Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Poznámka:
Tento článek popisuje Databricks Connect pro Databricks Runtime 13.3 LTS a novější verze.
Databricks Connect je klientská knihovna pro Databricks Runtime, která umožňuje připojit se k Azure Databricks výpočetních prostředků z prostředí IDE, jako jsou Visual Studio Code, PyCharm a IntelliJ IDEA, poznámkové bloky a libovolná vlastní aplikace, a umožnit tak nová interaktivní uživatelská prostředí založená na vašem Azure Databricks Lakehouse.
Databricks Connect je k dispozici pro následující jazyky:
Co můžu dělat s Databricks Connect?
Pomocí Databricks Connect můžete psát kód pomocí rozhraní Spark API a vzdáleně jej spouštět na výpočetních prostředcích Azure Databricks místo v místní relaci Sparku.
Interaktivní vývoj a ladění z libovolného integrovaného vývojového prostředí (IDE). Databricks Connect umožňuje vývojářům vyvíjet a ladit kód na výpočetních prostředcích Databricks pomocí nativních spuštěných a ladicích funkcí integrovaného vývojového prostředí ( IDE). Rozšíření Databricks Visual Studio Code používá Databricks Connect k zajištění integrovaného ladění uživatelského kódu v Databricks.
Vytváření interaktivních datových aplikací Stejně jako ovladač JDBC může být knihovna Databricks Connect vložená do libovolné aplikace pro interakci s Databricks. Databricks Connect poskytuje plnou výraznost Pythonu prostřednictvím PySparku, eliminuje problém nekompatibility programovacího jazyka SQL a umožňuje vám spouštět všechny transformace dat na platformě Databricks pomocí Spark v škálovatelné bezserverové architektuře.
Jak to funguje?
Služba Databricks Connect je založená na opensourcovém sparkovém připojení, která má oddělenou architekturu klientského serveru pro Apache Spark, která umožňuje vzdálené připojení ke clusterům Spark pomocí rozhraní DataFrame API. Základní protokol používá nevyřešené logické plány Sparku a Apache Arrow nad gRPC. Klientské rozhraní API je navržené tak, aby bylo dynamické, aby bylo možné ho vložit všude: na aplikačních serverech, prostředích IDE, poznámkových blocích a programovacích jazycích.
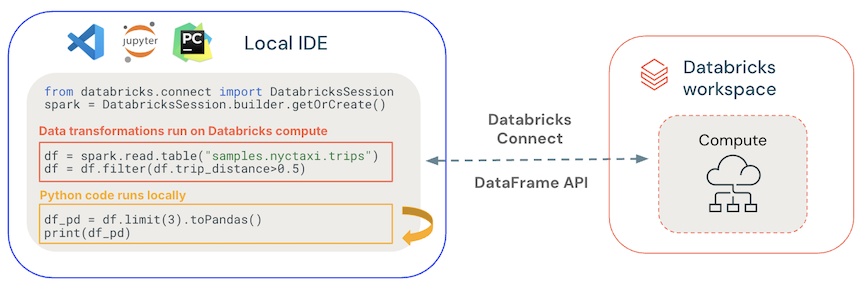
- General kód běží místně: Python a kód Scala běží na straně klienta a umožňuje interaktivní ladění. Veškerý kód se spouští místně, zatímco veškerý kód Sparku se bude dál spouštět ve vzdáleném clusteru.
-
API datového rámce se spouští na výpočetních prostředcích Databricks. Všechny transformace dat se převedou na plány Sparku a spustí se na výpočetních prostředcích Databricks prostřednictvím vzdálené relace Sparku. Jsou materializovány ve vašem místním klientovi při použití příkazů, jako jsou
collect(),show()atoPandas(). -
Kód definovaný uživatelem běží na výpočetních prostředcích Databricks: UDF definované uživatelem jsou definované místně, serializují se a přenášejí do clusteru, na kterém se spouští. Rozhraní API, která spouštějí uživatelský kód v Databricks, mezi ně patří: UDFs,
foreach,foreachBatch, atransformWithState. - Správa závislostí:
- Nainstalujte na místní počítač závislosti aplikací. Tyto běhy běží místně a musí být nainstalovány jako součást projektu, jako je například součást vašeho Python virtuálního prostředí.
- Nainstalujte závislosti UDF do Databricks. Viz Správa závislostí UDF.
Jak souvisí Databricks Connect a Spark Connect?
Spark Connect je opensourcový protokol založený na GRPC v Rámci Apache Sparku, který umožňuje vzdálené spouštění úloh Sparku pomocí rozhraní DATAFrame API.
Pro Databricks Runtime 13.3 LTS a vyšší je Databricks Connect rozšířením Spark Connect s přidanými funkcemi a úpravami pro podporu práce s výpočetními režimy Databricks a službou Unity Catalog.
Další zdroje informací
V následujících kurzech můžete rychle začít vyvíjet řešení Databricks Connect:
- Databricks Connect pro Python klasický výpočetní kurz
- Tutoriál pro bezserverové výpočty v Pythonu pomocí Databricks Connect
- Kurz klasického výpočetního prostředí Databricks Connect pro Scala
- Výukový program Databricks Connect pro Scalu a bezserverový výpočet
- Kurz pro Databricks Connect pro R
Ukázkové aplikace, které používají Databricks Connect, najdete v úložišti příkladů GitHub, které zahrnují následující příklady: