Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Tato funkce je ve verzi Public Preview.
Důležité
Tento článek popisuje prostředí tabulky odvozování starší verze, které je relevantní pouze pro určitou předem nastavenou propustnost a vlastní obslužné koncové body modelu.
- Od 20. února 2026 není možné povolit starší tabulky odvozování pro nové nebo existující koncové body obsluhy modelu.
- Od 30. dubna 2026 nebude podporována uživatelská zkušenost se staršími tabulkami odvozování.
Databricks doporučuje tabulky odvozování s podporou AI Gateway díky jejich dostupnosti pro vlastní modely, základní modely a pro agenty sloužící k obsluze koncových bodů. Pro pokyny k migraci na inference tabulky s podporou AI Gateway si přečtěte Migrace na inference tabulky s podporou AI Gateway.
Poznámka:
Pokud v Databricks obsluhujete aplikaci gen AI, můžete pomocí monitorování AI genu Databricks automaticky nastavit tabulky odvozování a sledovat provozní i kvalitní metriky pro vaši aplikaci.
Tento článek popisuje tabulky odvozování pro monitorování obsluhovaných modelů. Následující diagram znázorňuje typický pracovní postup s odvozovacími tabulkami. Tabulka odvozování automaticky zaznamenává příchozí požadavky a odchozí odpovědi pro model obsluhující koncový bod a protokoluje je jako tabulku Delta katalogu Unity. Data v této tabulce můžete použít k monitorování, ladění a vylepšování modelů ML.
pracovní postup odvozovacích tabulek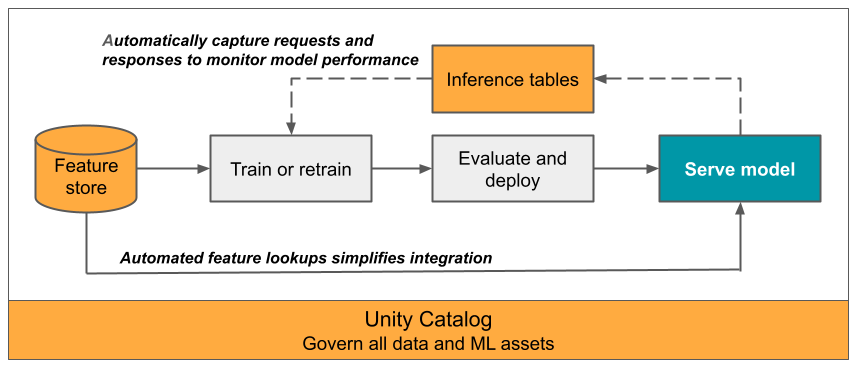 Inference tables workflow
Inference tables workflow
Co jsou odvozovací tabulky?
Monitorování výkonu modelů v produkčních pracovních postupech je důležitým aspektem životního cyklu modelu AI a ML. Tabulky pro inferenci zjednodušují monitorování a diagnostiku modelů průběžným protokolováním vstupů a odpovědí požadavků (předpovědí) z koncových bodů obsluhy modelu Mosaic AI a jejich uložením do tabulky Delta v katalogu Unity. K monitorování, ladění a optimalizaci modelů pak můžete použít všechny možnosti platformy Databricks, jako jsou dotazy Databricks SQL, poznámkové bloky a profilace dat.
Tabulky odvozování můžete povolit u libovolného existujícího nebo nově vytvořeného modelu obsluhujícího koncový bod a požadavky na tento koncový bod se pak automaticky zaprotokolují do tabulky v UC.
Mezi běžné aplikace pro odvozování tabulek patří:
- Monitorování kvality dat a modelu Pomocí profilace dat můžete průběžně monitorovat výkon modelu a posun dat. Profilace dat automaticky generuje řídicí panely kvality dat a modelů, které můžete sdílet se zúčastněnými stranami. Kromě toho můžete upozornění povolit, abyste věděli, kdy potřebujete model přetrénovat na základě posunů v příchozích datech nebo snížení výkonu modelu.
- Řešení problémů v produkci Tabulky inference zaznamenávají data, například stavové kódy HTTP, časy spuštění modelu a kód JSON požadavku a odpovědi. Tato data o výkonu můžete použít pro účely ladění. Historická data v tabulkách odvozování můžete použít také k porovnání výkonu modelu u historických požadavků.
- Vytvořte trénovací korpus. Spojením odvozovacích tabulek s popisky základní pravdy můžete vytvořit trénovací korpus, který můžete použít k opětovnému trénování nebo vyladění a vylepšení modelu. Pomocí úloh Lakeflow můžete nastavit nepřetržitou smyčku zpětné vazby a automatizovat opakované trénování.
Požadavky
- Váš pracovní prostor musí mít povolený katalog Unity.
- Autor koncového bodu i upravovatel musí mít oprávnění ke správě koncového bodu. Viz řídící seznamy přístupu.
- Tvůrce koncového bodu i modifikátor musí mít v katalogu Unity následující oprávnění :
-
USE CATALOGoprávnění k zadanému katalogu. -
USE SCHEMAoprávnění k zadanému schématu. -
CREATE TABLEoprávnění ve schématu.
-
Povolení a zakázání odvozovacích tabulek
V této části se dozvíte, jak povolit nebo zakázat tabulky odvozování pomocí uživatelského rozhraní Databricks. Můžete také použít rozhraní API; Pokyny najdete v tématu Povolení tabulek odvozování v modelech obsluhujících koncové body pomocí rozhraní API.
Vlastníkem tabulek odvozování je uživatel, který koncový bod vytvořil. Všechny seznamy řízení přístupu (ACL) v tabulce se řídí standardními oprávněními katalogu Unity a může je upravit vlastník tabulky.
Varování
Tabulka odvozování může být poškozena, pokud provedete některou z následujících věcí:
- Změňte schéma tabulky.
- Změňte název tabulky.
- Odstraňte tabulku.
- Ztratíte oprávnění ke katalogu nebo schématu Unity Catalog.
V tomto případě stav auto_capture_config koncového bodu ukazuje stav FAILED pro tabulku datové části. Pokud k tomu dojde, musíte vytvořit nový koncový bod, abyste mohli dál používat odvozovací tabulky.
K povolení odvozovacích tabulek během vytváření koncového bodu použijte následující postup:
Klikněte na Obsluha v uživatelském rozhraní Databricks Mosaic AI.
Klikněte na Vytvořit koncový bod služby.
Vyberte Povolit odvozovací tabulky.
V rozevíracích nabídkách vyberte požadovaný katalog a schéma, ve kterém se má tabulka nacházet.
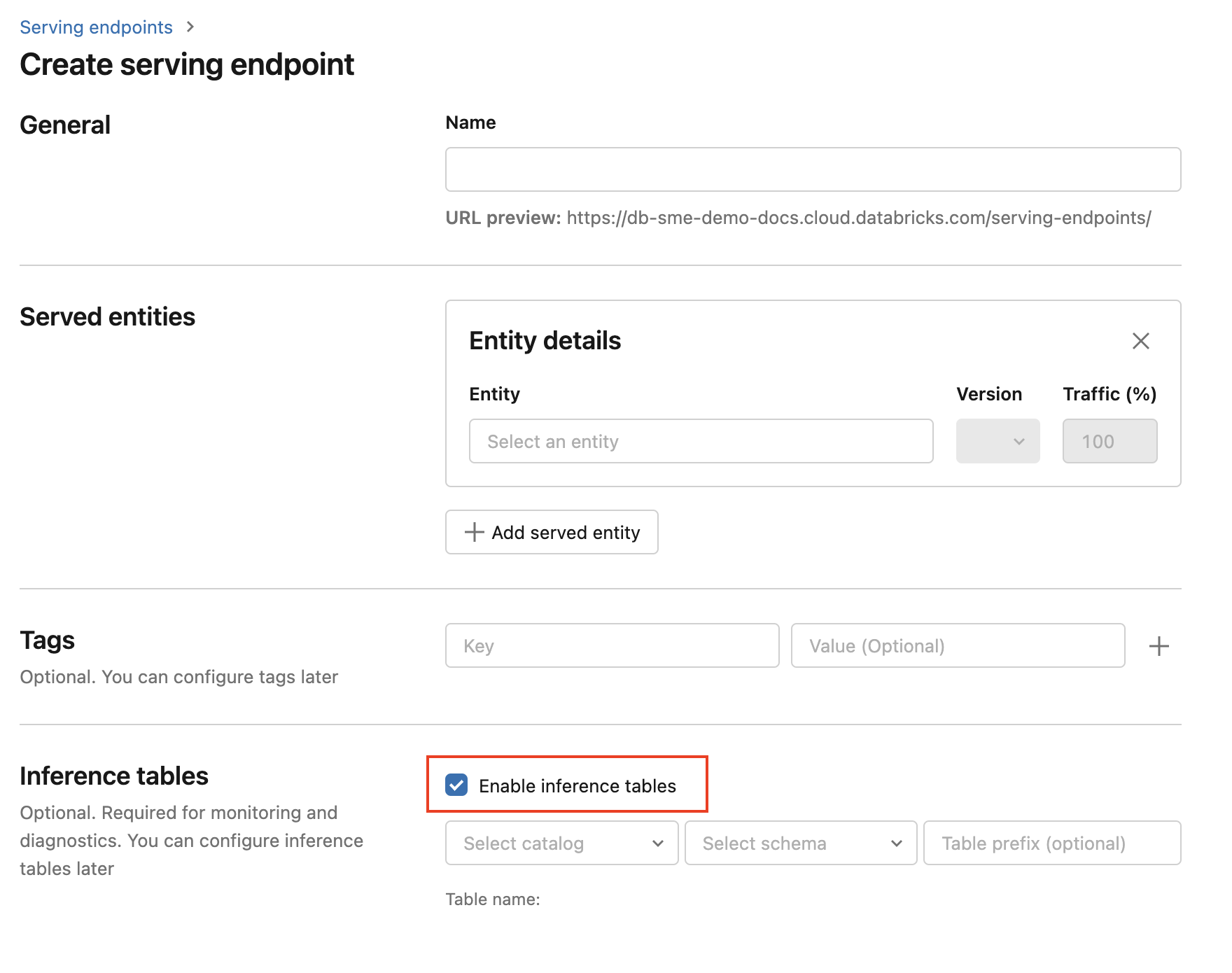
Výchozí název tabulky je
<catalog>.<schema>.<endpoint-name>_payload. V případě potřeby můžete zadat vlastní předponu tabulky.Klikněte na Vytvořit koncový bod služby.
U existujícího koncového bodu můžete také povolit odvozovací tabulky. Pokud chcete upravit existující konfiguraci koncového bodu, postupujte takto:
- Přejděte na stránku koncového bodu.
- Klikněte na Upravit konfiguraci.
- Postupujte podle předchozích pokynů počínaje krokem 3.
- Až budete hotovi, klikněte na Aktualizovat koncový bod služby.
Podle těchto pokynů zakažte odvozovací tabulky:
- Přejděte na stránku koncového bodu.
- Klikněte na Upravit konfiguraci.
- Klikněte na Povolit odvozovací tabulku a zrušte zaškrtnutí.
- Jakmile budete spokojeni se specifikacemi koncových bodů, klikněte na Aktualizovat.
Migrace do inferenčních tabulek AI Gateway
Důležité
Po migraci koncového bodu pro použití tabulky odvození služby AI Gateway se nemůže přepnout zpět na starší tabulku.
Poznámka:
Tabulky odvození AI Gateway mají v porovnání se staršími odvozovacími tabulkami různá schémata .
Informace o cenách najdete na stránce s cenami služby Mosaic AI Gateway.
V této části se dozvíte, jak migrovat ze starších odvozovacích tabulek na odvozovací tabulky AI Gateway.
Konfigurace se dá aktualizovat dvěma hlavními kroky:
- Aktualizujte koncový bod obsluhy, aby se zakázala starší tabulka odvozování.
- Aktualizujte servisní koncový bod pro povolení inferenční tabulky AI brány.
Použití uživatelského rozhraní k migraci konfigurace odvozovací tabulky
V případě malého počtu obsluhovaných koncových bodů upravte konfiguraci koncového bodu v uživatelském rozhraní:
Klikněte na Serving v uživatelském rozhraní Databricks Mosaic AI a přejděte na stránku s koncovým bodem.
Klikněte na Upravit konfiguraci.
Kliknutím na Zakázat odvozovací tabulky zrušte zaškrtnutí.
klikněte na Aktualizovat a počkejte, až se stav koncového bodu stane připraveným.
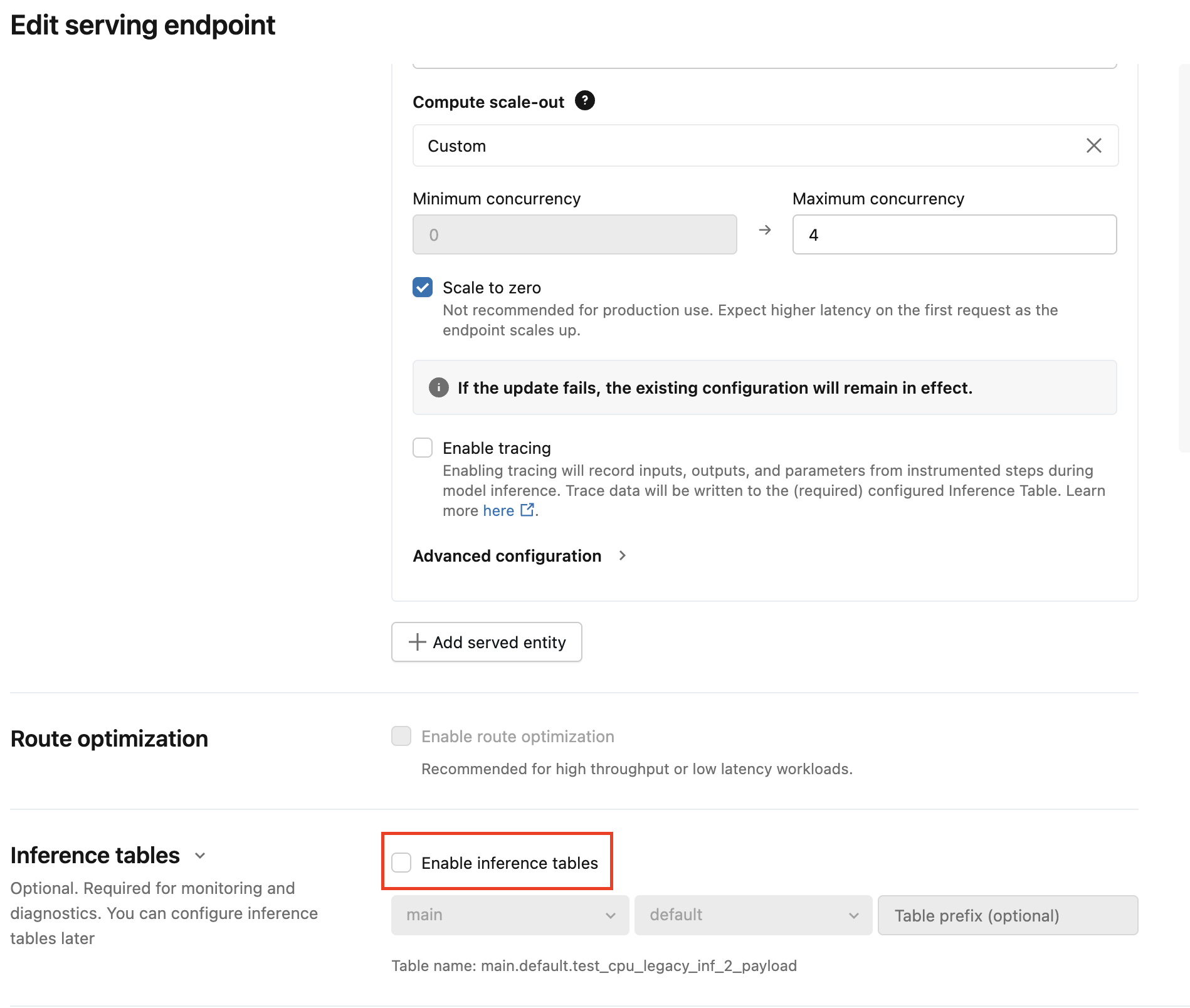
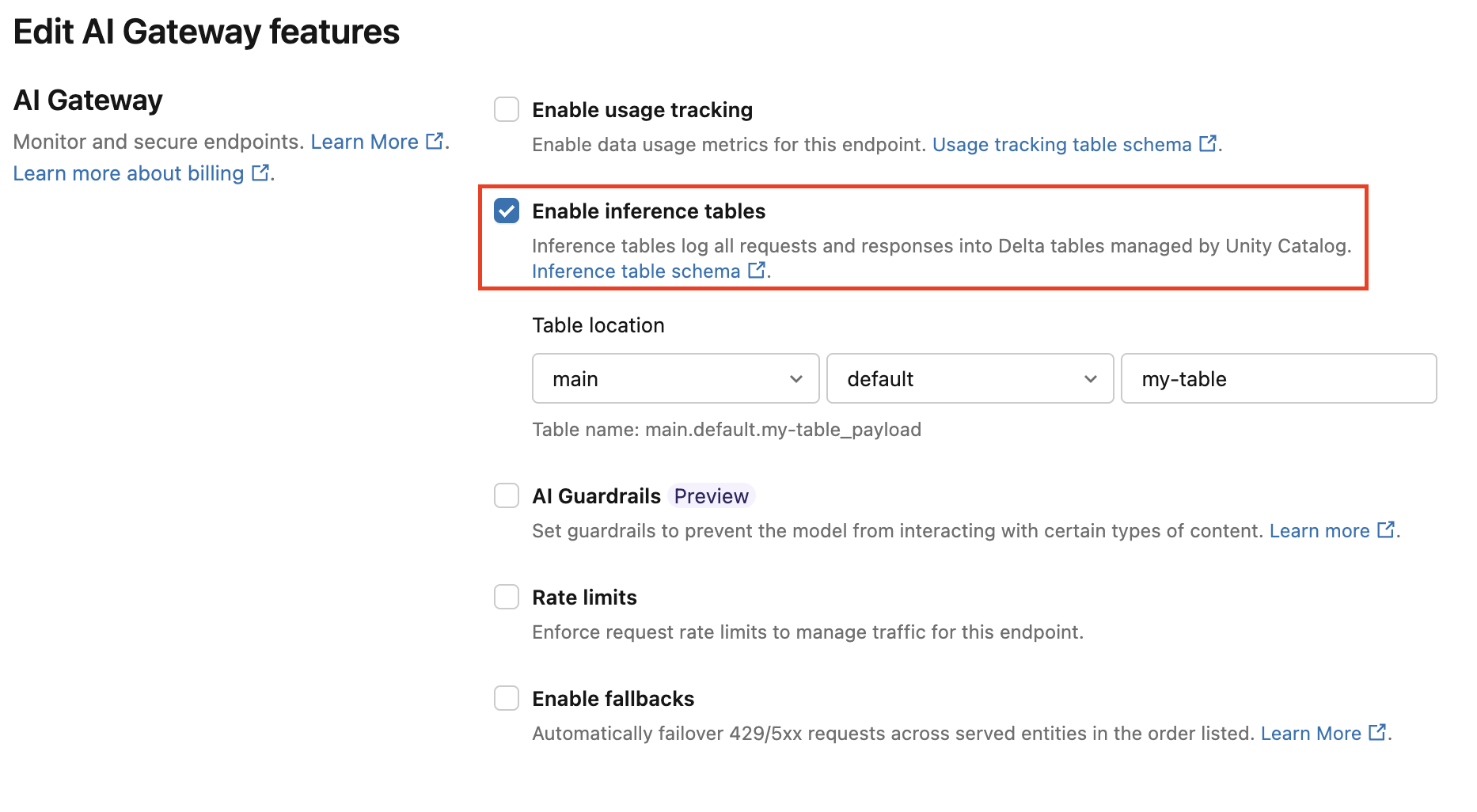
Podle těchto pokynů povolte inferenční tabulku AI Gateway.
Klikněte na Serving v uživatelském rozhraní Databricks Mosaic AI a přejděte na stránku s koncovým bodem.
Klikněte na Upravit bránu AI.
Klikněte na Povolit odvozovací tabulky.
V rozevírací nabídce vyberte požadovaný katalog a schéma, ve kterém se má tabulka nacházet.
Výchozí název tabulky je
<catalog>.<schema>.<endpoint-name>_payload. Volitelně můžete zadat vlastní předponu tabulky.Klikněte na Aktualizovat.
Použijte poznámkový blok k migraci konfigurace inferenční tabulky
U mnoha koncových bodů můžete pomocí rozhraní API automatizovat proces migrace. Databricks poskytuje ukázkový poznámkový blok, který dávkově migruje koncové body a příklady migrace existujících dat ze starších tabulek odvozování do tabulek odvozování AI Gateway.
Migrovat na sešit inferenčních tabulek AI brány
pracovní postup : Monitorování výkonu modelu pomocí odvozovacích tabulek
Pokud chcete monitorovat výkon modelu pomocí odvozovacích tabulek, postupujte takto:
- Povolte tabulky odvozování ve vašem koncovém bodu, a to buď během vytváření koncového bodu, nebo následnou aktualizací.
- Naplánujte pracovní postup pro zpracování datových částí JSON v tabulce odvozování tak, že je rozbalíte podle schématu koncového bodu.
- (Volitelné) Přiřaďte oddělené požadavky a odpovědi s referenčními označeními, aby bylo možné vypočítat metriky kvality modelu.
- Vytvořte monitorování nad výslednou tabulkou Delta a aktualizujte metriky.
Počáteční poznámkové bloky implementují tento pracovní postup.
Úvodní notebook pro monitorování inferenční tabulky
Následující poznámkový blok implementuje výše uvedené kroky pro rozbalení požadavků z tabulky odvozování profilace dat. Poznámkový blok můžete spustit na vyžádání nebo podle opakujícího se plánu pomocí úloh Lakeflow.
Úvodní poznámkový blok pro profilování dat inferenční tabulky
Úvodní poznámkový blok pro monitorování kvality textu z koncových bodů obsluhujících LLM
Následující poznámkový blok rozbalí požadavky z tabulky odvozování, vypočítá sadu metrik vyhodnocení textu (například čitelnost a toxicitu) a umožňuje monitorování těchto metrik. Poznámkový blok můžete spustit na vyžádání nebo podle opakujícího se plánu pomocí úloh Lakeflow.
Startovací poznámkový blok pro profilování dat tabulky inference LLM
Dotazování a analýza výsledků v tabulce odvozování
Jakmile budou vaše obsluhované modely připravené, všechny požadavky provedené na vašich modelech se automaticky zaprotokolují do tabulky odvozování spolu s odpověďmi. Tabulku můžete zobrazit v uživatelském rozhraní, dotazovat se na tabulku z DBSQL nebo poznámkového bloku nebo dotazovat tabulku pomocí rozhraní REST API.
Zobrazení tabulky v uživatelském rozhraní: Na stránce koncového bodu kliknutím na název tabulky odvozování otevřete tabulku v Průzkumníku katalogu.

Dotazování tabulky z DBSQL nebo poznámkového bloku Databricks: Můžete spustit kód podobný následujícímu dotazu na tabulku odvozování.
SELECT * FROM <catalog>.<schema>.<payload_table>
Pokud jste povolili odvozovací tabulky pomocí uživatelského rozhraní, payload_table je název tabulky, který jste přiřadili při vytváření koncového bodu. Pokud jste povolili odvozování tabulek pomocí rozhraní API, payload_table se zobrazí v state části odpovědi auto_capture_config. Příklad najdete v tématu Povolení odvozovacích tabulek v modelech obsluhujících koncové body pomocí rozhraní API.
Poznámka k výkonu
Po vyvolání koncového bodu můžete vidět, jak je volání během hodiny od odeslání žádosti o skórování zaznamenáno do vaší inference tabulky. Kromě toho Azure Databricks zaručuje doručení protokolů alespoň jednou, takže je možné, i když je nepravděpodobné, že se odesílají duplicitní protokoly.
Schéma odvozovací tabulky Unity Catalog
Každý požadavek a odpověď, které se zaprotokolují do odvozovací tabulky, se zapisují do tabulky Delta s následujícím schématem:
Poznámka:
Pokud vyvoláte koncový bod s dávkou vstupů, zaprotokoluje se celá dávka jako jeden řádek.
| Název sloupce | Popis | Typ |
|---|---|---|
databricks_request_id |
Identifikátor požadavku vygenerovaný službou Azure Databricks připojený ke všem žádostem obsluhující model | ŘETĚZEC |
client_request_id |
Volitelný identifikátor požadavku vygenerovaný klientem, který lze zadat v modelu obsluhující tělo požadavku. Viz Specify client_request_id pro více informací. |
ŘETĚZEC |
date |
Datum UTC, kdy byl přijat požadavek na obsluhu modelu. | DATUM |
timestamp_ms |
Časové razítko v milisekundách od počátku epochy, kdy byl přijat požadavek na obsluhu modelu. | DLOUHÝ |
status_code |
Stavový kód HTTP vrácený z modelu. | INT |
sampling_fraction |
Zlomek vzorkování použitý v případě, že byla snížena úroveň vzorkování požadavku. Tato hodnota je mezi 0 a 1, kde 1 představuje, že bylo zahrnuto 100% příchozích požadavků. | DVOJITÝ |
execution_time_ms |
Doba provádění v milisekundách, pro kterou model provedl odvozování. Toto nezahrnuje dodatečné latence sítě a představuje pouze čas, který modelu zabralo generování předpovědí. | DLOUHÝ |
request |
Nezpracovaný text JSON požadavku, který byl odeslán do koncového bodu obsluhy modelu. | ŘETĚZEC |
response |
Nezpracovaný text JSON odpovědi vrácený koncovým bodem obsluhy modelu. | ŘETĚZEC |
request_metadata |
Mapa metadat souvisejících s koncovým bodem obsluhující model přidružený k požadavku Tato mapa obsahuje název koncového bodu, název modelu a verzi modelu používanou pro váš koncový bod. | MAPOVACÍ<ŘETĚZEC, ŘETĚZEC> |
Specifikovatclient_request_id
Pole client_request_id je volitelná hodnota, kterou může uživatel zadat v modelu obsluhující tělo požadavku. To uživateli umožní zadat vlastní identifikátor požadavku, který se zobrazí v poslední tabulce odvozování v client_request_id a dá se použít pro připojení žádosti s jinými tabulkami, které používají client_request_id, jako je připojení základního popisku pravdy. Pokud chcete specifikovat client_request_id, zahrňte ho jako klíč nejvyšší úrovně v těle požadavku. Pokud není zadána žádná client_request_id hodnota, zobrazí se hodnota v řádku odpovídajícím požadavku jako null.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
client_request_id lze později použít pro spojení popisků základní pravdy, pokud existují jiné tabulky, které mají přidružené popisky client_request_id.
Omezení
- Klíče spravované zákazníkem se nepodporují.
- U koncových bodů, které hostují foundation models, jsou tabulky odvozování podporovány pouze u pracovních zátěží se zřízenou propustností .
- Azure Firewall může způsobit selhání vytvoření tabulky Unity Catalog Delta, takže se ve výchozím nastavení nepodporuje. Spojte se s týmem účtu Databricks a povolte ho.
- Pokud jsou tabulky odvozování povolené, je limit maximální souběžnosti napříč všemi obsluhované modely v jednom koncovém bodu 128. Spojte se s týmem účtu Azure Databricks a požádejte o zvýšení tohoto limitu.
- Pokud tabulka odvozování obsahuje více než 500 tisíc souborů, nebudou zaprotokolována žádná další data. Pokud se chcete vyhnout překročení tohoto limitu, spusťte OPTIMIZE nebo nastavte uchovávání dat v tabulce odstraněním starších dat. Pokud chcete zkontrolovat počet souborů v tabulce, spusťte
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>. - Doručování protokolů pro tabulky odvozování je v současné době na základě nejlepšího úsilí, ale můžete očekávat, že protokoly budou dostupné do 1 hodiny od odeslání požadavku. Další informace získáte od týmu účtu Databricks.
Obecná omezení koncového bodu obsluhy modelu najdete v tématu Omezení a oblasti obsluhy modelů.