Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje dva běžné vzory pro přesun artefaktů ML prostřednictvím přípravy a do produkčního prostředí. Asynchronní povaha změn v modelech a kódu znamená, že existuje více možných vzorů, které může vývojový proces strojového učení následovat.
Modely se vytvářejí pomocí kódu, ale výsledné artefakty modelu a kód, který je vytvořil, můžou fungovat asynchronně. To znamená, že nové verze modelu a změny kódu nemusí probíhat současně. Uvažujme například následující scénáře:
- K detekci podvodných transakcí vyvíjíte proces zpracování ML, který každý týden přetrénuje model. Kód se nemusí velmi často měnit, ale model se může každý týden znovu natrénovat, aby zahrnoval nová data.
- Pro klasifikaci dokumentů můžete vytvořit velkou hlubokou neurální síť. V tomto případě je trénování modelu výpočetně nákladné a časově náročné a opakované trénování modelu pravděpodobně proběhne zřídka. Kód, který nasazuje, obsluhuje a monitoruje tento model, se ale dá aktualizovat bez opětovného trénování modelu.
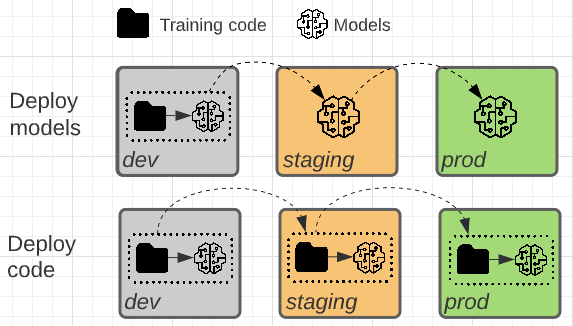
Tyto dva vzory se liší tím, zda je směrem k použití v produkčním prostředí povýšen artefakt modelu nebo trénovací kód, který vytváří artefakt modelu.
Nasazení kódu (doporučeno)
Ve většině situací doporučuje Databricks přístup "nasadit kód". Tento přístup je začleněn do doporučeného pracovního postupu MLOps.
V tomto modelu se kód pro trénování modelů vyvíjí ve vývojovém prostředí. Stejný kód se přesune do přípravného a poté produkčního prostředí. Model je trénován v každém prostředí: zpočátku ve vývojovém prostředí jako součást vývoje modelu, ve stagingu (na omezené podmnožině dat) v rámci integračních testů a v produkčním prostředí (na úplných produkčních datech) pro vytvoření konečného modelu.
Výhody:
- V organizacích, kde je přístup k produkčním datům omezený, umožňuje tento model trénovat na produkčních datech v produkčním prostředí.
- Automatizované přetrénování modelů je bezpečnější, protože trénovací kód se kontroluje, testuje a schválí pro produkční prostředí.
- Podpůrný kód se řídí stejným vzorem jako trénovací kód modelu. Oba projdou integračními testy v přípravné fázi.
Nevýhody:
- Křivka učení pro datové vědce, kteří předávají kód spolupracovníkům, může být strmá. Předdefinované šablony projektů a pracovní postupy jsou užitečné.
V tomto modelu musí být datoví vědci schopni zkontrolovat výsledky trénování z produkčního prostředí, protože mají znalosti k identifikaci a opravě problémů specifických pro ML.
Pokud vaše situace vyžaduje, aby byl model vytrénován v rámci přípravy přes úplnou produkční datovou sadu, můžete použít hybridní přístup nasazením kódu do přípravy, trénování modelu a následným nasazením modelu do produkčního prostředí. Tento přístup šetří náklady na trénování v produkčním prostředí, ale přidává další provozní náklady v přípravném prostředí.
Nasadit modely
V tomto vzoru se artefakt modelu generuje trénovacím kódem ve vývojovém prostředí. Artefakt se pak před nasazením do produkčního prostředí testuje v přípravném prostředí.
Tuto možnost zvažte, pokud platí jedna nebo více z následujících možností:
- Trénování modelu je velmi nákladné nebo obtížné reprodukovat.
- Veškerá práce se provádí v jednom pracovním prostoru Azure Databricks.
- Nepracujete s externími úložištěmi ani s procesem CI/CD.
Výhody:
- Jednodušší předání datovým vědcům
- V případech, kdy je trénování modelu nákladné, vyžaduje pouze jedno trénování modelu.
Nevýhody:
- Pokud produkční data nejsou přístupná z vývojového prostředí (což může být pravdivé z bezpečnostních důvodů), tato architektura nemusí být proveditelná.
- Automatizované přetrénování modelů je v tomto modelu složité. Můžete automatizovat opětovné trénování ve vývojovém prostředí, ale tým zodpovědný za nasazení modelu v produkčním prostředí nemusí výsledný model přijmout jako připravený pro produkční prostředí.
- Podpůrný kód, jako jsou kanály používané pro přípravu funkcí, odvozování a monitorování, je potřeba nasadit do produkčního prostředí samostatně.
Prostředí (vývoj, příprava nebo produkce) obvykle odpovídá katalogu v Unity Catalog. Podrobnosti o tom, jak tento model implementovat, najdete v průvodci upgradem.
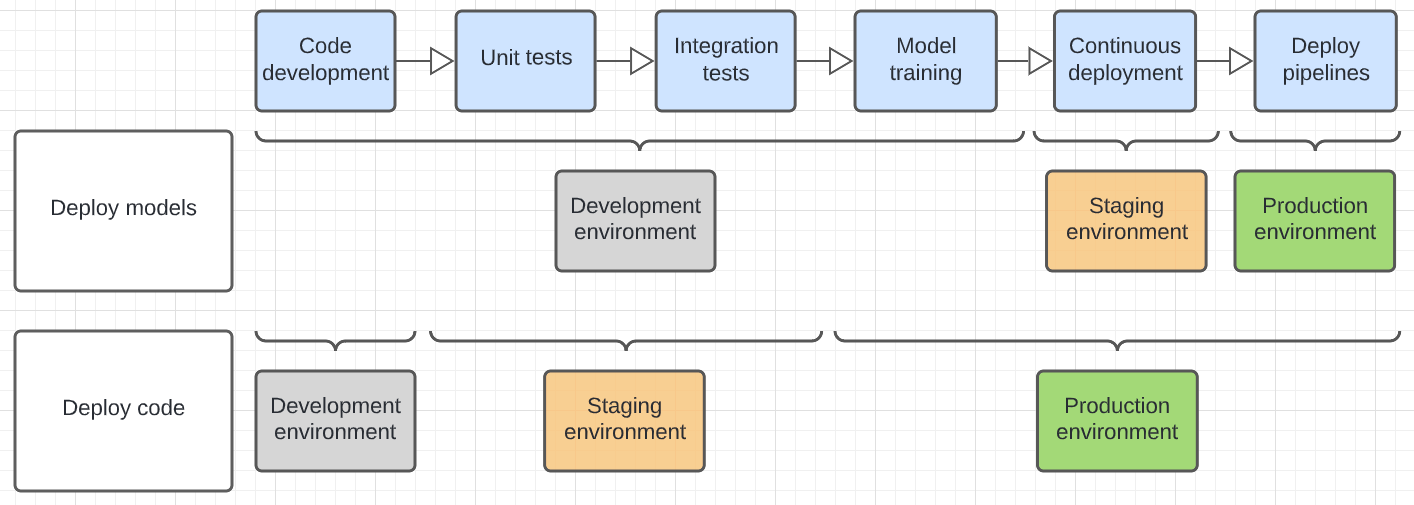
Následující diagram kontrastuje životní cyklus kódu pro výše uvedené vzory nasazení v různých spouštěcích prostředích.
Prostředí zobrazené v diagramu je konečné prostředí, ve kterém se spustí krok. Například v modelu nasazení modelů se ve vývojovém prostředí provádí finální testování jednotek a integrace. V modelu nasazení kódu se testy jednotek a integrační testy spouští ve vývojových prostředích a konečné testování jednotek a integračního testování se provádí v přípravném prostředí.