Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat přes následné zpracování dat, analýzy v reálném čase, podnikovou inteligenci a reporting. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici v kanálech Azure Data Factory i v kanálech Azure Synapse Analytics. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toků dat.
Transformace Assert umožňuje vytvářet vlastní pravidla uvnitř mapování toků dat pro kvalitu dat a ověření dat. Můžete vytvořit pravidla, která určují, jestli hodnoty splňují očekávanou doménu hodnoty. Kromě toho můžete vytvářet pravidla, která kontrolují jedinečnost řádků. Transformace Assert pomáhá určit, jestli každý řádek v datech splňuje sadu kritérií. Transformace Assert také umožňuje nastavit vlastní chybové zprávy, pokud nejsou splněna pravidla ověření dat.
Konfigurace
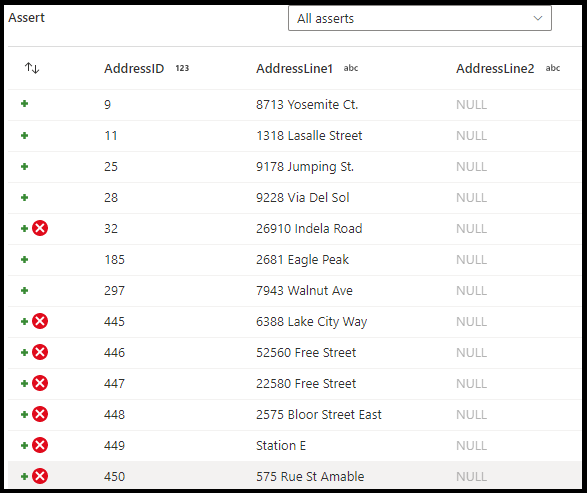
Na konfiguračním panelu transformace assert zvolíte typ asserce, zadáte jedinečný název pro asserci, volitelný popis a definujete výraz i volitelný filtr. Podokno náhledu dat označuje, které řádky nesplnily vaše ověření. Kromě toho můžete otestovat jednotlivé značky řádků níže pomocí isError() a hasError() pro řádky, u kterých došlo k selhání kontrolních výrazů.
Typ assertu
- Očekávejte hodnotu true, která znamená, že výsledek vašeho výrazu musí být vyhodnocen jako logicky pravdivý. Pomocí tohoto nastavení ověřte rozsahy hodnot domény ve vašich datech.
- Očekávejte jedinečnost: Nastavte ve svých datech sloupec nebo výraz jako pravidlo jedinečnosti. Pomocí tohoto nastavení označíte duplicitní řádky.
- Očekává se: Tato možnost je dostupná jenom v případě, že jste vybrali druhý příchozí datový proud. Funkce Exists sleduje oba datové proudy a určí, jestli řádky existují v obou datových proudech na základě sloupců nebo výrazů, které jste zadali. Chcete-li přidat druhý proud pro existující, vyberte
Additional streams.
Selhání toku dat
Vyberte fail data flow, pokud chcete, aby aktivita toku dat okamžitě selhala, jakmile selže asserční pravidlo.
Assert ID
Assert ID je vlastnost, do které zadáte název pro kontrolní výraz (řetězec). Později ve svém toku dat můžete použít identifikátor pomocí hasError() nebo můžete zobrazit kód selhání kontrolního výrazu. Id assert musí být v rámci každého toku dat jedinečná.
Popis assertu
Zadejte popis řetězce pro vaši aserci sem. Tady můžete také použít výrazy a hodnoty sloupců v kontextu řádku.
Filtrovat
Filtr je volitelná vlastnost, ve které můžete filtrovat pouze podmnožinu řádků na základě hodnoty výrazu.
Výraz
Zadejte výraz k vyhodnocení pro každé z vašich tvrzení. Pro každou transformaci asertů můžete mít více asercí. Každý typ kontrolního výrazu vyžaduje výraz, který musí ADF vyhodnotit k otestování, pokud byl kontrolní výraz úspěšný.
Ignorovat NULL hodnoty
Ve výchozím nastavení transformace assert zahrnuje hodnoty NULL ve vyhodnocení kontrolního výrazu řádku. U této vlastnosti můžete ignorovat hodnoty NULLs.
Přímá selhání řádku kontrolního výrazu
Pokud assert selže, můžete tyto chybové řádky volitelně nasměrovat do souboru v Azure pomocí karty Chyby v cílové transformaci. U transformace jímky máte také možnost ignorovat chybové řádky a neodesílat vůbec řádky se selháními kontrolního výrazu.
Příklady
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
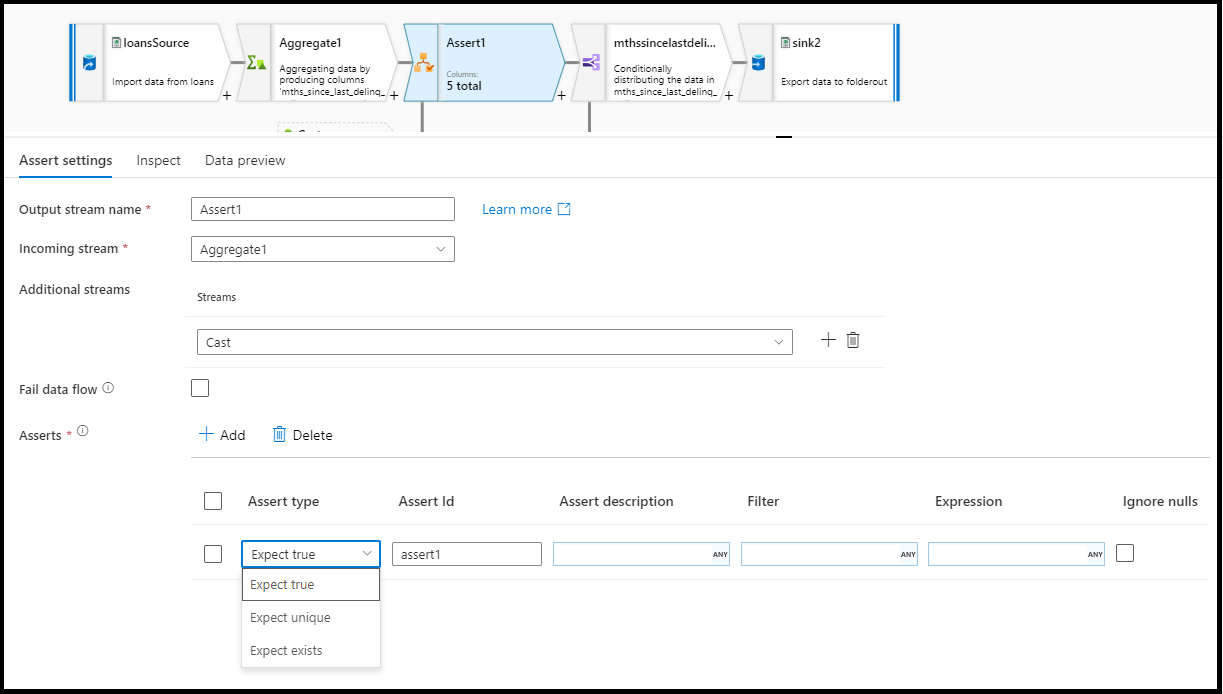
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Skript toku dat
Příklady
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Související obsah
- Použijte transformaci Vybrat k výběru a ověření sloupců.
- Použijte transformaci odvozeného sloupce k transformaci hodnot sloupců.