Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Poznámka:
Tento článek se zabývá Azure DevOps, který vyvíjí třetí strana. Pokud chcete kontaktovat poskytovatele, podívejte se na podporu Azure DevOps Services.
Tento článek vás provede konfigurací Azure DevOps pro práci s Azure Databricks. Konkrétně nakonfigurujete pracovní postup kontinuální integrace a doručování (CI/CD) pro připojení k úložišti Git, spuštění úloh pomocí Azure Pipelines k sestavení a testování jednotek kola Pythonu (*.whl) a jeho nasazení pro použití v poznámkových blocích Databricks.
Přehled CI/CD s Azure Databricks najdete v tématu CI/CD v Azure Databricks. Osvědčené postupy najdete v tématu Osvědčené postupy a doporučené pracovní postupy CI/CD v Databricks.
O příkladu
Tento příklad používá dva kanály ke shromáždění, nasazení a spuštění ukázkového kódu Pythonu a poznámkových bloků Pythonu uložených ve vzdáleném úložišti Git.
První pipeline, označovaná jako build pipeline, připraví artefakty sestavení pro druhou pipeline, označovanou jako release pipeline. Oddělení kanálu sestavení od kanálu nasazení vám umožňuje vytvořit artefakt sestavení bez jeho nasazení nebo současné nasazení artefaktů z různých sestavení. Vytvoření kanálů buildu a verze:
- Vytvořte virtuální počítač Azure pro kanál buildu.
- Zkopírujte soubory z úložiště Git do virtuálního počítače.
- Vytvořte soubor gzip'ed tar, který obsahuje kód Pythonu, poznámkové bloky Pythonu a související soubory sestavení, nasazení a spuštění nastavení.
- Zkopírujte gzipovaný soubor tar jako ZIP soubor do umístění, k němuž má přístup distribuční kanál.
- Vytvořte další virtuální počítač Azure pro uvolňovací kanál.
- Získejte soubor ZIP z umístění kanálu buildu a potom jej rozbalte, abyste získali Pythonový kód, Pythonové poznámkové bloky a související soubory s nastavením pro sestavení, nasazení a spuštění.
- Nasaďte kód Pythonu, poznámkové bloky Pythonu a související soubory sestavení, nasazení a spouštění souborů nastavení do vzdáleného pracovního prostoru Azure Databricks.
- Sestavte soubory kódu komponent knihovny wheel do Python wheel souboru.
- Spuštěním jednotkových testů na kódu komponent zkontrolujte logiku v Pythonovém wheel souboru.
- Spusťte poznámkové bloky Pythonu, z nichž jeden využívá funkci wheel balíčku Pythonu.
Než začnete
Pokud chcete použít příklad tohoto článku, musíte mít:
- Existující projekt Azure DevOps Pokud ještě projekt nemáte, vytvořte projekt v Azure DevOps.
- Existující úložiště s poskytovatelem Gitu, které Azure DevOps podporuje. Do tohoto úložiště přidáte ukázkový kód Pythonu, ukázkový poznámkový blok Pythonu a související soubory nastavení verzí. Pokud ještě nemáte úložiště, vytvořte ho podle pokynů svého poskytovatele Gitu. Pokud jste to ještě neudělali, připojte projekt Azure DevOps k tomuto úložišti. Pokyny najdete na odkazech v podporovaných zdrojových úložištích.
- Příklad v tomto článku používá ověřování OAuth M2M (machine-to-machine) k autentizaci služebního principálu Microsoft Entra ID do pracovního prostoru Azure Databricks. Pro tento instanční objekt musíte mít instanční objekt Microsoft Entra ID s tajným kódem Azure Databricks OAuth. Viz Autorizace přístupu instančního objektu k Azure Databricks pomocí OAuth.
Návod
Azure DevOps můžete také ověřit ve službě Databricks pomocí připojení služby Azure Resource Manager nebo federace identit úloh Databricks. Tyto možnosti eliminují potřebu správy tajných kódů.
Krok 1: Přidání souborů příkladu do úložiště
V tomto kroku v úložišti s vaším poskytovatelem třetí strany Gitu přidáte všechny ukázkové soubory z tohoto článku, které vaše pipeliny Azure DevOps sestavují, nasazují a spouštějí na vašem vzdáleném pracovním prostoru Azure Databricks.
Krok 1.1: Přidání souborů komponent kolečka Pythonu
V příkladu tohoto článku kanály Azure DevOps sestaví a provedou jednotkové testy balíčku Python wheel. Poznámkový blok Azure Databricks pak zavolá funkce vytvořeného souboru kola Pythonu.
Pokud chcete definovat logiku a jednotkové testy pro soubor Python Wheel, proti kterému jsou spuštěny poznámkové bloky, vytvořte v kořenovém adresáři úložiště dva soubory s názvy addcol.py a test_addcol.py, a přidejte je do struktury složek pojmenované python/dabdemo/dabdemo ve složce Libraries, vizualizováno takto:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
Soubor addcol.py obsahuje funkci knihovny, která je později integrovaná do souboru kola Pythonu a pak je nainstalovaná v clusterech Azure Databricks. Jedná se o jednoduchou funkci, která do datového rámce Apache Sparku přidá nový sloupec naplněný literálem:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Soubor test_addcol.py obsahuje testy, které předávají simulovaný objekt DataFrame funkci with_status definované v addcol.py. Výsledek se pak porovná s objektem DataFrame obsahujícím očekávané hodnoty. Pokud se hodnoty shodují, test projde:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Aby rozhraní příkazového řádku Databricks správně zabalilo kód knihovny do souboru pythonového balíku typu wheel, vytvořte dva soubory pojmenované __init__.py a __main__.py ve stejné složce jako předchozí dva soubory. Vytvořte také soubor pojmenovaný setup.py ve python/dabdemo složce, vizualizovaný následujícím způsobem:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
Soubor __init__.py obsahuje číslo verze a autora knihovny. Nahraďte <my-author-name> svým jménem:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Soubor __main__.py obsahuje vstupní bod knihovny:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Soubor setup.py obsahuje další nastavení pro sestavení knihovny do souboru kola Pythonu. Nahraďte <my-url>, <my-author-name>@<my-organization>a <my-package-description> platnými hodnotami:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Krok 1.2: Přidání poznámkového bloku testování jednotek pro soubor kola Pythonu
Později spustí rozhraní příkazového řádku Databricks úlohu poznámkového bloku. Tato úloha spustí poznámkový blok Pythonu s názvem souboru run_unit_tests.py. Tento poznámkový blok běží pytest proti logice knihovny kol Pythonu.
Pokud chcete spustit testy jednotek pro příklad tohoto článku, přidejte do kořenového adresáře úložiště soubor poznámkového bloku s názvem run_unit_tests.py s následujícím obsahem:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Krok 1.3: Přidání poznámkového bloku, který volá soubor kola Pythonu
Později spustí rozhraní příkazového řádku Databricks další úlohu poznámkového bloku. Tento poznámkový blok vytvoří objekt datového rámce, předá ho funkci knihovny with_status kol Pythonu, vytiskne výsledek a nahlásí výsledky spuštění úlohy. Vytvořte kořen úložiště a soubor poznámkového bloku s názvem dabdemo_notebook.py s následujícím obsahem:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Krok 1.4: Vytvoření konfigurace sady
Příklad tohoto článku používá sady prostředků Databricks k definování nastavení a chování při sestavování, nasazování a spouštění souboru kolečka Pythonu, dvou poznámkových bloků a souboru kódu Pythonu. Sady prostředků Databricks umožňují vyjádřit kompletní data, analýzy a projekty ML jako kolekci zdrojových souborů. Podívejte se na Co jsou Databricks Asset Bundles?.
Pokud chcete nakonfigurovat sadu pro příklad tohoto článku, vytvořte v kořenovém adresáři úložiště soubor s názvem databricks.yml. V tomto ukázkovém databricks.yml souboru nahraďte následující zástupné symboly:
- Nahraďte
<bundle-name>jedinečným programovým názvem sady. Například:azure-devops-demo. - Nahraďte
<job-prefix-name>nějakým řetězcem, který v tomto příkladu pomáhá jednoznačně identifikovat úlohy vytvořené v pracovním prostoru Azure Databricks. Například:azure-devops-demo. - Nahraďte
<spark-version-id>ID verze databricks Runtime pro clustery úloh, například13.3.x-scala2.12. - Nahraďte
<cluster-node-type-id>ID typu uzlu clusteru pro clustery úloh, napříkladStandard_DS3_v2. - Všimněte si, že
devv mapovánítargetsurčuje hostitele a související chování nasazení. V praktických implementacích můžete dát této položce jiný název ve vlastních balíčcích.
Tady je obsah souboru tohoto příkladu databricks.yml :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
targets:
dev:
mode: development
Další informace o databricks.yml syntaxi souboru najdete v tématu Konfigurace sady prostředků Databricks.
Krok 2: Definování sestavovacího řetězce
Azure DevOps poskytuje uživatelské rozhraní hostované v cloudu pro definování fází kanálu CI/CD pomocí YAML. Další informace o Azure DevOps a kanálech najdete v dokumentaci k Azure DevOps.
V tomto kroku použijete YAML kód k definování sestavení, které vytvoří artefakt pro nasazení. Pokud chcete nasadit kód do pracovního prostoru Azure Databricks, zadáte artefakt sestavení tohoto kanálu jako vstup do kanálu verze. Tento předávací kanál definujete později.
Azure DevOps poskytuje ke spouštění kanálů sestavení cloudově hostované agenty spouštění na vyžádání, které podporují nasazení do Kubernetes, virtuálních počítačů, Azure Functions, Azure Web Apps a mnoha dalších cílů. V tomto příkladu použijete agenta na vyžádání k automatizaci sestavení artefaktu nasazení.
Definujte ukázkovou sestavovací linku tohoto článku takto:
Přihlaste se k Azure DevOps a kliknutím na odkaz Přihlásit se otevřete projekt Azure DevOps.
Poznámka:
Pokud se místo vašeho projektu Azure DevOps zobrazí Azure Portal, klikněte na Další služby > Organizace Azure DevOps > Moje organizace Azure DevOps a poté otevřete svůj projekt Azure DevOps.
Na bočním panelu klikněte na Pipelines a potom v nabídce Pipelines klikněte na Pipelines.
Klikněte na tlačítko Nový kanál a postupujte podle pokynů na obrazovce. (Pokud už kanály máte, klikněte na Místo toho vytvořte kanál .) Na konci těchto pokynů se otevře editor kanálu. Tady definujete skript sestavovacího kanálu v
azure-pipelines.ymlsouboru, který se zobrazí. Pokud editor kanálu není na konci pokynů viditelný, vyberte název kanálu buildu a klikněte na Upravit.Pomocí
 můžete přizpůsobit proces sestavení pro každou větev ve svém úložišti Git. V rámci osvědčených postupů CI/CD by se neměla provádět produkční práce přímo ve větvi úložiště
můžete přizpůsobit proces sestavení pro každou větev ve svém úložišti Git. V rámci osvědčených postupů CI/CD by se neměla provádět produkční práce přímo ve větvi úložiště main. Tento příklad předpokládá, že v úložišti existuje pojmenovanáreleasevětev, která se má použít místomain.
azure-pipelines.ymlSkript kanálu buildu je standardně uložený v kořenovém adresáři vzdáleného úložiště Git, které přidružíte ke kanálu.Přepište úvodní obsah souboru kanálu
azure-pipelines.ymlnásledující definicí a klikněte na Uložit.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Krok 3: Definujte vydávací kanál
Kanál verze nasadí artefakty sestavení z kanálu buildu do prostředí Azure Databricks. Oddělení vydávacího kanálu v tomto kroku od kanálu sestavení v předchozích krocích umožňuje vytvořit sestavení bez nasazení jeho artefaktů, nebo nasadit artefakty z více sestavení zároveň.
V projektu Azure DevOps v nabídce Pipelines na bočním panelu klikněte na Vydané verze.
Klikněte na Nové > nové potrubí pro vydání. (Pokud už máte pipeliny, klikněte na Nová pipeline.)
Na straně obrazovky je seznam doporučených šablon pro běžné vzory nasazení. Pro tento příklad publikačního kanálu klikněte na
 .
.
V poli Artefakty na straně obrazovky klikněte na
 . V podokně Přidat artefakt pro Zdroj (kanál buildu) vyberte kanál buildu, který jste vytvořili dříve. Pak klikněte na Přidat.
. V podokně Přidat artefakt pro Zdroj (kanál buildu) vyberte kanál buildu, který jste vytvořili dříve. Pak klikněte na Přidat.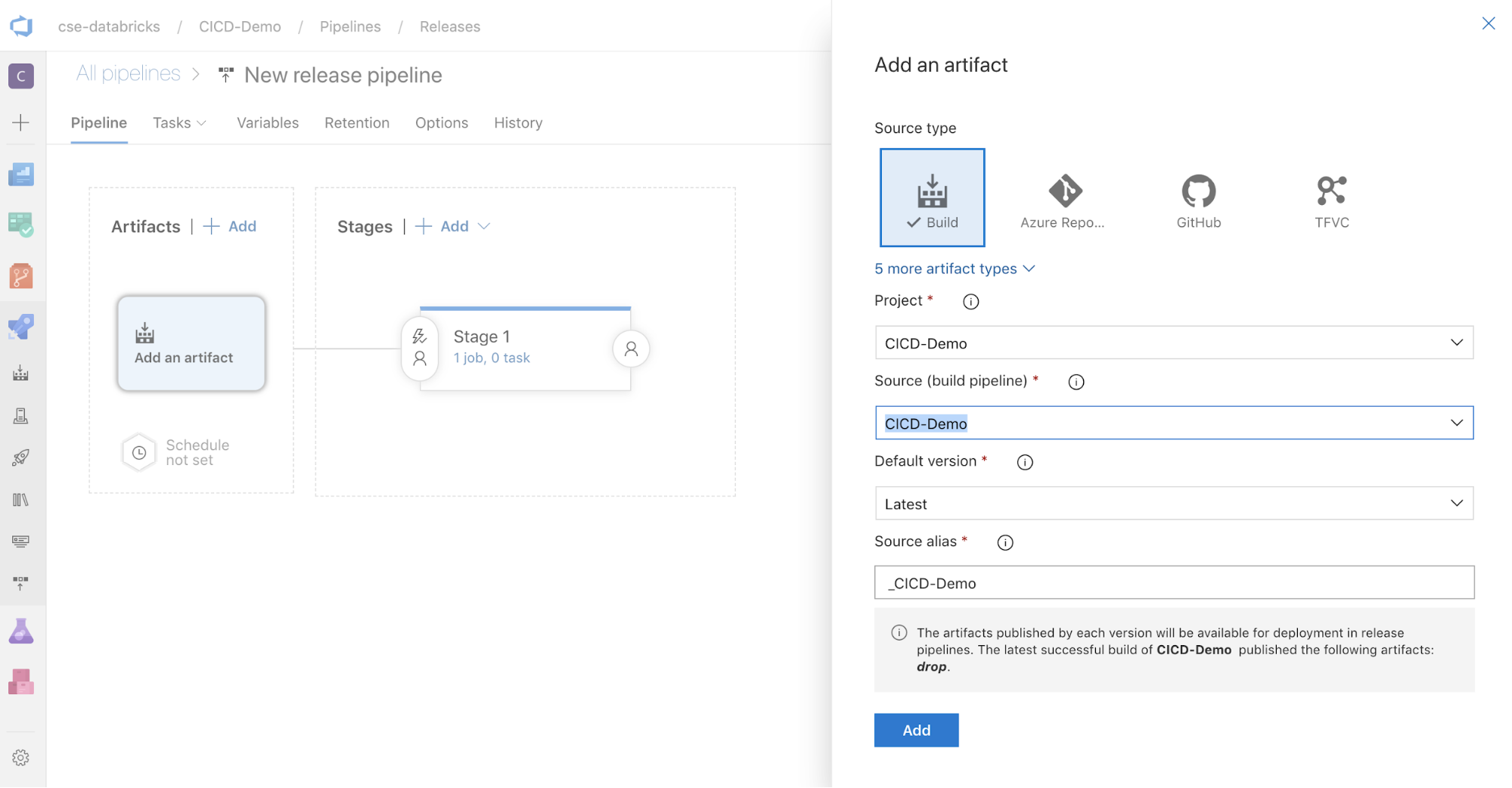
Způsob spuštění pipeline můžete nakonfigurovat kliknutím na
 pro zobrazení možností spuštění na okraji obrazovky. Pokud chcete, aby se verze spouštěla automaticky na základě dostupnosti artefaktů buildu nebo po pracovního postupu žádosti o přijetí změn, povolte příslušnou aktivační událost. Prozatím v tomto příkladu v posledním kroku tohoto článku ručně aktivujete kanál buildu a potom kanál verze.
pro zobrazení možností spuštění na okraji obrazovky. Pokud chcete, aby se verze spouštěla automaticky na základě dostupnosti artefaktů buildu nebo po pracovního postupu žádosti o přijetí změn, povolte příslušnou aktivační událost. Prozatím v tomto příkladu v posledním kroku tohoto článku ručně aktivujete kanál buildu a potom kanál verze.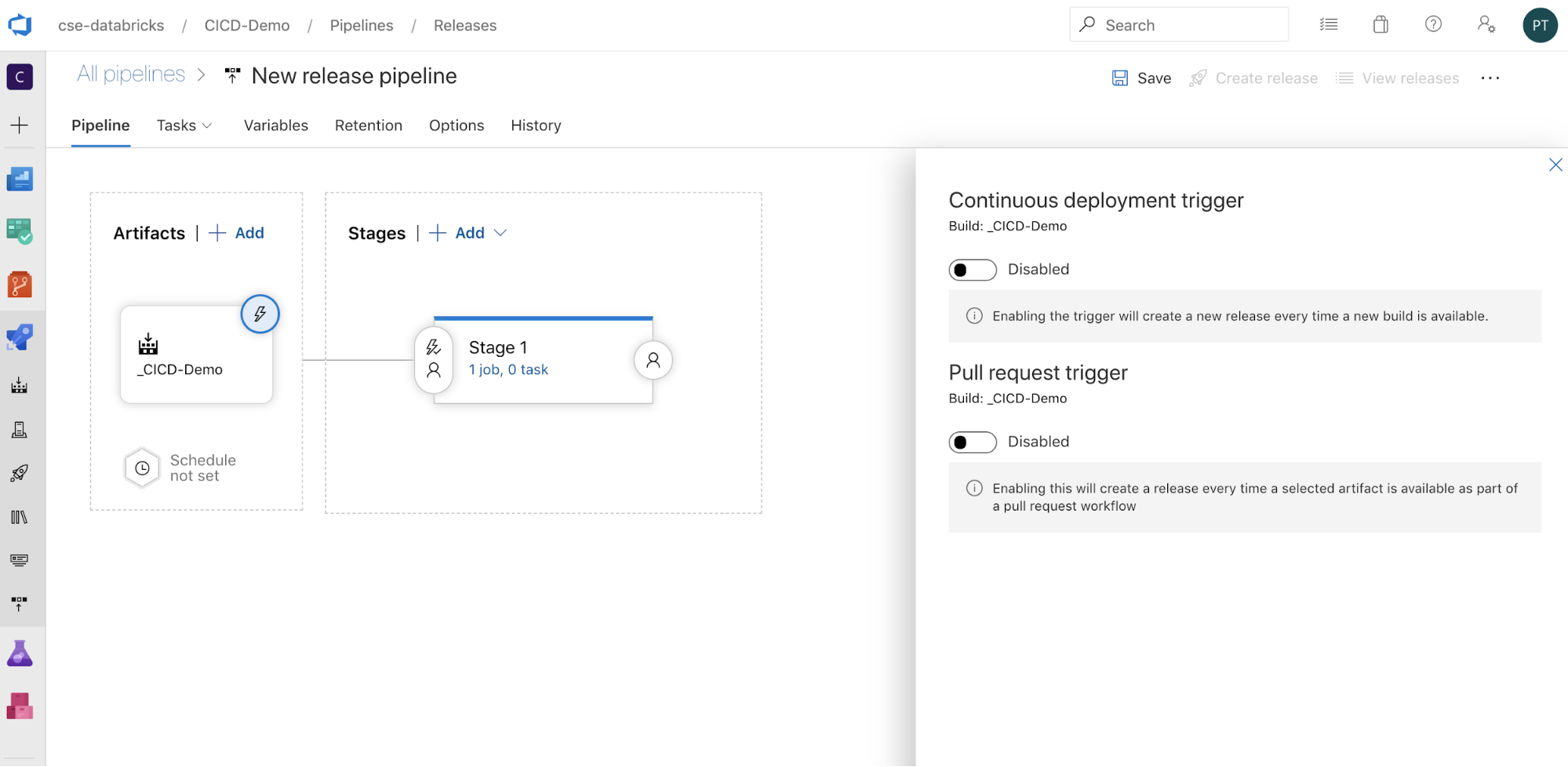
Klepněte na tlačítko Uložit > OK.
Krok 3.1: Definujte proměnné prostředí pro vydávací kanál
Pipeline verze tohoto příkladu závisí na následujících proměnných prostředí, které můžete přidat kliknutím na Přidat v části Proměnné pipeline na kartě Proměnné s rozsahem fáze 1:
-
BUNDLE_TARGET, který by se měl shodovat stargetnázvem vdatabricks.ymlsouboru. V příkladu tohoto článku jedev. -
DATABRICKS_HOST, který představuje adresu URL na základě pracovního prostoru vašeho pracovního prostoru Azure Databricks, začínajícíhttps://, napříkladhttps://adb-<workspace-id>.<random-number>.azuredatabricks.net. Nezahrnujte koncové/za.net. -
DATABRICKS_CLIENT_ID, který představuje ID aplikace pro služební účet Microsoft Entra ID. -
DATABRICKS_CLIENT_SECRET, který představuje tajný klíč OAuth Azure Databricks pro služební objekt Microsoft Entra ID.
Krok 3.2: Konfigurace agenta vydání pro vydávací potrubí
Klikněte na odkaz 1 úlohu, 0 úkolů v rámci objektu Fáze 1.
Na kartě Úkoly klikněte na úlohu agenta.
V části Výběr agenta pro fond agentůvyberte Azure Pipelines.
V specifikaci agentavyberte stejného agenta, kterého jste dříve určili jako agenta sestavení, v tomto příkladu ubuntu-22.04.
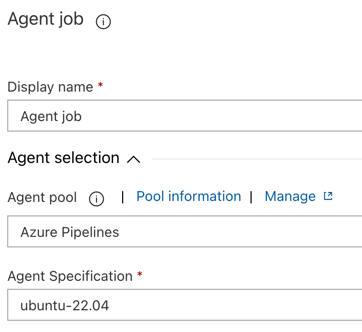
Klepněte na tlačítko Uložit > OK.
Krok 3.3: Nastavení verze Pythonu pro vydávacího agenta
Klikněte na symbol plus v části Úloha agenta označená červenou šipkou na následujícím obrázku. Zobrazí se prohledávatelný seznam dostupných úkolů. K dispozici je také karta Marketplace pro moduly plug-in třetích stran, které je možné použít k doplnění standardních úloh Azure DevOps. V průběhu několika následujících kroků přidáte do nasazovacího agenta několik úloh.
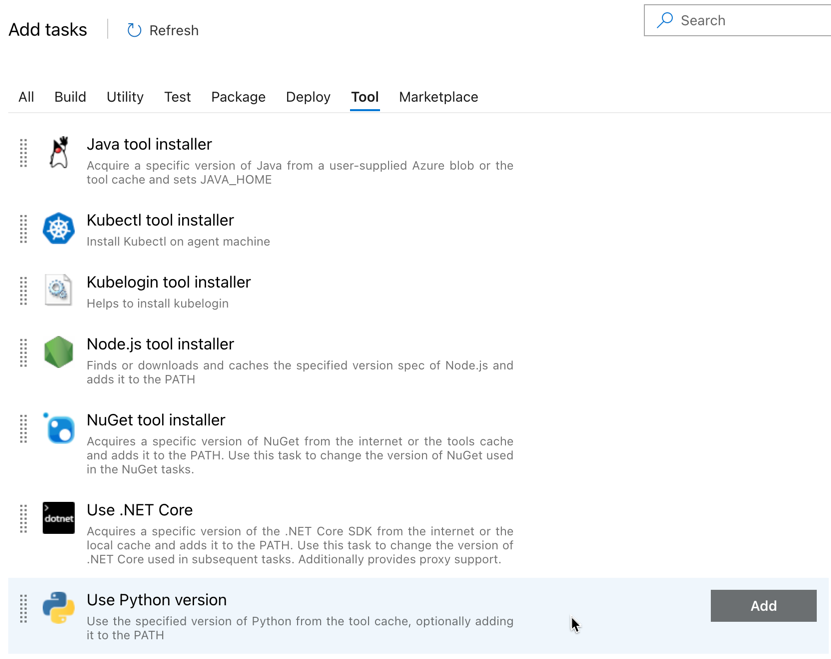
Prvním úkolem, který přidáte, je Použít verzi Pythonu, která je umístěná na kartě Nástroje. Pokud tento úkol nemůžete najít, vyhledejte ho pomocí vyhledávacího pole. Až ho najdete, vyberte ho a stiskněte tlačítko Přidat vedle úlohy Použít verzi Pythonu.
Stejně jako u kanálu buildu chcete mít jistotu, že je verze Pythonu kompatibilní se skripty volanými v dalších úlohách. V tomto případě klikněte na úlohu Použít Python 3.x vedle úlohy agenta, a potom nastavte Version spec na
3.10. Nastavte také Zobrazovaný název naUse Python 3.10. Tento kanál předpokládá, že v clusterech používáte Databricks Runtime 13.3 LTS, které mají nainstalovaný Python 3.10.12.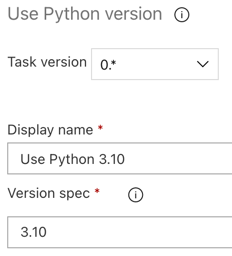
Klepněte na tlačítko Uložit > OK.
Krok 3.4: Rozbalení artefaktu sestavení z kanálu buildu
Dále požádejte agenta verze, aby extrahoval soubor kola Pythonu, související soubory nastavení verzí, poznámkové bloky a soubor kódu Pythonu ze souboru ZIP pomocí úlohy Extrahovat soubory: klikněte na plus v části Úloha agenta, vyberte úlohu Extrahovat soubory na kartě Utility a potom klikněte na Přidat.
Klikněte na úlohu Extrahovat soubory vedle úlohy agenta, nastavte Archivovat vzory souborů na
**/*.zip, a nastavte Cílová složka na systémovou proměnnou$(Release.PrimaryArtifactSourceAlias)/Databricks. Nastavte také Zobrazovaný název naExtract build pipeline artifact.Poznámka:
$(Release.PrimaryArtifactSourceAlias)představuje alias vygenerovaný v Azure DevOps, který identifikuje umístění zdroje primárních artefaktů v agentu verze, například_<your-github-alias>.<your-github-repo-name>. Vydávací kanál nastaví tuto hodnotu jako proměnnou prostředíRELEASE_PRIMARYARTIFACTSOURCEALIASv fázi inicializace práce pro agenta vydání. Podívejte se na proměnné klasického vydání a artefaktů.Nastavte Zobrazovaný název na
Extract build pipeline artifact.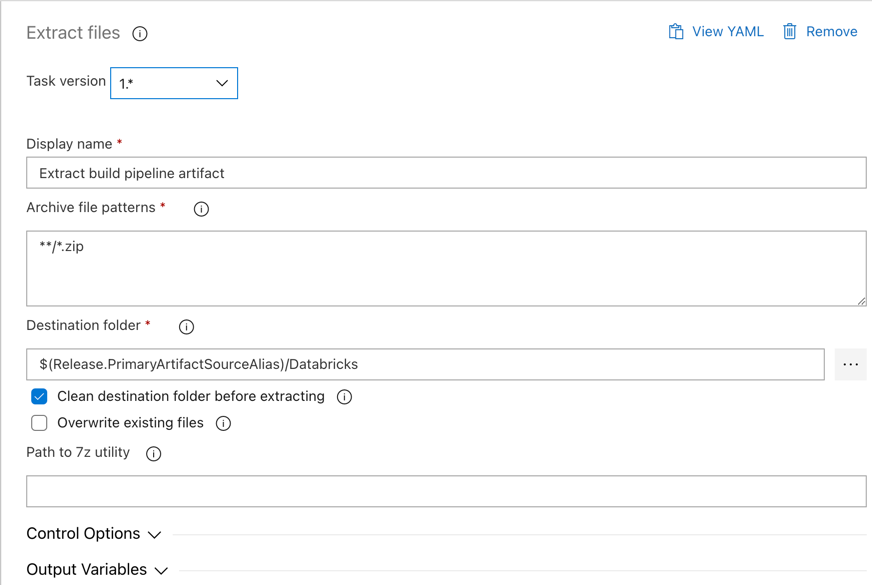
Klepněte na tlačítko Uložit > OK.
Krok 3.5: Nastavení proměnné prostředí BUNDLE_ROOT
Aby příklad v tomto článku fungoval, jak se očekává, je nutné nastavit proměnnou prostředí pojmenovanou BUNDLE_ROOT ve vydávacím kanálu. Sady prostředků Databricks používají tuto proměnnou prostředí k určení umístění souboru databricks.yml. Chcete-li nastavit tuto proměnnou prostředí:
Použijte úkol Proměnné prostředí: Klikněte znovu na symbol plus v části Agent job, vyberte úkol Proměnné prostředí na kartě Utility, a potom klikněte na Přidat.
Poznámka:
Pokud úkol proměnných prostředí není viditelný na kartě Utility, zadejte
Environment Variablesdo pole Vyhledávací a podle pokynů na obrazovce přidejte úkol na kartu Utility. To může vyžadovat, abyste opustili Azure DevOps a pak se vrátili na toto umístění, kde jste skončili.Do pole Proměnné prostředí (oddělené čárkami) zadejte následující definici:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Poznámka:
$(Agent.ReleaseDirectory)představuje alias vygenerovaný službou Azure DevOps pro identifikaci umístění adresáře vydané verze v agentu verze, například/home/vsts/work/r1/a. Vydávací kanál nastaví tuto hodnotu jako proměnnou prostředíAGENT_RELEASEDIRECTORYv fázi inicializace práce pro agenta vydání. Podívejte se na proměnné klasického vydání a artefaktů. Informace o$(Release.PrimaryArtifactSourceAlias)naleznete v poznámce v předchozím kroku.Nastavte Zobrazovaný název na
Set BUNDLE_ROOT environment variable.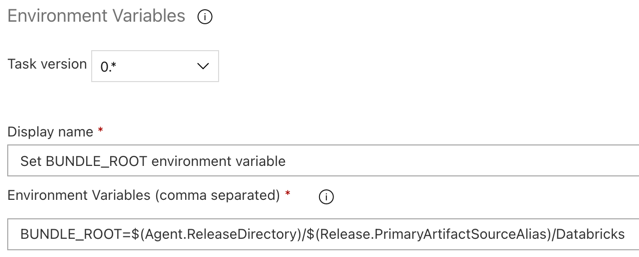
Klepněte na tlačítko Uložit > OK.
Krok 3.6 Instalace CLI Databricks a nástrojů pro sestavení wheel v Pythonu
Dále nainstalujte Rozhraní příkazového řádku Databricks a nástroje pro sestavování wheelů Pythonu na agenta verze. Agent verze bude v několika dalších úlohách volat nástroje sestavení kol Databricks CLI a Pythonu. Chcete-li to provést, použijte Bash úkol: klikněte znovu na znaménko plus v úloze agenta, vyberte Bash úkol na kartě Utility a potom klikněte na Přidat.
Klikněte na úlohu skriptu Bash vedle úlohy agenta.
Pro Typvyberte Online.
Obsah skriptu nahraďte následujícím příkazem, který nainstaluje nástroje databricks CLI a nástroje pro sestavení kol Pythonu:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelNastavte Zobrazovaný název na
Install Databricks CLI and Python wheel build tools.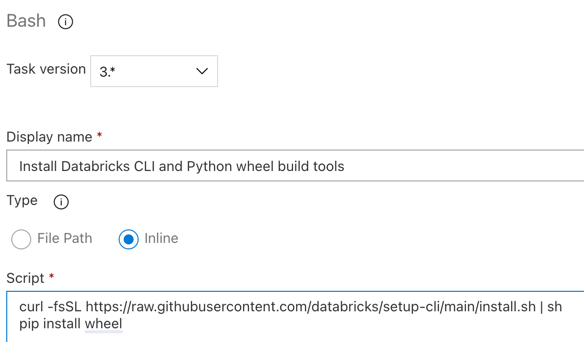
Klepněte na tlačítko Uložit > OK.
Krok 3.7: Ověření sady prostředků Databricks
V tomto kroku se ujistěte, že databricks.yml je soubor syntakticky správný.
Použijte úlohu Bash: v části úlohy agenta znovu klikněte na znaménko plus, vyberte úlohu Bash na kartě Utility, a potom klikněte na Přidat.
Klikněte na úlohu skriptu Bash vedle úlohy agenta.
Pro Typvyberte Online.
Obsah skriptu nahraďte následujícím příkazem, který pomocí rozhraní příkazového řádku Databricks zkontroluje, jestli
databricks.ymlje soubor syntakticky správný:databricks bundle validate -t $(BUNDLE_TARGET)Nastavte Zobrazovaný název na
Validate bundle.Klepněte na tlačítko Uložit > OK.
Krok 3.8: Nasazení sady
V tomto kroku sestavíte soubor kola Pythonu a nasadíte vytvořený soubor kola Pythonu, dva poznámkové bloky Pythonu a soubor Pythonu z kanálu verze do pracovního prostoru Azure Databricks.
Použijte úlohu Bash: v části úlohy agenta znovu klikněte na znaménko plus, vyberte úlohu Bash na kartě Utility, a potom klikněte na Přidat.
Klikněte na úlohu skriptu Bash vedle úlohy agenta.
Pro Typvyberte Online.
Obsah skriptu nahraďte následujícím příkazem, který pomocí rozhraní příkazového řádku Databricks sestaví soubor kola Pythonu a nasadí ukázkové soubory tohoto článku z kanálu verze do pracovního prostoru Azure Databricks:
databricks bundle deploy -t $(BUNDLE_TARGET)Nastavte Zobrazovaný název na
Deploy bundle.Klepněte na tlačítko Uložit > OK.
Krok 3.9: Spuštění poznámkového bloku jednotkového testu pro Python wheel
V tomto kroku spustíte úlohu, která spustí notebook pro jednotkové testy ve vašem pracovním prostoru Azure Databricks. Tento poznámkový blok spouští jednotkové testy proti logice knihovny wheels Pythonu.
Použijte úlohu Bash: v části úlohy agenta znovu klikněte na znaménko plus, vyberte úlohu Bash na kartě Utility, a potom klikněte na Přidat.
Klikněte na úlohu skriptu Bash vedle úlohy agenta.
Pro Typvyberte Online.
Obsah skriptu nahraďte následujícím příkazem, který pomocí rozhraní příkazového řádku Databricks spustí úlohu v pracovním prostoru Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsNastavte Zobrazovaný název na
Run unit tests.Klepněte na tlačítko Uložit > OK.
Krok 3.10: Spusťte poznámkový blok, který volá Python wheel
V tomto kroku spustíte úlohu, která v pracovním prostoru Azure Databricks spustí jiný poznámkový blok. Tento poznámkový blok volá knihovnu kol Pythonu.
Použijte úlohu Bash: v části úlohy agenta znovu klikněte na znaménko plus, vyberte úlohu Bash na kartě Utility, a potom klikněte na Přidat.
Klikněte na úlohu skriptu Bash vedle úlohy agenta.
Pro Typvyberte Online.
Obsah skriptu nahraďte následujícím příkazem, který pomocí rozhraní příkazového řádku Databricks spustí úlohu v pracovním prostoru Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookNastavte Zobrazovaný název na
Run notebook.Klepněte na tlačítko Uložit > OK.
Dokončili jste konfiguraci svého nasazovacího kanálu. Měl by vypadat takto:
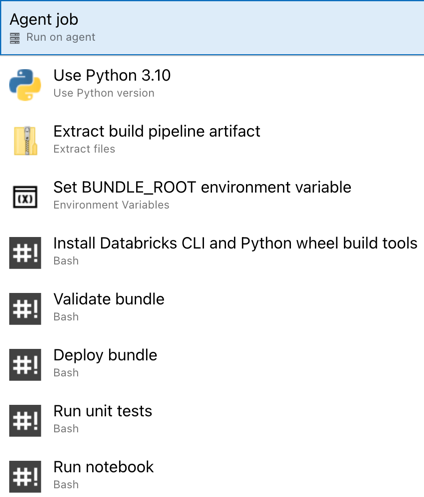
Krok 4: Spuštění build a release pipelineů
V tomto kroku spustíte potrubí ručně. Informace o tom, jak kanály spouštět automaticky, najdete v tématu Určení událostí, které aktivují kanály a aktivační události vydané verze.
Ruční spuštění potrubí buildu:
- V nabídce Pipelines na bočním panelu klikněte na Pipelines.
- Klikněte na název kanálu buildu a potom klikněte na Spustit kanál.
- Pro větev/značku vyberte název větve v úložišti Git, který obsahuje veškerý zdrojový kód, který jste do něj přidali. Tento příklad předpokládá, že toto je ve
releasevětvi. - Klepněte na položku Spustit. Zobrazí se stránka spuštění build pipeline.
- Pokud chcete sledovat průběh sestavovacího řetězce a podívat se na související protokoly, klikněte na otáčející se ikonu vedle úlohy.
- Jakmile se ikona Úlohy změní na zelenou značku zaškrtnutí, pokračujte spuštěním kanálu verze.
Pro ruční spuštění vydávacího kanálu:
- Po úspěšném spuštění kanálu buildu v nabídce Pipelines na bočním panelu klikněte na Vydané verze.
- Klikněte na název vašeho kanálu pro nasazení a pak klikněte na Vytvořit nasazení.
- Klikněte na Vytvořit.
- Chcete-li zobrazit průběh vydávací potrubí, klikněte v seznamu verzí na název nejnovější verze.
- V poli Fáze klikněte na Fáze 1 a klikněte na Protokoly.