Správa výpočetních služeb
Tento článek popisuje, jak spravovat výpočetní prostředky Azure Databricks, včetně zobrazení, úprav, spuštění, ukončení, odstranění, řízení přístupu a monitorování výkonu a protokolů. Rozhraní API clusterů můžete také použít ke správě výpočetních prostředků prostřednictvím kódu programu.
Zobrazení výpočetních prostředků
Pokud chcete zobrazit výpočetní prostředky, klikněte na ![]() Výpočetní prostředky na bočním panelu pracovního prostoru.
Výpočetní prostředky na bočním panelu pracovního prostoru.
Na levé straně jsou dva sloupce označující, jestli je výpočetní výkon připnutý, a stav výpočetních prostředků. Pokud chcete získat další informace, najeďte myší na stav.
Zobrazení konfigurace výpočetních prostředků jako souboru JSON
Někdy může být užitečné zobrazit konfiguraci výpočetních prostředků ve formátu JSON. To je užitečné hlavně v případě, že chcete vytvořit podobné výpočetní prostředky pomocí rozhraní API clusterů. Když zobrazíte existující výpočetní prostředky, přejděte na kartu Konfigurace , klikněte v pravém horním rohu karty na JSON , zkopírujte JSON a vložte ho do volání rozhraní API. Zobrazení JSON je jen pro čtení.
Připnutí výpočetních prostředků
30 dní po ukončení výpočetních prostředků se trvale odstraní. Pokud chcete zachovat konfiguraci výpočetních prostředků pro všechny účely po ukončení výpočetních prostředků po dobu delší než 30 dnů, může správce výpočetní prostředky připnout. Připnout můžete až 100 výpočetních prostředků.
Správci můžou připnout výpočetní prostředky ze seznamu výpočetních prostředků nebo na stránku podrobností o výpočetních prostředcích kliknutím na ikonu špendlíku.
Úprava výpočetních prostředků
Konfiguraci výpočetních prostředků můžete upravit v uživatelském rozhraní podrobností o výpočetních prostředcích.
Poznámka:
- Poznámkové bloky a úlohy, které byly připojené k výpočetnímu objektu, zůstanou po úpravách připojené.
- Knihovny nainstalované na výpočetních prostředcích zůstanou po úpravách nainstalované.
- Pokud upravíte jakýkoli atribut spuštěného výpočetního objektu (s výjimkou velikosti výpočetních prostředků a oprávnění), musíte ho restartovat. To může narušit uživatele, kteří aktuálně používají výpočetní prostředky.
- Spuštěné nebo ukončené výpočetní prostředky můžete upravovat pouze. Na stránce podrobností o výpočetních prostředcích ale můžete aktualizovat oprávnění pro výpočty, která nejsou v těchto stavech.
Klonování výpočetních prostředků
Pokud chcete naklonovat existující výpočetní prostředky, vyberte z nabídky kebab výpočetních prostředků ![]() klonování.
klonování.
Po výběru možnosti Klonovat se uživatelské rozhraní pro vytváření výpočetních prostředků otevře předem vyplněné konfigurací výpočetních prostředků. Do klonu nejsou zahrnuty následující atributy:
- Výpočetní oprávnění
- Připojené poznámkové bloky
Pokud nechcete do klonovaných výpočetních prostředků zahrnout dříve nainstalované knihovny, klikněte na rozevírací nabídku vedle tlačítka Vytvořit výpočetní prostředky a vyberte Vytvořit bez knihoven.
Výpočetní oprávnění
Pro výpočetní prostředky existují čtyři úrovně oprávnění: ŽÁDNÁ OPRÁVNĚNÍ, MŮŽE SE PŘIPOJIT, MŮŽE RESTARTOVAT a MŮŽE SPRAVOVAT. Podrobnosti najdete v tématu Seznamy ACL pro výpočty.
Poznámka:
Tajné kódy nejsou redactovány z protokolu stdout stderr a streamů ovladačů Spark clusteru. Aby bylo možné chránit citlivá data, protokoly ovladačů Sparku se ve výchozím nastavení dají zobrazit jenom uživatelům s oprávněním CAN MANAGE pro úlohu, režim přístupu jednoho uživatele a clustery režimu sdíleného přístupu. Chcete-li uživatelům, kteří mají oprávnění PŘIPOJIT SE K nebo MŮŽE RESTARTOVAT, můžete zobrazit protokoly v těchto clusterech, nastavte v konfiguraci clusteru následující vlastnost konfigurace Sparku: spark.databricks.acl.needAdminPermissionToViewLogs false
V clusterech s režimem sdíleného přístupu bez izolace můžou uživatelé zobrazit protokoly ovladačů Spark s oprávněním MŮŽE PŘIPOJIT nebo MŮŽE SPRAVOVAT. Chcete-li omezit, kdo může číst protokoly pouze uživatelům s oprávněním CAN MANAGE, nastavte na truehodnotu spark.databricks.acl.needAdminPermissionToViewLogs .
Informace o přidání vlastností Sparku do konfigurace clusteru najdete v konfiguraci Sparku.
Konfigurace výpočetních oprávnění
Tato část popisuje, jak spravovat oprávnění pomocí uživatelského rozhraní pracovního prostoru. Můžete také použít rozhraní API pro oprávnění nebo zprostředkovatele Databricks Terraform.
Ke konfiguraci výpočetních oprávnění musíte mít oprávnění CAN MANAGE (CAN MANAGE) výpočetních prostředků.
- Na bočním panelu klikněte na Výpočty.
- Na řádku výpočetních prostředků klikněte na nabídku
 kebabu vpravo a vyberte Upravit oprávnění.
kebabu vpravo a vyberte Upravit oprávnění. - V nastavení oprávnění klikněte na rozevírací nabídku Vybrat uživatele, skupinu nebo instanční objekt... a vyberte uživatele, skupinu nebo instanční objekt.
- V rozevírací nabídce oprávnění vyberte oprávnění.
- Klikněte na Přidat a klikněte na Uložit.
Ukončení výpočetních prostředků
Pokud chcete ušetřit výpočetní prostředky, můžete výpočetní prostředky ukončit. Ukončená konfigurace výpočetních prostředků se uloží tak, aby ji bylo možné později znovu použít (nebo v případě úloh automaticky spustit). Výpočetní prostředky můžete ručně ukončit nebo nakonfigurovat tak, aby se po zadané době nečinnosti automaticky ukončily. Když počet ukončených výpočetních prostředků překročí 150, odstraní se nejstarší výpočetní prostředky.
Pokud se výpočetní prostředky připnou nebo nerestartují, automaticky a trvale se odstraní 30 dní po ukončení.
Ukončené výpočty se zobrazí v seznamu výpočetních prostředků se šedým kruhem nalevo od názvu výpočetního objektu.
Poznámka:
Když spustíte úlohu na novém výpočetním prostředí úlohy (což se obvykle doporučuje), výpočetní výkon se ukončí a po dokončení úlohy nebude k dispozici pro restartování. Pokud na druhou stranu naplánujete spuštění úlohy na existujícím výpočetním objektu pro všechny účely, který byl ukončen, tento výpočetní objekt se automaticky spustí.
Důležité
Pokud používáte zkušební pracovní prostor Premium, všechny spuštěné výpočetní prostředky se ukončí:
- Při upgradu pracovního prostoru na plnou úroveň Premium.
- Pokud se pracovní prostor neupgraduje a platnost zkušební verze vyprší.
Ruční ukončení
Výpočetní prostředky můžete ručně ukončit ze seznamu výpočetních prostředků (kliknutím na čtverec na řádku výpočetních prostředků) nebo na stránku podrobností o výpočetních prostředcích (kliknutím na tlačítko Ukončit).
Automatické ukončení
Můžete také nastavit automatické ukončení výpočetních prostředků. Během vytváření výpočetních prostředků můžete zadat období nečinnosti v minutách, po které se má výpočetní výkon ukončit.
Pokud je rozdíl mezi aktuálním časem a posledním spuštěním příkazu na výpočetních prostředcích větší než zadané období nečinnosti, Azure Databricks tento výpočetní výkon automaticky ukončí.
Výpočetní prostředky se považují za neaktivní, když se dokončí provádění všech příkazů výpočetních prostředků, včetně úloh Sparku, strukturovaného streamování a volání JDBC.
Upozorňující
- Výpočetní prostředky nehlásí aktivitu vyplývající z použití DStreams. To znamená, že automatické ukončování výpočetních prostředků může být ukončeno během spouštění DStreams. Vypněte automatické ukončení výpočetních prostředků, na kterých běží DStreams, nebo zvažte použití strukturovaného streamování.
- Nečinné výpočetní prostředky nadále hromadí poplatky za DBU a cloudové instance během období nečinnosti před ukončením.
Konfigurace automatického ukončení
Automatické ukončení můžete nakonfigurovat v novém výpočetním uživatelském rozhraní. Ujistěte se, že je políčko zaškrtnuté, a zadejte počet minut v nastavení ukončení po ___ minutách nečinnosti .
Zrušení automatického ukončení můžete zrušit zrušením zaškrtnutí políčka Automatické ukončení nebo zadáním období 0nečinnosti .
Poznámka:
Automatické ukončení se nejlépe podporuje v nejnovějších verzích Sparku. Starší verze Sparku mají známá omezení, která můžou vést k nepřesným generování sestav výpočetní aktivity. Například výpočetní prostředky, na kterých běží příkazy JDBC, R nebo streamování, můžou hlásit zastaralou dobu aktivity, která vede k předčasnému ukončení výpočetních prostředků. Upgradujte na nejnovější verzi Sparku, abyste mohli využívat opravy chyb a vylepšení automatického ukončení.
Neočekávané ukončení
Někdy se výpočetní výkon neočekávaně ukončí, ne v důsledku ručního ukončení nebo nakonfigurovaného automatického ukončení.
Seznam důvodů ukončení a nápravných kroků najdete ve znalostní bázi Knowledge Base.
Odstranění výpočetních prostředků
Odstranění výpočetních prostředků výpočetní prostředky ukončí a odebere jeho konfiguraci. Pokud chcete odstranit výpočetní prostředky, vyberte v nabídce výpočetních prostředků ![]() možnost Odstranit.
možnost Odstranit.
Upozorňující
Tuto akci nelze vrátit zpět.
Pokud chcete odstranit připnuté výpočetní prostředky, musí ho nejdřív odepnout správce.
Můžete také vyvolat koncový bod rozhraní API clusterů a odstranit výpočetní prostředky prostřednictvím kódu programu.
Restartování výpočetních prostředků
Dříve ukončené výpočetní prostředky můžete restartovat ze seznamu výpočetních prostředků, stránky podrobností o výpočetních prostředcích nebo poznámkového bloku. Můžete také vyvolat koncový bod rozhraní API clusterů a spustit výpočetní prostředky prostřednictvím kódu programu.
Azure Databricks identifikuje výpočetní prostředky pomocí jedinečného ID clusteru. Když spustíte ukončené výpočetní prostředky, Databricks znovu vytvoří výpočetní prostředky se stejným ID, automaticky nainstaluje všechny knihovny a znovu připojí poznámkové bloky.
Poznámka:
Pokud používáte zkušební pracovní prostor a platnost zkušební verze vypršela, nebudete moct spustit výpočetní prostředky.
Restartujte výpočetní prostředky a aktualizujte ho nejnovějšími imagemi.
Při restartování výpočetních prostředků získá nejnovější image pro kontejnery výpočetních prostředků a hostitele virtuálních počítačů. Je důležité naplánovat pravidelné restartování pro dlouhotrvající výpočetní prostředky, jako jsou ty, které se používají ke zpracování streamovaných dat.
Je vaší zodpovědností pravidelně restartovat všechny výpočetní prostředky, aby byla image aktuální s nejnovější verzí image.
Důležité
Pokud pro svůj účet nebo pracovní prostor povolíte profil zabezpečení dodržování předpisů, dlouhotrvající výpočetní prostředky se automaticky restartují podle potřeby během plánovaného časového období údržby. Tím se snižuje riziko, že automatické restartování přeruší naplánovanou úlohu. Můžete také vynutit restartování během časového období údržby. Viz Automatická aktualizace clusteru.
Příklad poznámkového bloku: Vyhledání dlouhotrvajících výpočetních prostředků
Pokud jste správcem pracovního prostoru, můžete spustit skript, který určuje, jak dlouho je každý výpočetní objekt spuštěný, a volitelně je restartovat, pokud jsou starší než zadaný počet dní. Azure Databricks tento skript poskytuje jako poznámkový blok.
První řádky skriptu definují konfigurační parametry:
min_age_output: Maximální počet dní, po který může výpočetní prostředí běžet. Výchozí hodnota je 1.perform_restart: PokudTrueskript restartuje jakékoli výpočty s věkem větším než počet dnů určených hodnotoumin_age_output. Výchozí hodnota jeFalse, která identifikuje dlouhotrvající výpočetní prostředky, ale nerestartuje je.secret_configuration: Nahraďte a nahraďteREPLACE_WITH_SCOPEREPLACE_WITH_KEYoborem tajného kódu a názvem klíče. Další podrobnosti o nastavení tajných kódů najdete v poznámkovém bloku.
Upozorňující
Pokud nastavíte perform_restart hodnotu True, skript automaticky restartuje opravňující výpočetní prostředky, což může způsobit selhání aktivních úloh a resetování otevřených poznámkových bloků. Pokud chcete snížit riziko narušení obchodních úloh pracovního prostoru, naplánujte časové období plánované údržby a nezapomeňte uživatele pracovního prostoru upozornit.
Identifikace a volitelné restartování dlouhotrvajících výpočetních prostředků
Automatický start výpočetních prostředků pro úlohy a dotazy JDBC/ODBC
Pokud je naplánované spuštění úlohy přiřazené k ukončeným výpočetním prostředkům nebo se připojíte k ukončeným výpočetním prostředkům z rozhraní JDBC/ODBC, výpočetní prostředky se automaticky restartují. Viz Konfigurace výpočetních prostředků pro úlohy a připojení JDBC.
Automatický start výpočetních prostředků umožňuje nakonfigurovat automatické ukončení výpočetních prostředků bez nutnosti ručního zásahu k restartování výpočetních prostředků pro naplánované úlohy. Kromě toho můžete naplánovat inicializaci výpočetních prostředků naplánováním úlohy, která se spustí na ukončených výpočetních prostředcích.
Před automatickým restartováním výpočetních prostředků se zkontrolují oprávnění řízení přístupu k výpočetním prostředkům a úloh .
Poznámka:
Pokud jste výpočetní prostředky vytvořili na platformě Azure Databricks verze 2.70 nebo starší, neexistuje žádný automatický start: úlohy naplánované na ukončení výpočetních prostředků selžou.
Zobrazení výpočetních informací v uživatelském rozhraní Apache Sparku
Podrobné informace o úlohách Sparku můžete zobrazit tak , že na stránce s podrobnostmi o výpočetních prostředcích vyberete kartu uživatelského rozhraní Sparku.
Pokud restartujete ukončené výpočetní prostředky, uživatelské rozhraní Sparku zobrazí informace o restartovaném výpočetním prostředí, ne historické informace o ukončených výpočetních prostředcích.
Projděte si diagnostiku problémů s náklady a výkonem pomocí uživatelského rozhraní Sparku a projděte si diagnostiku problémů s náklady a výkonem pomocí uživatelského rozhraní Sparku.
Zobrazení výpočetních protokolů
Azure Databricks poskytuje tři druhy protokolování aktivity související s výpočetními prostředky:
- Protokoly výpočetních událostí, které zachycují události životního cyklu výpočetních prostředků, jako jsou vytváření, ukončení a úpravy konfigurace.
- Ovladač Apache Spark a protokol pracovního procesu, který můžete použít k ladění.
- Protokoly inicializačních skriptů výpočetních prostředků, které jsou užitečné pro ladění inicializačních skriptů.
Tato část popisuje protokoly výpočetních událostí a protokoly ovladačů a pracovních procesů. Podrobnosti o protokolech inicializačních skriptů najdete v tématu Protokolování inicializačních skriptů.
Protokoly výpočetních událostí
Protokol výpočetních událostí zobrazuje důležité události životního cyklu výpočetního cyklu aktivované ručně akcemi uživatelů nebo automaticky službou Azure Databricks. Tyto události ovlivňují provoz výpočetních prostředků jako celku a úlohy spuštěné ve výpočetním prostředí.
Podporované typy událostí najdete v datové struktuře rozhraní API clusterů.
Události se ukládají po dobu 60 dnů, což je srovnatelné s jinými dobami uchovávání dat v Azure Databricks.
Zobrazení protokolu událostí výpočetních prostředků
Pokud chcete zobrazit protokol událostí výpočetních prostředků, vyberte na stránkách s podrobnostmi o výpočetních prostředcích kartu Protokol událostí.
Další informace o události získáte kliknutím na jeho řádek v protokolu a kliknutím na kartu JSON zobrazíte podrobnosti.
Protokoly výpočetních ovladačů a pracovních procesů
Přímý výstup a příkazy protokolování z poznámkových bloků, úloh a knihoven se odesílají do protokolů ovladače Sparku. K těmto souborům protokolů se dostanete z karty Protokoly ovladačů na stránce s podrobnostmi o výpočetních prostředcích. Kliknutím na název souboru protokolu ho stáhněte.
Tyto protokoly mají tři výstupy:
- Standardní výstup
- Standardní chyba
- Protokoly Log4j
Pokud chcete zobrazit protokoly pracovního procesu Sparku, použijte kartu uživatelského rozhraní Sparku. Pro výpočetní prostředky můžete také nakonfigurovat umístění doručení protokolu. Pracovní i výpočetní protokoly se doručí do zadaného umístění.
Monitorování výkonu
Azure Databricks poskytuje přístup k metrikám ze stránky s podrobnostmi o výpočetních prostředcích, aby vám pomohl monitorovat výkon výpočetních prostředků. Pro Databricks Runtime 12.2 a novější poskytuje Azure Databricks přístup k metrikám Ganglia . Pro Databricks Runtime 13.3 LTS a vyšší jsou výpočetní metriky poskytované službou Azure Databricks.
Kromě toho můžete nakonfigurovat výpočetní prostředky Azure Databricks tak, aby odesílaly metriky do pracovního prostoru služby Log Analytics ve službě Azure Monitor, monitorovací platformě pro Azure.
Agenty Datadog můžete také nainstalovat na výpočetní uzly a odesílat metriky datadogu do vašeho účtu Datadog.
Výpočetní metriky
Výpočetní metriky jsou výchozím monitorovacím nástrojem pro výpočetní prostředky bez serveru a pro úlohy bez serveru. Pokud chcete získat přístup k uživatelskému rozhraní výpočetních metrik, přejděte na kartu Metriky na stránce s podrobnostmi o výpočetních prostředcích.
Historické metriky můžete zobrazit výběrem časového rozsahu pomocí filtru pro výběr data. Metriky se shromažďují každou minutu. Nejnovější metriky můžete získat také kliknutím na tlačítko Aktualizovat . Další informace najdete v tématu Zobrazení výpočetních metrik.
Metriky Ganglia
Poznámka:
Metriky Ganglia jsou dostupné pouze pro Databricks Runtime 12.2 a níže.
Pokud chcete získat přístup k uživatelskému rozhraní Ganglia, přejděte na kartu Metriky na stránce podrobností výpočetních prostředků a povolte nastavení starších metrik . Metriky GPU jsou k dispozici pro výpočetní prostředky s podporou GPU.
Pokud chcete zobrazit živé metriky, klikněte na odkaz Uživatelské rozhraní Ganglia.
Pokud chcete zobrazit historické metriky, klikněte na soubor snímku. Snímek obsahuje agregované metriky za hodinu před vybraným časem.
Poznámka:
Ganglia se nepodporuje s kontejnery Dockeru. Pokud s výpočetními prostředky používáte kontejner Dockeru, metriky Ganglia nebudou k dispozici.
Konfigurace shromažďování metrik Ganglia
Azure Databricks ve výchozím nastavení shromažďuje metriky Ganglia každých 15 minut. Pokud chcete nakonfigurovat období shromažďování, nastavte DATABRICKS_GANGLIA_SNAPSHOT_PERIOD_MINUTES proměnnou prostředí pomocí inicializačního skriptu nebo pole spark_env_vars v rozhraní API pro vytvoření clusteru.
Azure Monitor
Výpočetní prostředky Azure Databricks můžete nakonfigurovat tak, aby odesílaly metriky do pracovního prostoru služby Log Analytics ve službě Azure Monitor, monitorovací platformě Pro Azure. Kompletní pokyny najdete v tématu Monitorování Azure Databricks.
Poznámka:
Pokud jste nasadili pracovní prostor Azure Databricks ve vlastní virtuální síti a nakonfigurovali jste skupiny zabezpečení sítě (NSG) tak, aby odepřely veškerý odchozí provoz, který Azure Databricks nevyžaduje, musíte nakonfigurovat další odchozí pravidlo pro značku služby AzureMonitor.
Příklad poznámkového bloku: Metriky služby Datadog
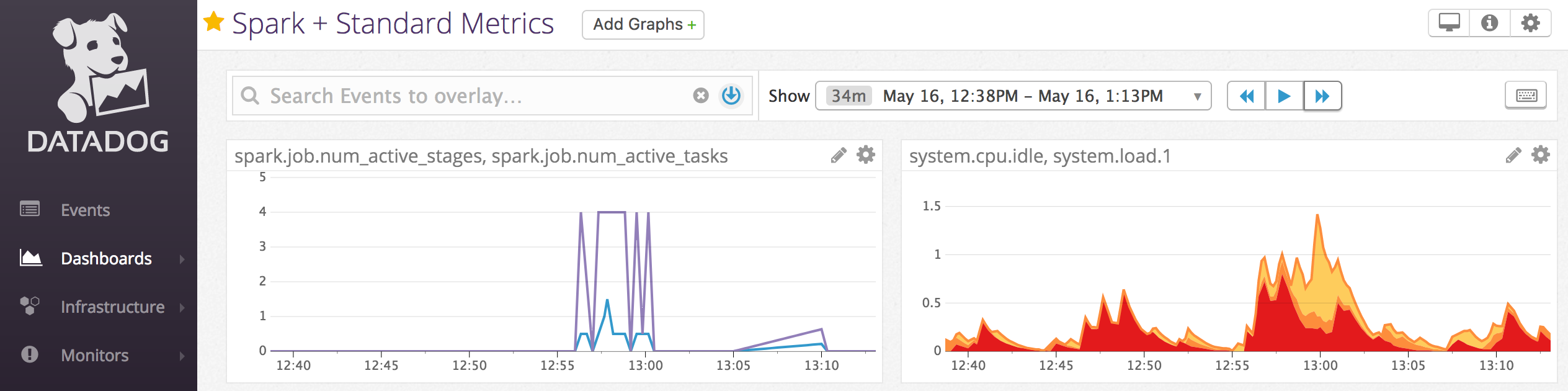
Agenty datadogu můžete nainstalovat na výpočetní uzly, abyste mohli odesílat metriky Služby Datadog do vašeho účtu Datadog. Následující poznámkový blok ukazuje, jak nainstalovat agenta Datadog na výpočetní prostředky pomocí inicializačního skriptu s rozsahem výpočetních prostředků.
Pokud chcete nainstalovat agenta Datadog na všechny výpočetní prostředky, spravujte inicializační skript s rozsahem výpočetních prostředků pomocí výpočetních zásad.
Instalace poznámkového bloku inicializačního skriptu agenta Datadog
Vyřazení spotových instancí z provozu
Vzhledem k tomu, že spotové instance můžou snížit náklady, vytváření výpočetních prostředků pomocí spotových instancí místo instancí na vyžádání představuje běžný způsob spouštění úloh. Spotové instance ale můžou být předem ovlivněné mechanismy plánování poskytovatele cloudu. Preemption spotových instancí může způsobovat problémy se spuštěnými úlohami, mezi které patří:
- Selhání načítání náhodného náhodného načítání
- Ztráta dat náhodného náhodného prohazování
- Ztráta dat RDD
- Selhání úloh
Pokud chcete tyto problémy vyřešit, můžete povolit vyřazení z provozu. Vyřazení z provozu využívá oznámení, že poskytovatel cloudu obvykle odesílá před vyřazením spotové instance z provozu. Když spotová instance obsahující exekutor obdrží oznámení o preemption, proces vyřazení z provozu se pokusí migrovat data náhodného prohazování a RDD do exekutorů, které jsou v pořádku. Doba trvání před poslední preempce je obvykle 30 sekund až 2 minuty v závislosti na poskytovateli cloudu.
Databricks doporučuje povolit migraci dat i při vyřazení z provozu. Obecně platí, že možnost chyb se snižuje, protože se migruje více dat, včetně selhání náhodného načítání, ztráty dat náhodného prohazování a ztráty dat RDD. Migrace dat může také vést k menšímu výpočtu a uloženým nákladům.
Poznámka:
Vyřazení z provozu je nejlepší úsilí a nezaručuje migraci všech dat před dokončením ukončení. Vyřazení z provozu nemůže zaručit selhání načítání náhodného prohazování při načítání dat z exekutoru při spouštění úloh.
Při povoleném vyřazení z provozu se selhání úkolů způsobená preempcí spotové instance nepřidávají k celkovému počtu neúspěšných pokusů. Selhání úloh způsobená preempce se nepočítají jako neúspěšné pokusy, protože příčina selhání je pro úkol externí a nezpůsobí selhání úlohy.
Povolení vyřazení z provozu
Pokud chcete povolit vyřazení výpočetních prostředků z provozu, zadejte na kartě Spark v části Upřesnit možnosti v uživatelském rozhraní konfigurace výpočetních prostředků následující vlastnosti. Informace o těchtovlastnostech
Pokud chcete povolit vyřazení aplikací z provozu, zadejte tuto vlastnost do konfiguračního pole Sparku:
spark.decommission.enabled truePokud chcete povolit migraci dat náhodného prohazování během vyřazení z provozu, zadejte tuto vlastnost do konfiguračního pole Sparku:
spark.storage.decommission.enabled true spark.storage.decommission.shuffleBlocks.enabled truePokud chcete povolit migraci dat mezipaměti RDD během vyřazení z provozu, zadejte tuto vlastnost do konfiguračního pole Sparku:
spark.storage.decommission.enabled true spark.storage.decommission.rddBlocks.enabled truePoznámka:
Pokud je replikace RDD StorageLevel nastavená na více než 1, Databricks nedoporučuje povolit migraci dat RDD, protože repliky zajišťují, že sady RDD nepřijdou o data.
Pokud chcete povolit vyřazení pracovních procesů z provozu, zadejte tuto vlastnost do pole Proměnné prostředí:
SPARK_WORKER_OPTS="-Dspark.decommission.enabled=true"
Zobrazení důvodu vyřazení z provozu a ztráty v uživatelském rozhraní
Pokud chcete získat přístup ke stavu vyřazení pracovního procesu z uživatelského rozhraní, přejděte do výpočetního uživatelského rozhraní Sparku – hlavní karta.
Po dokončení vyřazení z provozu můžete na stránce s podrobnostmi o výpočetních prostředcích zobrazit důvod ztráty exekutoru na kartě Exekutory uživatelského rozhraní > Sparku.