Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
APPLIES TO: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
Ve světě velkých objemů dat jsou nezpracovaná, neuspořádaná data často uložená v relačních, nerelačních a jiných systémech úložiště. Nezpracovaná data sama o sobě ale nemají potřebný kontext ani význam, aby mohla analytikům, datovým vědcům nebo osobám rozhodujícím v rámci podniků poskytnout smysluplný přehled.
Velké objemy dat vyžadují službu, která dokáže orchestrovat a zprovoznit procesy pro upřesnění těchto obrovských úložišť nezpracovaných dat do použitelných obchodních přehledů. Azure Data Factory je spravovaná cloudová služba vytvořená pro tyto komplexní projekty integrace extrakce a transformace (ETL), extract-load-transform (ELT) a projektů integrace dat.
Funkce Azure Data Factory
Komprese dat: Během aktivita Copy dat je možné komprimovat data a zapsat komprimovaná data do cílového zdroje dat. Tato funkce pomáhá optimalizovat využití šířky pásma při kopírování dat.
Rozsáhlá podpora připojení pro různé zdroje dat: Azure Data Factory poskytuje širokou podporu připojení pro připojení k různým zdrojům dat. To je užitečné, když chcete načíst nebo zapisovat data z různých zdrojů dat.
Vlastní triggery událostí: Azure Data Factory umožňuje automatizovat zpracování dat pomocí vlastních triggerů událostí. Tato funkce umožňuje automaticky provést určitou akci, když dojde k určité události.
Náhled a ověření dat: Během aktivita Copy dat jsou k dispozici nástroje pro zobrazení náhledu a ověřování dat. Tato funkce vám pomůže zajistit, aby se data správně zkopírovala a správně zapisovala do cílového zdroje dat.
Přizpůsobitelné toky dat: Azure Data Factory umožňuje vytvářet přizpůsobitelné toky dat. Tato funkce umožňuje přidat vlastní akce nebo kroky pro zpracování dat.
Integrované zabezpečení: Azure Data Factory nabízí integrované funkce zabezpečení, jako je integrace Entra ID a řízení přístupu na základě role pro řízení přístupu k tokům dat. Tato funkce zvyšuje zabezpečení při zpracování dat a chrání vaše data.
Scénáře použití
Představte si například herní společnost, která shromažďuje petabajty herních protokolů vytvářených hrami v cloudu. Společnost chce tyto protokoly analyzovat, aby získala informace o preferencích zákazníků, demografických ukazatelích a chování uživatelů. Zároveň chce identifikovat příležitosti křížového a následného prodeje, vyvíjet nové, zajímavé funkce, podpořit obchodní růst a zlepšovat zkušenosti zákazníků.
Aby společnost mohla tyto protokoly analyzovat, potřebuje použít referenční data, jako jsou informace o zákaznících, hrách a marketingových kampaních, které jsou uložené v místním úložišti dat. Společnost chce využít tato data z místního úložiště dat a zkombinovat je s dalšími daty protokolů, která má uložená v cloudovém úložišti dat.
Aby extrahovali přehledy, plánují zpracovat propojená data pomocí clusteru Spark v cloudu (Azure HDInsight) a publikovat transformovaná data do cloudového datového skladu, jako je Azure Synapse Analytics, k tomu, aby bylo snadné na něm sestavit report. Chce tento pracovní postup automatizovat a monitorovat a spravovat ho podle denního plánu. Chtějí ho také spustit, když soubory dorazí do kontejneru úložiště typu blob.
Azure Data Factory je platforma, která řeší takové datové scénáře. Jedná se o cloudovou službu ETL a integraci dat, která umožňuje vytvářet pracovní postupy řízené daty pro orchestraci přesunu dat a transformaci dat ve velkém měřítku. Pomocí Azure Data Factory můžete vytvářet a plánovat pracovní postupy řízené daty (označované jako kanály), které ingestují data z různorodých úložišť dat. Můžete vytvářet složité procesy ETL, které vizuálně transformují data pomocí toků dat nebo pomocí výpočetních služeb, jako jsou Azure HDInsight Hadoop, Azure Databricks a Azure SQL Database.
Kromě toho můžete publikovat svá transformovaná data do úložišť dat, jako je Azure Synapse Analytics, aby je mohly aplikace business intelligence (BI) využívat. Díky Azure Data Factory můžou být nezpracovaná data uspořádaná do smysluplných úložišť dat a datových jezer pro lepší obchodní rozhodnutí.
Jak to funguje?
Data Factory obsahuje řadu vzájemně propojených systémů, které poskytují kompletní platformu pro datové techniky.

Tento vizuální průvodce poskytuje podrobný přehled kompletní architektury služby Data Factory:

Pokud chcete zobrazit další podrobnosti, vyberte předchozí obrázek, který chcete přiblížit, nebo přejděte na obrázek s vysokým rozlišením. Tady se dozvíte o vývoji tohoto vizuálního průvodce a skici projektu dokumentace.
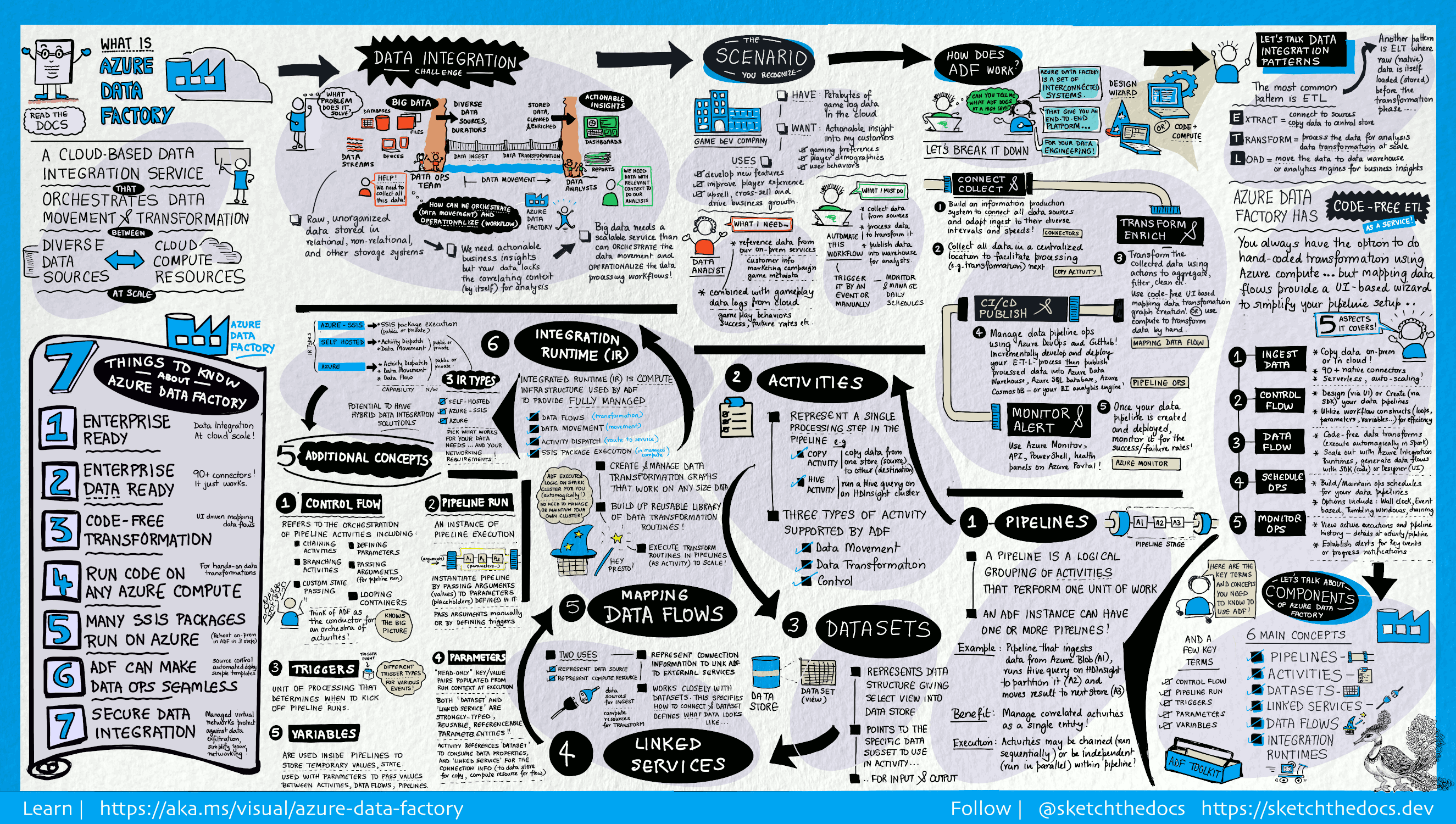{kind=link}
Připojte se a sbírejte
Podniky mají data různých typů, která jsou uložená v různorodých místních zdrojích nebo v cloudu, a data strukturovaná, nestrukturovaná i částečně strukturovaná, která přicházejí v různých intervalech a různou rychlostí.
Prvním krokem při sestavování systému vytváření informací je připojení ke všem požadovaným zdrojům dat a zpracování, jako jsou například služby typu software jako služba (SaaS), databáze, sdílené složky a webové služby FTP. Dalším krokem je přesun dat podle potřeby do centralizovaného umístění pro následné zpracování.
Bez služby Data Factory musí podniky sestavovat vlastní komponenty pro přesun dat nebo vyvíjet vlastní služby pro integraci a zpracování těchto zdrojů dat. Integrace a údržba takových systémů je nákladná a složitá. Kromě toho často postrádají monitorování a upozorňování na podnikové úrovni a ovládací prvky, které může nabídnout plně spravovaná služba.
Se službou Data Factory můžete pomocí aktivity kopírování v datovém kanálu přesouvat data z místních i cloudových úložišť dat do centralizovaného úložiště v cloudu pro účely další analýzy. Data můžete například shromažďovat v Azure Data Lake Storage a později je transformovat pomocí Azure Data Lake Analytics výpočetní služby. Data můžete také shromažďovat v úložišti objektů blob Azure a později je transformovat pomocí clusteru Azure HDInsight Hadoop.
Transformace a rozšíření
Jakmile se data nacházejí v centralizovaném úložišti dat v cloudu, zpracujte nebo transformujte shromážděná data pomocí toků dat mapování ADF. Toky dat umožňují datovým inženýrům vytvářet a udržovat grafy transformace dat, které se spouštějí ve Sparku, aniž by museli rozumět clusterům Spark nebo programování Sparku.
Pokud dáváte přednost transformacím kódu ručně, ADF podporuje externí aktivity pro provádění transformací ve výpočetních službách, jako je HDInsight Hadoop, Spark, Data Lake Analytics a Machine Learning.
CI/CD a publikování
Data Factory nabízí plnou podporu CI/CD datových kanálů pomocí Azure DevOps a GitHub. To vám umožní postupně vyvíjet a dodávat procesy ETL před publikováním hotového produktu. Po upřesnění nezpracovaných dat do formy připravené k použití v podnikání načtěte data do Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB nebo do kteréhokoli analytického nástroje, na které mohou firemní uživatelé přistupovat pomocí svých nástrojů business intelligence.
Monitor
Jakmile úspěšně sestavíte a nasadíte kanál integrace dat, který ze zpracovaných dat získává obchodní hodnotu, můžete monitorovat naplánované aktivity a kanály a jejich míru úspěšnosti a chyb. Azure Data Factory má integrovanou podporu monitorování kanálů prostřednictvím Azure Monitor, rozhraní API, PowerShellu, protokolů Azure Monitor a panelů stavu na portálu Azure.
Koncepty nejvyšší úrovně
Předplatné Azure může mít jednu nebo více Azure Data Factory instancí (nebo datových továren). Azure Data Factory se skládá z následujících klíčových komponent:
- Pipelines
- Aktivity
- Datové sady
- Propojené služby
- Přenosy dat
- Integrační runtime
Tyto součásti společně poskytují platformu, na které můžete vytvářet pracovní postupy řízené daty s kroky pro přesun a transformaci dat.
Kanál
Datová továrna může mít jeden nebo více pipelines. Pipelina je logické seskupení aktivit, které provádí jednotku práce. Aktivity v potrubí společně vykonávají úkol. Kanál může například obsahovat skupinu aktivit, které ingestují data z objektu blob Azure, a pak spustí dotaz Hive v clusteru HDInsight, aby se data rozdělila.
Výhodou tohoto přístupu je, že vám potrubí umožňuje spravovat aktivity jako sadu, a ne každou zvlášť. Aktivity v kanálu je možné zřetězit, aby probíhaly postupně, nebo můžou probíhat souběžně a nezávisle na sobě.
Mapování toků dat
Vytvářejte a spravujte grafy logiky transformace dat, které můžete použít k transformaci libovolných velikostí dat. Z kanálů ADF můžete vytvořit opakovaně použitelnou knihovnu rutin transformace dat a spouštět tyto procesy škálovaným způsobem. Data Factory spustí vaši logiku na clusteru Spark, který se v případě potřeby spouští a vypíná. Clustery nebudete muset spravovat ani udržovat.
Aktivita
Aktivity představují krok zpracování v rámci zpracovatelského řetězce. Například můžete použít aktivitu kopírování ke kopírování dat z jednoho úložiště dat do jiného. Podobně můžete k transformaci nebo analýze dat použít aktivitu Hive, která spouští dotaz Hive na clusteru Azure HDInsight. Data Factory podporuje tři typy aktivit: aktivity přesunu dat, aktivity transformace dat a aktivity řízení.
Datové sady
Datové sady představují datové struktury v rámci úložišť dat, které jednoduše odkazují na data, která chcete ve svých aktivitách použít jako vstupy nebo výstupy.
Propojené služby
Propojené služby jsou velmi podobné připojovacím řetězcům, které definují informace o připojení, které služba Data Factory potřebuje pro připojení k externím prostředkům. Můžete si to představit tak, že propojená služba definuje připojení ke zdroji dat a datová sada představuje strukturu těchto dat. Například propojená služba Azure Storage určuje připojovací řetězec pro připojení k účtu Azure Storage. Kromě toho datová sada objektů blob Azure určuje kontejner objektů blob a složku, která obsahuje data.
Propojené služby slouží ve službě Data Factory ke dvěma účelům:
Pro reprezentaci úložiště dat , které zahrnuje, ale není omezeno na SQL Server databázi, databázi Oracle, sdílenou složku nebo účet úložiště Azure Blob. Seznam podporovaných úložišť dat najdete v článku o aktivitě kopírování.
Představují výpočetní prostředek, který může hostovat provádění aktivity. Například aktivita HDInsightHive se spouští na clusteru HDInsight Hadoop. Seznam aktivit transformace a podporovaných výpočetních prostředí najdete v článku o transformaci dat.
Integration Runtime
Aktivita ve službě Data Factory určuje akci, která se má provést. Propojená služba určuje cílové úložiště dat nebo výpočetní službu. Prostředí Integration Runtime poskytuje most mezi aktivitou a propojenými službami. Odkazuje na ni propojená služba nebo aktivita a poskytuje výpočetní prostředí, ve kterém se aktivita spouští nebo odesílá. Tímto způsobem se dá aktivita co nejefektivněji provést v oblasti, která je nejblíž cílovému úložišti dat nebo výpočetní službě, a zároveň vyhovět potřebám zabezpečení a dodržování předpisů.
Spouštěče
Triggery představují jednotku zpracování, která určuje, kdy je potřeba spustit spuštění kanálu. Pro různé typy událostí existují různé typy aktivačních událostí.
Běhy pipeliny
Spuštění kanálu je instance spuštění kanálu. Běhy kanálu se obvykle vytvářejí předáním parametrům argumentů, které jsou definovány v kanálech. Argumenty je možné předat ručně nebo v rámci definice aktivační události.
Parametry
Parametry jsou páry klíčů a hodnot určené pouze ke čtení. Parametry jsou definovány v potrubí. Argumenty definovaných parametrů se předávají během provádění z kontextu spuštění vytvořeného spouštěčem nebo pipelinem, který byl spuštěn ručně. Aktivity v rámci kanálu spotřebovávají hodnoty parametrů.
Datová sada je parametr silného typu a opakovaně použitelná/odkazovatelná entita. Aktivita může odkazovat na datové sady a může využívat vlastnosti definované v definici datové sady.
Propojená služba je také parametr silného typu, který obsahuje informace o připojení k úložišti dat nebo výpočetnímu prostředí. Je to také opakovaně použitelná/odkazovatelná entita.
Řízení toku
Tok řízení představuje orchestraci aktivit kanálu, která zahrnuje zřetězení aktivit v sekvenci, větvení, definování parametrů na úrovni kanálu a předávání argumentů při volání kanálu na vyžádání nebo z aktivační události. Zahrnuje také předávání stavů na míru a kontejnery pro cykly, tedy iterátory typu For-each.
Proměnné
Proměnné se dají použít uvnitř kanálů k ukládání dočasných hodnot a dají se použít také ve spojení s parametry, které umožňují předávání hodnot mezi kanály, toky dat a dalšími aktivitami.
Související obsah
Tady jsou důležité další dokumenty, které je potřeba prozkoumat: