Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje, jak můžete pomocí MLOps na platformě Databricks optimalizovat výkon a dlouhodobou efektivitu systémů strojového učení (ML). Zahrnuje obecná doporučení pro architekturu MLOps a popisuje generalizovaný pracovní postup pomocí platformy Databricks, kterou můžete použít jako model pro proces vývoje a produkčního procesu ML. Úpravy tohoto pracovního postupu pro aplikace LLMOps najdete v pracovních postupech LLMOps.
Další podrobnosti najdete v tématu Velká kniha MLOps.
Co je MLOps?
MLOps je sada procesů a automatizovaných kroků pro správu kódu, dat a modelů za účelem zlepšení výkonu, stability a dlouhodobé efektivity systémů ML. Kombinuje DevOps, DataOps a ModelOps.

Prostředky ML, jako jsou kód, data a modely, se vyvíjejí ve fázích, které se vyvíjejí od raných fází vývoje, které nemají úzká omezení přístupu a nejsou pečlivě testovány prostřednictvím přechodné fáze testování do konečné fáze výroby, která je přísně řízena. Platforma Databricks umožňuje spravovat tyto prostředky na jedné platformě s jednotným řízením přístupu. Na stejné platformě můžete vyvíjet datové aplikace a aplikace ML, což snižuje rizika a zpoždění spojená s přesouváním dat.
Obecná doporučení pro MLOps
Tato část obsahuje některá obecná doporučení pro MLOps v Databricks s odkazy na další informace.
Vytvoření samostatného prostředí pro každou fázi
Spouštěcí prostředí je místo, kde se modely a data vytvářejí nebo využívají kódem. Každé spouštěcí prostředí se skládá z výpočetních instancí, jejich modulů runtime a knihoven a automatizovaných úloh.
Databricks doporučuje vytvářet samostatná prostředí pro různé fáze vývoje kódu ML a modelu s jasně definovanými přechody mezi fázemi. Pracovní postup popsaný v tomto článku se řídí tímto procesem pomocí běžných názvů fází:
Další konfigurace se dají použít také ke splnění konkrétních potřeb vaší organizace.
Řízení přístupu a správa verzí
Řízení přístupu a správa verzí jsou klíčovými komponentami jakéhokoli procesu softwarového provozu. Databricks doporučuje následující:
- Použijte Git pro správu verzí. Kanály a kód by měly být uložené v Gitu pro správu verzí. Přesun logiky ML mezi fázemi je pak možné interpretovat jako přesun kódu z vývojové větve do přípravné větve do větve vydané verze. Pomocí složek Git Databricks můžete integrovat s vaším poskytovatelem Gitu a synchronizovat poznámkové bloky a zdrojový kód s pracovními prostory Databricks. Databricks také poskytuje další nástroje pro integraci Gitu a správu verzí; viz místní vývojové nástroje.
- Data můžete ukládat v architektuře lakehouse pomocí tabulek Delta. Data by se měla ukládat v lakehouse architektuře ve vašem cloudovém účtu. Nezpracovaná data i tabulky funkcí by se měly ukládat jako tabulky Delta s řízením přístupu, aby bylo možné určit, kdo je může číst a upravovat.
- Správa vývoje modelů pomocí MLflow Pomocí MLflow můžete sledovat proces vývoje modelu a ukládat snímky kódu, parametry modelu, metriky a další metadata.
- Ke správě životního cyklu modelu použijte modely v katalogu Unity. Použijte modely v katalogu Unity ke správě verzování modelů, řízení a stavu nasazení.
Nasazujte kód, ne modely
Ve většině situací databricks doporučuje, abyste během procesu vývoje STROJOVÉho učení propagovali kód místo modelů z jednoho prostředí na další. Přesun prostředků projektu tímto způsobem zajišťuje, že veškerý kód v procesu vývoje ML prochází stejnými procesy kontroly kódu a procesu testování integrace. Také zajišťuje, aby produkční verze modelu byla natrénována v produkčním kódu. Podrobnější diskuzi o možnostech a kompromisech najdete v tématu Vzory nasazení modelu.
Doporučený pracovní postup MLOps
Následující části popisují typický pracovní postup MLOps, který pokrývá každou ze tří fází: vývoj, přípravu a produkci.
Tato část používá termíny "datový vědec" a "technik ML" jako archetypal personas; konkrétní role a zodpovědnosti v pracovním postupu MLOps se budou mezi týmy a organizacemi lišit.
Vývojová fáze
Cílem fáze vývoje je experimentování. Datoví vědci vyvíjejí funkce a modely a spouští experimenty za účelem optimalizace výkonu modelu. Výstupem procesu vývoje je kód kanálu ML, který může zahrnovat výpočty funkcí, trénování modelu, odvozování a monitorování.
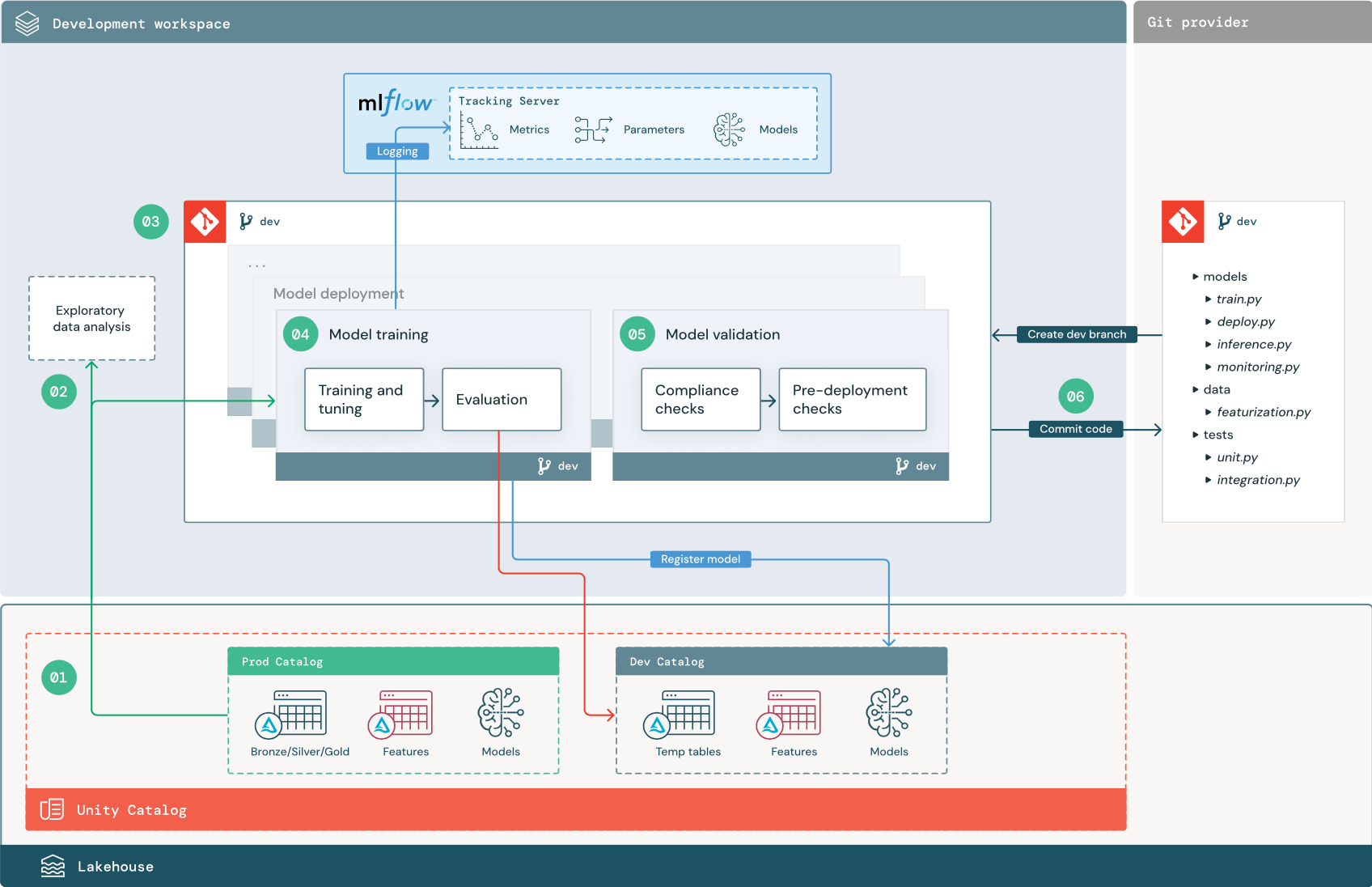
Číslovaný postup odpovídá číslům uvedeným v diagramu.
1. Zdroje dat
Vývojové prostředí představuje vývojový katalog v katalogu Unity. Datoví vědci mají přístup pro čtení a zápis do vývojového katalogu při vytváření dočasných dat a tabulek funkcí v pracovním prostoru pro vývoj. Modely vytvořené ve fázi vývoje se zaregistrují do vývojového katalogu.
V ideálním případě mají datoví vědci pracující ve vývojovém pracovním prostoru také přístup jen pro čtení k produkčním datům v prod katalogu. Povolení přístupu datových vědců ke čtení produkčních dat, odvozování tabulek a tabulek metrik v katalogu prod jim umožňuje analyzovat predikce a výkon aktuálního produkčního modelu. Datoví vědci by také měli být schopni načíst produkční modely pro experimentování a analýzu.
Pokud není možné udělit přístup jen pro čtení k prod katalogu, můžete do vývojového katalogu zapsat snímek produkčních dat, který datovým vědcům umožní vyvíjet a vyhodnocovat kód projektu.
2. Průzkumná analýza dat (EDA)
Datoví vědci prozkoumávají a analyzují data v interaktivním iterativním procesu pomocí poznámkových bloků. Cílem je posoudit, jestli dostupná data mají potenciál k vyřešení obchodního problému. V tomto kroku začne datový vědec identifikovat kroky přípravy a featurizace dat pro trénování modelu. Tento ad hoc proces obecně není součástí zpracovatelského řetězce, který bude nasazen v jiných prostředích spuštění.
AutoML tento proces zrychluje generováním standardních modelů pro datovou sadu. AutoML provádí a zaznamenává sadu zkušebních verzí a poskytuje poznámkový blok Pythonu se zdrojovým kódem pro každé zkušební spuštění, abyste mohli kód zkontrolovat, reprodukovat a upravit. AutoML také vypočítá souhrnnou statistiku datové sady a uloží tyto informace do poznámkového bloku, který si můžete prohlédnout.
3. Kód
Úložiště kódu obsahuje všechny kanály, moduly a další soubory projektu pro projekt ML. Datoví vědci vytvářejí nové nebo aktualizované kanály ve vývojové ("vývojové") větvi úložiště projektu. Počínaje EDA a počátečními fázemi projektu by datoví vědci měli pracovat v úložišti za účelem sdílení kódu a sledování změn.
4. Trénování modelu (vývoj)
Datoví vědci vyvíjejí proces pro trénování modelu ve vývojovém prostředí pomocí tabulek z vývojových nebo produkčních katalogů.
Tento pipeline zahrnuje 2 úlohy:
Školení a optimalizace. Proces trénování protokoluje parametry modelu, metriky a artefakty na server pro sledování MLflow. Po trénování a ladění hyperparametrů se konečný artefakt modelu uloží na sledovací server, aby zaznamenal propojení mezi modelem, vstupními daty, na kterých byl natrénován, a kódem použitým k jeho vygenerování.
Vyhodnocení: Vyhodnoťte kvalitu modelu testováním uložených dat. Výsledky těchto testů se protokolují na server pro sledování MLflow. Účelem vyhodnocení je určit, jestli nově vyvinutý model funguje lépe než aktuální produkční model. Vzhledem k dostatečným oprávněním lze do vývojového pracovního prostoru načíst jakýkoli produkční model zaregistrovaný v katalogu pro vývoj a porovnat ho s nově natrénovaným modelem.
Pokud požadavky vaší organizace na zásady správného řízení obsahují další informace o modelu, můžete ho uložit pomocí sledování MLflow. Typické artefakty jsou popisy prostého textu a interpretace modelů, jako jsou grafy vytvořené pomocí SHAP. Konkrétní požadavky zásad správného řízení můžou pocházet od pracovníka zásad správného řízení dat nebo obchodních zúčastněných stran.
Výstupem trénovacího kanálu modelu je artefakt modelu ML uložený na serveru pro sledování MLflow pro vývojové prostředí. Pokud se pipeline spustí v testovacím nebo produkčním pracovním prostoru, artefakt modelu se uloží na MLflow Tracking server pro tento pracovní prostor.
Po dokončení trénování modelu zaregistrujte model do katalogu Unity. Nastavte kód kanálu pro registraci modelu do katalogu odpovídajícímu prostředí, ve které byl kanál modelu spuštěn; v tomto příkladu katalog vývojářů.
S doporučenou architekturou nasadíte pracovní postup Multitask Databricks, ve kterém první úlohou je trénovací kanál modelu, následovaný ověřením modelu a úlohami nasazení modelu. Úloha trénování modelu poskytuje identifikátor URI modelu, který může použít úloha ověření modelu. K předání tohoto identifikátoru URI do modelu můžete použít hodnoty úkolů.
5. Ověření a nasazení modelu (vývoj)
Kromě kanálu trénování modelu se v vývojovém prostředí vyvíjejí i další kanály, jako je ověření modelu a kanály nasazení modelu.
Ověření modelu Kanál ověření modelu přebírá identifikátor URI modelu z trénovacího kanálu modelu, načte model z katalogu Unity a spouští kontroly ověření.
Kontroly ověření závisí na kontextu. Můžou zahrnovat základní kontroly, jako je potvrzení formátu a požadovaná metadata, a složitější kontroly, které mohou být vyžadovány pro vysoce regulovaná odvětví, jako jsou předdefinované kontroly dodržování předpisů a potvrzení výkonu modelu u vybraných datových řezů.
Primární funkcí kanálu ověření modelu je určit, jestli má model pokračovat krokem nasazení. Pokud model projde kontrolami před nasazením, může být v katalogu Unity přiřazen alias "Challenger". Pokud kontroly selžou, proces skončí. Pracovní postup můžete nakonfigurovat tak, aby uživatelům upozorňovat na selhání ověření. Podívejte se na Přidat oznámení na úlohu.
Nasazení modelu Kanál nasazení modelu obvykle buď přímo propaguje nově natrénovaný model "Challenger" na "Champion" status pomocí aktualizace aliasu, nebo usnadňuje porovnání mezi existujícím modelem "Champion" a novým modelem "Challenger". Tento kanál může také nastavit jakoukoli požadovanou infrastrukturu odvozování, jako jsou koncové body služby Model Serving. Podrobné informace o krocích, které jsou součástí kanálu nasazení modelu, najdete v části Produkční.
6. Potvrzení kódu
Po vývoji kódu pro trénování, ověřování, nasazení a další procesy potvrdí datový vědec nebo ML inženýr změny ve vývojové větvi do systému správy verzí.
Přípravná fáze
Cílem této fáze je testování kódu kanálu ML, aby se zajistilo, že je připravený pro produkční prostředí. Veškerý kód kanálu ML se v této fázi testuje, včetně kódu pro trénování modelu a také kanálů přípravy funkcí, odvozování kódu atd.
Inženýři STROJOVÉho učení vytvoří kanál CI pro implementaci testů jednotek a integrace spuštěných v této fázi. Výstupem přípravného procesu je větev verze, která aktivuje systém CI/CD pro spuštění produkční fáze.
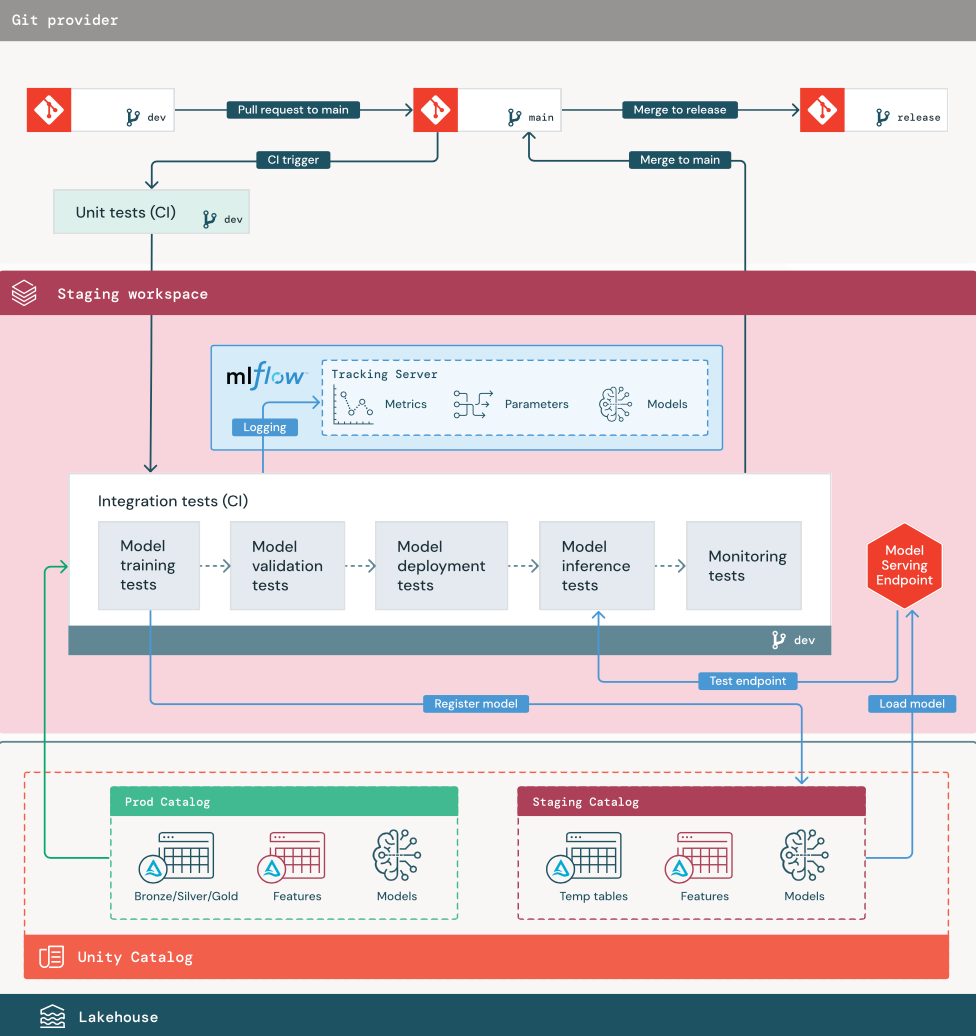
1. Data
Přípravné prostředí by mělo mít vlastní katalog v katalogu Unity pro testování kanálů ML a registraci modelů do katalogu Unity. Tento katalog se v diagramu zobrazuje jako "přípravný" katalog. Prostředky zapsané do tohoto katalogu jsou obecně dočasné a uchovávají se pouze do dokončení testování. Vývojové prostředí může také vyžadovat přístup k přípravnému katalogu pro účely ladění.
2. Sloučit kód
Datoví vědci vyvíjejí kanál trénování modelu ve vývojovém prostředí pomocí tabulek z vývojových nebo produkčních katalogů.
Žádost o přijetí změn Proces nasazení začíná, když je vytvořen pull request proti hlavní větvi projektu ve správě zdrojového kódu.
Jednotkové testy (CI). Žádost o přijetí změn automaticky sestaví zdrojový kód a aktivuje testy jednotek. Pokud jednotkové testy selžou, pull request se odmítne.
Testy jednotek jsou součástí procesu vývoje softwaru a průběžně se spouštějí a přidávají do základu kódu během vývoje libovolného kódu. Spouštění testů jednotek v rámci kanálu CI zajišťuje, že změny provedené ve vývojové větvi neporušují stávající funkce.
3. Integrační testy (CI)
Proces CI pak spustí integrační testy. Integrační testy spouštějí všechny kanály (včetně přípravy funkcí, trénování modelů, odvozování a monitorování), aby se zajistilo, že fungují správně společně. Přípravné prostředí by se mělo shodovat s produkčním prostředím tak, jak je přiměřené.
Pokud nasazujete aplikaci ML s odvozováním v reálném čase, měli byste vytvořit a otestovat obslužnou infrastrukturu v přípravném prostředí. To zahrnuje spuštění pipeline pro nasazení modelu, který vytvoří koncový bod pro obsluhu v přípravném prostředí a načte model.
Aby se zkrátila doba potřebná ke spuštění integračních testů, některé kroky mohou dělat kompromis mezi přesností testování a rychlostí či náklady. Pokud jsou například modely nákladné nebo časově náročné na trénování, můžete použít malé podmnožina dat nebo spustit méně trénovacích iterací. V závislosti na požadavcích na produkční prostředí můžete v integračních testech provádět kompletní zátěžové testování nebo můžete testovat jen malé dávkové úlohy nebo požadavky na dočasný koncový bod.
4. Sloučení do přípravné větve
Pokud všechny testy projdou, nový kód se sloučí do hlavní větve projektu. Pokud testy selžou, měl by systém CI/CD upozornit uživatele a zveřejnit výsledky na pull request.
V hlavní větvi můžete naplánovat pravidelné integrační testy. To je dobrý nápad, pokud se větev často aktualizuje souběžnými pull requesty od více uživatelů.
5. Vytvořte větev vydání
Po dokončení testů CI a sloučení vývojové větve do hlavní větve vytvoří ML inženýr vydávací větev, která aktivuje systém CI/CD pro aktualizaci produkčních úloh.
Produkční fáze
Inženýři ML vlastní produkční prostředí, kde jsou nasazována a spouštěna ML potrubí. Tyto kanály aktivují trénování modelu, ověřují a nasazují nové verze modelu, publikují předpovědi do podřízených tabulek nebo aplikací a monitorují celý proces, aby nedocházelo ke snížení výkonu a nestabilitě.
Datoví vědci obvykle nemají v produkčním prostředí přístup k zápisu ani výpočetnímu výkonu. Je však důležité, aby měli přehled o výsledcích testů, protokolech, artefaktech modelu, stavu produkčního pracovního postupu a monitorovacích tabulkách. Tato viditelnost jim umožňuje identifikovat a diagnostikovat problémy v produkčním prostředí a porovnat výkon nových modelů s modely, které jsou aktuálně v produkčním prostředí. Pro tyto účely můžete datovým vědcům udělit přístup k prostředkům jen pro čtení v produkčním katalogu.
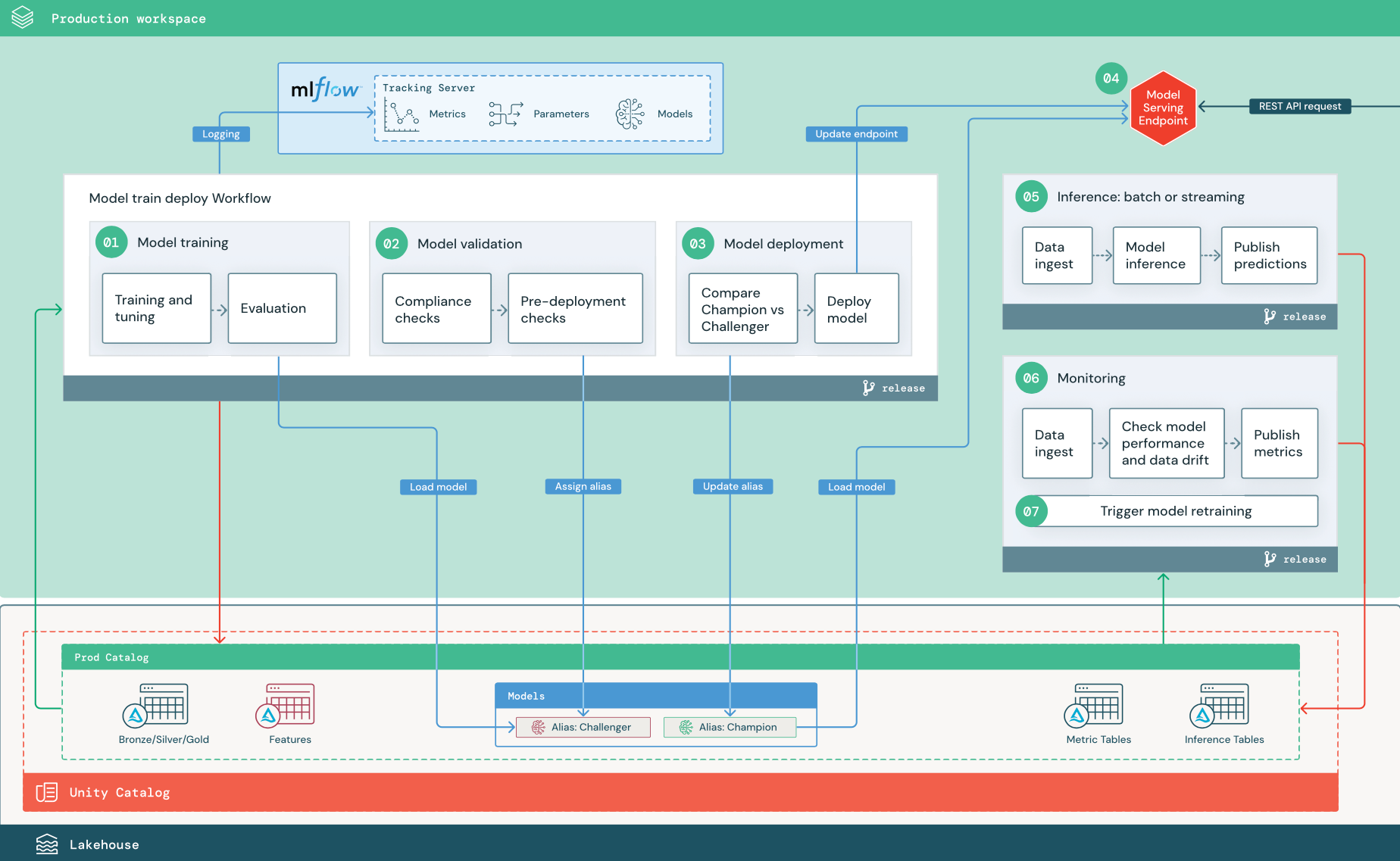
Číslovaný postup odpovídá číslům uvedeným v diagramu.
Trénování modelu
Tento kanál je možné aktivovat změnami kódu nebo automatizovanými úlohami opětovného natrénování. V tomto kroku se tabulky z produkčního katalogu používají pro následující kroky.
Školení a optimalizace. Během trénování se protokoly zaznamenávají do produkčního prostředí serveru MLflow Tracking. Mezi tyto protokoly patří metriky modelu, parametry, značky a samotný model. Pokud používáte příznakové tabulky, model se zaprotokoluje do MLflow pomocí klienta úložiště funkcí Databricks, který balí model s informacemi pro vyhledávání příznaků, které se používají při inferenci.
Během vývoje mohou datoví vědci testovat mnoho algoritmů a hyperparametrů. V produkčním trénovacím kódu je běžné zvážit pouze možnosti s nejvyšším výkonem. Omezení ladění tímto způsobem šetří čas a může snížit variabilitu při ladění při automatizovaném přetrénování.
Pokud mají datoví vědci přístup jen pro čtení do produkčního katalogu, můžou být schopni určit optimální sadu hyperparametrů pro model. V tomto případě lze kanál trénování modelu nasazený v produkčním prostředí spustit pomocí vybrané sady hyperparametrů, které jsou obvykle součástí kanálu jako konfigurační soubor.
Vyhodnocení: Kvalita modelu se vyhodnocuje testováním uložených produkčních dat. Výsledky těchto testů se protokolují na server pro sledování MLflow. Tento krok používá metriky vyhodnocení určené datovými vědci ve fázi vývoje. Tyto metriky můžou zahrnovat vlastní kód.
Zaregistrujte model. Po dokončení trénování modelu se výstup modelu uloží jako registrovaná verze modelu na zadané cestě v produkčním katalogu Unity Catalog. Úloha trénování modelu poskytuje identifikátor URI modelu, který může použít úloha ověření modelu. K předání tohoto identifikátoru URI do modelu můžete použít hodnoty úkolů.
2. Ověření modelu
Tento kanál používá identifikátor URI modelu z kroku 1 a načte model z katalogu Unity. Potom provede řadu ověřovacích kontrol. Tyto kontroly závisí na vaší organizaci a případu použití a můžou zahrnovat například základní ověřování formátu a metadat, vyhodnocení výkonu u vybraných datových řezů a dodržování předpisů s požadavky organizace, jako jsou kontroly dodržování předpisů pro značky nebo dokumentaci.
Pokud model úspěšně projde všemi kontrolami ověření, můžete přiřadit alias Challenger k verzi modelu v katalogu Unity. Pokud model neprojde všemi ověřovacími kontrolami, proces se ukončí a uživatelé můžou být automaticky upozorněni. Značky můžete použít k přidání atributů klíč-hodnota v závislosti na výsledku těchto ověřovacích kontrol. Například můžete vytvořit značku "model_validation_status" a nastavit hodnotu na "ČEKÁ" během provádění testů a po dokončení potrubí ji aktualizovat na "ÚSPĚŠNÉ" nebo "NEÚSPĚŠNÉ".
Vzhledem k tomu, že je model zaregistrovaný v katalogu Unity, můžou datoví vědci pracující ve vývojovém prostředí načíst tuto verzi modelu z produkčního katalogu a zjistit, jestli model selže při ověřování. Bez ohledu na výsledek se výsledky zaznamenávají do registrovaného modelu v produkčním katalogu pomocí poznámek k verzi modelu.
3. Nasazení modelu
Stejně jako kanál ověření závisí kanál nasazení modelu na vaši organizaci a případ použití. V této části se předpokládá, že jste nově ověřenému modelu přiřadili alias Challenger a že stávající produkční model má přiřazený alias Šampion. Prvním krokem před nasazením nového modelu je potvrdit, že jeho výkon je alespoň tak dobrý jako výkon aktuálního produkčního modelu.
Porovnejte model CHALLENGER s modelem CHAMPION. Toto porovnání můžete provést offline nebo online. Offline porovnání vyhodnocuje oba modely oproti uchovávané sadě dat a sleduje výsledky pomocí serveru pro sledování MLflow. Pro poskytování modelu v reálném čase můžete chtít provádět déle trvající online porovnávání, jako jsou A/B testy nebo postupné zavádění nového modelu. Pokud verze modelu "Challenger" v porovnání funguje lépe, nahradí aktuální alias "Champion".
Funkce obsluhy a profilace dat v modelu AI v systému Mosaic vám umožní automaticky shromažďovat a monitorovat tabulky odvozování, které obsahují data požadavků a odpovědí pro koncový bod.
Pokud neexistuje žádný model "Champion", můžete model "Challenger" porovnat s obchodní heuristikou nebo jiným prahovým kritériem jako základní úrovní.
Zde popsaný proces je plně automatizovaný. Pokud jsou vyžadovány kroky ručního schvalování, můžete je nastavit pomocí oznámení pracovního postupu nebo zpětného volání CI/CD z kanálu nasazení modelu.
Nasazení modelu Je možné nastavit inferenční kanály pro dávkové nebo streamované zpracování tak, aby používaly model s aliasem „Champion“. Pro případy použití v reálném čase musíte nastavit infrastrukturu pro nasazení modelu jako koncový bod rozhraní REST API. Tento koncový bod můžete vytvořit a spravovat pomocí nasazení modelu Mosaic AI. Pokud se koncový bod už používá pro aktuální model, můžete koncový bod aktualizovat novým modelem. Mosaic AI Model Serving provede aktualizaci bez přerušení provozu tím, že ponechá stávající konfiguraci v provozu, dokud nebude nová připravena.
4. Obsluha modelu
Při konfiguraci koncového bodu obsluhy modelu zadáte název modelu v katalogu Unity a verzi, která se má použít. Pokud byla verze modelu natrénována pomocí atributů z tabulek v katalogu Unity, model uloží závislosti pro atributy a funkce. Obsluha modelů automaticky používá tento graf závislostí k vyhledání funkcí z příslušných online obchodů v době odvozování. Tento přístup se dá použít také k použití funkcí pro předběžné zpracování dat nebo k výpočtu funkcí na vyžádání během vyhodnocování modelu.
Můžete vytvořit jeden koncový bod s více modely a určit rozdělení provozu na koncovém bodu mezi těmito modely, což vám umožní provádět online porovnání „Šampion“ versus „Challenger“.
5. Inference: dávkové nebo streamovací zpracování
Kanál odvozování čte nejnovější data z produkčního katalogu, spouští funkce pro výpočty funkcí na vyžádání, načte model Champion, vyhodnotuje data a vrací předpovědi. Batchová nebo streamovaná inference je obecně nákladově nejefektivnější možností pro případy použití s vyšší propustností a latencí. V situacích, kdy jsou vyžadovány předpovědi s nízkou latencí, ale předpovědi je možné vypočítat offline, je možné tyto dávkové předpovědi publikovat do online úložiště klíč-hodnota, jako je DynamoDB nebo Cosmos DB.
Na zaregistrovaný model v katalogu Unity odkazuje jeho alias. Inferenční kanál je nakonfigurovaný k načtení a použití verze modelu "Champion". Pokud se verze "Champion" aktualizuje na novou verzi modelu, kanál odvozování automaticky použije novou verzi pro další spuštění. Tímto způsobem je krok nasazení modelu oddělený od kanálů odvozování.
Dávkové úlohy obvykle publikují předpovědi do tabulek v produkčním katalogu, do plochých souborů nebo přes připojení JDBC. Úlohy streamování obvykle publikují předpovědi buď do tabulek Unity Catalog nebo do front zpráv, stejně jako Apache Kafka.
6. Profilace dat
Profilace dat monitoruje statistické vlastnosti, jako je posun dat a výkon modelu, vstupních dat a předpovědí modelu. Na základě těchto metrik můžete vytvářet upozornění nebo je publikovat na řídicích panelech.
- Příjem dat. Tento kanál čte protokoly z dávkového, streamovaného nebo online odvozování.
- Zkontrolujte přesnost a posun dat. Příkazový řetězec vypočítá metriky týkající se vstupních dat, predikce modelu a výkonu infrastruktury. Datoví vědci určují metriky dat a modelů během vývoje a technici STROJOVÉho učení určují metriky infrastruktury. Můžete také definovat vlastní metriky.
- Publikujte metriky a nastavte upozornění. Kanál zapisuje do tabulek v produkčním katalogu pro účely analýzy a vytváření sestav. Tyto tabulky byste měli nakonfigurovat tak, aby byly čitelné z vývojového prostředí, aby datoví vědci měli přístup k analýze. Databricks SQL můžete použít k vytvoření řídicích panelů monitorování ke sledování výkonu modelu a nastavení úlohy monitorování nebo nástroje řídicího panelu k vydání oznámení, když metrika překročí zadanou prahovou hodnotu.
- Spustit opětovné trénování modelu. Při monitorování metrik indikují problémy s výkonem nebo změny vstupních dat, může datový vědec potřebovat vytvořit novou verzi modelu. Můžete nastavit upozornění SQL, která upozorní datové vědce, když k tomu dojde.
7. Přeučování
Tato architektura podporuje automatické přetrénování pomocí téže tréninkové pipeline modelu zmíněné výše. Databricks doporučuje začít s naplánovaným, pravidelným opětovným natrénováním a přejít k vyvolanému opětovnému natrénování v případě potřeby.
- Naplánováno. Pokud jsou nová data k dispozici pravidelně, můžete vytvořit naplánovanou úlohu pro spuštění trénovacího kódu modelu na nejnovějších dostupných datech. Viz Automatizace úloh pomocí plánů a triggerů
- Aktivované: Pokud kanál monitorování dokáže identifikovat problémy s výkonem modelu a odesílat výstrahy, může také aktivovat opětovné trénování. Pokud se například distribuce příchozích dat výrazně změní nebo pokud dojde ke snížení výkonu modelu, může automatické opětovné trénování a opětovné nasazení zvýšit výkon modelu s minimálním zásahem člověka. Toho lze dosáhnout prostřednictvím upozornění SQL a zkontrolovat, jestli je metrika neobvyklá (například kontrola posunu nebo kvality modelu proti prahové hodnotě). Výstrahu lze nakonfigurovat tak, aby používala cíl webhooku, který následně může aktivovat pracovní postup trénování.
Pokud kanál opětovného natrénování nebo jiné kanály vykazují problémy s výkonem, může se datový vědec potřebovat vrátit do vývojového prostředí a provést další experimentování k vyřešení těchto problémů.