tok dat
Pokud chcete spustit spuštění kanálu ladění s aktivitou Tok dat, je nutné zapnout režim ladění toku dat pomocí posuvníku Tok dat Ladění na horním panelu. Režim ladění umožňuje spustit tok dat v aktivním clusteru Spark. Další informace naleznete v tématu Režim ladění.

Kanál ladění běží na aktivním ladicím clusteru, nikoli v prostředí Integration Runtime zadaném v nastavení aktivity Tok dat. Při spouštění režimu ladění můžete zvolit výpočetní prostředí ladění.
Monitorování aktivity Tok dat
Aktivita Tok dat má speciální prostředí pro monitorování, kde můžete zobrazit informace o dělení, fázi a rodokmenu dat. Otevřete podokno monitorování pomocí ikony brýlí v části Akce. Další informace naleznete v tématu Monitorování Tok dat.
Použití Tok dat aktivity vede k následné aktivitě.
Aktivita toku dat vypíše metriky týkající se počtu řádků zapsaných do každé jímky a řádků přečtených z každého zdroje. Tyto výsledky se vrátí v output části výsledku spuštění aktivity. Vrácené metriky jsou ve formátu níže uvedeném kódu JSON.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Pokud například chcete získat počet řádků zapsaných do jímky s názvem sink1 v aktivitě s názvem dataflowActivity, použijte @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Chcete-li získat počet řádků přečtených ze zdroje s názvem "source1", který byl použit v této jímce, použijte @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Poznámka:
Pokud má jímka zapisované nulové řádky, nezobrazí se v metrikách. Existenci lze ověřit pomocí contains funkce. Například zkontroluje, contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') jestli byly do jímky zapsány nějaké řádky.
Související obsah
Projděte si podporované aktivity toku řízení: