Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Distribuovanou úlohu můžete spustit napříč několika GPU – buď v jednom uzlu, nebo napříč několika uzly – pomocí bezserverového rozhraní GPU Python API. Rozhraní API poskytuje jednoduché sjednocené rozhraní, které abstrahuje podrobnosti o zřizování GPU, nastavení prostředí a distribuci úloh. S minimálními změnami kódu můžete bezproblémově přejít z trénování s jedním GPU na distribuované spouštění napříč vzdálenými gpu ze stejného poznámkového bloku.
Rychlý start
Bezserverové rozhraní API GPU pro distribuované trénování je předinstalované v bezserverových výpočetních prostředích GPU určených pro poznámkové bloky Databricks. Doporučujeme prostředí GPU 4 a vyšší. Pokud ho chcete použít pro distribuované učení, importujte a použijte distributed dekorátor k distribuci funkce učení.
Následující fragment kódu ukazuje základní použití @distributed:
# Import the distributed decorator
from serverless_gpu import distributed
# Decorate your training function with @distributed and specify the number of GPUs, the GPU type,
# and whether or not the GPUs are remote
@distributed(gpus=8, gpu_type='A10', remote=True)
def run_train():
...
Níže je úplný příklad, který trénuje model MLP (multilayer perceptron) na 8 uzlech GPU A10 v poznámkovém bloku:
Nastavte model a definujte funkce nástroje.
# Define the model import os import torch import torch.distributed as dist import torch.nn as nn def setup(): dist.init_process_group("nccl") torch.cuda.set_device(int(os.environ["LOCAL_RANK"])) def cleanup(): dist.destroy_process_group() class SimpleMLP(nn.Module): def __init__(self, input_dim=10, hidden_dim=64, output_dim=1): super().__init__() self.net = nn.Sequential( nn.Linear(input_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.2), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.2), nn.Linear(hidden_dim, output_dim) ) def forward(self, x): return self.net(x)Importujte knihovnu serverless_gpu a distribuovaný modul.
import serverless_gpu from serverless_gpu import distributedVložte kód pro trénování modelu do funkce a ozdobte funkci dekorátorem
@distributed.@distributed(gpus=8, gpu_type='A10', remote=True) def run_train(num_epochs: int, batch_size: int) -> None: import mlflow import torch.optim as optim from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data import DataLoader, DistributedSampler, TensorDataset # 1. Set up multi node environment setup() device = torch.device(f"cuda:{int(os.environ['LOCAL_RANK'])}") # 2. Apply the Torch distributed data parallel (DDP) library for data-parellel training. model = SimpleMLP().to(device) model = DDP(model, device_ids=[device]) # 3. Create and load dataset. x = torch.randn(5000, 10) y = torch.randn(5000, 1) dataset = TensorDataset(x, y) sampler = DistributedSampler(dataset) dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size) # 4. Define the training loop. optimizer = optim.Adam(model.parameters(), lr=0.001) loss_fn = nn.MSELoss() for epoch in range(num_epochs): sampler.set_epoch(epoch) model.train() total_loss = 0.0 for step, (xb, yb) in enumerate(dataloader): xb, yb = xb.to(device), yb.to(device) optimizer.zero_grad() loss = loss_fn(model(xb), yb) # Log loss to MLflow metric mlflow.log_metric("loss", loss.item(), step=step) loss.backward() optimizer.step() total_loss += loss.item() * xb.size(0) mlflow.log_metric("total_loss", total_loss) print(f"Total loss for epoch {epoch}: {total_loss}") cleanup()Spusťte distribuované trénování voláním distribuované funkce s uživatelsky definovanými argumenty.
run_train.distributed(num_epochs=3, batch_size=1)Po spuštění bude ve výstupu buňky poznámkového bloku vygenerován odkaz na běh MLflow. Pokud chcete zobrazit výsledky spuštění, klikněte na odkaz spuštění MLflow nebo ho najděte na panelu Experiment .
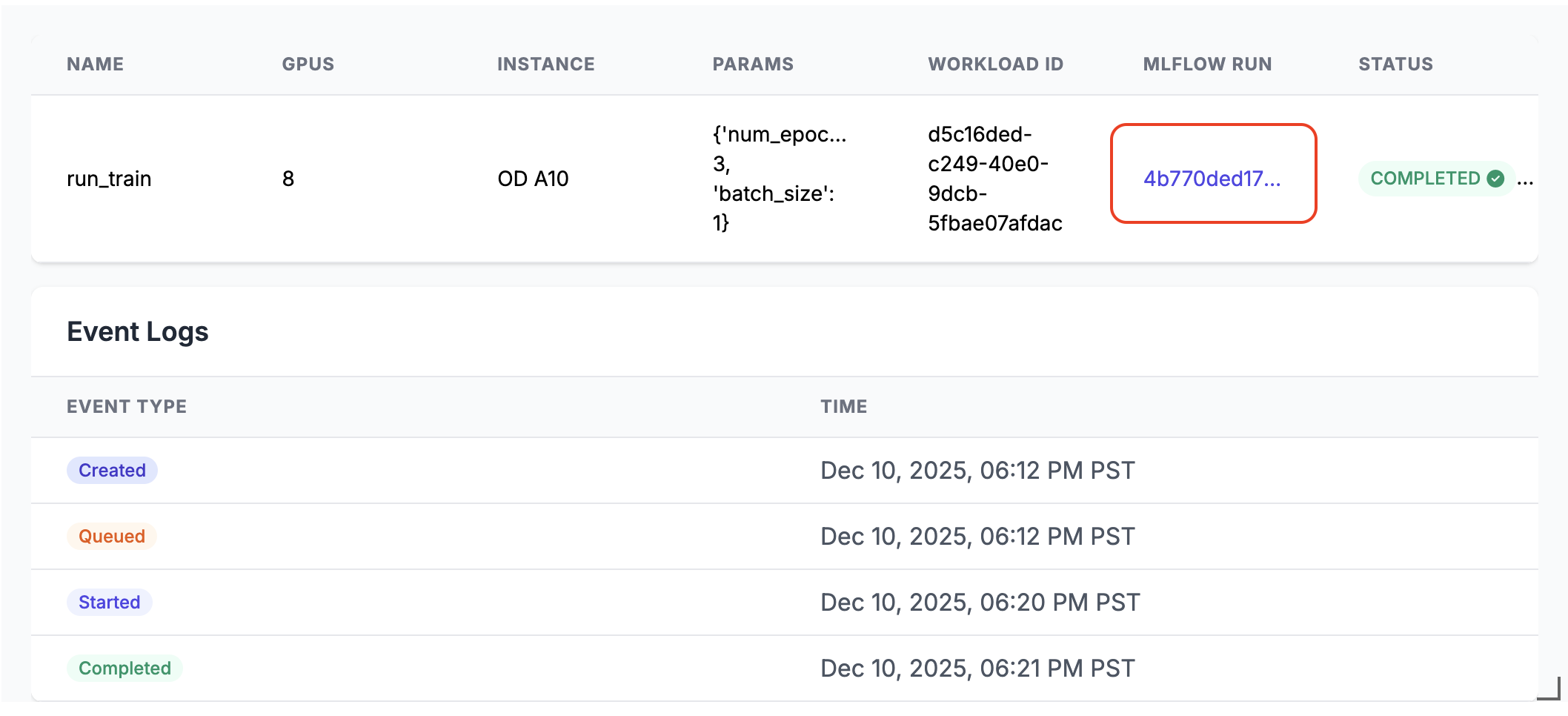
Podrobnosti distribuovaného spuštění
Bezserverové rozhraní GPU API se skládá z několika klíčových komponent:
- Správce výpočetních prostředků: Zpracovává přidělování a správu prostředků
- Běhové prostředí: Spravuje prostředí a závislosti Pythonu.
- Spouštěč: Orchestrace provádění a monitorování úloh
Při spuštění v distribuovaném režimu:
- Funkce se serializuje a distribuuje napříč zadaným počtem GRAFICKÝch procesorů.
- Každý GPU spouští kopii funkce se stejnými parametry.
- Prostředí se synchronizuje napříč všemi uzly.
- Výsledky se shromažďují a vrací ze všech grafických procesorů.
Pokud je remote nastaveno na True, úloha se distribuuje na vzdálených grafických procesorech. Pokud je remote nastaven na False, úloha běží na jediném GPU uzlu připojeném k aktuálnímu poznámkovému bloku. Pokud má uzel více čipů GPU, budou všechny využity.
Rozhraní API podporuje oblíbené paralelní trénovací knihovny, jako je DDP (Distributed Data Parallel ), Fully Sharded Data Parallel (FSDP), DeepSpeed a Ray.
V příkladech poznámkových bloků najdete více skutečných distribuovaných trénovacích scénářů pomocí různých knihoven.
Spuštění pomocí Ray
Bezserverové rozhraní GPU API také podporuje spouštění distribuovaného trénování pomocí Ray pomocí dekorátoru @ray_launch , který je vrstvený nad @distributed.
Každý ray_launch úkol nejprve inicializuje torch.distributed rendezvous k určení vedoucího pracovníka Ray a ke shromáždění IP adres. Začátek rank-nula ray start --head (s exportem metrik, pokud je povolen), nastaví RAY_ADDRESS a spustí vaši dekorovanou funkci jako řidič Ray. Ostatní uzly se připojují přes ray start --address a čekají, dokud ovladač nezapíše značku dokončení.
Další podrobnosti o konfiguraci:
- Pro povolení shromažďování metrik systému Ray na každém uzlu použijte
RayMetricsMonitorremote=True. - Pomocí standardních rozhraní API Ray definujte možnosti modulu runtime Ray (actors, datasets, skupiny umístění a plánování) uvnitř vaší dekorované funkce.
- Spravujte ovládací prvky pro celý cluster (počet a typ GPU, vzdálený a místní režim, asynchronní chování a proměnné prostředí fondu Databricks) mimo funkci v argumentech dekorátoru nebo prostředí poznámkového bloku.
Následující příklad ukazuje, jak používat @ray_launch:
from serverless_gpu.ray import ray_launch
@ray_launch(gpus=16, remote=True, gpu_type='A10')
def foo():
import os
import ray
print(ray.state.available_resources_per_node())
return 1
foo.distributed()
Úplný příklad najdete v tomto poznámkovém bloku, který spouští Ray k trénování neurální sítě Resnet18 na několika grafických procesorech A10.
Pomocí tohoto rozhraní API můžete také volat Ray Data, škálovatelnou knihovnu pro zpracování dat pro úlohy AI, ke spuštění distribuovaného dávkového odvozování v LLM. Viz příklady vllm a sglang .
FAQs
Kam se má kód načítání dat umístit?
Při použití Serverless GPU API pro distribuované trénování přesuňte kód načítání dat do dekorátoru @distributed. Velikost datové sady může překročit maximální velikost povolenou funkcí pickle, takže je doporučeno vygenerovat datovou sadu uvnitř dekorátoru, jak je znázorněno níže:
from serverless_gpu import distributed
# this may cause pickle error
dataset = get_dataset(file_path)
@distributed(gpus=8, remote=True)
def run_train():
# good practice
dataset = get_dataset(file_path)
....
Můžu používat vyhrazené fondy GPU?
Pokud je ve vašem pracovním prostoru k dispozici vyhrazený fond GPU (obraťte se na správce) a zadáte v dekorátoru remoteTrue@distributed, úkol se ve výchozím nastavení spustí ve vyhrazeném fondu GPU. Pokud chcete použít fond GPU na vyžádání, nastavte prosím proměnnou prostředí DATABRICKS_USE_RESERVED_GPU_POOL na hodnotu False ještě před voláním distribuované funkce, jak je znázorněno níže:
import os
os.environ['DATABRICKS_USE_RESERVED_GPU_POOL'] = 'False'
@distributed(gpus=8, remote=True)
def run_train():
...
Další informace
Referenční informace k rozhraní API najdete v dokumentaci k bezserverové verzi rozhraní GPU Python API .