Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
VZTAHUJE SE NA: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
V tomto kurzu vytvoříte Azure Data Factory s datovým kanálem, který načte delta data z více tabulek v databázi SQL Serveru do Azure SQL Database.
V tomto kurzu provedete následující kroky:
- Příprava zdrojového a cílového datového úložiště
- Vytvoření datové továrny
- Vytvořte místní prostředí Integration Runtime.
- Instalace prostředí Integration Runtime
- Vytvoření propojených služeb
- Vytvořte zdroj, úložiště a datové sady s vodoznakem.
- Vytvoření a spuštění kanálu a jeho monitorování
- Zkontrolujte výsledky.
- Přidání nebo aktualizace dat ve zdrojových tabulkách
- Opakované spuštění kanálu a jeho monitorování
- Kontrola konečných výsledků
Přehled
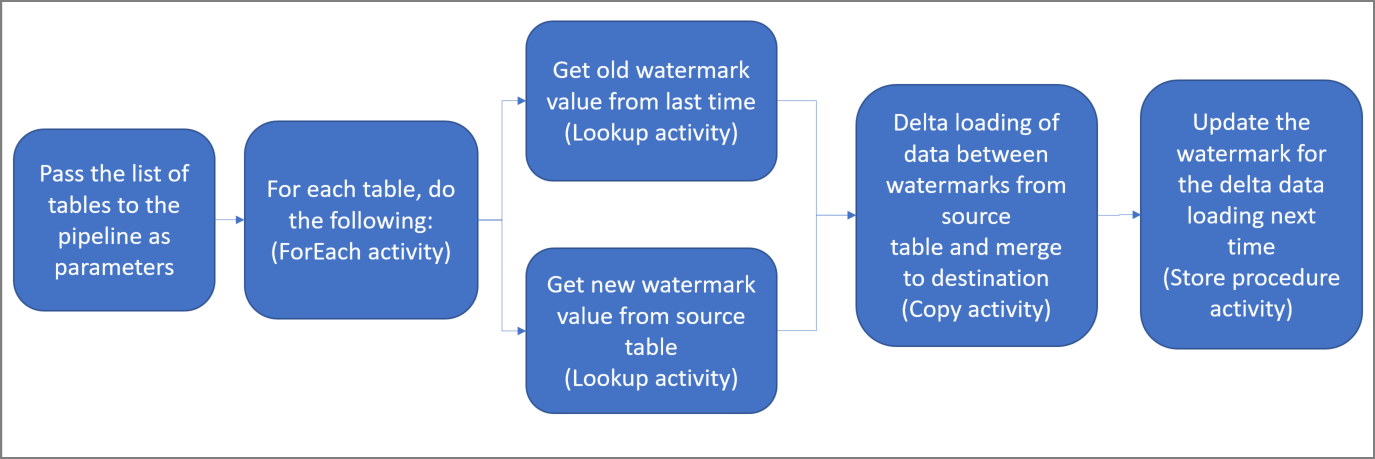
Tady jsou důležité kroky pro vytvoření tohoto řešení:
Vyberte sloupec vodoznaku.
Vyberte jeden sloupec pro každou tabulku ve zdrojovém úložišti dat, které můžete identifikovat nové nebo aktualizované záznamy pro každé spuštění. Data v tomto vybraném sloupci (například čas_poslední_změny nebo ID) se při vytváření nebo aktualizaci řádků obvykle zvyšují. Maximální hodnota v tomto sloupci se používá jako horní mez.
Připravte úložiště dat pro uložení hodnoty vodotisku.
V tomto kurzu uložíte hodnotu vodoznaku do databáze SQL.
Vytvořte kanál s následujícími aktivitami:
Vytvořte aktivitu ForEach, která prochází seznam názvů zdrojových tabulek, který je předán jako parametr do pipeline. Pro každou zdrojovou tabulku vyvolá následující aktivity, aby pro tabulku provedl nahrání změn.
Vytvořte dvě aktivity vyhledávání. První aktivitu vyhledávání použijte k načtení poslední hodnoty vodotisku. Druhou aktivitu vyhledávání použijte k načtení nové hodnoty vodítka. Tyto hodnoty vodoznaku se předávají kopírovací aktivitě.
Vytvořte Copy activity, která kopíruje řádky ze zdrojového úložiště dat s hodnotou sloupce vodoznaku větší než stará hodnota vodoznaku a menší nebo rovna nové hodnotě vodoznaku. Potom zkopíruje rozdílová data ze zdrojového úložiště dat do Azure Blob Storage jako nový soubor.
Vytvořte aktivitu typu StoredProcedure, která aktualizuje hodnotu ukazatele pro další spuštění pipeline.
Tady je souhrnný diagram tohoto řešení:
Pokud nemáte předplatné Azure, vytvořte si účet free před tím, než začnete.
Požadavky
- SQL Server. Jako zdrojové úložiště dat v tomto kurzu použijete databázi SQL Server.
- Azure SQL Database. Jako úložiště dat jímky použijete databázi v Azure SQL Database. Pokud databázi SQL nemáte, přečtěte si téma Vytvoření databáze v Azure SQL Database postup vytvoření databáze.
Vytváření zdrojových tabulek v databázi SQL Server
Otevřete SQL Server Management Studio (SSMS) nebo Visual Studio Code a připojte se k databázi SQL Server.
V Server Explorer (SSMS) nebo v podokně Pojení (Visual Studio Code) klikněte pravým tlačítkem myši na databázi a zvolte New Query.
Spusťte na databázi následující příkaz SQL, aby se vytvořily tabulky s názvem
customer_tableaproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Vytváření cílových tabulek v Azure SQL Database
Otevřete SQL Server Management Studio (SSMS) nebo Visual Studio Code a připojte se k databázi SQL Server.
V Server Explorer (SSMS) nebo v podokně Pojení (Visual Studio Code) klikněte pravým tlačítkem myši na databázi a zvolte New Query.
Spusťte na databázi následující příkaz SQL, aby se vytvořily tabulky s názvem
customer_tableaproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Vytvoření další tabulky v Azure SQL Database pro uložení hodnoty horní meze
Spuštěním následujícího příkazu SQL pro vaši databázi vytvořte tabulku s názvem
watermarktablepro uložení hodnoty meze:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Do tabulky mezí vložte hodnoty počátečních mezí pro obě zdrojové tabulky.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Vytvoření uložené procedury v Azure SQL Database
Spuštěním následujícího příkazu vytvořte uloženou proceduru v databázi. Tato uložená procedura aktualizuje hodnotu vodotisku po každém spuštění pipeline.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Vytváření datových typů a dalších uložených procedur v Azure SQL Database
Spuštěním následujícího dotazu vytvořte ve své databázi dvě uložené procedury a dva datové typy. Slouží ke slučování dat ze zdrojových tabulek do cílových tabulek.
Aby byla cesta co nejjednodušší již na začátku, přímo používáme tyto uložené procedury, které předávají rozdílová data prostřednictvím proměnné tabulky, a poté je sloučíme do cílového úložiště. Dávejte pozor, aby nebyl očekáván značný počet rozdílových řádků (více než 100) k uložení v tabulkové proměnné.
Pokud potřebujete sloučit velký počet rozdílových řádků do cílového úložiště, doporučujeme použít kopírovací aktivitu ke zkopírování všech rozdílových dat nejprve do dočasné "přípravné" tabulky v cílovém úložišti a pak vytvořte vlastní uložený postup bez použití proměnné tabulky ke sloučení z "přípravné" tabulky do "konečné" tabulky.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
Nainstalujte nejnovější moduly Azure PowerShell podle pokynů v Install a nakonfigurujte Azure PowerShell.
Vytvoření datové továrny
Definujte proměnnou pro název skupiny prostředků, kterou použijete později v příkazech PowerShellu. Zkopírujte následující text příkazu do PowerShellu, zadejte název skupiny prostředků Azure v uvozovkách a spusťte příkaz. Příklad:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Pokud již skupina prostředků existuje, možná nebudete chtít ji přepsat. Přiřaďte proměnné
$resourceGroupNamejinou hodnotu a spusťte tento příkaz znovu.Definujte proměnnou pro umístění datové továrny.
$location = "East US"Pokud chcete vytvořit skupinu prostředků Azure, spusťte následující příkaz:
New-AzResourceGroup $resourceGroupName $locationPokud již skupina prostředků existuje, možná nebudete chtít ji přepsat. Přiřaďte proměnné
$resourceGroupNamejinou hodnotu a spusťte tento příkaz znovu.Definujte proměnnou název datové továrny.
Důležité
Aktualizujte název továrny dat tak, aby byl jedinečný na celém světě. Příklad: ADFIncMultiCopyTutorialFactorySP1127.
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";Pokud chcete vytvořit datovou továrnu, spusťte následující rutinu Set-AzDataFactoryV2 :
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Mějte na paměti následující body:
Název datové továrny musí být globálně jedinečný. Pokud se zobrazí následující chyba, změňte název a zkuste to znovu:
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Aby bylo možné vytvářet instance služby Data Factory, uživatelský účet, který používáte k přihlášení k Azure, musí být členem role přispěvatele nebo vlastníka nebo správcem Azure předplatného.
Seznam Azure oblastí, ve kterých je služba Data Factory aktuálně dostupná, vyberte oblasti, které vás zajímají, na následující stránce a rozbalte Analytics a vyhledejte Data Factory: Products available by region. Úložiště dat (Azure Storage, SQL Database, SQL Managed Instance atd.) a výpočty (Azure HDInsight atd.) používané datová továrnou můžou být v jiných oblastech.
Vytvoření vlastního prostředí pro Integration Runtime
V této části vytvoříte místní prostředí Integration Runtime a přidružíte ho k místnímu počítači s SQL Server databází. Vlastní hostované Integration Runtime je komponenta, která kopíruje data ze SQL serveru na vašem počítači do Azure SQL Database.
Vytvořte proměnnou pro název prostředí Integration Runtime. Použijte jedinečný název a poznamenejte si ho. Použijete ho později v tomto kurzu.
$integrationRuntimeName = "ADFTutorialIR"Vytvořte místní prostředí Integration Runtime.
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupNameTady je ukázkový výstup:
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIRPokud chcete načíst stav vytvořeného prostředí Integration Runtime, spusťte následující příkaz. Potvrďte, že hodnota vlastnosti State je nastavena na NeedRegistration.
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusTady je ukázkový výstup:
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>Pokud chcete načíst ověřovací klíče použité k registraci místního prostředí Integration Runtime ve službě Azure Data Factory v cloudu, spusťte následující příkaz:
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonTady je ukázkový výstup:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }Pro registraci místního prostředí Integration Runtime, které nainstalujete na počítači v dalších krocích, zkopírujte jeden z klíčů (bez uvozovek).
Instalace nástroje Integration Runtime
Pokud již na počítači máte prostředí Integration Runtime, odinstalujte ho pomocí panelu Přidat nebo odebrat programy.
Download místní prostředí Integration Runtime na místním počítači Windows. Spusťte instalaci.
Na stránce Vítejte v nastavení Microsoft Integration Runtime vyberte Další.
Na stránce Licenční smlouva s koncovým uživatelem (EULA) přijměte podmínky a licenční smlouvu a vyberte Další.
Na stránce Cílová složka vyberte Další.
Na stránce Ready pro instalaci Microsoft Integration Runtime vyberte Install.
Na stránce Dokončení instalace prostředí Microsoft Integration Runtime vyberte Dokončit.
Na stránce Registrace Integration Runtime (v místním prostředí) vložte klíč, který jste uložili v předchozí části, a vyberte Registrovat.
Na stránce Nový Integration Runtime (místní) uzel vyberte Dokončit.
Po úspěšném dokončení registrace místního prostředí Integration Runtime se zobrazí následující zpráva:
Na stránce Register Integration Runtime (v místním prostředí) vyberte Spustit Configuration Manager.
Jakmile se uzel připojí ke cloudové službě, zobrazí se následující stránka:
Teď otestujte připojení k databázi SQL Server.
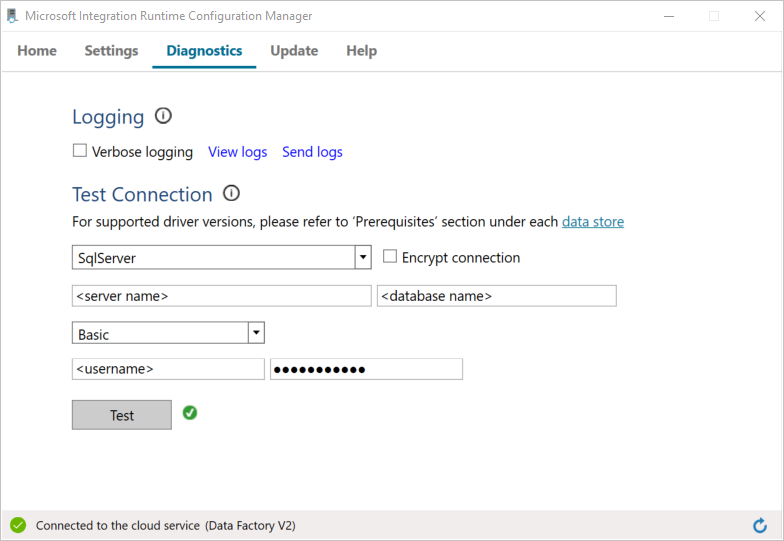
a. Na stránce Configuration Manager přejděte na kartu Diagnostics.
b. Jako typ zdroje dat vyberte SqlServer.
c. Zadejte název serveru.
d. Zadejte název databáze.
e. Vyberte režim ověřování.
f. Zadejte uživatelské jméno.
g. Zadejte heslo přidružené k uživatelskému jménu.
h. Vyberte Test a ověřte, že se prostředí Integration Runtime může připojit k SQL Server. Pokud je připojení úspěšné, zobrazí se zelená značka zaškrtnutí. Jestliže připojení není úspěšné, zobrazí se chybová zpráva. Opravte všechny problémy a ujistěte se, že se prostředí Integration Runtime může připojit k SQL Server.
Poznámka:
Poznamenejte si hodnoty pro typ ověřování, server, databázi, uživatele a heslo. Použijete je později v tomto kurzu.
Vytvoření propojených služeb
V datové továrně vytvoříte propojené služby, abyste svá úložiště dat a výpočetní služby spojili s datovou továrnou. V této části vytvoříte propojené služby s SQL Server databází a databází v Azure SQL Database.
Vytvoření propojené služby SQL Server
V tomto kroku propojujete svou databázi SQL Server s datovou továrnou.
Vytvořte soubor JSON s názvem SqlServerLinkedService.json ve složce C:\ADFTutorials\IncCopyMultiTableTutorial (vytvořte místní složky, pokud ještě neexistují) s následujícím obsahem. Vyberte správný oddíl na základě ověřování, které používáte pro připojení k SQL Server.
Důležité
Vyberte správný oddíl na základě ověřování, které používáte pro připojení k SQL Server.
Pokud používáte ověřování SQL, zkopírujte následující definici JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Pokud používáte Windows authentication, zkopírujte následující definici JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Důležité
- Vyberte správný oddíl na základě ověřování, které používáte pro připojení k SQL Server.
- Nahraďte <název prostředí Integration Runtime> názvem vašeho prostředí Integration Runtime.
- Nahraďte <servername>, <databasename>, <username> a <password> s hodnotami databáze SQL Server před uložením souboru.
- Pokud v názvu účtu uživatele nebo serveru potřebujete použít lomítko (
\), použijte escape znak (\). Příklad:mydomain\\myuser.
V PowerShellu spusťte následující rutinu, která přepne do složky C:\ADFTutorials\IncCopyMultiTableTutorial.
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Spuštěním rutiny Set-AzDataFactoryV2LinkedService vytvořte propojenou službu AzureStorageLinkedService. V následujícím příkladu předáte hodnoty pro parametry ResourceGroupName a DataFactoryName:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"Tady je ukázkový výstup:
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
Vytvoření propojené služby SQL Database
Ve složce C:\ADFTutorials\IncCopyMultiTableTutorial vytvořte soubor JSON s názvem AzureSQLDatabaseLinkedService.json s následujícím obsahem. (Pokud složka ADF ještě neexistuje, vytvořte ji.) Nahraďte <servername>, <názedatabáze>, < uživatelské jméno> a <password> s názvem databáze SQL Server, názvem databáze, uživatelským jménem a heslem před uložením souboru.
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }V PowerShellu spusťte rutinu Set-AzDataFactoryV2LinkedService a vytvořte propojenou službu AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Tady je ukázkový výstup:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Vytvoření datových sad
V tomto kroku vytvoříte datové sady, které představují zdroj dat, cíl dat a místo pro uložení vodoznaku.
Vytvoření zdrojové datové sady
Ve stejné složce vytvořte soubor JSON s názvem SourceDataset.json a s následujícím obsahem:
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }Aktivita kopírování v kanálu používá SQL dotaz k načtení dat namísto načtení celé tabulky.
Spuštěním rutiny Set-AzDataFactoryV2Dataset vytvořte datovou sadu SourceDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Toto je ukázkový výstup tohoto cmdletu:
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Vytvoření datové sady jímky
Ve stejné složce vytvořte soubor JSON s názvem SinkDataset.json s následujícím obsahem. Element tableName je nastaven potrubím dynamicky v době běhu. Aktivita ForEach v tomto kanálu iteruje přes seznam názvů tabulek a předává název tabulky této datové sadě při každé iteraci.
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Spuštěním rutiny Set-AzDataFactoryV2Dataset vytvořte datovou sadu SinkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Toto je ukázkový výstup tohoto cmdletu:
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Vytvořit datovou sadu pro vodoznak
V tomto kroku vytvoříte datovou sadu pro uložení hodnoty horní meze.
Ve stejné složce vytvořte soubor JSON s názvem WatermarkDataset.json s následujícím obsahem:
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Spuštěním rutiny Set-AzDataFactoryV2Dataset vytvořte datovou sadu WatermarkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"Toto je ukázkový výstup tohoto cmdletu:
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Vytvořit potrubí
Tento datový kanál dostává jako parametr seznam názvů tabulek. Aktivita ForEach prochází seznam názvů tabulek a provádí následující operace:
Pomocí aktivity Vyhledávání můžete načíst starou hodnotu vodotisku (počáteční hodnotu nebo hodnotu použitou v poslední iteraci).
Pomocí aktivity Vyhledávání můžete načíst novou hodnotu vodoznaku (což je maximální hodnota tohoto sloupce ve zdrojové tabulce).
Pomocí Copy activity zkopírujte data mezi těmito dvěma hodnotami meze ze zdrojové databáze do cílové databáze.
Pomocí aktivity StoredProcedure aktualizujte starou hodnotu značky, která má být použita v prvním kroku další iterace.
Vytvořte kanál
Ve stejné složce vytvořte soubor JSON s názvem IncrementalCopyPipeline.json s následujícím obsahem:
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Spuštěním rutiny Set-AzDataFactoryV2Pipeline vytvořte kanál IncrementalCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Tady je ukázkový výstup:
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
Spuštění kanálu
Ve stejné složce vytvořte soubor parametrů s názvem Parameters.json s následujícím obsahem:
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Spusťte kanál IncrementalCopyPipeline pomocí rutiny Invoke-AzDataFactoryV2Pipeline . Zástupné znaky nahraďte vlastním názvem skupiny prostředků a názvem datové továrny.
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
Sledujte potrubí
Přihlaste se k portálu Azure.
Vyberte Všechny služby, spusťte hledání pomocí klíčového slova Datové továrny a vyberte Datové továrny.
V seznamu datových továren vyhledejte vaši datovou továrnu a vyberte ji. Otevře se stránka Datová továrna.
Na stránce Data factory vyberte Open na dlaždici Open Azure Data Factory Studio a spusťte Azure Data Factory na samostatné kartě.
Na domovské stránce Azure Data Factory vyberte na levé straně Monitor.
Můžete vidět všechna spuštění kanálu a jejich stavy. Všimněte si, že stav spuštění pipeline v následujícím příkladu je Úspěšný. Parametry předané kanálu můžete zkontrolovat kliknutím na odkaz ve sloupci Parametry. Pokud došlo k chybě, uvidíte odkaz ve sloupci Chyba.

Když vyberete odkaz ve sloupci Akce, zobrazí se všechna spuštění aktivit datového kanálu.
Pokud se chcete vrátit do zobrazení Pipeline Runs, vyberte Všechna Pipeline Runs.
Kontrola výsledků
V SQL Server Management Studio spusťte následující dotazy na cílovou databázi SQL a ověřte, že se data zkopírovala ze zdrojových tabulek do cílových tabulek:
Dotaz
select * from customer_table
Výstup
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Dotaz
select * from project_table
Výstup
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Dotaz
select * from watermarktable
Výstup
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Všimněte si, že hodnoty mezí pro obě tabulky byly aktualizovány.
Přidání dalších dat do zdrojových tabulek
Spuštěním následujícího dotazu na zdrojovou SQL Server databázi aktualizujte existující řádek v customer_table. Vložte nový řádek do tabulky project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Opětovné spuštění potrubí
Nyní spusťte znovu potrubí provedením následujícího příkazu PowerShell:
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"Monitorujte běhy potrubí podle pokynů v části Sledování potrubí. Pokud je stav kanálu probíhající, zobrazí se v části Akce další odkaz na akci, která zruší spuštění kanálu.
Kliknutím na Aktualizovat můžete aktualizovat seznam, dokud nebude spuštění kanálu úspěšné.
Volitelně můžete vybrat odkaz Zobrazit spuštění aktivit v části Akce, abyste viděli všechna spuštění aktivit související s tímto spuštěním potrubí.
Kontrola konečných výsledků
V SQL Server Management Studio spusťte následující dotazy na cílovou databázi a ověřte, že se aktualizovaná nebo nová data zkopírovala ze zdrojových tabulek do cílových tabulek.
Dotaz
select * from customer_table
Výstup
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Všimněte si nových hodnot položek Name a LastModifytime pro PersonID pro číslo 3.
Dotaz
select * from project_table
Výstup
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Všimněte si, že do tabulky project_table byla přidána položka NewProject.
Dotaz
select * from watermarktable
Výstup
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Všimněte si, že hodnoty mezí pro obě tabulky byly aktualizovány.
Související obsah
V tomto kurzu jste provedli následující kroky:
- Příprava zdrojového a cílového datového úložiště
- Vytvoření datové továrny
- Vytvoření místního prostředí Integration Runtime (IR)
- Instalace prostředí Integration Runtime
- Vytvoření propojených služeb
- Vytvořte zdroj, úložiště a datové sady s vodoznakem.
- Vytvoření a spuštění kanálu a jeho monitorování
- Zkontrolujte výsledky.
- Přidání nebo aktualizace dat ve zdrojových tabulkách
- Opakované spuštění kanálu a jeho monitorování
- Kontrola konečných výsledků
V následujícím kurzu se dozvíte, jak transformovat data pomocí clusteru Spark na Azure: