Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
VZTAHUJE SE NA: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
V tomto kurzu vytvoříte Azure Data Factory s datovým tokem, který načítá rozdílová data na základě sledování změn ve zdrojové databázi v Azure SQL databázi do úložiště objektů blob Azure.
V tomto kurzu provedete následující kroky:
- Příprava zdrojového úložiště dat
- Vytvoření datové továrny
- Vytvoření propojených služeb
- Vytvoření datových sad pro zdroj, jímku a sledování změn
- Vytvořte, spusťte a monitorujte proces úplného kopírování
- Přidání nebo aktualizace dat ve zdrojové tabulce
- Vytvořte, spusťte a sledujte přírůstkový kopírovací datový tok
Poznámka:
K interakci s Azure doporučujeme použít modul Azure Az PowerShell. Pokud chcete začít, přečtěte si téma Install Azure PowerShell. Informace o migraci do modulu Az PowerShell najdete v tématu Migrace Azure PowerShell z AzureRM do Az.
Přehled
V řešení integrace dat je přírůstkové načítání dat po počátečním načtení dat často používaný scénář. V některých případech lze změněné údaje ve vašem zdrojovém úložišti za určité období snadno rozdělit (například LastModifyTime, CreationTime). V některých případech ale neexistuje žádný explicitní způsob identifikace rozdílových dat od posledního zpracování dat. Pro identifikaci rozdílových dat může být použita technologie sledování změn (Change Tracking), kterou podporují úložiště dat, jako jsou Azure SQL Database a SQL Server. Tento kurz popisuje, jak používat Azure Data Factory s technologií SQL Change Tracking pro načítání přírůstků dat z Azure SQL Database do Azure Blob Storage. Další konkrétní informace o technologii SQL Change Tracking najdete v tématu Change tracking v SQL Server.
Kompletní pracovní tok
Tady jsou obvyklé kroky uceleného pracovního postupu pro přírůstkové načtení dat s využitím technologie Change Tracking.
Poznámka:
Technologie Change Tracking podporují Azure SQL Database i SQL Server. Tento kurz používá Azure SQL Database jako zdrojové úložiště dat. Můžete také použít instanci SQL Server.
-
Počáteční načítání historických dat (spustit jednou):
- Povolte technologii Change Tracking ve zdrojové databázi v Azure SQL Database.
- Získat počáteční hodnotu SYS_CHANGE_VERSION v databázi jako základ pro zachycení změněných dat.
- Načtěte úplná data ze zdrojové databáze do úložiště Azure Blob.
-
Přírůstkové načítání rozdílových dat podle plánu (spouští se pravidelně po počátečním načítání dat):
- Získejte starou a novou hodnotu SYS_CHANGE_VERSION.
- Načtěte rozdílová data spojením primárních klíčů změněných řádků (mezi dvěma hodnotami SYS_CHANGE_VERSION) ze sys.change_tracking_tables s daty ve zdrojové tabulce a potom přesuňte rozdílová data do cílového umístění.
- Aktualizujte SYS_CHANGE_VERSION pro příští načítání delty.
Řešení na nejvyšší úrovni
V tomto kurzu vytvoříte dva kanály, které provádějí následující dvě operace:
Initial load: vytvoříte kanál s aktivitou kopírování, která kopíruje celá data ze zdrojového úložiště dat (Azure SQL Database) do cílového úložiště dat (Azure Blob Storage).

Přírůstkové načtení: Vytvoříte kanál s následujícími aktivitami a pravidelně ho budete spouštět.
- Vytvořte dvě vyhledávací aktivity, abyste získali staré a nové SYS_CHANGE_VERSION z Azure SQL Database a předali je aktivitě kopírování.
- Vytvořte onovou aktivitu kopírování a zkopírujte vložená/aktualizovaná/odstraněná data mezi dvěma SYS_CHANGE_VERSION hodnotami z Azure SQL Database do Azure Blob Storage.
- Vytvořte jednu činnost uložené procedury pro aktualizaci hodnoty SYS_CHANGE_VERSION pro další spuštění potrubí.

Pokud nemáte předplatné Azure, vytvořte si účet free před tím, než začnete.
Požadavky
- Azure PowerShell. Nainstalujte nejnovější moduly Azure PowerShell podle pokynů v Jak nainstalovat a nakonfigurovat Azure PowerShell.
- Azure SQL Database. Tuto databázi použijete jako zdrojové úložiště dat. Pokud v Azure SQL Database nemáte databázi, přečtěte si článek Vytvoření databáze v článku Azure SQL Database pokyny k jeho vytvoření.
- Účet služby Azure Storage. Úložiště objektů blob použijete jako konečné úložiště dat. Pokud účet úložiště Azure nemáte, přečtěte si článek Vytvoření účtu úložiště článek s pokyny k jeho vytvoření. Vytvořte kontejner s názvem adftutorial.
Vytvoření tabulky zdroje dat v databázi
Spusťte SQL Server Management Studio a připojte se ke službě SQL Database.
V Průzkumníku serveru klikněte pravým tlačítkem na databázi a potom zvolte Nový dotaz.
Spuštěním následujícího příkazu SQL pro vaši databázi vytvořte tabulku pojmenovanou
data_source_tablejako úložiště zdrojů dat.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Povolte mechanismus Change Tracking pro vaši databázi a zdrojovou tabulku (data_source_table) spuštěním následujícího příkazu SQL:
Poznámka:
- Nahraďte <název vaší databáze> názvem své databáze, která obsahuje data_source_table.
- V uvedeném příkladě se změněná data uchovávají po dobu dvou dnů. Pokud načtete změněná data vždy po třech nebo více dnech, některá změněná data nejsou zahrnuta. Musíte buď změnit hodnotu CHANGE_RETENTION na větší číslo. Další možností je zajistit, že interval načítání změněných dat spadá do dvou dnů. Další informace najdete v tématu věnovaném povolení sledování změn pro databázi.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Vytvořte novou tabulku a uložte ChangeTracking_version s výchozí hodnotou spuštěním následujícího dotazu:
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Poznámka:
Pokud se data po povolení sledování změn pro SQL Database nezmění, hodnota verze sledování změn je 0.
Spuštěním následujícího dotazu vytvořte uloženou proceduru v databázi. Kanál vyvolá tuto uloženou proceduru pro aktualizaci verze sledování změn v tabulce, kterou jste vytvořili v předchozím kroku.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Nainstalujte nejnovější moduly Azure PowerShell podle pokynů v Jak nainstalovat a nakonfigurovat Azure PowerShell.
Vytvoření datové továrny
Definujte proměnnou pro název skupiny prostředků, kterou použijete později v příkazech PowerShellu. Zkopírujte následující text příkazu do PowerShellu, zadejte název skupiny prostředků Azure v dvojitých uvozovkách a spusťte příkaz. Například:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Pokud již skupina prostředků existuje, nemusíte ji chtít přepsat. Přiřaďte proměnné
$resourceGroupNamejinou hodnotu a spusťte tento příkaz znovu.Definujte proměnnou pro umístění datové továrny:
$location = "East US"Pokud chcete vytvořit skupinu prostředků Azure, spusťte následující příkaz:
New-AzResourceGroup $resourceGroupName $locationPokud již skupina prostředků existuje, nemusíte ji chtít přepsat. Přiřaďte proměnné
$resourceGroupNamejinou hodnotu a spusťte tento příkaz znovu.Definujte proměnnou pro název datové továrny.
Důležité
Aktualizujte název datové továrny tak, aby byl globálně jedinečný.
$dataFactoryName = "IncCopyChgTrackingDF";Pokud chcete vytvořit datovou továrnu, spusťte následující rutinu Set-AzDataFactoryV2 :
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Mějte na paměti následující body:
Název Azure datové továrny musí být globálně jedinečný. Pokud se zobrazí následující chyba, změňte název a zkuste to znovu.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Pokud chcete vytvořit instance služby Data Factory, účet uživatele, kterého používáte k přihlášení do Azure, musí být členem role contributor nebo owner, nebo členem role administrator předplatného Azure.
Seznam Azure oblastí, ve kterých je služba Data Factory aktuálně dostupná, vyberte oblasti, které vás zajímají, na následující stránce a rozbalte Analytics a vyhledejte Data Factory: Products available by region. Úložiště dat (Azure Storage, Azure SQL Database atd.) a výpočty (HDInsight atd.) používané datovými továrnami můžou být v jiných oblastech.
Vytvoření propojených služeb
V datové továrně vytvoříte propojené služby, abyste svá úložiště dat a výpočetní služby spojili s datovou továrnou. V této části vytvoříte propojené služby s vaším účtem Azure Storage a databází v Azure SQL Database.
Vytvoření propojené služby Azure Storage
V tomto kroku propojíte svůj účet Azure Storage s datovou továrnou.
Vytvořte soubor JSON s názvem AzureStorageLinkedService.json ve složce C:\ADFTutorials\IncCopyChangeTrackingTutorial s následujícím obsahem. (Pokud tato složka ještě neexistuje, vytvořte ji.) Před uložením souboru nahraďte
<accountName>,<accountKey>názvem a klíčem účtu úložiště Azure.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }V Azure PowerShell přepněte do složky C:\ADFTutorials\IncCopyChangeTrackingTutorial.
Spuštěním rutiny Set-AzDataFactoryV2LinkedService vytvořte propojenou službu AzureStorageLinkedService. V následujícím příkladu předáte hodnoty pro parametry ResourceGroupName a DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Tady je ukázkový výstup:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Vytvoření propojené služby Azure SQL Database
V tomto kroku propojíte databázi s datovou továrnou.
Vytvořte soubor JSON s názvem AzureSQLDatabaseLinkedService.json ve složce C:\ADFTutorials\IncCopyChangeTrackingTutorial následujícím obsahem: Před uložením souboru nahraďte <název> serveru a <> databáze názvem vašeho serveru a databáze. cs-CZ: Musíte také nakonfigurovat Azure SQL Server tak, aby udělil přístup ke spravované identitě vaší datové továrny.
{ "name": "AzureSqlDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server=tcp:<your-server-name>.database.windows.net,1433;Database=<your-database-name>;" }, "authenticationType": "ManagedIdentity", "annotations": [] } }V Azure PowerShell spusťte rutinu Set-AzDataFactoryV2LinkedService a vytvořte propojenou službu: AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Tady je ukázkový výstup:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Vytvoření datových sad
V tomto kroku vytvoříte datové sady, které reprezentují zdroj a cíl dat a místo pro uložení SYS_CHANGE_VERSION.
Vytvoření zdrojové datové sady
V tomto kroku vytvoříte datovou sadu pro reprezentaci zdrojových dat.
Ve stejné složce vytvořte soubor JSON s názvem SourceDataset.json a s následujícím obsahem:
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Spuštěním rutiny Set-AzDataFactoryV2Dataset vytvořte datovou sadu: SourceDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Zde je ukázkový výstup z tohoto cmdletu:
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Vytvoření datové sady jímky
V tomto kroku vytvoříte datovou sadu pro reprezentaci dat, která se kopírují ze zdrojového úložiště dat.
Ve stejné složce vytvořte soubor JSON s názvem SinkDataset.json a s následujícím obsahem:
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }Kontejner adftutorial vytvoříte v Azure Blob Storage jako součást požadavků. Pokud tento kontejner neexistuje, vytvořte ho nebo použijte název existujícího kontejneru. V tomto kurzu se název výstupního souboru dynamicky generuje pomocí výrazu: '@CONCAT(Incremental-', pipeline().RunId, '.txt').
Spuštěním rutiny Set-AzDataFactoryV2Dataset vytvořte datovou sadu: SinkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Zde je ukázkový výstup z tohoto cmdletu:
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Vytvoření datové sady sledování změn
V tomto kroku vytvoříte datovou sadu pro uložení verze sledování změn.
Ve stejné složce vytvořte soubor JSON s názvem ChangeTrackingDataset.json a s následujícím obsahem:
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Jako součást požadavků vytvoříte tabulku table_store_ChangeTracking_version.
Spuštěním rutiny Set-AzDataFactoryV2Dataset vytvořte datovou sadu: ChangeTrackingDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Zde je ukázkový výstup z tohoto cmdletu:
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Vytvořte potrubí pro úplné kopírování
V tomto kroku vytvoříte kanál s aktivitou kopírování, která kopíruje celá data ze zdrojového úložiště dat (Azure SQL Database) do cílového úložiště dat (Azure Blob Storage).
Ve stejné složce vytvořte soubor JSON s názvem FullCopyPipeline.json a s následujícím obsahem:
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Spuštěním rutiny Set-AzDataFactoryV2Pipeline vytvořte kanál: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Tady je ukázkový výstup:
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Spustit celý proces kopírování
Spusťte kanál: FullCopyPipeline pomocí rutiny Invoke-AzDataFactoryV2Pipeline .
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Sledujte celkový proces kopírování
Přihlaste se k portálu Azure.
Klikněte na Všechny služby, spusťte hledání pomocí klíčového slova
data factoriesa vyberte Datové továrny.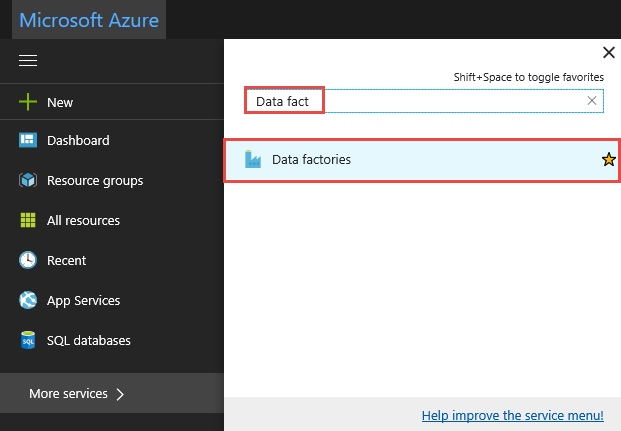
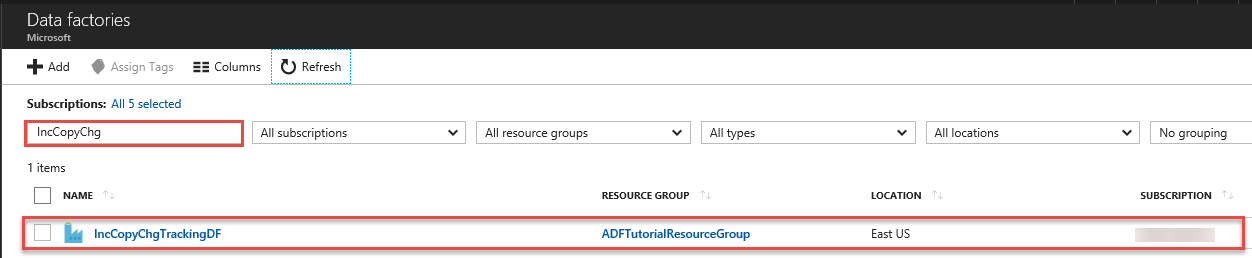
V seznamu datových továren vyhledejte vaši datovou továrnu a vyberte ji, spustí se stránka Datová továrna.
Na stránce Data Factory klikněte na dlaždici
Monitor & Manage .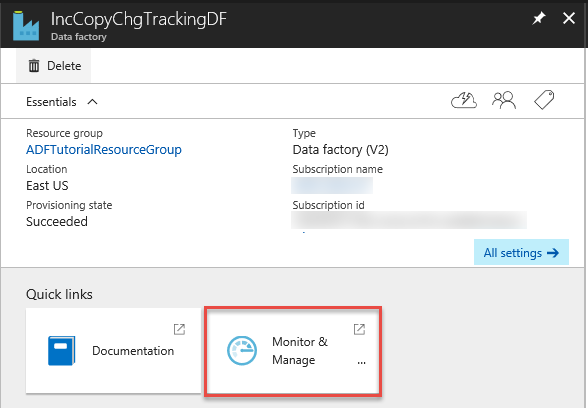
Aplikace Integrace dat se spustí na samostatné kartě. Zobrazí se všechny běhy pipeline a jejich stavy. Všimněte si, že stav spuštění kanálu v následujícím příkladu je Úspěšně. Parametry předané kanálu můžete zkontrolovat kliknutím na sloupec Parametry. Pokud došlo k chybě, zobrazí se odkaz ve sloupci Chyba. Klikněte na odkaz ve sloupci Akce.
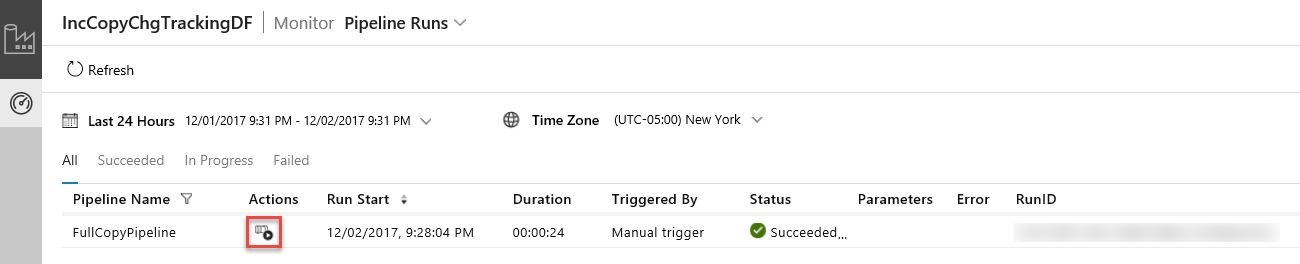
Po kliknutí na odkaz ve sloupci Akce uvidíte následující stránku, která zobrazuje všechna spuštění aktivit pro příslušný kanál.
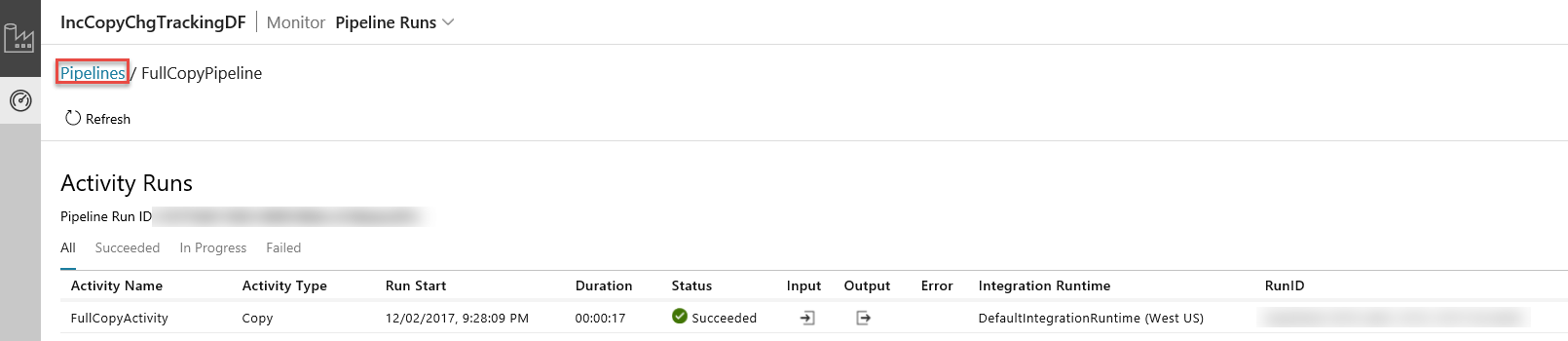
Pokud chcete přejít zpátky k zobrazení Kanálů, klikněte na Kanály, jak je ukázáno na obrázku.
Kontrola výsledků
Ve složce incremental-<GUID>.txt kontejneru incchgtracking uvidíte soubor s názvem adftutorial.
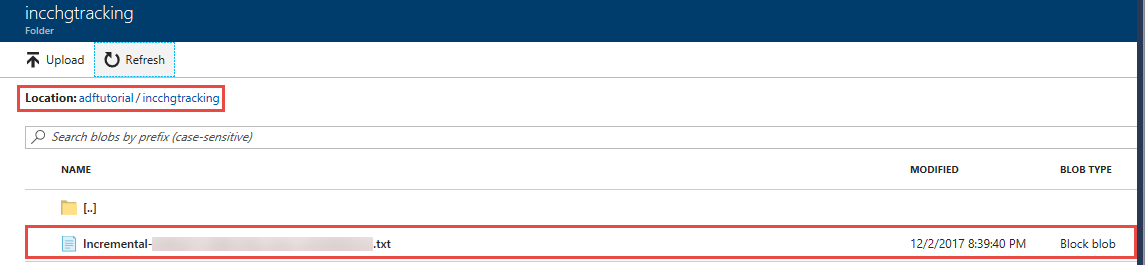
Soubor by měl obsahovat data z vaší databáze:
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Přidání dalších dat do zdrojové tabulky
Spuštěním následujícího dotazu na databázi přidejte řádek a aktualizujte řádek.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Vytvoření pracovního postupu pro delta kopírování
V tomto kroku vytvoříte kanál s následujícími aktivitami a pravidelně ho budete spouštět. Vyhledávací aktivity získávají staré a nové hodnoty SYS_CHANGE_VERSION z Azure SQL Database a předávají je aktivitě kopírování. Aktivita copy zkopíruje vložená/aktualizovaná/odstraněná data mezi dvěma hodnotami SYS_CHANGE_VERSION z Azure SQL Database do Azure Blob Storage. Aktivita uložených procedur aktualizuje hodnotu SYS_CHANGE_VERSION pro další spuštění kanálu.
Ve stejné složce vytvořte soubor JSON s názvem IncrementalCopyPipeline.json a s následujícím obsahem:
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Spuštěním rutiny Set-AzDataFactoryV2Pipeline vytvořte kanál: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Tady je ukázkový výstup:
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
Spuštění kanálu přírůstkového kopírování
Spusťte datový kanál: IncrementalCopyPipeline pomocí rutiny Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorujte tok přírůstkového kopírování
V aplikaci pro integraci dat aktualizujte zobrazení provozy kanálu. Zkontrolujte, že se v tomto seznamu zobrazuje IncrementalCopyPipeline. Klikněte na odkaz ve sloupci Akce.
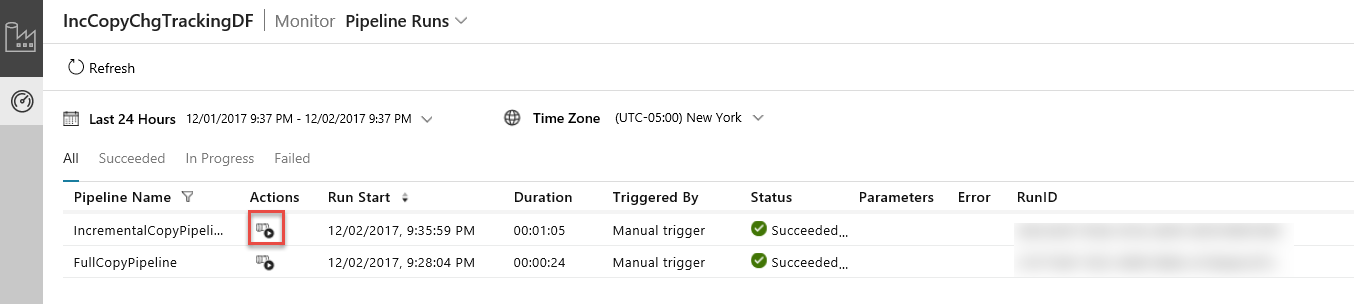
Po kliknutí na odkaz ve sloupci Akce uvidíte následující stránku, která zobrazuje všechna spuštění aktivit pro příslušný kanál.
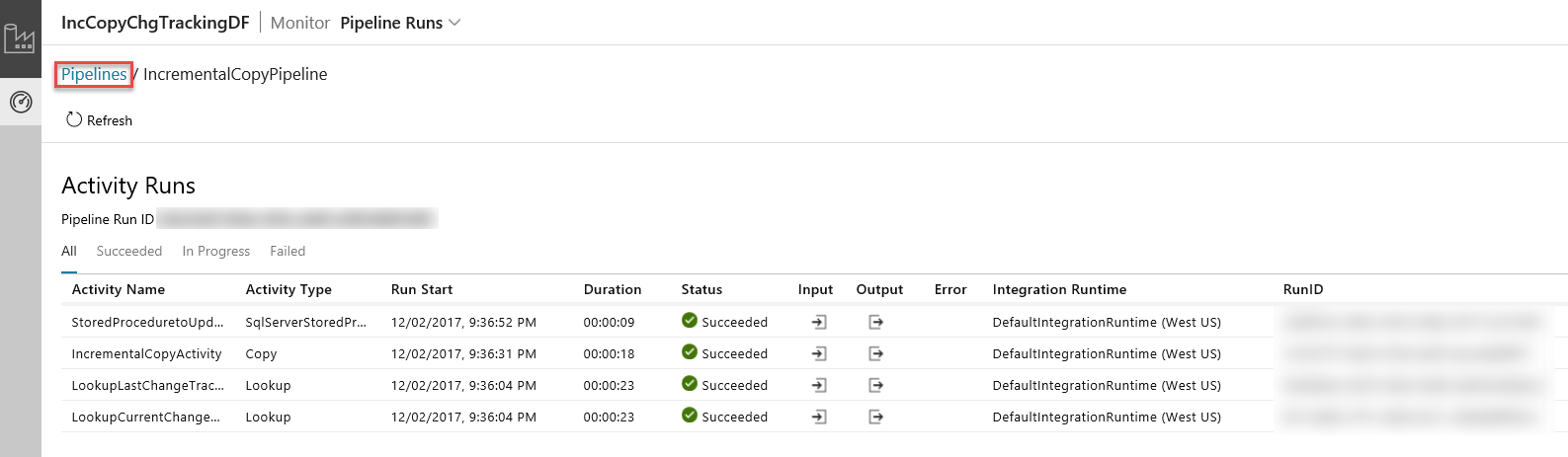
Pokud chcete přejít zpátky k zobrazení Kanálů, klikněte na Kanály, jak je ukázáno na obrázku.
Kontrola výsledků
Ve složce incchgtracking kontejneru adftutorial uvidíte druhý soubor.
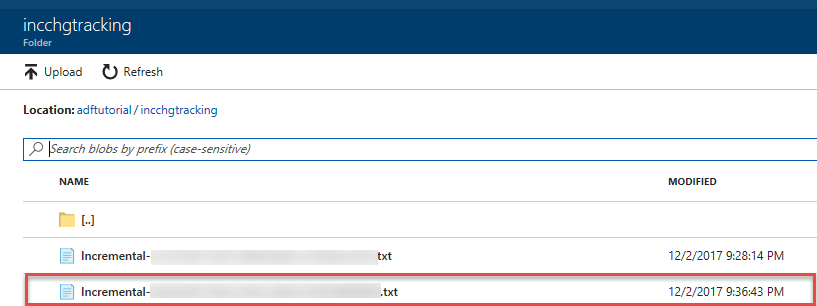
Soubor by měl obsahovat pouze rozdílová data z vaší databáze. Záznam s U je aktualizovaný řádek v databázi a I je přidaný řádek.
1,update,10,2,U
6,new,50,1,I
První tři sloupce představují změněná data z data_source_table. Poslední dva sloupce jsou metadata ze systémové tabulky sledování změn. Čtvrtý sloupec je SYS_CHANGE_VERSION pro každý změněný řádek. Pátý řádek představuje operaci: U = aktualizace, I = vložení. Podrobné informace o sledování změn najdete v tématu CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Související obsah
V následujícím kurzu se dozvíte, jak kopírovat nové a změněné soubory jenom na základě jejich lastModifiedDate: