Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Seznamte se s deklarativními kanály Sparku (SDP) Lakeflow, základními koncepty (například kanály, streamovacími tabulkami a materializovanými zobrazeními), které je definují, vztahy mezi těmito koncepty a výhodami jeho používání v pracovních postupech zpracování dat.
Poznámka:
Deklarativní kanály Sparku Lakeflow vyžadují plán Premium. Další informace získáte od týmu účtu Databricks.
Co je SDP?
Deklarativní kanály Sparku Lakeflow jsou deklarativní rozhraní pro vývoj a spouštění dávkových a streamovaných datových kanálů v SQL a Pythonu. Lakeflow SDP se rozšiřuje a je kompatibilní s deklarativními kanály Apache Spark, přičemž běží na modulu Runtime optimalizovaném pro výkon. API Lakeflow Spark deklarativních kanálů flows využívá stejné rozhraní API DataFrame jako Apache Spark a strukturované streamování. Mezi běžné případy použití SDP patří přírůstkové příjem dat ze zdrojů, jako je cloudové úložiště (včetně Amazon S3, Azure ADLS Gen2 a Google Cloud Storage) a sběrnice zpráv (například Apache Kafka, Amazon Kinesis, Google Pub/Sub, Azure EventHub a Apache Pulsear), přírůstkové dávkové transformace a transformace streamování s bezstavovými a stavovými operátory a zpracování datových proudů v reálném čase mezi transakčními úložišti, jako jsou sběrnice zpráv a databáze.
Další podrobnosti o deklarativním zpracování dat najdete v tématu Procedurální a deklarativní zpracování dat v Databricks.
Jaké jsou výhody SDP?
Deklarativní povaha protokolu SDP poskytuje následující výhody v porovnání s vývojem datových procesů pomocí rozhraní Apache Spark a rozhraní API strukturovaného streamování Sparku a jejich spouštění pomocí modulu Databricks Runtime pomocí ruční orchestrace prostřednictvím úloh Lakeflow.
- Automatická orchestrace: SDP orchestruje kroky zpracování (označované jako "toky") automaticky, aby se zajistilo správné pořadí provádění a maximální úroveň paralelismu pro optimální výkon. Kanály navíc automaticky a efektivně opakují přechodné selhání. Proces opakování začíná nejpodrobnější a nákladově efektivní jednotkou: úlohou Sparku. Pokud opakování na úrovni úlohy selže, protokol SDP pokračuje opakováním toku a nakonec opakuje celý tok, pokud je to nutné.
- Deklarativní zpracování: SDP poskytuje deklarativní funkce, které můžou snížit stovky nebo dokonce tisíce řádků ručního kódu Sparku a strukturovaného streamování na několik řádků. Rozhraní API SDP AUTO CDC zjednodušuje zpracování událostí cdc (Change Data Capture) s podporou SCD Type 1 i SCD Type 2. Eliminuje potřebu ručního kódu pro zpracování událostí mimo pořadí a nevyžaduje pochopení sémantiky streamování ani konceptů, jako jsou vodoznaky.
- Přírůstkové zpracování: SDP poskytuje modul pro přírůstkové zpracování pro materializovaná zobrazení. Pokud ji chcete použít, napíšete logiku transformace s dávkovou sémantikou a modul bude zpracovávat nová data a změny ve zdrojích dat vždy, když je to možné. Přírůstkové zpracování snižuje neefektivní opětovné zpracování při výskytu nových dat nebo změn ve zdrojích a eliminuje potřebu ručního kódu pro zpracování přírůstkového zpracování.
Klíčové koncepty
Následující diagram znázorňuje nejdůležitější koncepty deklarativních kanálů Lakeflow Sparku.
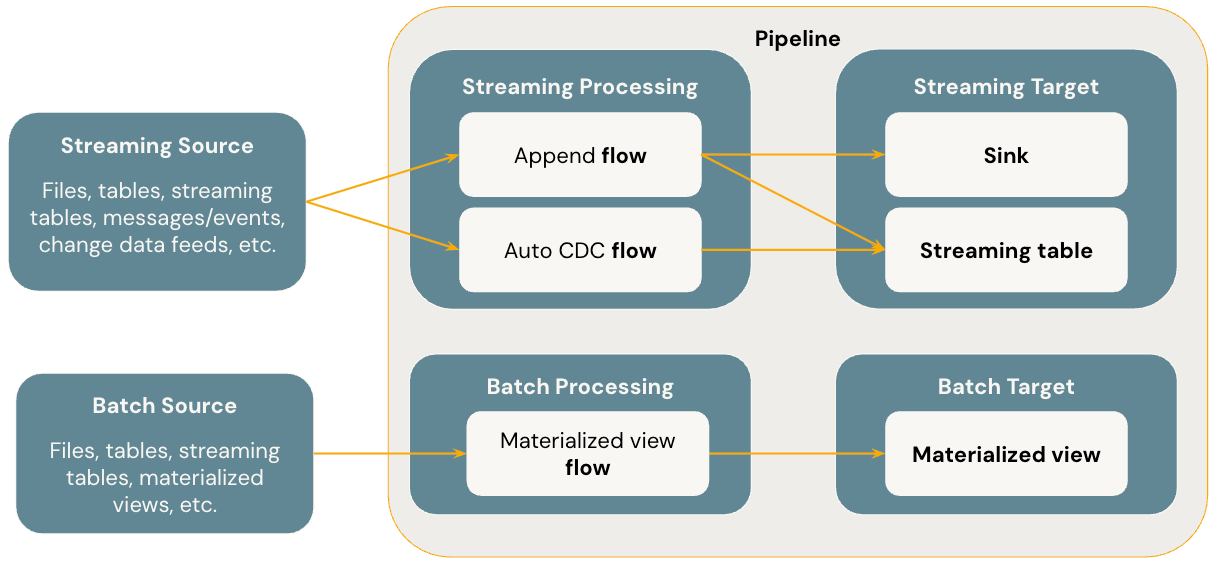
Flows
Tok je základní koncept zpracování dat v protokolu SDP, který podporuje sémantiku streamování i dávkového zpracování. Tok čte data ze zdroje, použije uživatelsky definovanou logiku zpracování a zapíše výsledek do cíle. SDP sdílí stejný typ toku streamování (připojení, aktualizace, dokončení) jako strukturované streamování Sparku. (V současné době je vystaven pouze tok připojení .) Další podrobnosti najdete v režimech výstupu ve strukturovaném streamování.
Deklarativní kanály Sparku pro Lakeflow také poskytují další typy toků:
- AUTO CDC je jedinečný tok streamování v Lakeflow SDP, který zpracovává neuspořádané události CDC a podporuje SCD Type 1 i SCD Type 2. Automatické CDC není k dispozici v deklarativních kanálech Apache Sparku.
- Materializované zobrazení je dávkové tok v SDP, který zpracovává pouze nová data a změny ve zdrojových tabulkách, kdykoli je to možné.
Další podrobnosti najdete tady:
Tabulky streamování
Streamovací tabulka je forma tabulky spravované Katalogem Unity, která je také streamovacím cílem pro Lakeflow SDP. Streamovací tabulka může obsahovat jeden nebo více toků streamování (Append, AUTO CDC), které jsou do ní zapisovány. AUTO CDC je jedinečný tok streamování, který je dostupný jenom pro streamované tabulky v Databricks. Toky streamování můžete definovat explicitně a odděleně od cílové tabulky streamování. Toky streamování můžete také definovat implicitně jako součást definice tabulky streamování.
Další podrobnosti najdete tady:
Materializované pohledy
Materializovaný pohled je také formou tabulky spravované v Unity Catalog a slouží jako cíl dávkového zpracování. Materializované zobrazení může obsahovat jeden nebo více toků dat materializovaného pohledu, které jsou do něho zapsány. Materializovaná zobrazení se liší od streamovaných tabulek, ve které vždy definujete toky implicitně jako součást definice materializovaného zobrazení.
Další podrobnosti najdete tady:
Sinks
Sink je cílový bod pro streamování v datovém kanálu a podporuje Delta tabulky, Apache Kafka témata, Azure EventHubs témata a Pythonové zdroje dat. Jímka může obsahovat jeden nebo více toků streamování (připojit) zapsaných do něj.
Další podrobnosti najdete tady:
Pipelines
Kanál je jednotka vývoje a spouštění v deklarativních kanálech Lakeflow Sparku. Potrubí může obsahovat jeden nebo více toků, streamovaných tabulek, materializovaných zobrazení a úložišť. Protokol SDP použijete definováním toků, streamovaných tabulek, materializovaných zobrazení a jímek ve zdrojovém kódu kanálu a následným spuštěním kanálu. Během spouštění kanálu analyzuje závislosti definovaných toků, streamovaných tabulek, materializovaných zobrazení a jímek a orchestruje jejich pořadí provádění a paralelizace automaticky.
Další podrobnosti najdete tady:
Kanály SQL Databricks
Streamované tabulky a materializovaná zobrazení jsou ve službě Databricks SQL dvě základní funkce. Standardní SQL můžete použít k vytváření a aktualizaci streamovaných tabulek a materializovaných zobrazení v Databricks SQL. Streamované tabulky a materializovaná zobrazení v Databricks SQL běží na stejné infrastruktuře Azure Databricks a mají stejnou sémantiku zpracování jako v deklarativních kanálech Sparku Lakeflow. Při použití streamovaných tabulek a materializovaných zobrazení v Databricks SQL jsou toky definovány implicitně jako součást streamovaných tabulek a materializovaných zobrazení definice.
Další podrobnosti najdete tady: