Transformace se službou Azure Databricks
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
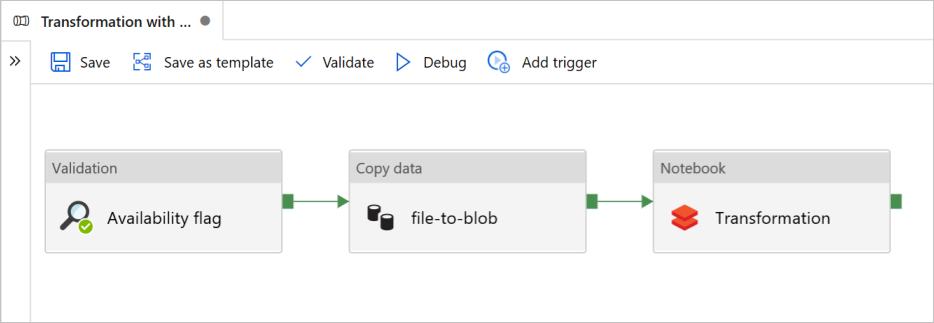
V tomto kurzu vytvoříte ucelený kanál, který obsahuje aktivity ověřování, kopírování dat a poznámkových bloků ve službě Azure Data Factory.
Ověření zajišťuje, že zdrojová datová sada je připravená pro příjem dat před aktivací úlohy kopírování a analýzy.
Kopírování dat duplikuje zdrojovou datovou sadu do úložiště jímky, která je připojená jako DBFS v poznámkovém bloku Azure Databricks. Tímto způsobem může datová sada přímo využívat Spark.
Poznámkový blok Aktivuje poznámkový blok Databricks, který transformuje datovou sadu. Přidá také datovou sadu do zpracované složky nebo azure Synapse Analytics.
Pro zjednodušení šablona v tomto kurzu nevytvoří naplánovanou aktivační událost. V případě potřeby ho můžete přidat.
Požadavky
Účet služby Azure Blob Storage s kontejnerem, který se volá
sinkdatajako jímka.Poznamenejte si název účtu úložiště, název kontejneru a přístupový klíč. Tyto hodnoty budete potřebovat později v šabloně.
Pracovní prostor Azure Databricks
Import poznámkového bloku pro transformaci
Import poznámkového bloku transformace do pracovního prostoru Databricks:
Přihlaste se ke svému pracovnímu prostoru Azure Databricks a pak vyberte Importovat.
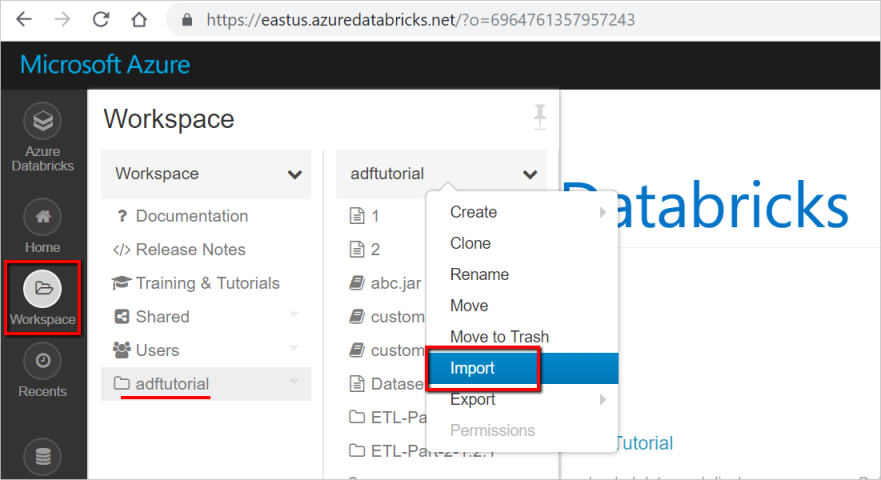 Cesta k vašemu pracovnímu prostoru se může lišit od zobrazené cesty, ale zapamatujte si ji pro pozdější použití.
Cesta k vašemu pracovnímu prostoru se může lišit od zobrazené cesty, ale zapamatujte si ji pro pozdější použití.Vyberte Importovat z adresy URL. Do textového pole zadejte
https://adflabstaging1.blob.core.windows.net/share/Transformations.html.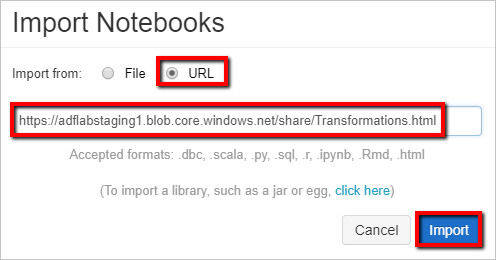
Teď aktualizujeme poznámkový blok transformace informacemi o připojení k úložišti.
V importovaném poznámkovém bloku přejděte na příkaz 5 , jak je znázorněno v následujícím fragmentu kódu.
- Nahraďte
<storage name>a<access key>nahraďte vlastními informacemi o připojení k úložišti. - Použijte účet úložiště s kontejnerem
sinkdata.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Nahraďte
Vygenerujte přístupový token Databricks pro službu Data Factory pro přístup k Databricks.
- V pracovním prostoru Databricks vyberte ikonu profilu uživatele v pravém horním rohu.
- Vyberte Uživatelská nastavení.
- Na kartě Přístupové tokeny vyberte Vygenerovat nový token.
- Vyberte Generovat.

Uložte přístupový token pro pozdější použití při vytváření propojené služby Databricks. Přístupový token vypadá nějak takto
dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Jak používat tuto šablonu
Přejděte k transformaci pomocí šablony Azure Databricks a vytvořte nové propojené služby pro následující připojení.
Připojení ke zdrojovému objektu blob – pro přístup ke zdrojovým datům.
V tomto cvičení můžete použít veřejné úložiště objektů blob, které obsahuje zdrojové soubory. Pro konfiguraci použijte následující snímek obrazovky. Pomocí následující adresy URL SAS se připojte ke zdrojovému úložišti (přístup jen pro čtení):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D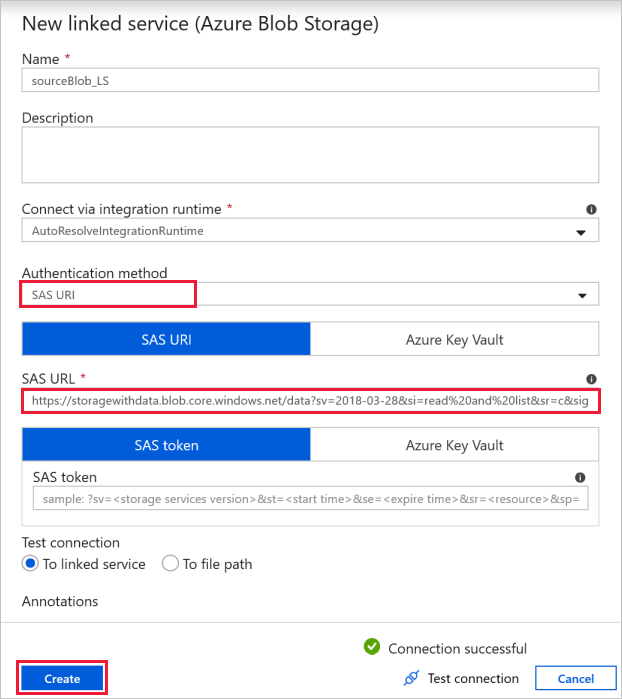
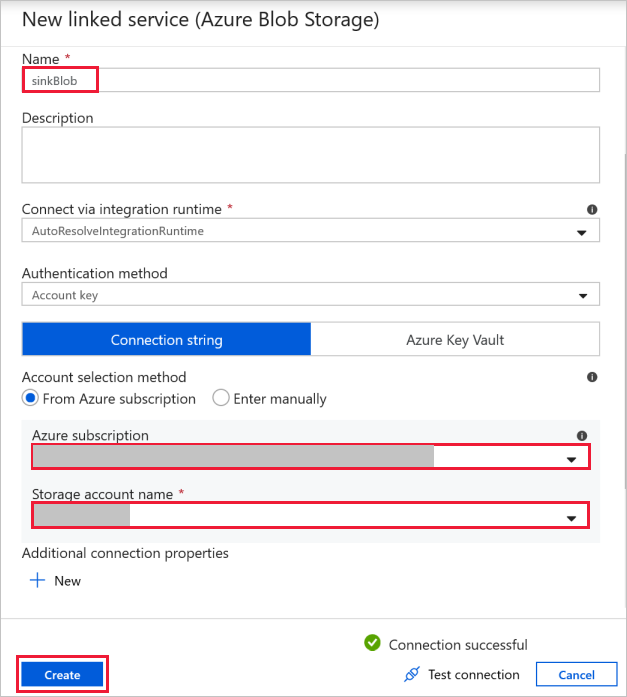
Cílové připojení objektu blob – pro uložení zkopírovaných dat.
V okně Nová propojená služba vyberte objekt blob úložiště jímky.
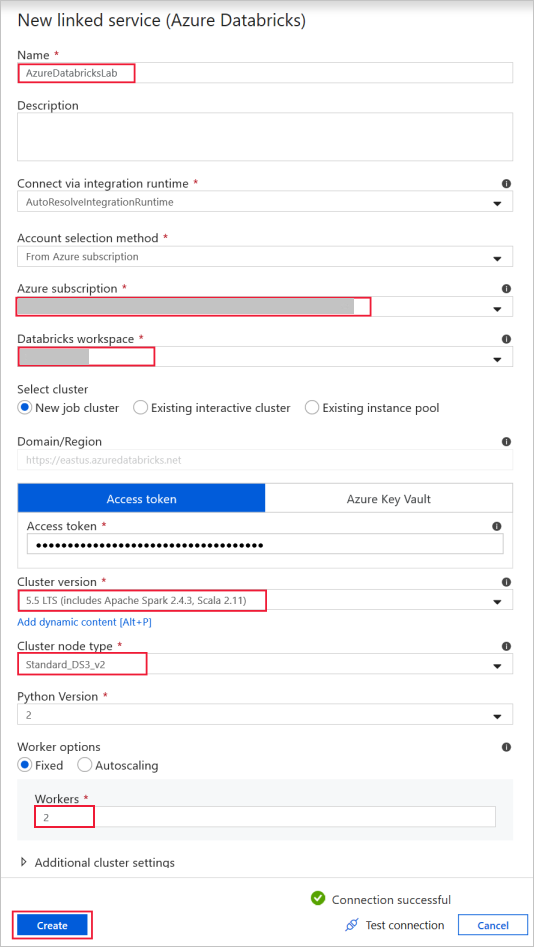
Azure Databricks – připojení ke clusteru Databricks
Vytvořte službu propojenou službou Databricks pomocí přístupového klíče, který jste vygenerovali dříve. Pokud ho máte, můžete zvolit interaktivní cluster . Tento příklad používá možnost Nový cluster úloh.
Vyberte Použít tuto šablonu. Zobrazí se vytvořený kanál.
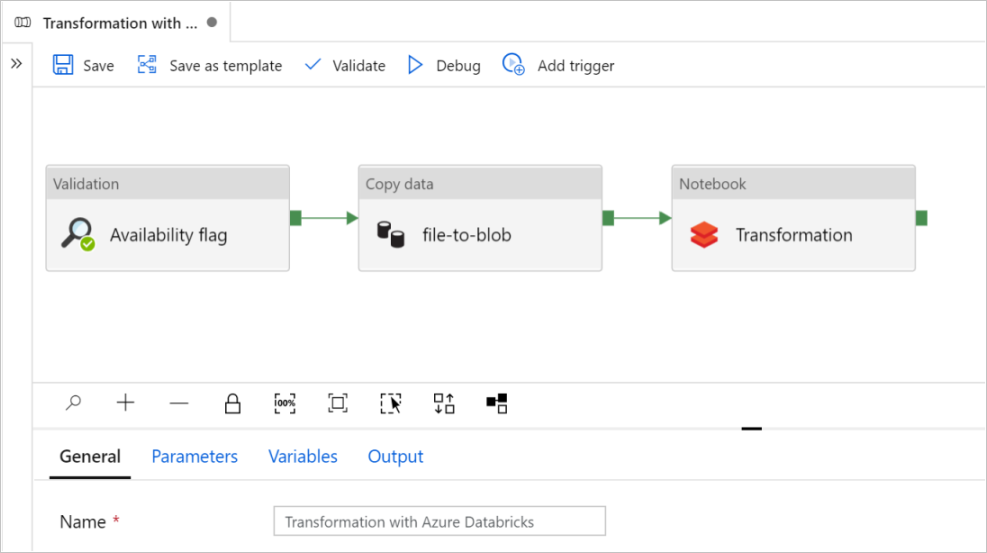
Úvod a konfigurace kanálu
V novém kanálu se většina nastavení konfiguruje automaticky s výchozími hodnotami. Zkontrolujte konfigurace kanálu a proveďte potřebné změny.
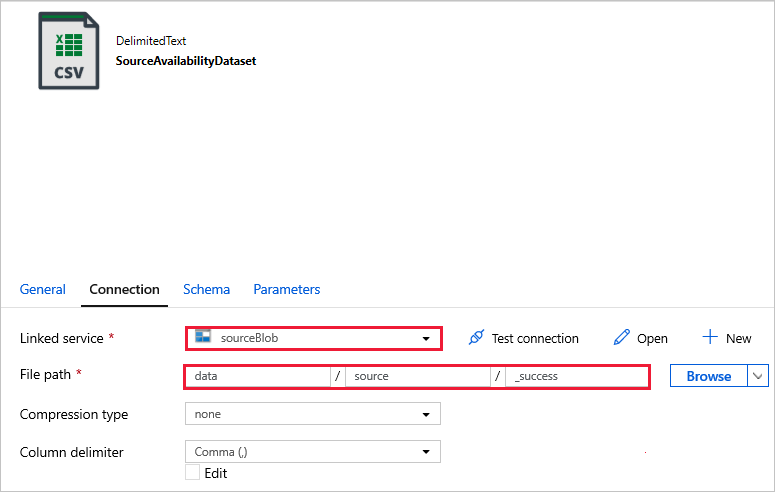
V příznaku Dostupnost aktivity ověření ověřte, že je zdrojová hodnota datové sady nastavená na
SourceAvailabilityDatasetdříve vytvořenou hodnotu.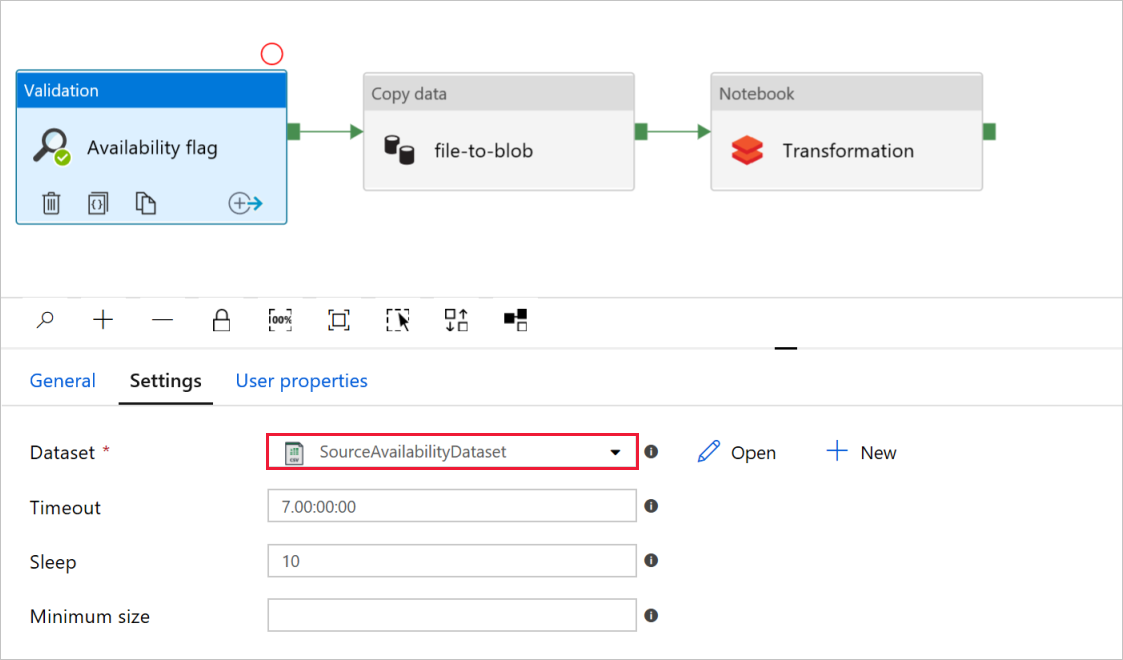
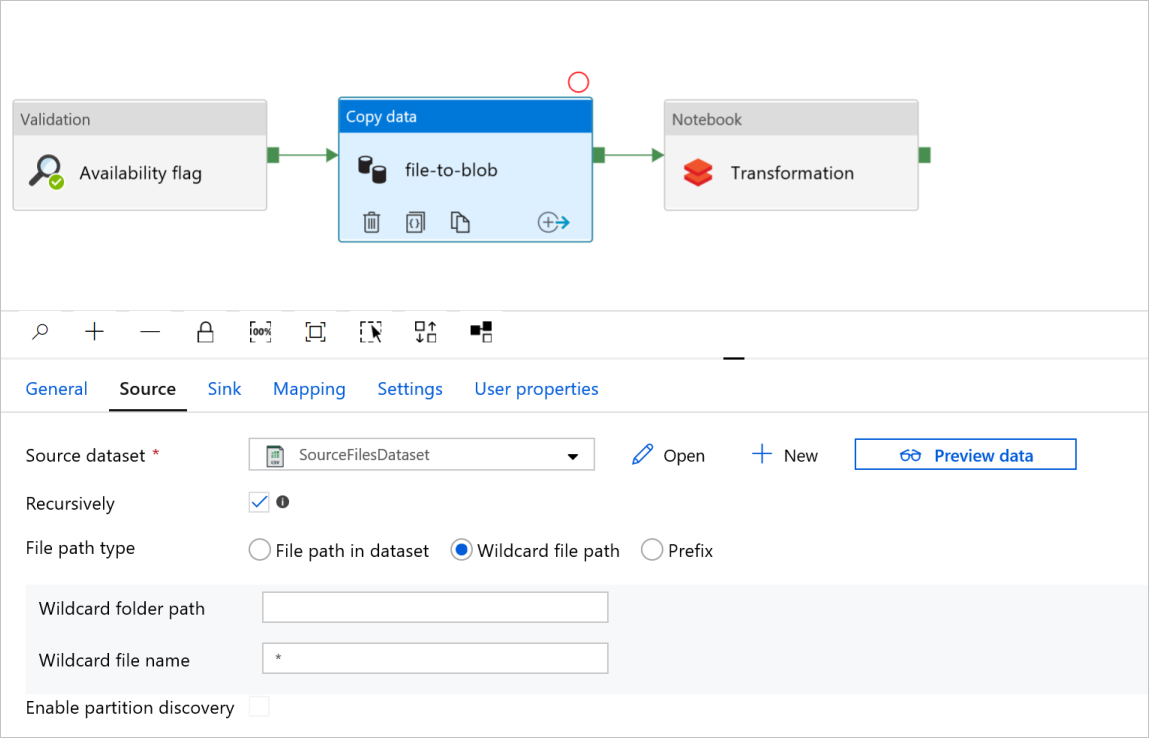
V souboru aktivity kopírování dat do objektu blob zkontrolujte karty Zdroj a Jímka. V případě potřeby změňte nastavení.
Karta Zdroj
Karta Jímka
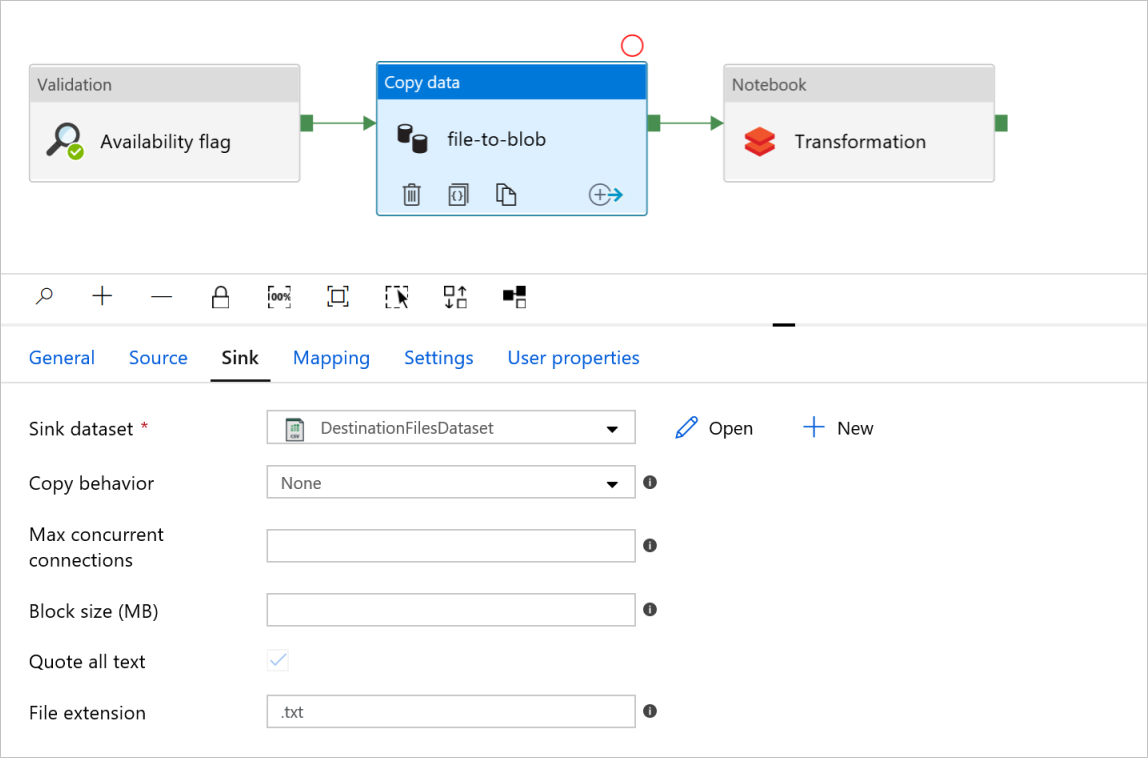
V transformaci aktivity poznámkového bloku zkontrolujte a podle potřeby aktualizujte cesty a nastavení.
Propojená služba Databricks by měla být předem vyplněná hodnotou z předchozího kroku, jak je znázorněno na obrázku:
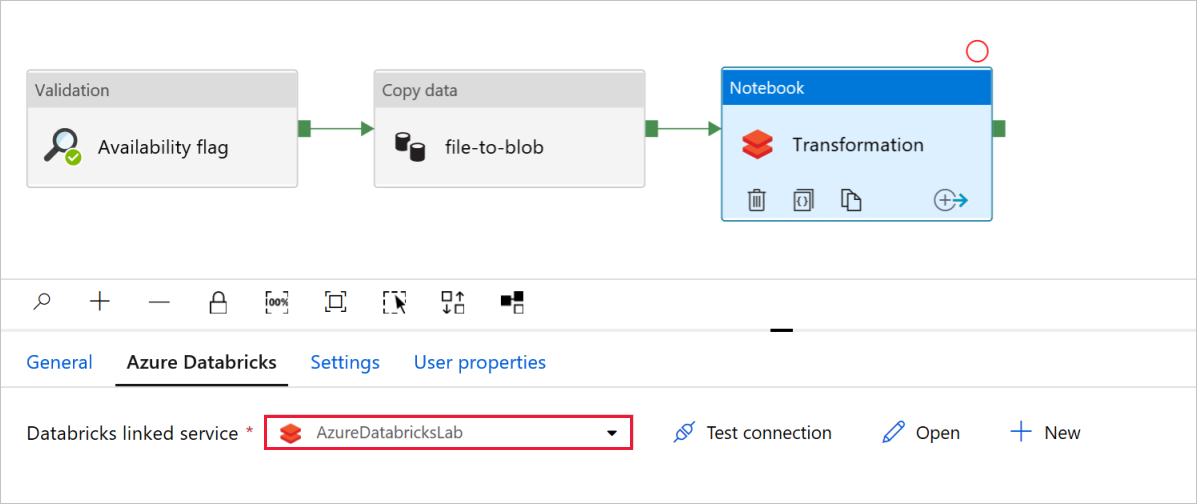
Kontrola nastavení poznámkového bloku:
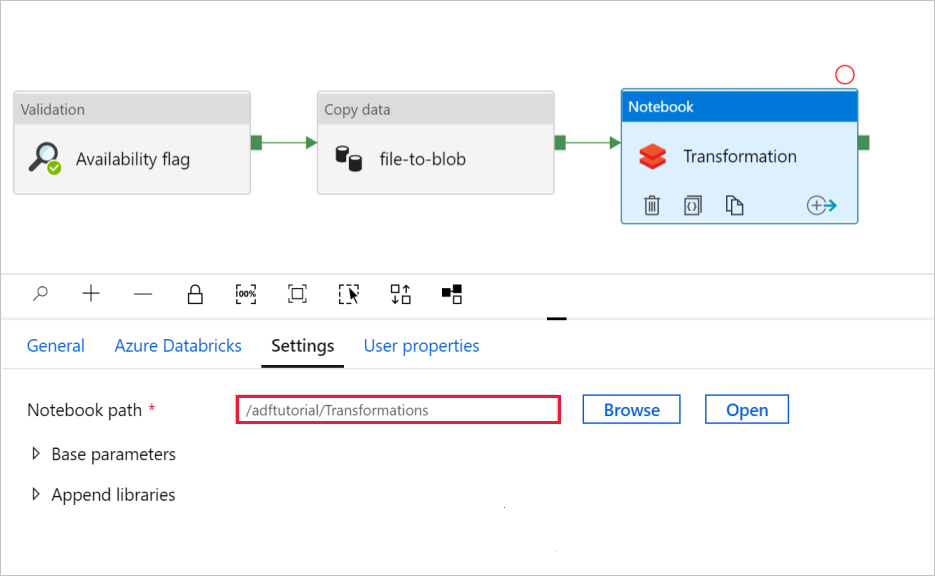
Vyberte kartu Nastavení. V případě cesty poznámkového bloku ověřte správnost výchozí cesty. Možná budete muset procházet a zvolit správnou cestu k poznámkovému bloku.
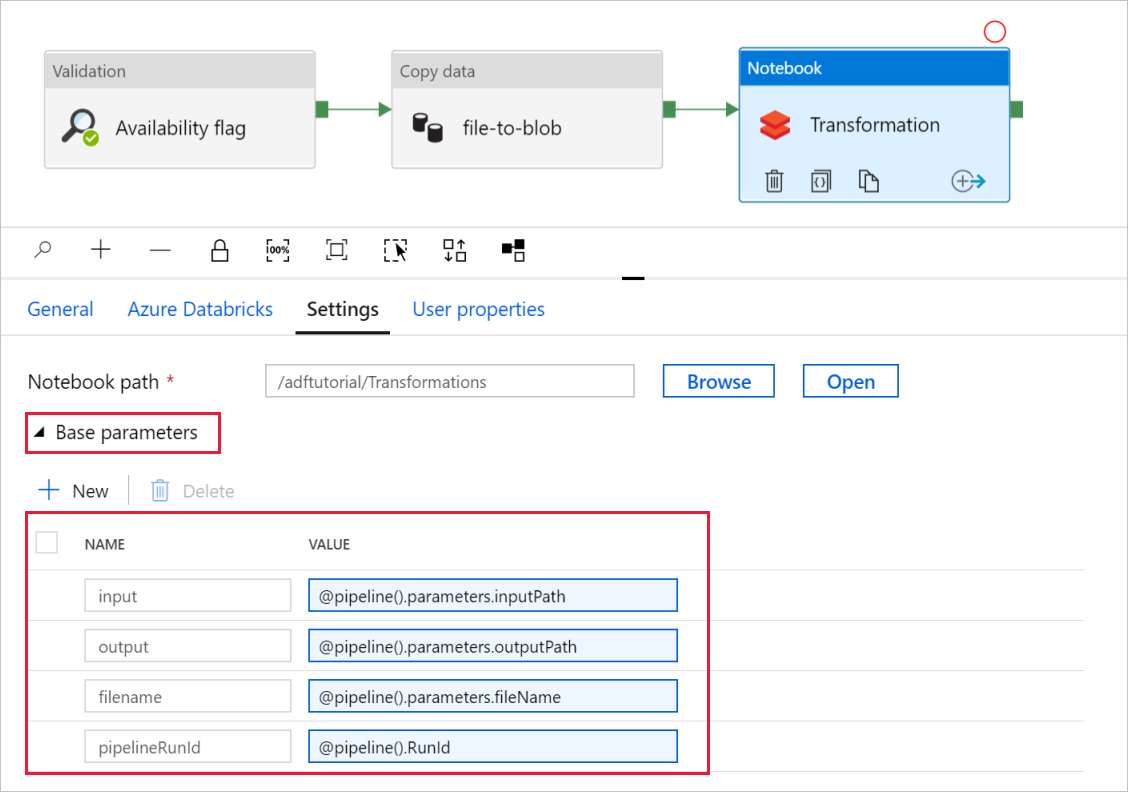
Rozbalte selektor základních parametrů a ověřte, že parametry odpovídají tomu, co je znázorněno na následujícím snímku obrazovky. Tyto parametry se předávají do poznámkového bloku Databricks ze služby Data Factory.
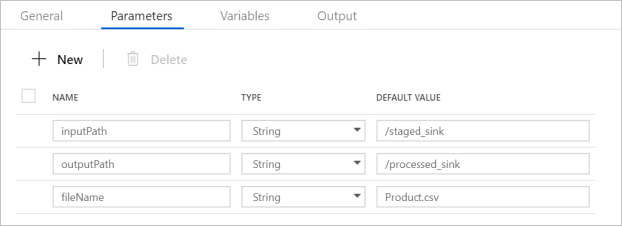
Ověřte, že parametry kanálu odpovídají tomu, co je znázorněno na následujícím snímku obrazovky:
Připojte se k datovým sadám.
Poznámka:
V následujících datových sadách byla cesta k souboru automaticky zadána v šabloně. Pokud se vyžadují nějaké změny, ujistěte se, že jste zadali cestu pro kontejner i adresář pro případ, že dojde k chybě připojení.
SourceAvailabilityDataset – zkontrolujte, jestli jsou zdrojová data dostupná.
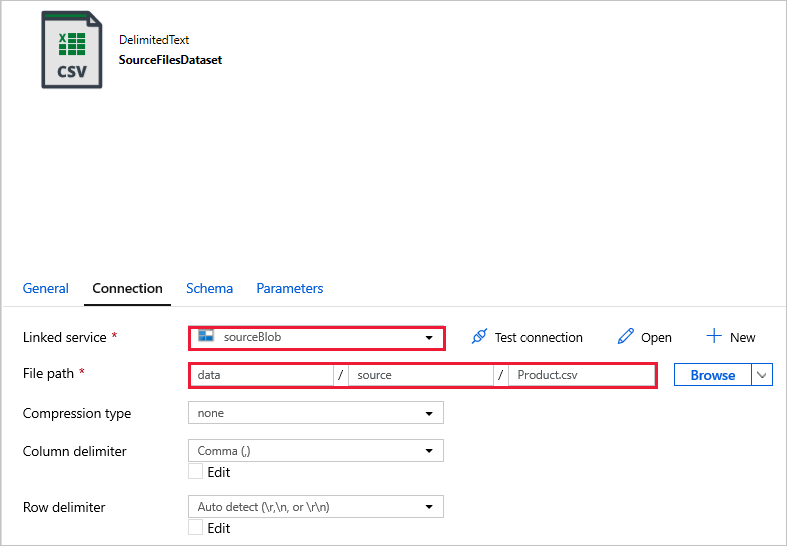
SourceFilesDataset – pro přístup ke zdrojovým datům.
DestinationFilesDataset – zkopírování dat do cílového umístění jímky Použijte následující hodnoty:
Propojená služba -
sinkBlob_LSvytvořená v předchozím krokuCesta k -
sinkdata/staged_sinksouboru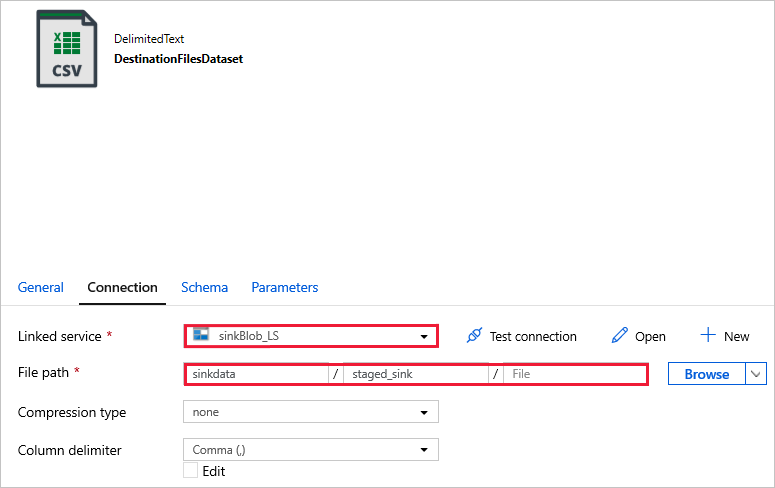
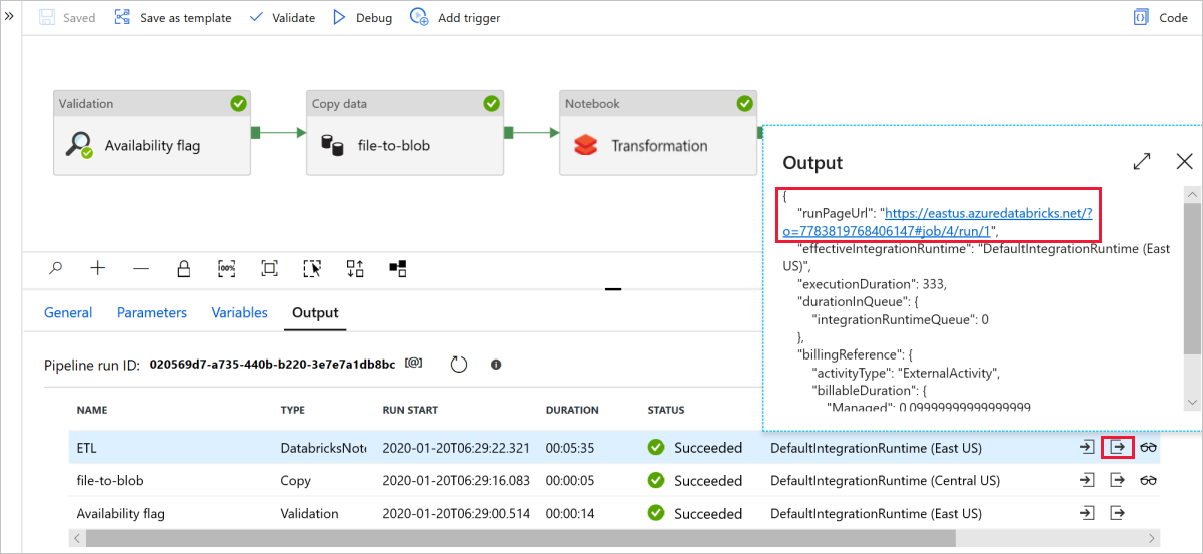
Vyberte Ladit a spusťte kanál. Odkaz na protokoly Databricks najdete pro podrobnější protokoly Sparku.
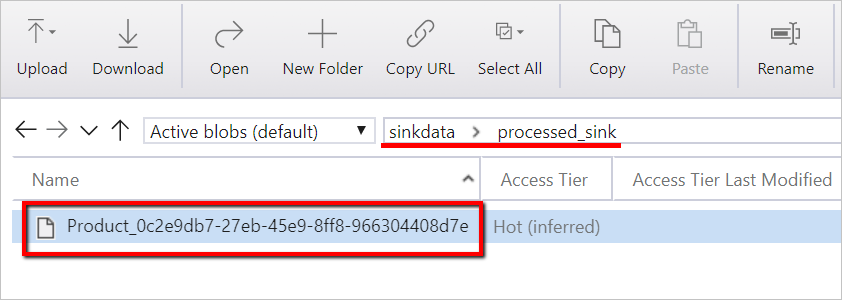
Datový soubor můžete také ověřit pomocí Průzkumník služby Azure Storage.
Poznámka:
Pro korelaci s spuštěním kanálu Data Factory tento příklad připojí ID spuštění kanálu z datové továrny do výstupní složky. To pomáhá sledovat soubory vygenerované jednotlivými spuštěními.
Související obsah
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro