Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento kurz vás provede použitím poznámkového bloku Azure Databricks k dotazování ukázkových dat uložených v katalogu Unity pomocí SQL, Pythonu, Scaly a R a následné vizualizace výsledků dotazu v poznámkovém bloku.
Návod
Řekněte Genie Code (režim agenta), aby to udělal za vás:
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
Požadavky
K dokončení úkolů v tomto článku musíte splňovat následující požadavky:
- Váš pracovní prostor musí mít katalog Unity povolený. Informace o tom, jak začít s katalogem Unity, najdete v tématu Začínáme s katalogem Unity.
- Musíte mít oprávnění k používání existujícího výpočetního prostředku nebo k vytvoření nového výpočetního prostředku. Podívejte se na Compute nebo se obraťte na správce Databricks.
Krok 1: Vytvoření nového poznámkového bloku
Chcete-li vytvořit poznámkový blok v pracovním prostoru, klepněte na tlačítko ![]() Nový na bočním panelu a potom klepněte na příkaz Poznámkový blok. V pracovním prostoru se otevře prázdný poznámkový blok.
Nový na bočním panelu a potom klepněte na příkaz Poznámkový blok. V pracovním prostoru se otevře prázdný poznámkový blok.
Další informace o vytváření a správě poznámkových bloků najdete v tématu Správa poznámkových bloků Databricks.
Krok 2: Proveďte dotaz na tabulku
Dotazování tabulky samples.nyctaxi.trips v katalogu Unity pomocí jazyka podle vašeho výběru Tato tabulka je jednou z ukázkových datových sad zahrnutých v samples katalogu.
Zkopírujte a vložte následující kód do nové prázdné buňky poznámkového bloku. Tento kód zobrazí výsledky dotazování
samples.nyctaxi.tripstabulky v katalogu Unity.SQL
SELECT * FROM samples.nyctaxi.tripsPython
display(spark.read.table("samples.nyctaxi.trips"))Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Stisknutím klávesy
Shift+Enterspusťte buňku a přejděte na další buňku.Výsledky dotazu se zobrazí v poznámkovém bloku.
Krok 3: Zobrazení dat
Zobrazí průměrnou částku jízdného podle vzdálenosti jízdy seskupené podle PSČ vyzvednutí.
Vedle záložky Tabulka klikněte, + a potom klikněte na Vizualizace.
Zobrazí se editor vizualizací.
V rozevíracím seznamu Typ vizualizace ověřte, že je vybrán Bar.
Vyberte
fare_amountsloupec X.Vyberte
trip_distancepro sloupec Y.Vyberte
Averagejako typ agregace.Vyberte
pickup_zipjako sloupec Seskupovat podle .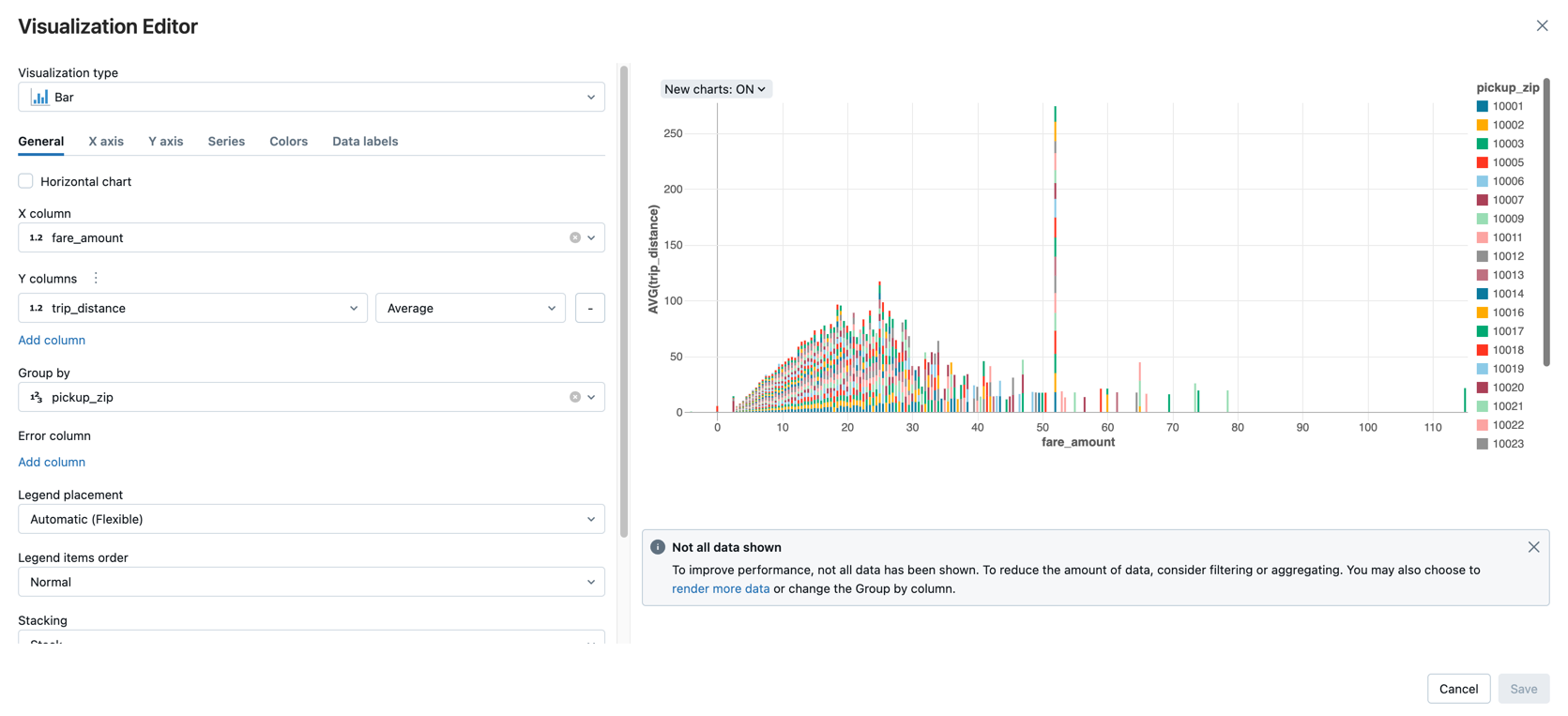
Klikněte na Uložit.
Další kroky
- Další informace o přidávání dat ze souboru CSV do katalogu Unity a vizualizaci dat najdete v tématu Kurz: Import a vizualizace dat CSV z poznámkového bloku.
- Informace o načtení dat do Databricks pomocí Apache Sparku najdete v kurzu : Načtení a transformace dat pomocí datových rámců Apache Spark.
- Další informace o ingestování dat do Databricks najdete v tématu Standardní konektory v Lakeflow Connect.
- Další informace o dotazování dat pomocí Databricks najdete v tématu Dotazování dat.
- Další informace o vizualizacích najdete v tématu Vizualizace v poznámkových blocích Databricks a editoru SQL.
- Další informace o technikách průzkumné analýzy dat (EDA) najdete v tématu Kurz: Techniky EDA využívající poznámkové bloky Databricks.