Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležitý
Tato funkce je v Beta.
Důležitý
Tato stránka popisuje použití zkušební verze 0.22 agenta s MLflow 2. Databricks doporučuje používat MLflow 3, které je integrováno s hodnocením agenta >1.0. V MLflow 3 jsou nyní rozhraní API pro vyhodnocení agenta součástí balíčku mlflow.
Informace o tomto tématu najdete v tématu Monitorování kvality produkce (automatické spouštění výkonnostních metrik).
Tato stránka popisuje, jak nastavit monitorování pro generující aplikace AI nasazené pomocí architektury agenta Mosaic AI. Obecné informace o používání monitorování, například schématu výsledků, zobrazení výsledků, používání uživatelského rozhraní, přidávání výstrah a správy monitorování, najdete v tématu Co je monitorování Lakehouse pro generování umělé inteligence? (MLflow 2).
Monitorování Lakehouse pro generativní AI vám pomůže sledovat provozní metriky, jako je objem, latence, chyby a náklady, a také metriky kvality, jako je správnost a dodržování pokynů, pomocí hodnocení agenta Mosaic AI.
Jak funguje monitorování:

uživatelské rozhraní monitorování:
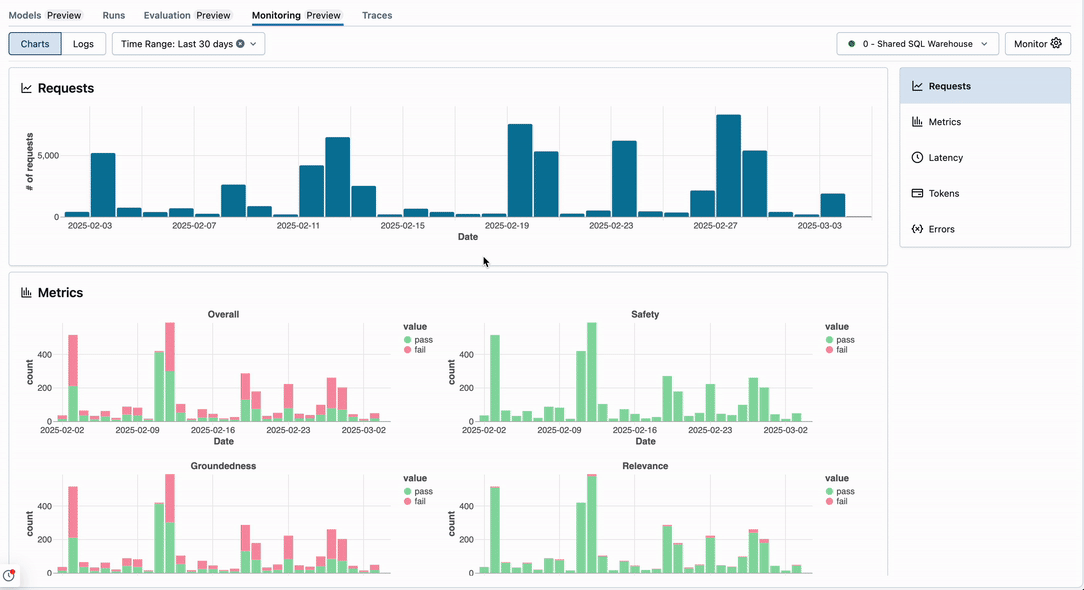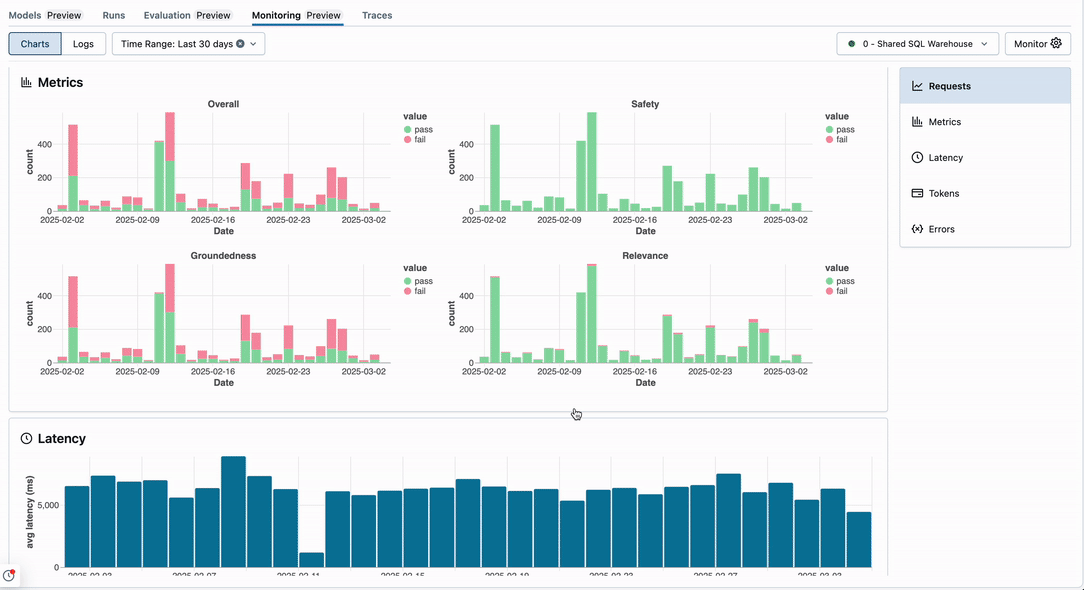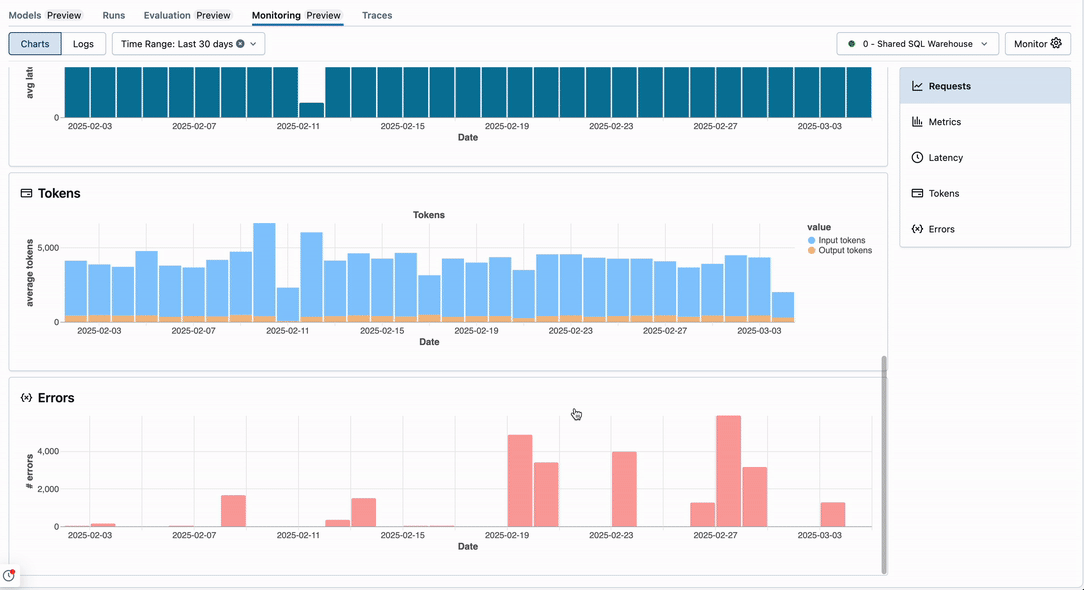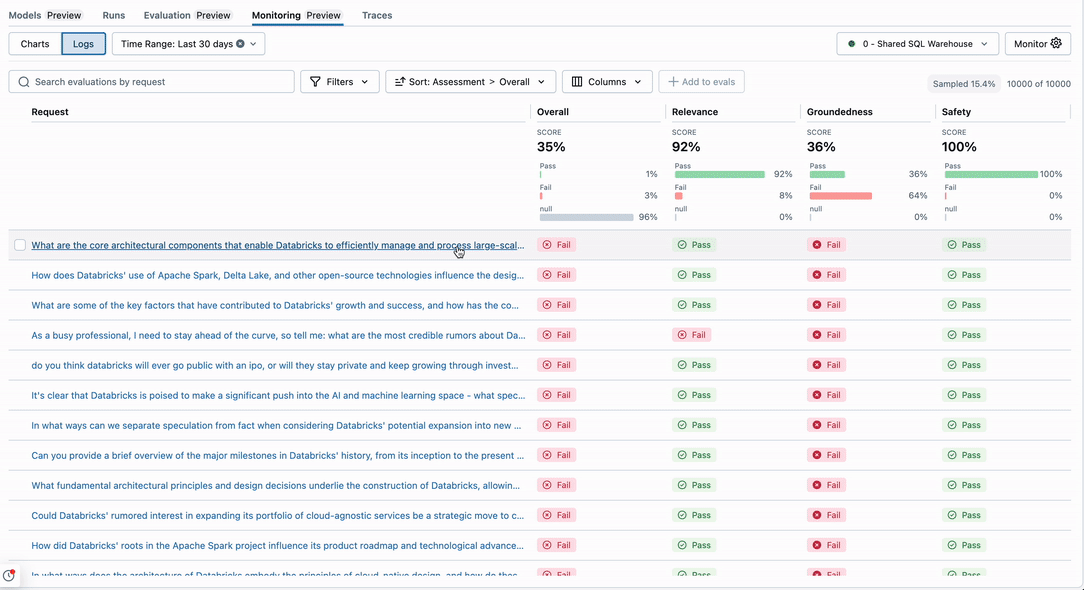
Požadavky
- Nainstalujte sadu SDK databricks-agents do notebooku Databricks.
%pip install databricks-agents>=0.22.0
dbutils.library.restartPython()
- Bezserverové úlohy musí být povolené.
- Metriky LLM Judge vyžadují, aby byly povoleny asistenční funkce partnery poháněné umělé inteligence. Ostatní metriky, jako je latence, se podporují bez ohledu na toto nastavení.
- Tvůrce koncového bodu (uživatel nasazující agenta) musí mít
CREATE VOLUMEoprávnění ke schématu vybranému k uložení tabulek odvozování v době nasazení. Tím zajistíte, že se ve schématu dají vytvořit relevantní tabulky posouzení a protokolování. Viz Povolení a zakázání odvozovacích tabulek.
Omezení
Důležitý
- Stopy mohou být dostupné prostřednictvím uživatelského rozhraní až za 2 hodiny.
- Výpočet metrik kvality může zabrat dalších 15 minut poté, co se trasování objeví v uživatelském rozhraní monitorování.
Další podrobnosti najdete v tématu Monitorování provádění a plánování.
Pokud potřebujete nižší latenci, obraťte se na zástupce účtu Databricks.
Nastavení monitorování
Při nasazování agentů vytvořených pomocí ChatAgent nebo ChatModel pomocí agents.deployse automaticky nastaví základní monitorování. To zahrnuje:
- Požadavek na sledování objemu
- Metriky latence
- Záznam chyb
Toto automatické monitorování nezahrnuje konkrétní metriky vyhodnocení, jako je dodržování pokynů nebo bezpečnost, ale poskytuje základní telemetrii ke sledování využití a výkonu vašeho agenta.
Doporučení
Chcete-li do monitorování zahrnout zpětnou vazbu od koncových uživatelů 👍 nebo 👎, podívejte se na pokyny v části Poskytnutí zpětné vazby k nasazenému agentovi (experimentální) pro připojení zpětné vazby k tabulce inference.
Konfigurace metrik monitorování agenta
Pokud chcete do automatického monitorování přidat metriky vyhodnocení, použijte metodu update_monitor:
Důležitý
Monitor musí být připojen k experimentu MLflow. Každý experiment může mít pouze jeden připojený monitor (pro jeden koncový bod). Ve výchozím nastavení: update_monitor a create_monitor používají experiment MLflow notebooku. Pokud chcete toto chování přepsat a vybrat jiný experiment, použijte parametr experiment_id.
from databricks.agents.monitoring import update_monitor, AssessmentsSuiteConfig, BuiltinJudge, GuidelinesJudge
monitor = update_monitor(
endpoint_name = "model-serving-endpoint-name",
assessments_config = AssessmentsSuiteConfig(
sample=1.0, # Sample 100% of requests
assessments=[
# Builtin judges: "safety", "groundedness", "relevance_to_query", "chunk_relevance"
BuiltinJudge(name='safety'), # or {'name': 'safety'}
BuiltinJudge(name='groundedness', sample_rate=0.4), # or {'name': 'groundedness', 'sample_rate': 0.4}
BuiltinJudge(name='relevance_to_query'), # or {'name': 'relevance_to_query'}
BuiltinJudge(name='chunk_relevance'), # or {'name': 'chunk_relevance'}
# Create custom judges with the guidelines judge.
GuidelinesJudge(guidelines={
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}),
],
)
)
U agentů, kteří nejsou nasazeni s automatickým monitorováním, můžete nastavit monitorování pomocí metody create_monitor:
from databricks.agents.monitoring import create_monitor, AssessmentsSuiteConfig, BuiltinJudge, GuidelinesJudge
monitor = create_monitor(
endpoint_name = "model-serving-endpoint-name",
assessments_config = AssessmentsSuiteConfig(
sample=1.0, # Sample 100% of requests
assessments=[
# Builtin judges: "safety", "groundedness", "relevance_to_query", "chunk_relevance"
BuiltinJudge(name='safety'), # or {'name': 'safety'}
BuiltinJudge(name='groundedness', sample_rate=0.4), # or {'name': 'groundedness', 'sample_rate': 0.4}
BuiltinJudge(name='relevance_to_query'), # or {'name': 'relevance_to_query'}
BuiltinJudge(name='chunk_relevance'), # or {'name': 'chunk_relevance'}
# Create custom judges with the guidelines judge.
GuidelinesJudge(guidelines={
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}),
],
)
)
Obě metody mají následující vstupy:
-
endpoint_name: str– název modelu obsluhujícího koncový bod pro monitorování. -
assessments_config: AssessmentsSuiteConfig | dict– Konfigurace pro posouzení vypočítaná monitorem. Podporují se následující parametry:-
[Optional] sample: float- Globální vzorkovací frekvence, což znamená podíl požadavků na výpočet hodnocení (od 0 do 1). Výchozí hodnota je 1,0 (výpočetní hodnocení pro veškerý provoz). -
[Optional] paused: bool- Zda je monitor pozastaven. -
[Optional] assessments: list[BuiltinJudge | GuidelinesJudge]Seznam hodnocení, která jsou buď vestavěná rozhodčí, nebo rozhodčí podle pokynů.
-
-
[Optional] experiment_id: Experiment MLflow, ve kterém se zobrazí výsledky monitorování. Pokud není zadán, monitor použije stejný experiment, ve kterém byl agent původně zaznamenán.
BuiltinJudge přijímá následující argumenty:
-
name: str- Jeden z integrovaných porotců podporuje monitorování: "bezpečnost", "uzemnění", "relevance_to_query", "chunk_relevance". Další podrobnosti o předdefinovaných porotcích najdete v tématu Předdefinované soudce. -
[Optional] sample_rate: float- Zlomek požadavků na výpočet tohoto hodnocení (od 0 do 1). Výchozí hodnota je globální vzorkovací frekvence.
GuidelinesJudge přijímá následující argumenty:
-
guidelines: dict[str, list[str]]- Slovník obsahující názvy pokynů a pokyny ve formátu prostého textu, které se používají k ověření požadavku nebo odpovědi. Další podrobnosti o pokynech najdete v tématu Dodržování zásad. -
[Optional] sample_rate: float- Zlomek požadavků na výpočet pokynů (mezi 0 a 1). Výchozí hodnota je globální vzorkovací frekvence.
Další podrobnosti najdete v dokumentaci k sadě Python SDK.
Po vytvoření monitoru se ve výstupu buňky zobrazí odkaz na uživatelské rozhraní monitoru. Výsledky vyhodnocení lze zobrazit v tomto uživatelském rozhraní a jsou uloženy v monitor.evaluated_traces_table. Pokud chcete zobrazit vyhodnocené řádky, spusťte:
display(spark.table(monitor.evaluated_traces_table).filter("evaluation_status != 'skipped'"))
Monitorování provádění a plánování
Důležitý
- Stopy mohou být dostupné prostřednictvím uživatelského rozhraní až za 2 hodiny.
- Po zobrazení trasování v uživatelském rozhraní monitorování může výpočet metrik kvality trvat dalších 30 minut.
Když vytvoříte monitor, zahájí proces, který vyhodnocuje vzorek požadavků na váš koncový bod za posledních 30 dnů. Dokončení tohoto počátečního vyhodnocení může trvat několik hodin v závislosti na objemu požadavků a vzorkovací frekvenci.
Když je na váš koncový bod učiněn požadavek, stane se toto:
- Požadavek a jeho MLflow Trace jsou zaznamenány do tabulky inferencí (15 až 30 minut).
- Naplánovaná úloha rozbalí tabulku odvozování do dvou samostatných tabulek:
request_log, která obsahuje požadavek a trasování, aassessment_logs, která obsahuje zpětnou vazbu uživatele (úloha se spouští každou hodinu). - Úloha monitorování vyhodnocuje zadanou ukázku požadavků (úloha se spouští každých 15 minut).
Zkombinované tyto kroky znamenají, že zobrazení požadavků v uživatelském rozhraní monitorování může trvat až 2,5 hodiny.
Monitorování jsou podporována pracovními postupy Databricks. Chcete-li ručně aktivovat aktualizaci monitoru (krok 3), vyhledejte pracovní postup s názvem [<endpoint_name>] Agent Monitoring Job a klikněte na Spustit nyní.
Pokud potřebujete nižší latenci, obraťte se na zástupce účtu Databricks.
Ukázkový poznámkový blok
Následující příklad zaznamenává a nasazuje jednoduchého agenta, a poté na něj povolí monitorování.
Ukázkový blok poznámek pro monitorování agenta
Získej poznámkový blok