Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Poznámka:
Tento článek se týká Databricks Connect pro Databricks Runtime 13.3 LTS a vyšší.
Databricks Connect umožňuje připojit oblíbená vývojová prostředí IDE, jako je PyCharm, servery poznámkových bloků a další vlastní aplikace k výpočetním prostředkům Azure Databricks. Viz Databricks Connect.
Tento článek ukazuje, jak rychle začít používat Službu Databricks Connect pro Python pomocí PyCharm. Vytvoříte projekt v PyCharm, nainstalujete Databricks Connect pro Databricks Runtime 13.3 LTS a novější a spustíte jednoduchý kód na klasických výpočetních prostředcích v pracovním prostoru Databricks z PyCharm.
Požadavky
K dokončení tohoto kurzu musíte splnit následující požadavky:
- Váš pracovní prostor, místní prostředí a výpočetní prostředí splňují požadavky služby Databricks Connect pro Python. Viz požadavky na využití Databricks Connect.
- Máte nainstalovaný PyCharm . Tento kurz byl testován s PyCharm Community Edition 2023.3.5. Pokud používáte jinou verzi nebo edici PyCharm, můžou se následující pokyny lišit.
- Pokud používáte klasické výpočetní prostředky, budete potřebovat ID clusteru. Pokud chcete získat ID clusteru, klikněte v pracovním prostoru na bočním panelu na Compute a potom na název clusteru. V adresní řádku webového prohlížeče zkopírujte řetězec znaků mezi
clustersadresou URL aconfigurationdo adresy URL.
Krok 1: Konfigurace ověřování Azure Databricks
V tomto kurzu se používá ověřování Azure Databricks pomocí OAuth uživatel-stroj (U2M) a konfiguračního profilu Azure Databricks pro autentizaci k vašemu pracovnímu prostoru Azure Databricks. Pokud chcete použít jiný typ ověřování, přečtěte si téma Konfigurace vlastností připojení.
Konfigurace ověřování OAuth U2M vyžaduje rozhraní příkazového řádku Databricks. Informace o instalaci rozhraní příkazového řádku Databricks najdete v tématu Instalace nebo aktualizace rozhraní příkazového řádku Databricks.
Následujícím způsobem zahajte ověřování OAuth U2M:
Pomocí Databricks CLI spusťte místní správu tokenů OAuth tak, že pro každý cílový pracovní prostor použijete následující příkaz.
V následujícím příkazu nahraďte
<workspace-url>adresou URL Azure Databricks per-workspace, napříkladhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Tip
Pokud chcete s Databricks Connect používat bezserverové výpočetní prostředky, přečtěte si téma Konfigurace připojení k bezserverovým výpočetním prostředkům.
Rozhraní příkazového řádku Databricks vás vyzve k uložení informací, které jste zadali jako profil konfigurace Azure Databricks . Stisknutím klávesy
Enterpotvrďte navrhovaný název profilu nebo zadejte název nového nebo existujícího profilu. Všechny existující profily se stejným názvem se přepíšou informacemi, které jste zadali. Profily můžete použít k rychlému přepnutí kontextu ověřování napříč několika pracovními prostory.Seznam existujících profilů získáte tak, že v samostatném terminálu nebo příkazovém řádku použijete rozhraní příkazového řádku Databricks ke spuštění příkazu
databricks auth profiles. Pokud chcete zobrazit existující nastavení konkrétního profilu, spusťte příkazdatabricks auth env --profile <profile-name>.Ve webovém prohlížeči dokončete pokyny na obrazovce, abyste se přihlásili ke svému Azure Databricks pracovnímu prostoru.
V seznamu dostupných clusterů, které se zobrazí v terminálu nebo příkazovém řádku, vyberte cílový Azure Databricks clusteru v pracovním prostoru pomocí šipky nahoru a dolů a stiskněte
Enter. Pokud chcete filtrovat seznam dostupných clusterů, můžete také zadat libovolnou část zobrazovaného názvu clusteru.Pokud chcete zobrazit aktuální hodnotu tokenu OAuth profilu a nadcházející časové razítko vypršení platnosti tokenu, spusťte jeden z následujících příkazů:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Pokud máte více profilů se stejnou
--hosthodnotou, možná budete muset zadat možnosti--hosta-pspolečně, aby rozhraní příkazového řádku Databricks mohlo najít správné odpovídající informace o tokenu OAuth.
Krok 2: Vytvoření projektu
- Spusťte PyCharm.
- V hlavní nabídce klikněte na Soubor > Nový Projekt.
- V dialogovém okně Nový Project klikněte na Pure Python.
- Pro Lokace klikněte na ikonu složky a dokončete pokyny na obrazovce a zadejte cestu k novému projektu Python.
- Ponechte vybranou možnost Vytvořit main.py uvítací skript.
- Pro typ Interpreter klikněte na Project venv.
- Rozbalte Python verzi a pomocí ikony složky nebo rozevíracího seznamu určete cestu k interpretu Python z předchozích požadavků.
- Klikněte na Vytvořit.
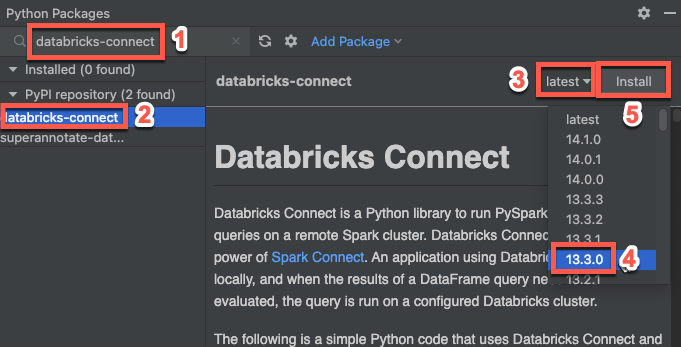
Krok 3: Přidání balíčku Databricks Connect
- V hlavní nabídce PyCharm klikněte na View > Tool Windows > Python Packages.
- Do vyhledávacího pole zadejte
databricks-connect. - V seznamu úložiště PyPI
klikněte na databricks-connect . - V nejnovějším rozevíracím seznamu podokna výsledků vyberte verzi, která odpovídá verzi Databricks Runtime vašeho clusteru. Pokud má váš cluster například nainstalovaný Databricks Runtime 14.3, vyberte 14.3.1.
- Klikněte na Instalovat balíček.
- Po instalaci balíčku můžete okno Python Packages zavřít.
Krok 4: Přidání kódu
V okně nástroje Project klikněte pravým tlačítkem na kořenovou složku project a klikněte na Nový > Python Soubor.
Zadejte
main.pya dvakrát klikněte na Python soubor.Do souboru zadejte následující kód a v závislosti na názvu konfiguračního profilu ho uložte.
Pokud má váš konfigurační profil z kroku 1 název
DEFAULT, zadejte do souboru následující kód a pak soubor uložte:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)Pokud váš konfigurační profil z kroku 1 není pojmenovaný
DEFAULT, zadejte do souboru následující kód. Zástupný symbol<profile-name>nahraďte názvem konfiguračního profilu z kroku 1 a pak soubor uložte:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
Krok 5: Spuštění kódu
- Spusťte cílový cluster ve vzdáleném pracovním prostoru Azure Databricks.
- Po spuštění clusteru v hlavní nabídce klikněte na Spustit 'main'>.
- V okně nástroje Run (View > Tool Windows > Run), v hlavním panelu na kartě Run se zobrazí prvních 5 řádků .
Krok 6: Ladění kódu
- Pokud je cluster stále spuštěný, klikněte v předchozím kódu na okraj vedle
df.show(5)a nastavte zarážku. - V hlavní nabídce klikněte na Spustit ladění 'main'>.
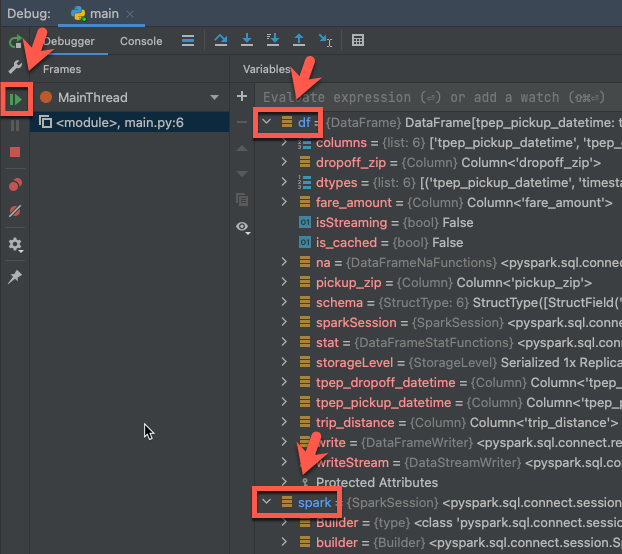
- V okně nástroje Debug (View > Tool Windows > Debug), na kartě Debugger v panelu Variables rozbalte uzly proměnných df a spark, abyste mohli procházet informace o
dfasparkproměnných. - Na bočním panelu okna nástroje Ladění klikněte na zelenou šipku (Resume Program).
- V podokně Konzola na kartě Ladicí program se zobrazí prvních 5 řádků
samples.nyctaxi.trips.