Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datovou vědu, analýzy v reálném čase, podnikovou inteligenci a reportování. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, co jsou datové sady, jak jsou definované ve formátu JSON a jak se používají v kanálech Azure Data Factory a Synapse.
Pokud se službou Data Factory začínáte, přehled najdete v tématu Úvod do služby Azure Data Factory . Další informace o Azure Synapse najdete v tématu Co je Azure Synapse.
Přehled
Pracovní prostor Azure Data Factory nebo Synapse může mít jeden nebo více kanálů. Pipeline je logické uspořádáníaktivit, které společně provádějí úlohu. Aktivity v procesu definují akce, které se mají s daty provádět. Nyní je datová množina pojmenovaným zobrazením dat, které jednoduše odkazuje na data, jež chcete použít ve svých aktivitách jako vstupy a výstupy. Datové sady identifikují data v rámci různých úložišť dat, jako jsou tabulky, soubory, složky a dokumenty. Datová sada objektů blob Azure například určuje kontejner objektů blob a složku ve službě Blob Storage, ze které by aktivita měla číst data.
Než vytvoříte datovou sadu, musíte vytvořit propojenou službu , která propojí vaše úložiště dat se službou. Propojené služby jsou podobně jako připojovací řetězec, které definují informace o připojení potřebné pro připojení služby k externím prostředkům. Myslete na to tímto způsobem; datová sada představuje strukturu dat v rámci propojených úložišť dat a propojená služba definuje připojení ke zdroji dat. Například propojená služba Azure Storage propojuje účet úložiště. Datová sada Azure Blob představuje kontejner objektů blob a složku v rámci účtu služby Azure Storage, který obsahuje vstupní objekty blob, které se mají zpracovat.
Tady je ukázkový scénář. Pokud chcete kopírovat data z úložiště objektů blob do služby SQL Database, vytvoříte dvě propojené služby: Azure Blob Storage a Azure SQL Database. Pak vytvořte dvě datové sady: datovou sadu s oddělovači (která odkazuje na propojenou službu Azure Blob Storage za předpokladu, že máte textové soubory jako zdroj) a datovou sadu tabulky Azure SQL (která odkazuje na propojenou službu Azure SQL Database). Propojené služby Azure Blob Storage a Azure SQL Database obsahují připojovací řetězec, které služba používá za běhu pro připojení k azure Storage a Azure SQL Database. Datová sada s odděleným textem určuje blob kontejner a blob složku, která obsahuje vstupní objekty blob ve službě Blob Storage, spolu s nastavením souvisejícím s formátem. Datová sada tabulky Azure SQL určuje tabulku SQL ve službě SQL Database, do které se mají data zkopírovat.
Následující diagram znázorňuje vztahy mezi kanálem, aktivitou, datovou sadou a propojenými službami:
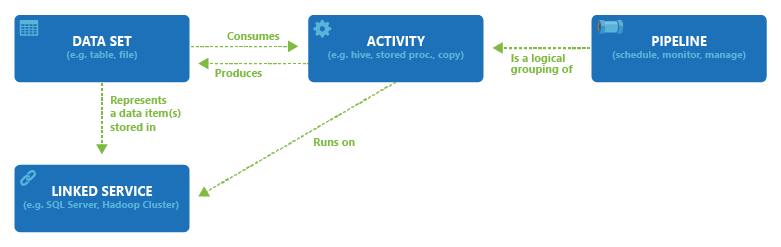
Vytvoření datové sady s uživatelským rozhraním
Pokud chcete vytvořit datovou sadu pomocí nástroje Azure Data Factory Studio, vyberte kartu Autor (s ikonou tužky) a pak ikonu znaménka plus a zvolte Datová sada.

Zobrazí se okno nové datové sady pro výběr libovolného konektoru dostupného ve službě Azure Data Factory pro nastavení existující nebo nové propojené služby.

Dále se zobrazí výzva k výběru formátu datové sady.

Nakonec můžete zvolit existující propojenou službu typu, který jste vybrali pro datovou sadu, nebo vytvořit novou, pokud ještě není definovaná.

Jakmile datovou sadu vytvoříte, můžete ji použít v libovolném kanálu ve službě Azure Data Factory.


Datová sada JSON
Datová sada je definována v následujícím formátu JSON:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
Následující tabulka popisuje vlastnosti ve výše uvedeném formátu JSON:
| Vlastnost | Popis | Povinné |
|---|---|---|
| jméno | Název datové sady Viz pravidla pojmenování. | Ano |
| typ | Typ datové sady Zadejte jeden z typů podporovaných službou Data Factory (například: DelimitedText, AzureSqlTable). Podrobnosti najdete v tématu Typy datových sad. |
Ano |
| schéma | Schéma datové sady představuje fyzický datový typ a tvar. | Ne |
| typVlastnosti | Vlastnosti typu se pro každý typ liší. Podrobnosti o podporovaných typech a jejich vlastnostech najdete v tématu Typ datové sady. | Ano |
Při importu schématu datové sady vyberte tlačítko Importovat schéma a zvolte import ze zdroje nebo z místního souboru. Ve většině případů schéma naimportujete přímo ze zdroje. Pokud ale už máte soubor místního schématu (soubor Parquet nebo CSV s hlavičkami), můžete službu nasměrovat tak, aby založil schéma na daném souboru.
V aktivitě kopírování se datové sady používají ve zdroji a cílovém úložišti. Schéma definované v datové sadě je volitelné jako odkaz. Pokud chcete použít mapování sloupců a polí mezi zdrojem a jímkou, projděte si mapování schématu a typu.
V toku dat se datové sady používají v transformacích zdroje a zásobníku. Datové sady definují základní schémata dat. Pokud data nemají žádné schéma, můžete pro zdroj a jímku použít posun schématu. Metadata z datových sad se zobrazí ve zdrojové transformaci jako zdrojová projekce. Projekce ve zdrojové transformaci představuje tok dat s definovanými názvy a typy.
Typ datové sady
Služba podporuje mnoho různých typů datových sad v závislosti na úložištích dat, která používáte. Seznam podporovaných úložišť dat najdete v článku s přehledem konektoru. Výběrem úložiště dat se dozvíte, jak pro ni vytvořit propojenou službu a datovou sadu.
Například u datové sady typu Text s oddělovači je typ datové sady nastaven na DelimitedText, jak je znázorněno v následující ukázce JSON:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Poznámka:
Hodnota schématu je definována pomocí syntaxe JSON. Podrobnější informace o mapování schématu a mapování datových typů najdete v dokumentaci ke schématu aktivity kopírování a mapování typů ve službě Azure Data Factory.
Vytvoření datových sad
Datové sady můžete vytvářet pomocí jednoho z těchto nástrojů nebo sad SDK: .NET API, PowerShell, REST API, šablony Azure Resource Manageru a webu Azure Portal.
Aktuální verze vs. verze 1 – datové sady
Tady jsou některé rozdíly mezi datovými sadami v aktuální verzi služby Data Factory (a Azure Synapse) a starší verzí služby Data Factory verze 1:
- V aktuální verzi není externí vlastnost podporovaná. Nahrazuje ji aktivační událost.
- Vlastnosti zásad a dostupnosti nejsou v aktuální verzi podporované. Čas spuštění kanálu závisí na aktivačních událostech.
- V aktuální verzi nejsou podporovány datové sady definované s vymezeným oborem (datové sady definované v procesním toku).
Související obsah
Rychlý úvod
Podrobné pokyny k vytváření kanálů a datových sad pomocí některého z těchto nástrojů nebo sad SDK najdete v následujícím kurzu.
- Rychlý start: Vytvoření datové továrny pomocí rozhraní .NET
- Rychlý start: Vytvoření datové továrny pomocí PowerShellu
- Rychlý start: Vytvoření datové továrny pomocí rozhraní REST API
- Rychlý start: Vytvoření datové továrny pomocí webu Azure Portal