Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
V tomto kurzu vytvoříte datovou továrnu Azure s kanálem, který načítá rozdílová data na základě informací o zachytávání dat změn (CDC) ve zdrojové databázi azure SQL Managed Instance do úložiště objektů blob v Azure.
V tomto kurzu provedete následující kroky:
- Příprava zdrojového úložiště dat
- Vytvoření datové továrny
- Vytvoření propojených služeb
- Vytvoření zdrojové datové sady a datové sady jímky
- Vytvoření, ladění a spuštění kanálu pro kontrolu změněná data
- Úprava dat ve zdrojové tabulce
- Dokončení, spuštění a monitorování úplného kanálu přírůstkového kopírování
Přehled
K identifikaci změněných dat je možné použít technologii Change Data Capture podporovanou úložišti dat, jako jsou Azure SQL Managed Instances (MI) a SQL Server. Tento kurz popisuje, jak pomocí služby Azure Data Factory s technologií SQL Change Data Capture přírůstkově načítat rozdílová data z Azure SQL Managed Instance do služby Azure Blob Storage. Další konkrétní informace o technologii SQL Change Data Capture naleznete v tématu Změna zachytávání dat na SQL Serveru.
Ucelený pracovní postup
Tady jsou typické komplexní kroky pracovního postupu pro přírůstkové načítání dat pomocí technologie Change Data Capture.
Poznámka:
Azure SQL MI i SQL Server podporují technologii Change Data Capture. V tomto kurzu se jako zdrojové úložiště dat používá spravovaná instance Azure SQL. Můžete také využít místní SQL Server.
Řešení na nejvyšší úrovni
V tomto kurzu vytvoříte kanál, který provede následující operace:
- Vytvořte vyhledávací aktivitu , která spočítá počet změněných záznamů v tabulce CDC služby SQL Database a předá ji aktivitě podmínky IF.
- Vytvořte podmínku If, která zkontroluje, jestli existují změněné záznamy, a pokud ano, vyvolání aktivity kopírování.
- Vytvořte aktivitu kopírování, která zkopíruje vložená, aktualizovaná nebo odstraněná data mezi tabulkou CDC do služby Azure Blob Storage.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
- Spravovaná instance Azure SQL Tuto databázi použijete jako zdrojové úložiště dat. Pokud nemáte spravovanou instanci Azure SQL, přečtěte si článek Vytvoření spravované instance Azure SQL Database, kde najdete postup jeho vytvoření.
- Účet služby Azure Storage. Úložiště objektů blob použijete jako úložiště dat jímky. Pokud nemáte účet úložiště Azure, přečtěte si článek Vytvoření účtu úložiště, kde najdete kroky pro jeho vytvoření. Vytvořte kontejner s názvem raw.
Vytvoření tabulky zdroje dat ve službě Azure SQL Database
Spusťte APLIKACI SQL Server Management Studio a připojte se k serveru Azure SQL Managed Instances.
V Průzkumníku serveru klikněte pravým tlačítkem na databázi a potom zvolte Nový dotaz.
Spuštěním následujícího příkazu SQL pro databázi Azure SQL Managed Instances vytvořte tabulku pojmenovanou
customersjako úložiště zdrojů dat.create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Spuštěním následujícího dotazu SQL povolte mechanismus Change Data Capture ve vaší databázi a zdrojové tabulce (zákazníci):
Poznámka:
- Nahraďte <název> zdrojového schématu schématu schématem azure SQL MI, které obsahuje tabulku zákazníků.
- Zachytávání dat změn nedělá nic jako součást transakcí, které mění sledované tabulky. Místo toho se operace vložení, aktualizace a odstranění zapisují do transakčního protokolu. Data uložená v tabulkách změn se nespravovatelně zvětšují, pokud data pravidelně a systematicky vyřazujete. Další informace najdete v tématu Povolení funkce Change Data Capture pro databázi.
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Spuštěním následujícího příkazu vložte data do tabulky customers:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Poznámka:
Před povolením zachytávání dat změn se nezachytí žádné historické změny v tabulce.
Vytvoření datové továrny
Postupujte podle kroků v rychlém startu v článku : Vytvoření datové továrny pomocí webu Azure Portal k vytvoření datové továrny, pokud ji ještě nemáte pro práci.
Vytvoření propojených služeb
V datové továrně vytvoříte propojené služby, abyste svá úložiště dat a výpočetní služby spojili s datovou továrnou. V této části vytvoříte propojené služby s vaším účtem Azure Storage a Azure SQL MI.
Vytvořte propojenou službu pro Azure Storage
V tomto kroku s datovou továrnou propojíte svůj účet služby Azure Storage.
Klikněte na Připojení a pak na + Nové.
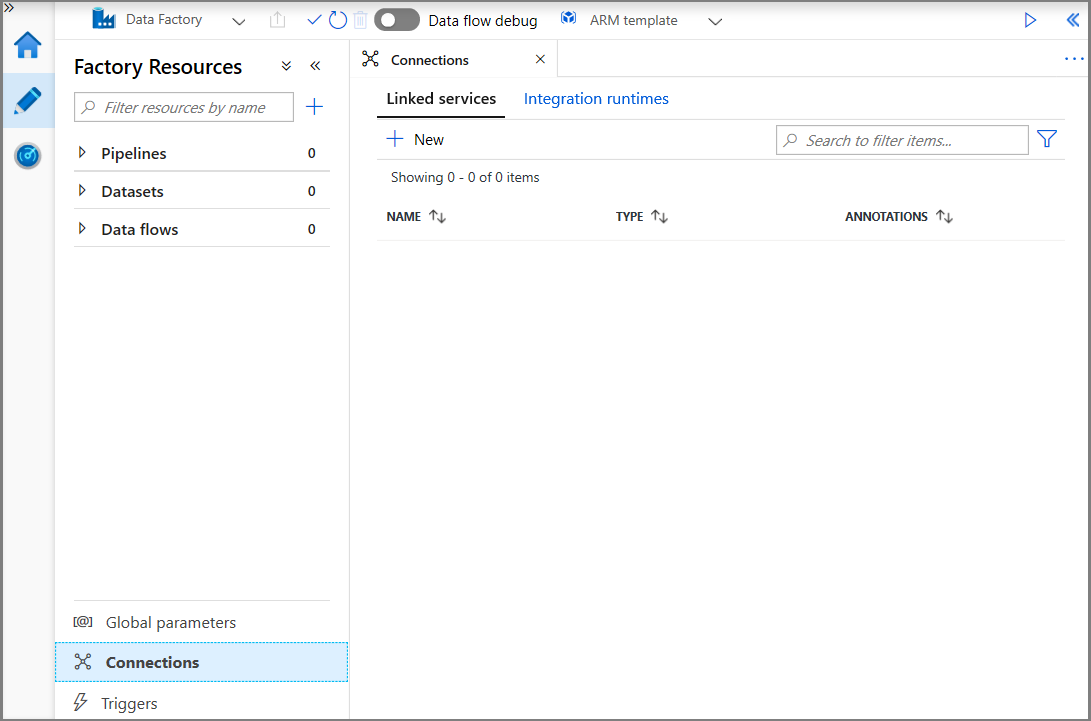
V okně Nová propojená služba vyberte Azure Blob Storage a klikněte na Pokračovat.
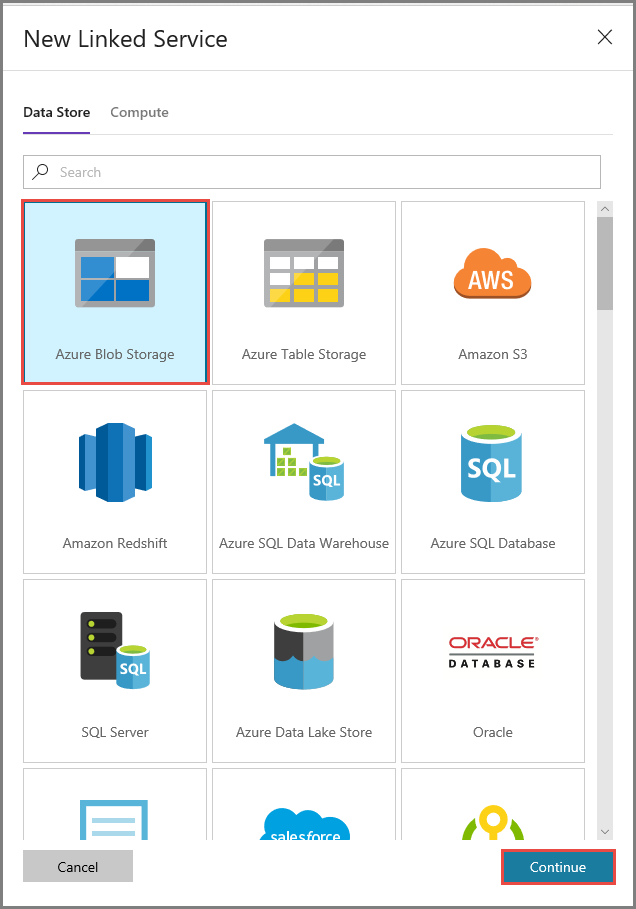
V okně Nová propojená služba proveďte následující kroky:
- Jako Název zadejte AzureStorageLinkedService.
- Jako Název účtu úložiště vyberte svůj účet služby Azure Storage.
- Klikněte na Uložit.
Vytvořte propojenou službu Azure SQL MI Database.
V tomto kroku propočítáte databázi Azure SQL MI s datovou továrnou.
Poznámka:
Informace o přístupu prostřednictvím veřejného a privátního koncového bodu najdete tady pro ty, kteří používají SQL MI. Pokud použijete privátní koncový bod, musíte tento kanál spustit pomocí místního prostředí Integration Runtime. Totéž platí pro ty, na kterých běží místní SQL Server, ve scénářích virtuálních počítačů nebo virtuálních sítí.
Klikněte na Připojení a pak na + Nové.
V okně Nová propojená služba vyberte spravovanou instanci Azure SQL Database a klikněte na Pokračovat.
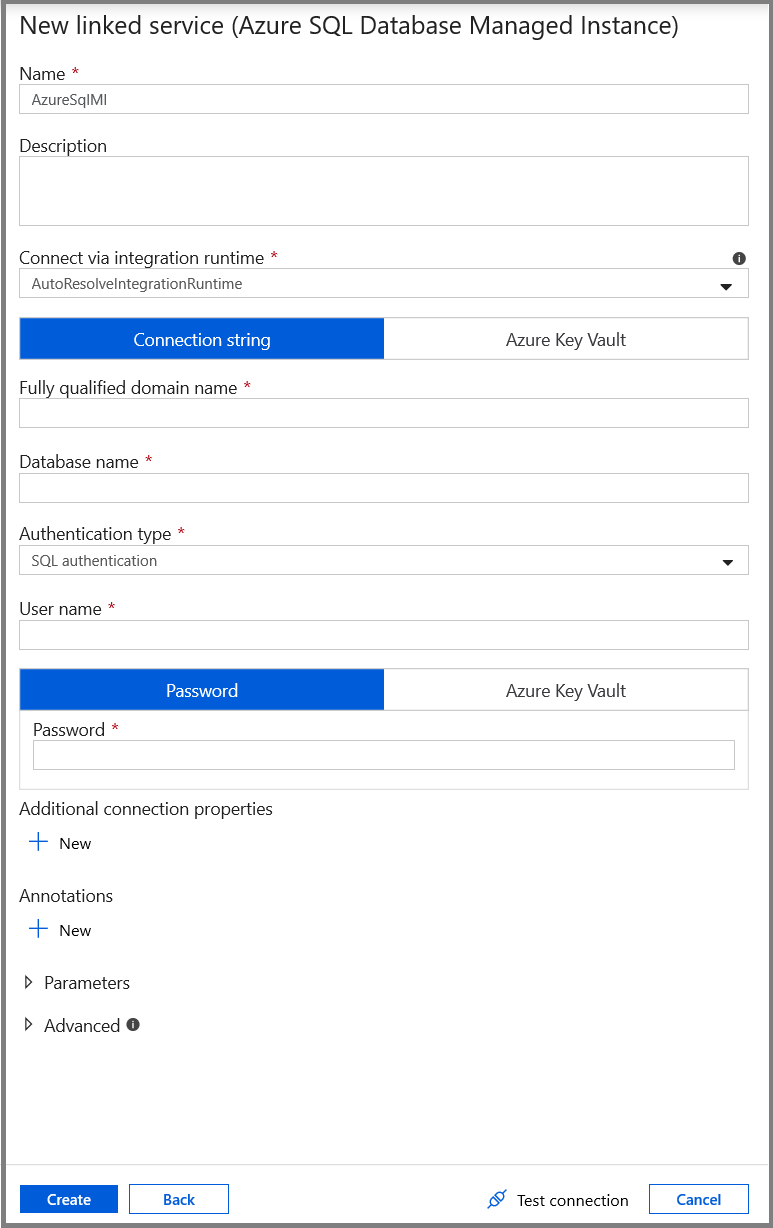
V okně Nová propojená služba proveďte následující kroky:
- Jako pole Název zadejte AzureSqlMI1.
- Jako pole Název serveru vyberte server SQL.
- Vyberte databázi SQL pro pole Název databáze.
- Do pole Uživatelské jméno zadejte jméno uživatele.
- Do pole Heslo zadejte heslo pro tohoto uživatele.
- Klikněte na Test připojení a otestujte připojení.
- Kliknutím na Uložit propojenou službu uložte.
Vytvoření datových sad
V tomto kroku vytvoříte datové sady, které představují zdroj dat a cíl dat.
Vytvoření datové sady představující zdrojová data
V tomto kroku vytvoříte datovou sadu pro reprezentaci zdrojových dat.
Ve stromovém zobrazení klikněte na symbol + (plus) a pak klikněte na Datová sada.
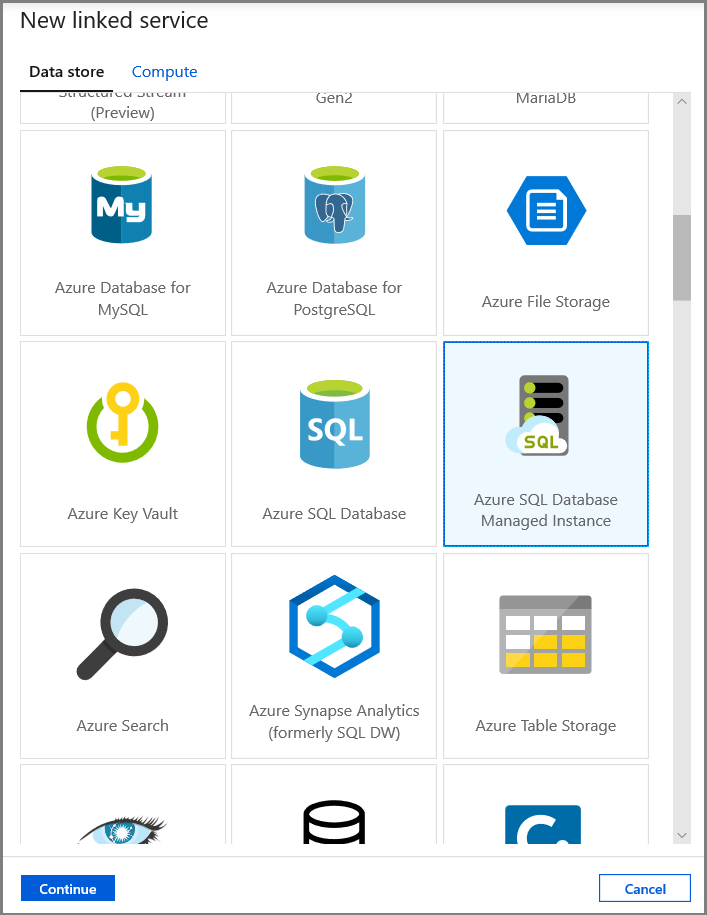
Vyberte spravovanou instanci Azure SQL Database a klikněte na Pokračovat.
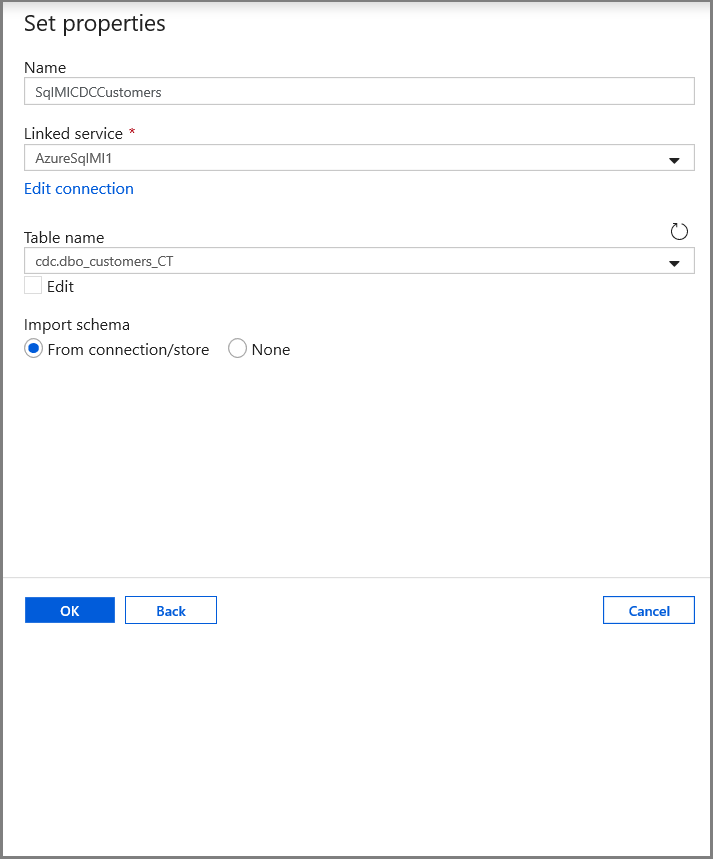
Na kartě Nastavit vlastnosti nastavte název datové sady a informace o připojení:
- Vyberte AzureSqlMI1 pro propojenou službu.
- Vyberte [dbo].[ dbo_customers_CT] pro název tabulky. Poznámka: Tato tabulka se automaticky vytvořila, když byla v tabulce zákazníků povolena služba CDC. Změněná data se z této tabulky nikdy přímo dotazují, ale místo toho se extrahují prostřednictvím funkcí CDC.
Vytvořte datovou sadu, která bude představovat data kopírovaná do úložiště dat jímky.
V tomto kroku vytvoříte datovou sadu pro reprezentaci dat, která se kopírují ze zdrojového úložiště dat. V rámci požadavků jste ve službě Azure Blob Storage vytvořili kontejner Data Lake. Pokud tento kontejner neexistuje, vytvořte ho nebo použijte název existujícího kontejneru. V tomto kurzu se název výstupního souboru dynamicky generuje pomocí času triggeru, který se nakonfiguruje později.
Ve stromovém zobrazení klikněte na symbol + (plus) a pak klikněte na Datová sada.
Vyberte Azure Blob Storage a klikněte na Pokračovat.

Vyberte Text s oddělovači a klikněte na Pokračovat.

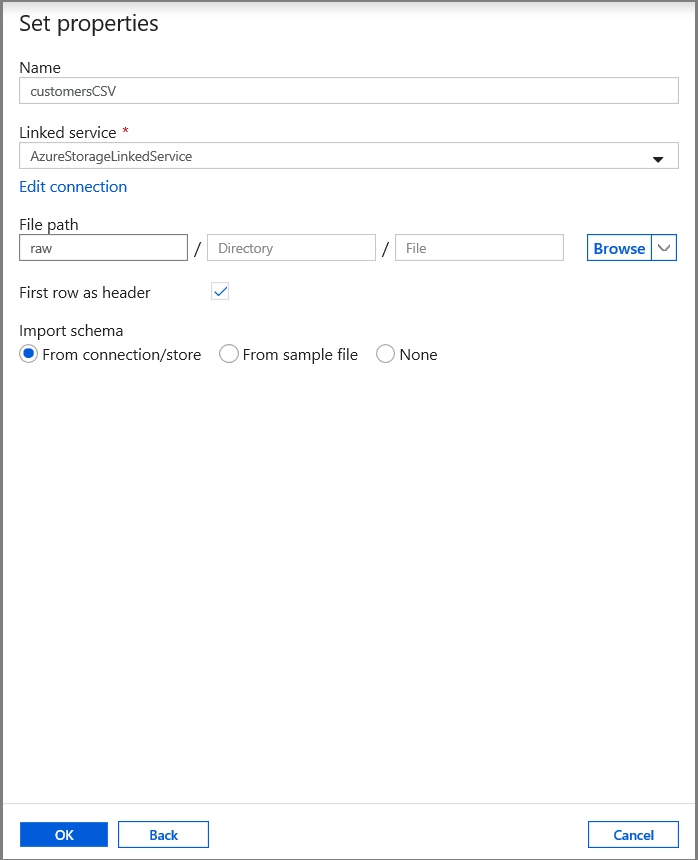
Na kartě Nastavit vlastnosti nastavte název datové sady a informace o připojení:
- Jako Propojená služba vyberte AzureStorageLinkedService.
- Zadejte nezpracovaný soubor pro část cesty k kontejneru.
- Povolit první řádek jako záhlaví
- Klikněte na ok.
Vytvoření kanálu pro zkopírování změněná data
V tomto kroku vytvoříte kanál, který nejprve zkontroluje počet změněných záznamů v tabulce změn pomocí vyhledávací aktivity. Aktivita podmínky KDYŽ kontroluje, jestli je počet změněných záznamů větší než nula, a spustí aktivitu kopírování pro kopírování vložených, aktualizovaných nebo odstraněných dat ze služby Azure SQL Database do služby Azure Blob Storage. Nakonec se nakonfiguruje aktivační událost pro přeskakující okno a počáteční a koncový čas se předá aktivitám jako parametry počátečního a koncového okna.
V uživatelském rozhraní služby Data Factory přepněte na kartu Upravit . V levém podokně klikněte na + (plus) a klikněte na Kanál.
Zobrazí se nová karta, na které můžete kanál konfigurovat. Kanál se zobrazí také ve stromovém zobrazení. V okně Vlastnosti změňte název kanálu na IncrementalCopyPipeline.
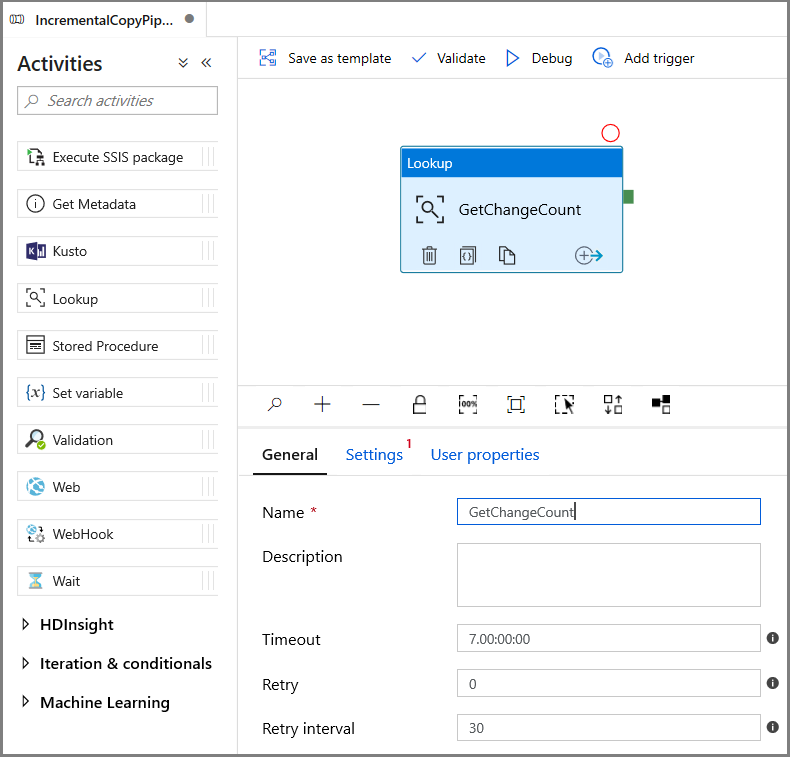
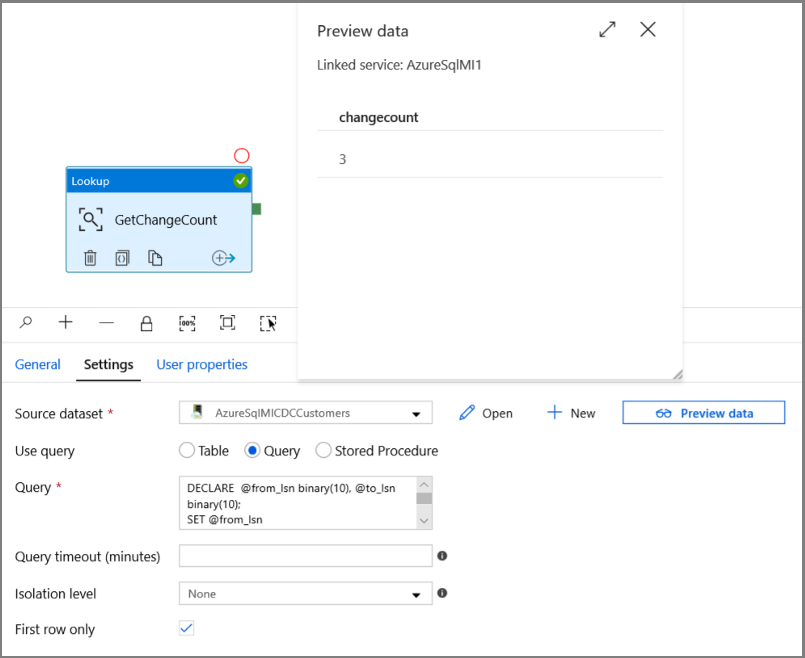
V sadě nástrojů Aktivity rozbalte Obecné a přetáhněte aktivitu Vyhledávání na plochu návrháře kanálu. Nastavte název aktivity na GetChangeCount. Tato aktivita získá počet záznamů v tabulce změn pro dané časové období.
Přepněte do nastavení v okně Vlastnosti :
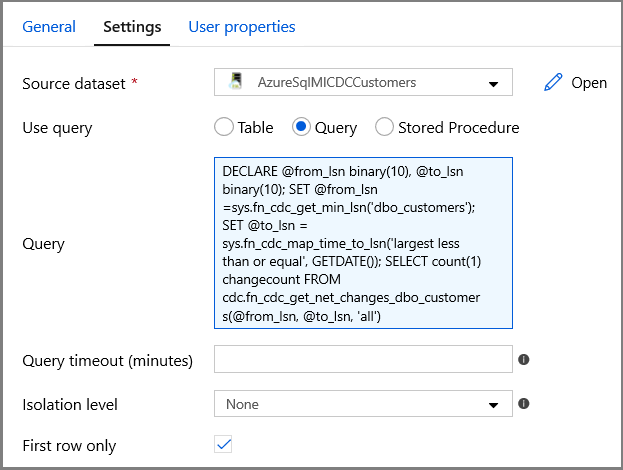
Zadejte název datové sady SQL MI pro pole Zdrojová datová sada .
Vyberte možnost Dotaz a do pole dotazu zadejte následující:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Povolit pouze první řádek
Klikněte na tlačítko Náhled dat a ujistěte se, že aktivita vyhledávání získá platný výstup.
Rozbalte iteraci a podmíněná nastavení na panelu nástrojů Aktivity a přetáhněte aktivitu Podmínky If na plochu návrháře kanálu. Nastavte název aktivity na HasChangedRows.
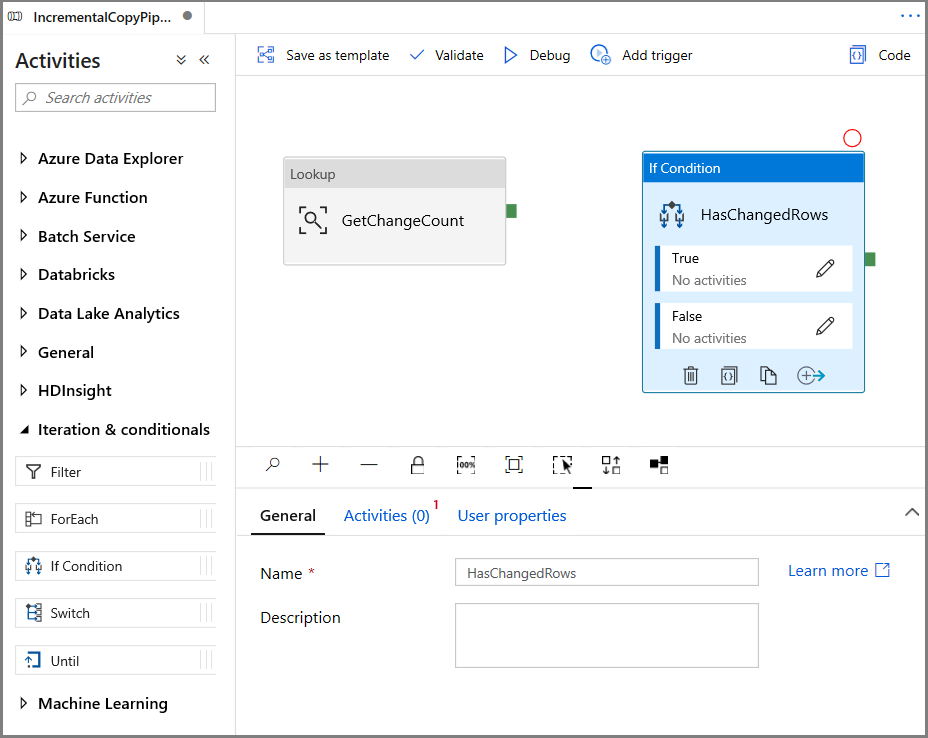
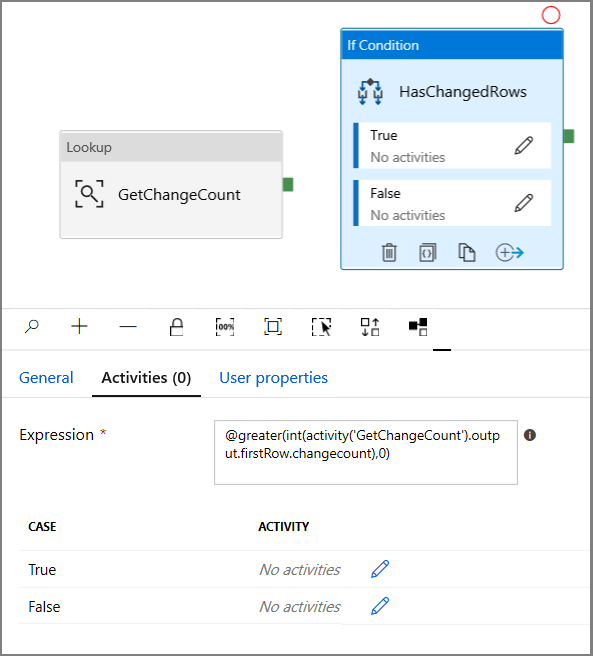
Přepněte na aktivity v okně Vlastnosti :
- Zadejte následující výraz.
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Kliknutím na ikonu tužky upravte podmínku True.
- Rozbalte položku Obecné na panelu nástrojů Aktivity a přetáhněte aktivitu Čekání na plochu návrháře kanálu. Jedná se o dočasnou aktivitu, která umožňuje ladit podmínku If a později v kurzu se změní.
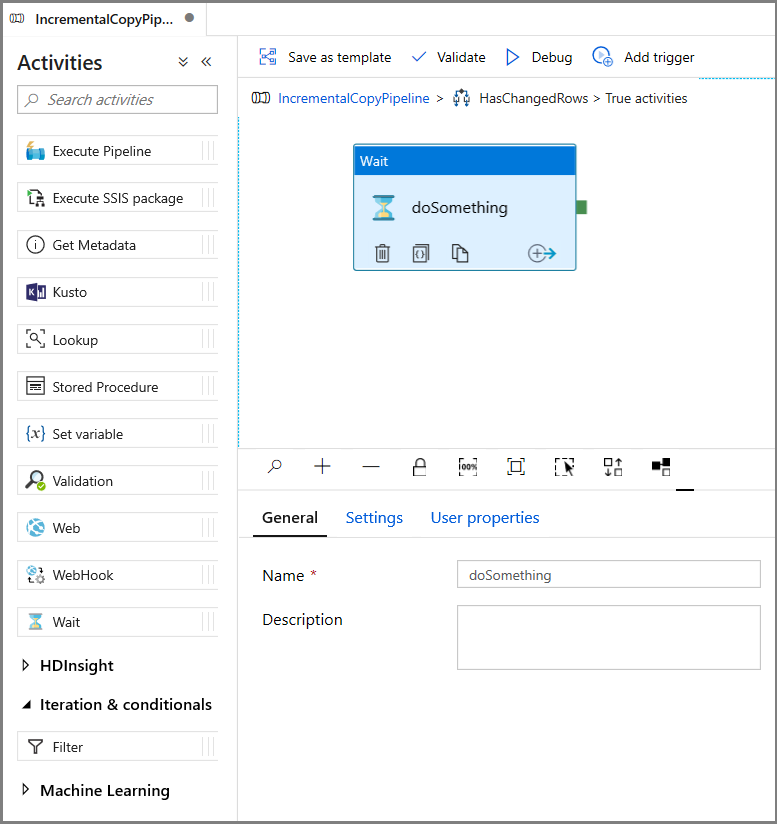
- Kliknutím na popis cesty IncrementalCopyPipeline se vraťte do hlavního kanálu.
Spusťte kanál v režimu ladění a ověřte, že se kanál úspěšně spustí.
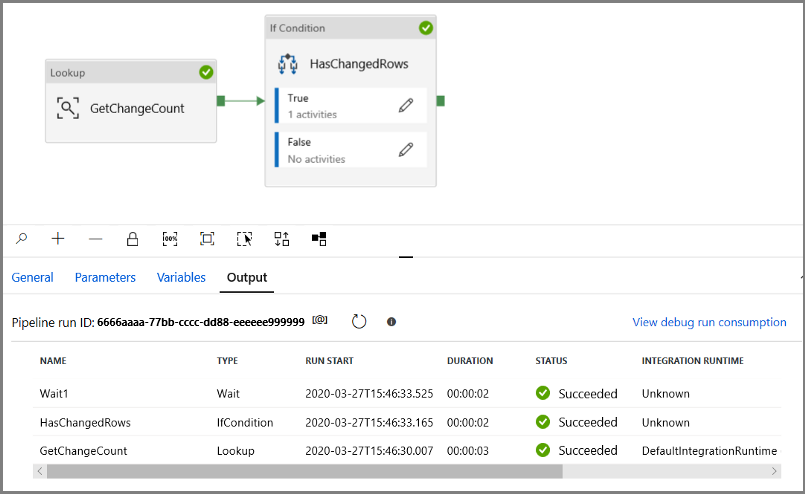
V dalším kroku se vraťte do kroku Podmínky True a odstraňte aktivitu Wait . V sadě nástrojů Aktivity rozbalte položku Přesunout a transformovat a přetáhněte aktivitu kopírování na plochu návrháře kanálu. Nastavte název aktivity na IncrementalCopyActivity.
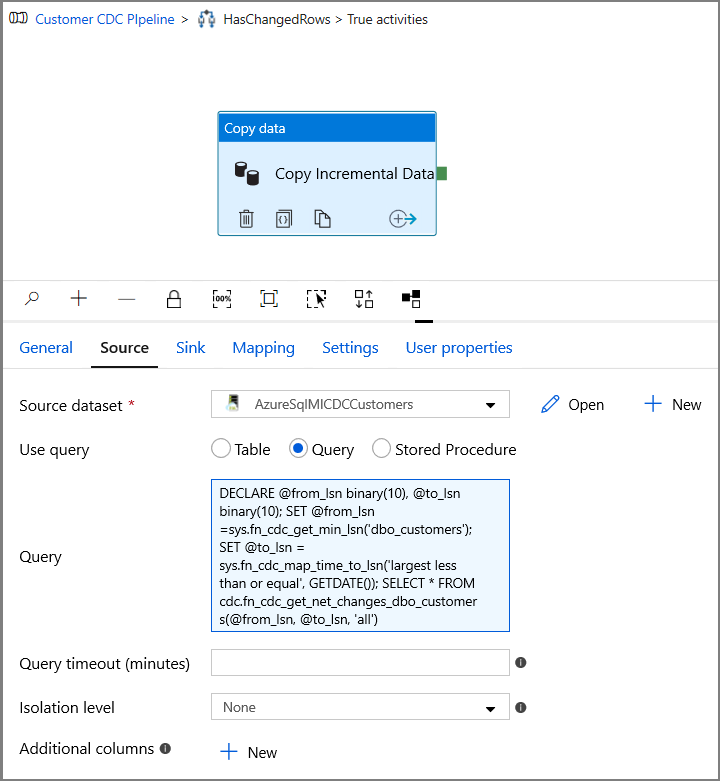
V okně Vlastnosti přepněte na kartu Zdroj a proveďte následující kroky:
Zadejte název datové sady SQL MI pro pole Zdrojová datová sada .
Jako Použít dotaz vyberte Dotaz.
Zadejte následující příkaz pro dotaz.
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
Kliknutím na náhled ověřte, že dotaz vrátí změněné řádky správně.
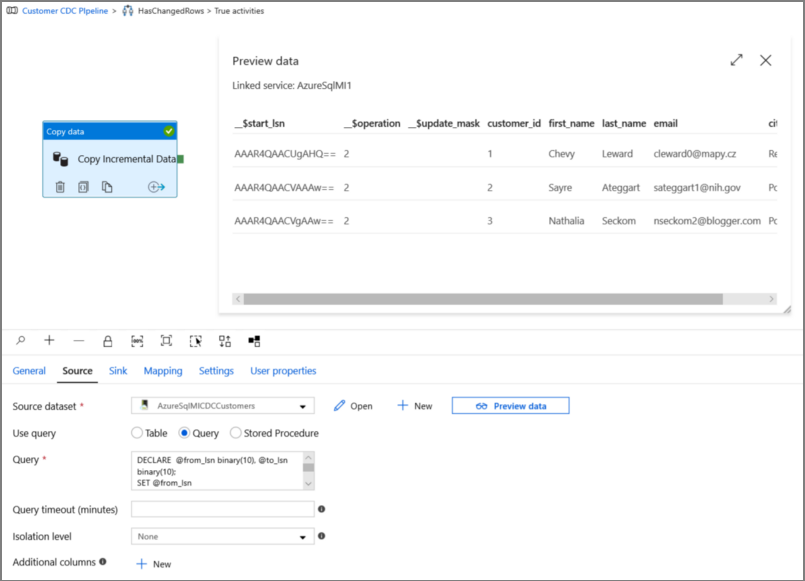
Přepněte na kartu Jímka a zadejte datovou sadu Azure Storage pro pole Datová sada jímky .

Klikněte zpět na plátno hlavního kanálu a připojte aktivitu Vyhledávání k aktivitě Podmínky If jeden po druhém. Přetáhněte zelené tlačítko připojené k aktivitě Vyhledávání do aktivity Podmínky If.
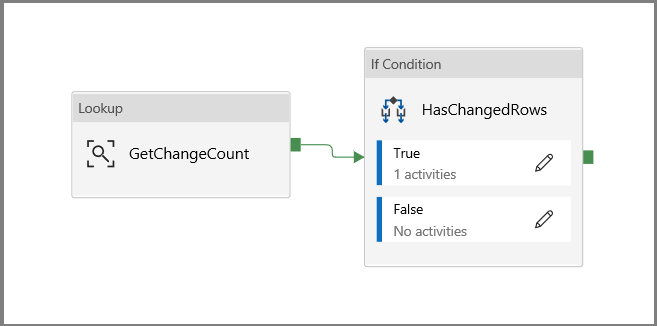
Klikněte na Ověřit na panelu nástrojů. Ověřte, že se nezobrazí žádné chyby ověření. Zavřete okno Sestava ověření kanálu kliknutím na >>.
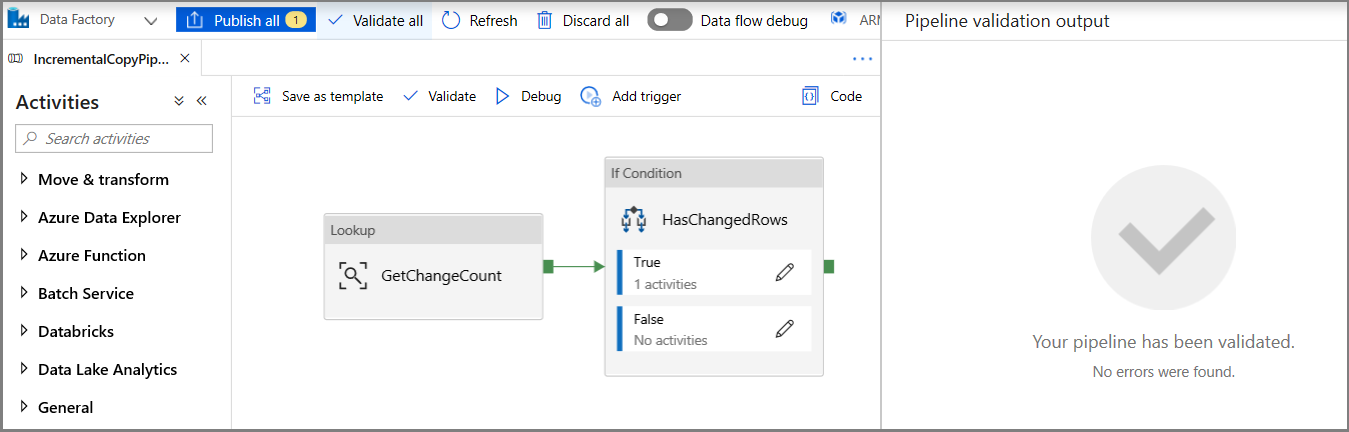
Kliknutím na Ladit otestujete kanál a ověříte, že se vygeneruje soubor v umístění úložiště.
Kliknutím na tlačítko Publikovat vše publikujte entity (propojené služby, datové sady a kanály) do služby Data Factory. Počkejte, dokud se nezobrazí zpráva Publikování proběhlo úspěšně.
Konfigurace triggeru pro přeskakujícího okna a parametrů okna CDC
V tomto kroku vytvoříte trigger pro přeskakující okno, který spustí úlohu podle časového plánu. Použijete systémové proměnné WindowStart a WindowEnd triggeru pro přeskakující okno a předáte je jako parametry kanálu, který se použije v dotazu CDC.
Přejděte na kartu Parametry kanálu IncrementalCopyPipeline a pomocí tlačítka + Nový přidejte do kanálu dva parametry (triggerStartTime a triggerEndTime), které budou představovat přeskakující okno počáteční a koncový čas. Pro účely ladění přidejte výchozí hodnoty ve formátu RRRR-MM-DD HH24:MI:SS.FFF , ale ujistěte se, že triggerStartTime není před povolením CDC v tabulce, jinak to způsobí chybu.
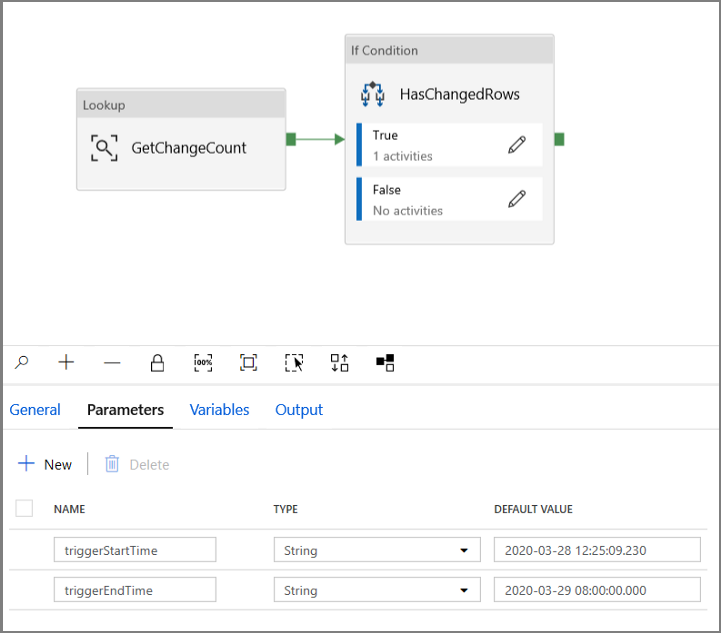
Klikněte na kartu nastavení aktivity Vyhledávání a nakonfigurujte dotaz tak, aby používal počáteční a koncové parametry. Zkopírujte do dotazu následující:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')V případě aktivity If Condition přejděte na aktivitu Kopírování a klikněte na kartu Zdroj. Zkopírujte do dotazu následující:
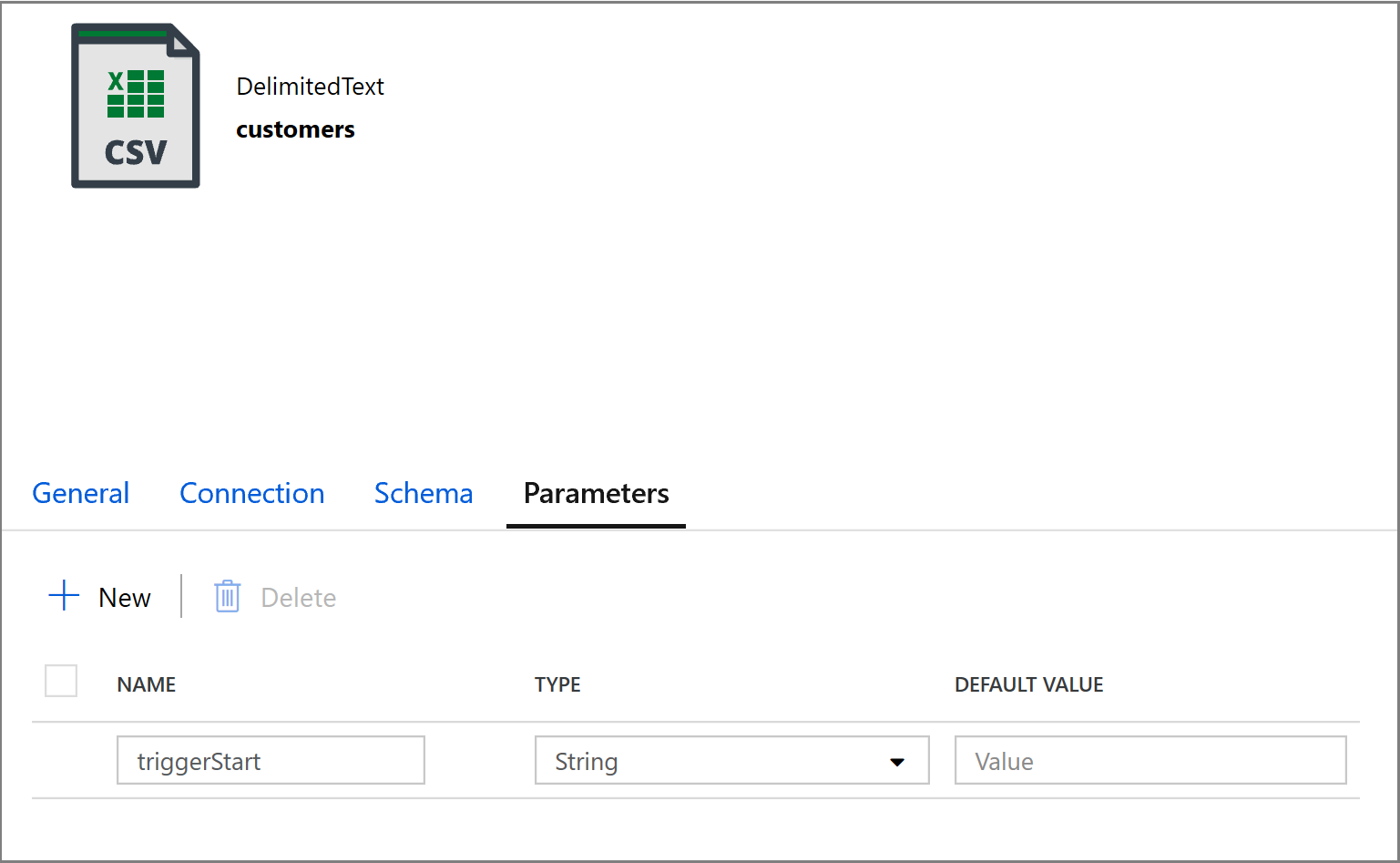
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Klikněte na kartu Jímka aktivity Kopírování a kliknutím na Otevřít upravte vlastnosti datové sady. Klikněte na kartu Parametry a přidejte nový parametr s názvem triggerStart.
Dále nakonfigurujte vlastnosti datové sady tak, aby ukládaly data v podadresáři customers/incremental s oddíly založenými na datech.
Klikněte na kartu Připojení vlastností datové sady a přidejte dynamický obsah pro oddíly Adresář i Soubor .
V části Adresář zadejte následující výraz kliknutím na odkaz na dynamický obsah pod textovým polem:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Do části Soubor zadejte následující výraz. Tím se vytvoří názvy souborů na základě počátečního a časového data triggeru s příponou CSV:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')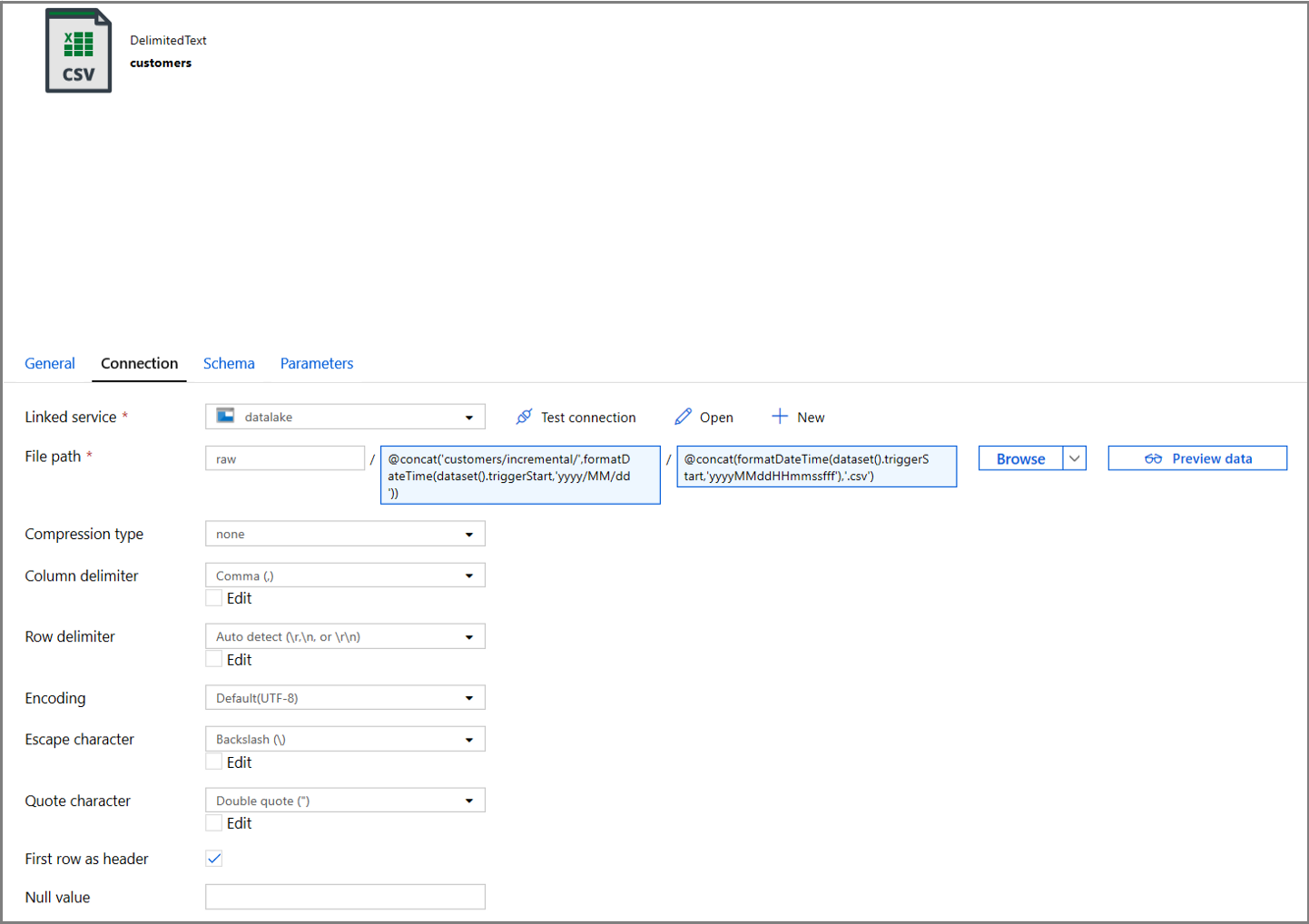
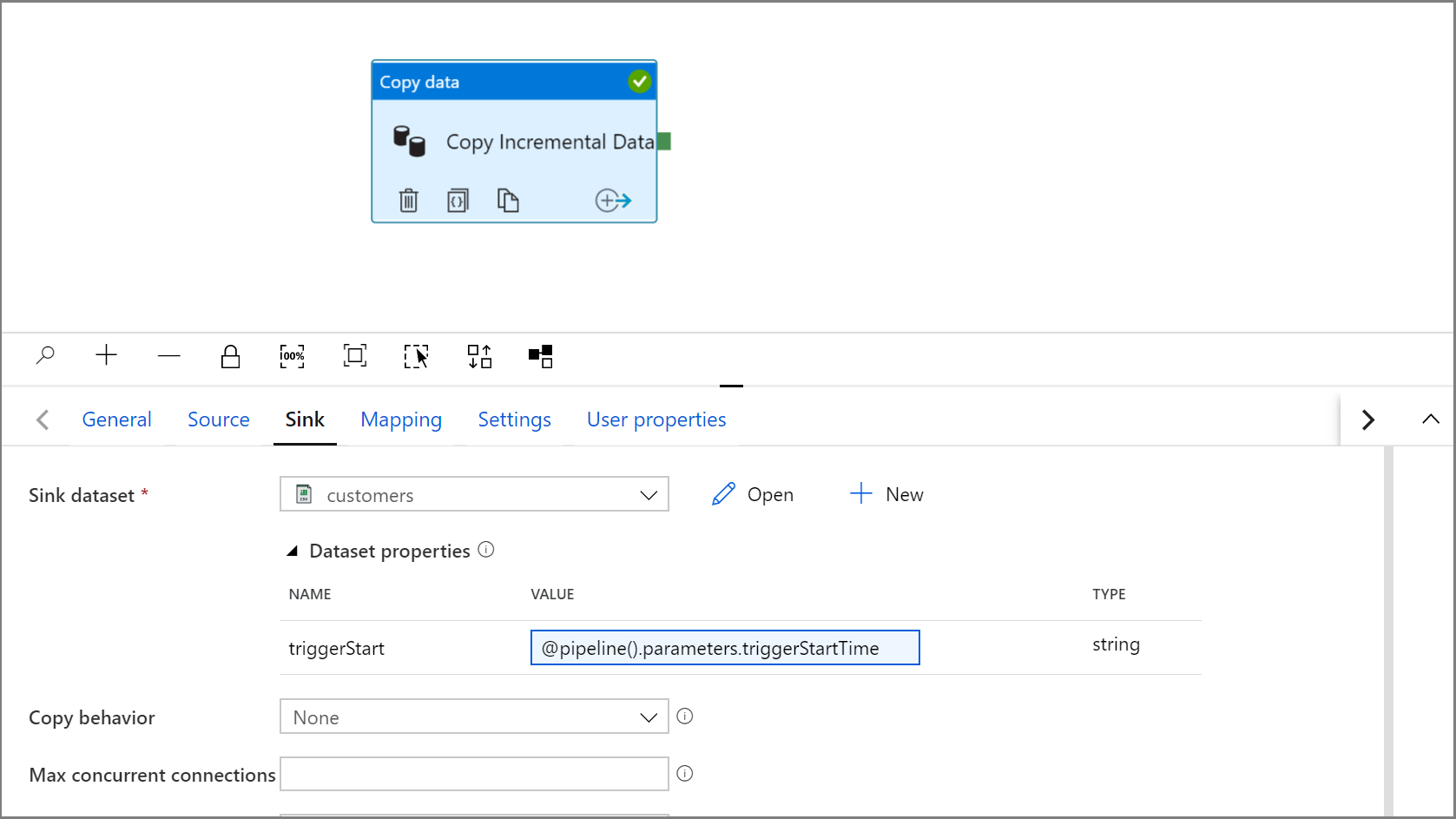
Kliknutím na kartu IncrementalCopyPipeline přejděte zpět do nastavení jímky v aktivitě kopírování.
Rozbalte vlastnosti datové sady a zadejte dynamický obsah do hodnoty parametru triggerStart s následujícím výrazem:
@pipeline().parameters.triggerStartTime
Kliknutím na Ladit otestujete kanál a zajistíte, že se struktura složek a výstupní soubor vygenerují podle očekávání. Stáhněte a otevřete soubor a ověřte jeho obsah.
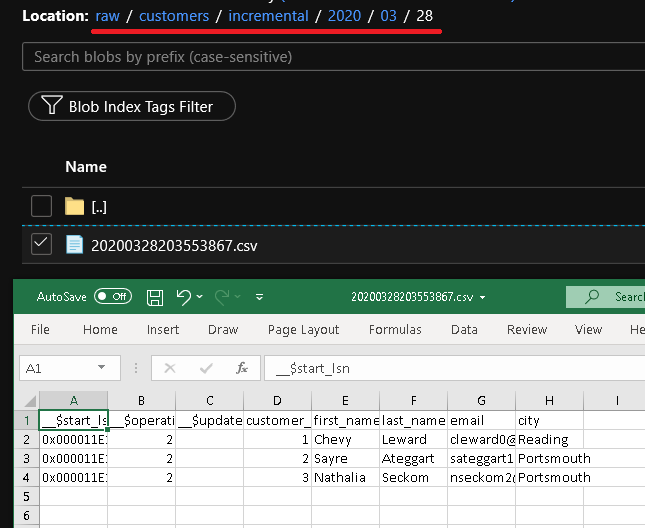
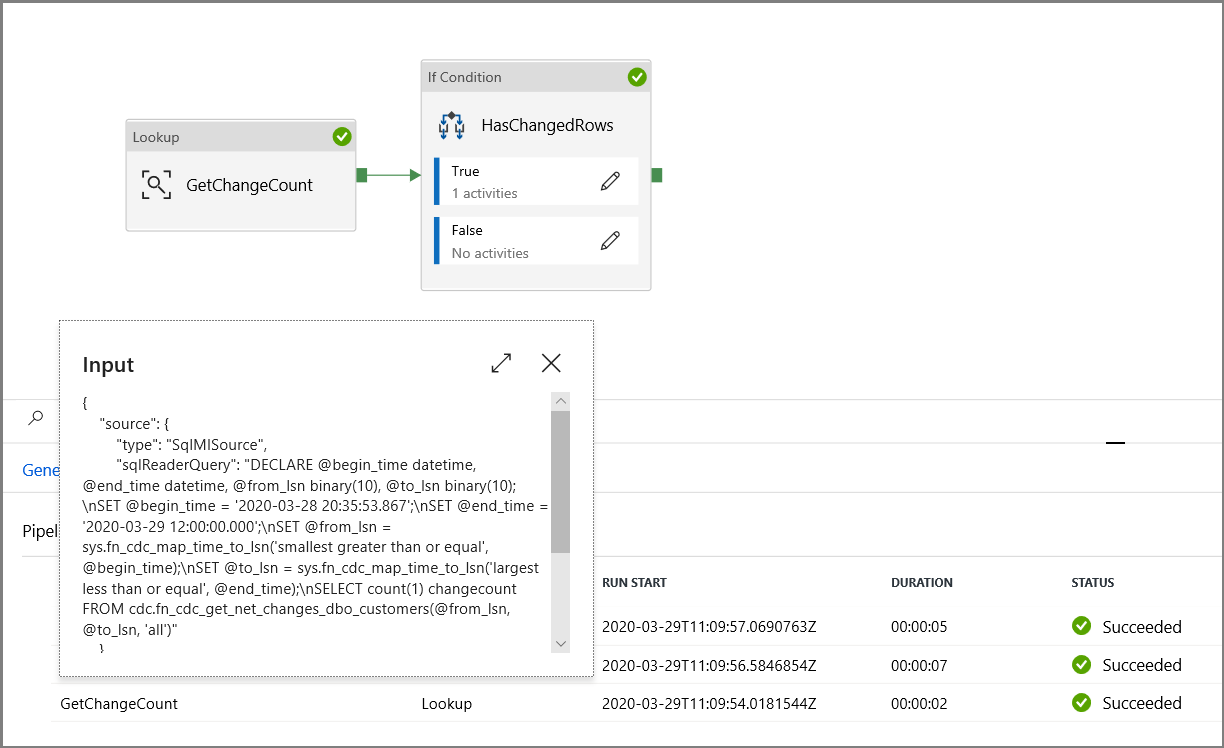
Zkontrolujte vstupní parametry spuštění kanálu.
Kliknutím na tlačítko Publikovat vše publikujte entity (propojené služby, datové sady a kanály) do služby Data Factory. Počkejte, dokud se nezobrazí zpráva Publikování proběhlo úspěšně.
Nakonec nakonfigurujte trigger pro přeskakující okno tak, aby se kanál spustil v pravidelných intervalech a nastavil parametry počátečního a koncového času.
- Klikněte na tlačítko Přidat trigger a vyberte Nový/Upravit.
- Zadejte název triggeru a zadejte počáteční čas, který se rovná koncovému času okna ladění výše.
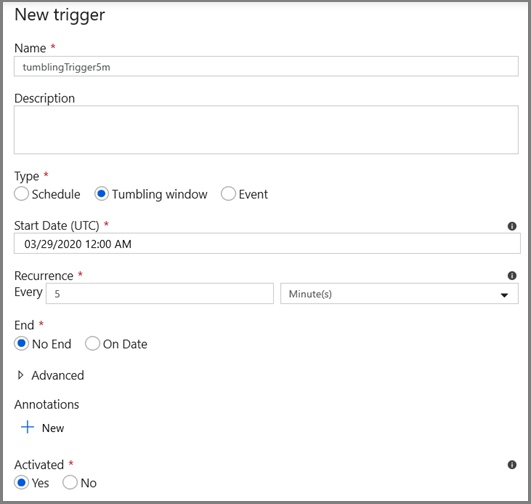
Na další obrazovce zadejte následující hodnoty pro počáteční a koncové parametry.
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')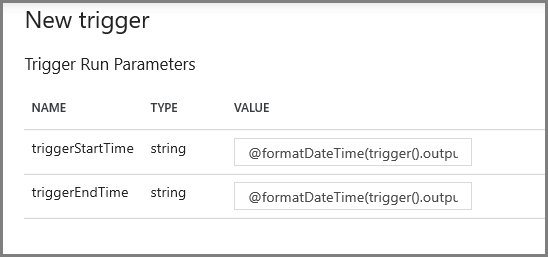
Poznámka:
Trigger se spustí jenom po publikování. Kromě toho očekávané chování přeskakujícího okna je spustit všechny historické intervaly od data zahájení až do této chvíle. Další informace o aktivačních událostech pro přeskakující okno najdete tady.
Pokud používáte SQL Server Management Studio , proveďte některé další změny tabulky zákazníků spuštěním následujícího SQL:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Klikněte na tlačítko Publikovat vše . Počkejte, dokud se nezobrazí zpráva Publikování proběhlo úspěšně.
Po několika minutách se kanál aktivuje a do Azure Storage se načte nový soubor.
Monitorování kanálu přírůstkového kopírování
Klikněte na kartu Monitorování na levé straně. V seznamu se zobrazí spuštění kanálu a jeho stav. Pokud chcete seznam aktualizovat, klikněte na Aktualizovat. Najetí myší na název kanálu pro přístup k akci Znovu spustit a sestavu Consumption
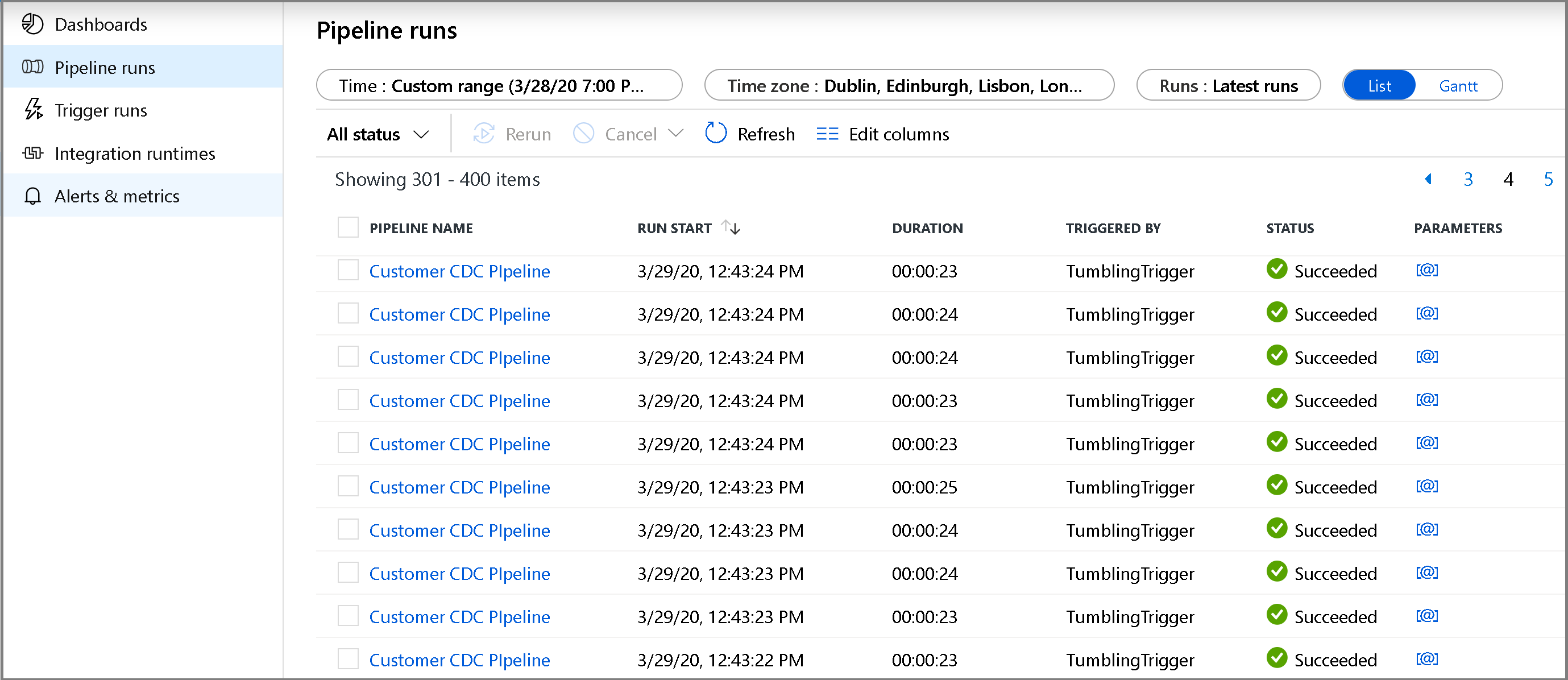
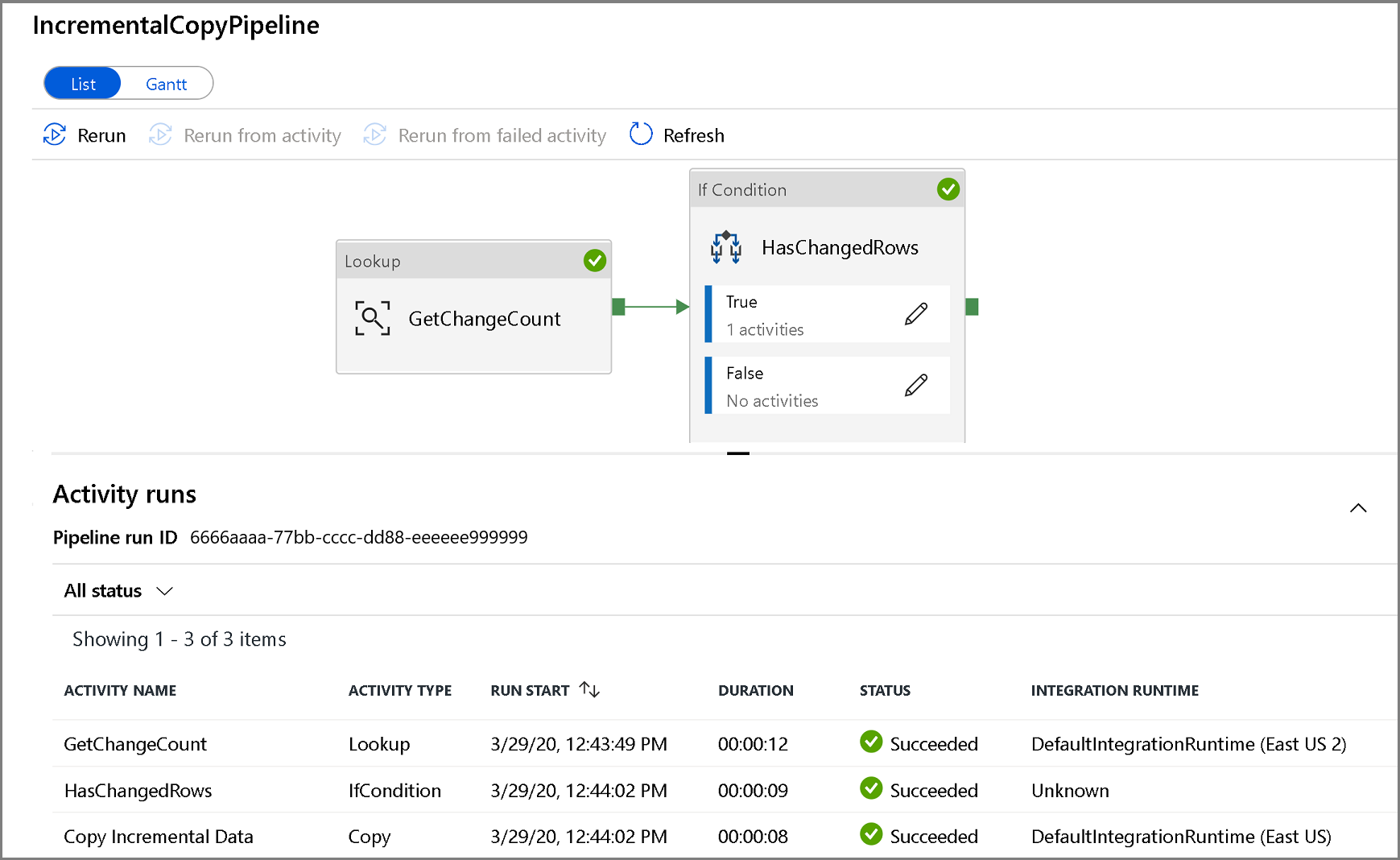
Pokud chcete zobrazit spuštění aktivit související se spuštěním kanálu, klikněte na název kanálu. Pokud byla zjištěna změněná data, budou existovat tři aktivity, včetně aktivity kopírování, jinak budou v seznamu pouze dvě položky. Pokud chcete přepnout zpět do zobrazení spuštění kanálu, klikněte v horní části na odkaz Všechny kanály .
Kontrola výsledků
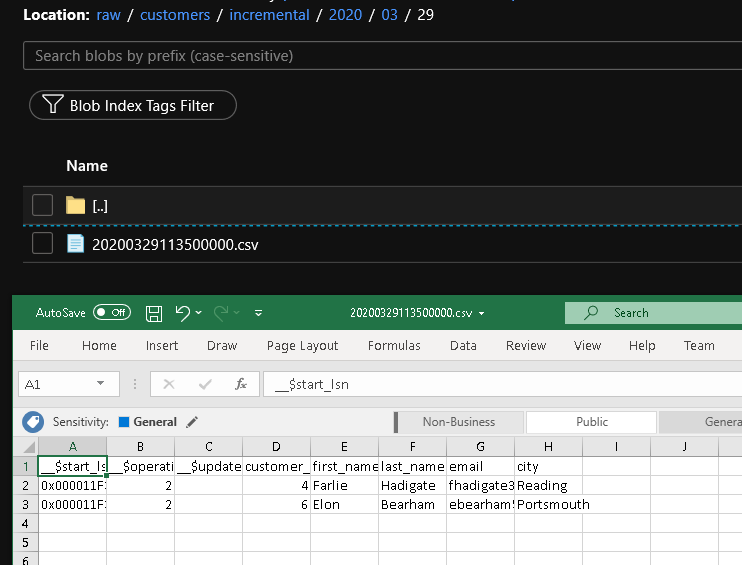
Ve složce customers/incremental/YYYY/MM/DD kontejneru raw uvidíte druhý soubor.
Související obsah
V následujícím kurzu se dozvíte, jak kopírovat nové a změněné soubory jenom na základě jejich lastModifiedDate: