Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
VZTAHUJE SE NA: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
Kanál v pracovním prostoru Azure Data Factory nebo Synapse Analytics zpracovává data v propojených službách úložiště pomocí propojených výpočetních služeb. Obsahuje posloupnost aktivit, ve kterých každá aktivita provádí konkrétní operaci zpracování. Tento článek popisuje aktivitu U-SQL služby Data Lake Analytics, která spouští skript U-SQL na výpočetní propojené službě Azure Data Lake Analytics.
Vytvořte účet Azure Data Lake Analytics před vytvořením kanálu s aktivitou Data Lake Analytics U-SQL. Další informace o Azure Data Lake Analytics naleznete v tématu Začínáme s Azure Data Lake Analytics.
Přidejte aktivitu U-SQL pro Azure Data Lake Analytics do potrubí pomocí uživatelského rozhraní.
Pokud chcete použít aktivitu U-SQL v rámci Azure Data Lake Analytics v datovém kanálu, proveďte následující kroky:
V podokně Aktivity kanálu vyhledejte Data Lake a přetáhněte aktivitu U-SQL na plátno kanálu.
Pokud ještě není vybraná, vyberte na plátně novou aktivitu U-SQL.
Vyberte kartu ADLA Account a vyberte nebo vytvořte novou propojenou službu Azure Data Lake Analytics, která se použije ke spuštění aktivity U-SQL.
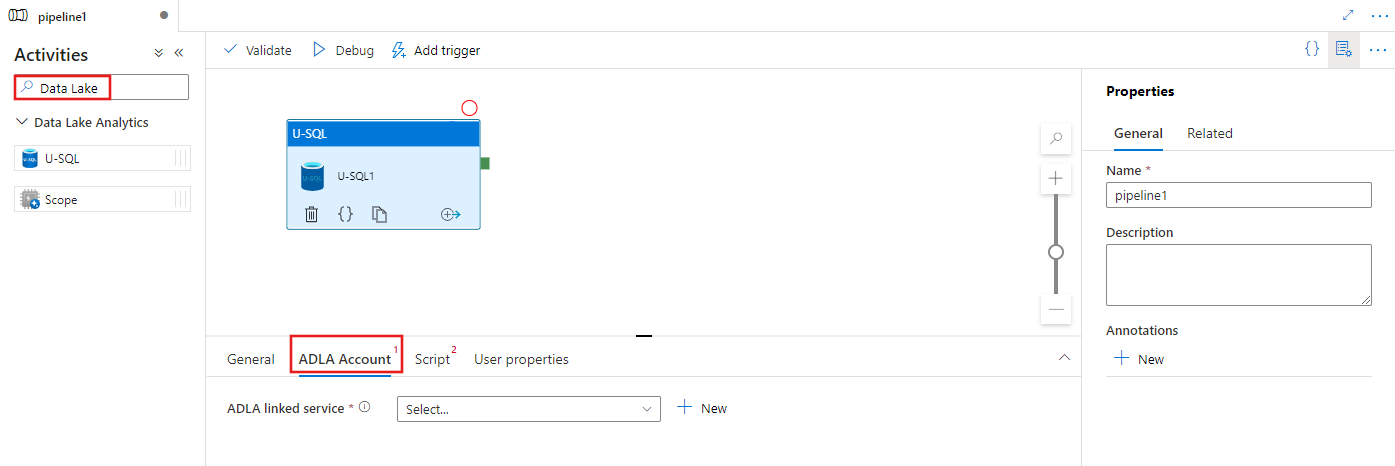
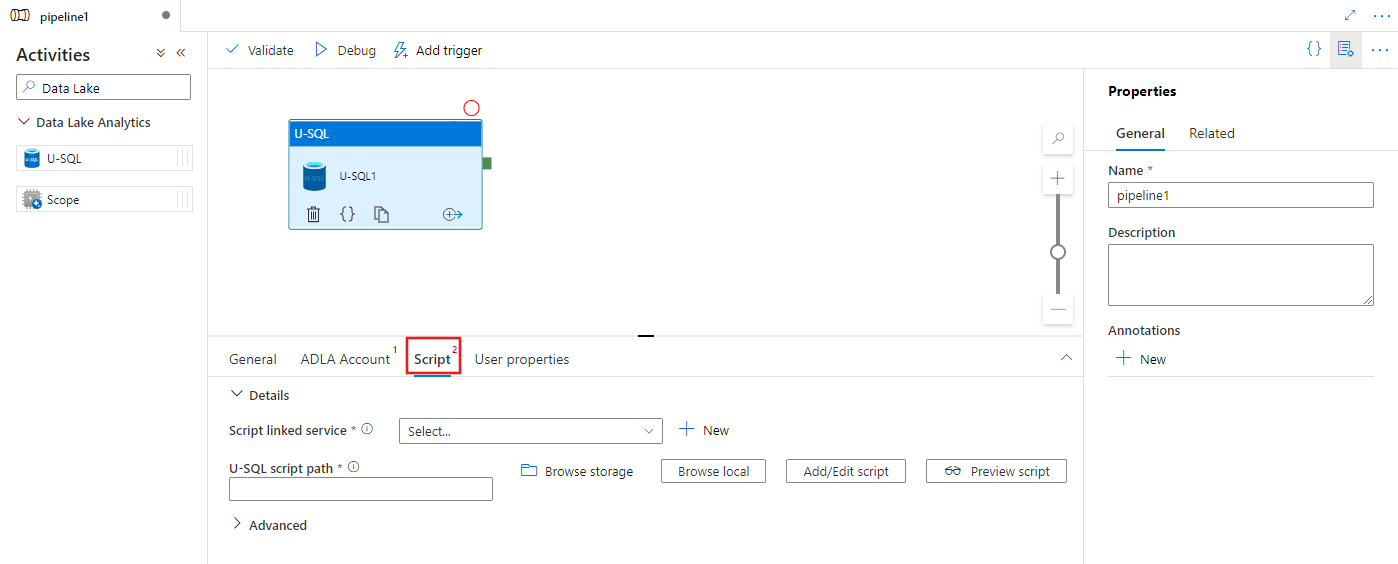
Výběrem karty Skript vyberte nebo vytvořte novou propojenou službu úložiště a cestu v umístění úložiště, která bude hostovat skript.
propojená služba Azure Data Lake Analytics
Vytvoříte propojenou službu Azure Data Lake Analytics, která propojí výpočetní službu Azure Data Lake Analytics s pracovním prostorem Azure Data Factory nebo Synapse Analytics. Analytická aktivita Data Lake U-SQL v datovém toku odkazuje na tuto propojenou službu.
Následující tabulka obsahuje popis obecných vlastností použitých v definici JSON.
| Vlastnost | Popis | Povinné |
|---|---|---|
| type | Vlastnost typu by měla být nastavena na: AzureDataLakeAnalytics. | Ano |
| accountName | Azure Data Lake Analytics název účtu. | Ano |
| dataLakeAnalyticsUri | Azure Data Lake Analytics identifikátor URI. | Ne |
| subscriptionId | ID předplatného Azure | Ne |
| resourceGroupName | název skupiny prostředků Azure | Ne |
Ověřování service principal
Propojená služba Azure Data Lake Analytics vyžaduje ověření služebního principálu pro připojení do služby Azure Data Lake Analytics. Pokud chcete použít ověřování pomocí obslužného principálu, zaregistrujte entitu aplikace v Microsoft Entra ID a udělte jí přístup k Data Lake Analytics a Data Lake Store, které používá. Podrobný postup najdete v tématu Ověřování mezi službami. Poznamenejte si následující hodnoty, které slouží k definování propojené služby:
- ID aplikace
- Klíč aplikace
- ID nájemce
Udělte služebnímu principálu oprávnění pro váš Azure Data Lake Analytics pomocí průvodce Přidání uživatele.
Ověřování principálu služby použijte zadáním následujících vlastností:
| Vlastnost | Popis | Povinné |
|---|---|---|
| servicePrincipalId | Zadejte ID klienta aplikace. | Ano |
| servicePrincipalKey | Zadejte klíč aplikace. | Ano |
| klient | Zadejte informace o tenantovi (název domény nebo ID tenanta), pod kterým se vaše aplikace nachází. Můžete ho získat najetím myší do pravého horního rohu portálu Azure. | Ano |
Příklad: Ověřování služební hlavní identity
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Další informace o propojené službě najdete v tématu Propojené služby Compute.
Aktivita Data Lake Analytics U-SQL
Následující fragment kódu JSON definuje kanál s aktivitou Data Lake Analytics U-SQL. Definice aktivity obsahuje odkaz na Azure Data Lake Analytics propojenou službu, kterou jste vytvořili dříve. Pokud chcete spustit Data Lake Analytics skript U-SQL, služba odešle skript, který jste zadali do Data Lake Analytics, a požadované vstupy a výstupy jsou definovány ve skriptu pro Data Lake Analytics k načtení a výstupu.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
Následující tabulka popisuje názvy a popisy vlastností, které jsou specifické pro tuto aktivitu.
| Vlastnost | Popis | Povinné |
|---|---|---|
| název | Název aktivity v potrubí | Ano |
| popis | Text popisující, co aktivita dělá. | Ne |
| typ | U Data Lake Analytics aktivity U-SQL je typ aktivity DataLakeAnalyticsU-SQL. | Ano |
| názevPrepojenéSlužby | Propojená služba pro Azure Data Lake Analytics Další informace o této propojené službě najdete v článku o propojených službách Compute. | Ano |
| scriptPath | Cesta ke složce, která obsahuje skript U-SQL V názvu souboru se rozlišují malá a velká písmena. | Ano |
| scriptLinkedService | Propojená služba, která propojuje Azure Data Lake Store nebo Azure Storage obsahující skript | Ano |
| stupeň paralelismu | Maximální počet uzlů, které se současně používají ke spuštění úlohy. | Ne |
| priorita | Určuje, které úlohy ve frontě mají být vybrány k spuštění jako první. Čím nižší je číslo, tím vyšší je priorita. | Ne |
| parametry | Parametry, které se mají předat do skriptu U-SQL | Ne |
| verze běhového prostředí | Verze modulu runtime U-SQL, který se má použít. | Ne |
| compilationMode | Režim kompilace U-SQL Musí to být jedna z těchto hodnot: Sémantika: Proveďte pouze sémantické kontroly a nezbytné kontroly sanity, Úplné: Proveďte úplnou kompilaci, včetně kontroly syntaxe, optimalizace, generování kódu atd., SingleBox: Proveďte úplnou kompilaci s nastavením TargetType na SingleBox. Pokud pro tuto vlastnost nezadáte hodnotu, server určí optimální režim kompilace. |
Ne |
Viz SearchLogProcessing.txt definice skriptu.
Ukázkový skript U-SQL
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
Ve výše uvedeném příkladu skriptu je vstup a výstup skriptu definován v @in a @out parametry. Hodnoty parametrů @in a @out ve skriptu U-SQL se službou předávají dynamicky pomocí oddílu "parameters".
Můžete také zadat další vlastnosti, jako je degreeOfParallelism a priorita, v definici kanálu pro úlohy, které běží ve službě Azure Data Lake Analytics.
Dynamické parametry
V definici ukázkového kanálu jsou parametry in a out přiřazeny pevně zakódovanými hodnotami.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Místo toho je možné použít dynamické parametry. Příklad:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
V tomto případě se vstupní soubory stále vybírají ze složky /datalake/input a výstupní soubory se generují ve složce /datalake/output. Názvy souborů jsou dynamické na základě počátečního času okna, který je předáván při spuštění datového toku.
Související obsah
Podívejte se na následující články, které vysvětlují, jak transformovat data jinými způsoby: