Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek obsahuje základní kroky pro nasazení a dotazování vlastního modelu, což je tradiční model ML pomocí obsluhy modelů. Model musí být zaregistrovaný v katalogu Unity nebo v registru modelů pracovního prostoru.
Další informace o poskytování a nasazování modelů generování AI najdete v následujících článcích:
Krok 1: Protokolování modelu
Existují různé způsoby, jak model protokolovat pro obsluhu modelu:
| Technika protokolování | Popis |
|---|---|
| Automatické přihlašování | To se automaticky zapne, když pro strojové učení použijete Databricks Runtime. Je to nejjednodušší způsob, ale dává vám menší kontrolu. |
| Protokolování pomocí vestavěných modulů MLflow | Model můžete ručně protokolovat pomocí předdefinovaných modelů MLflow. |
Vlastní protokolování s využitím pyfunc |
Tuto možnost použijte, pokud máte vlastní model nebo pokud potřebujete další kroky před nebo po odvozování. |
Následující příklad ukazuje, jak protokolovat model MLflow pomocí transformer příchutě a zadat parametry, které potřebujete pro váš model.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Po zalogování modelu nezapomeňte zkontrolovat, jestli je váš model zaregistrovaný buď v katalogu Unity , nebo v registru modelů MLflow .
Krok 2: Vytvoření koncového bodu pomocí uživatelského rozhraní obsluhy
Po zaprotokolování zaregistrovaného modelu a když jste připraveni k jeho obsluze, můžete vytvořit koncový bod obsluhující model pomocí rozhraní Serving.
Klikněte na položku Obsluha v postranním panelu pro zobrazení uživatelského rozhraní Obsluha.
Klikněte na Vytvořit servisní koncový bod.
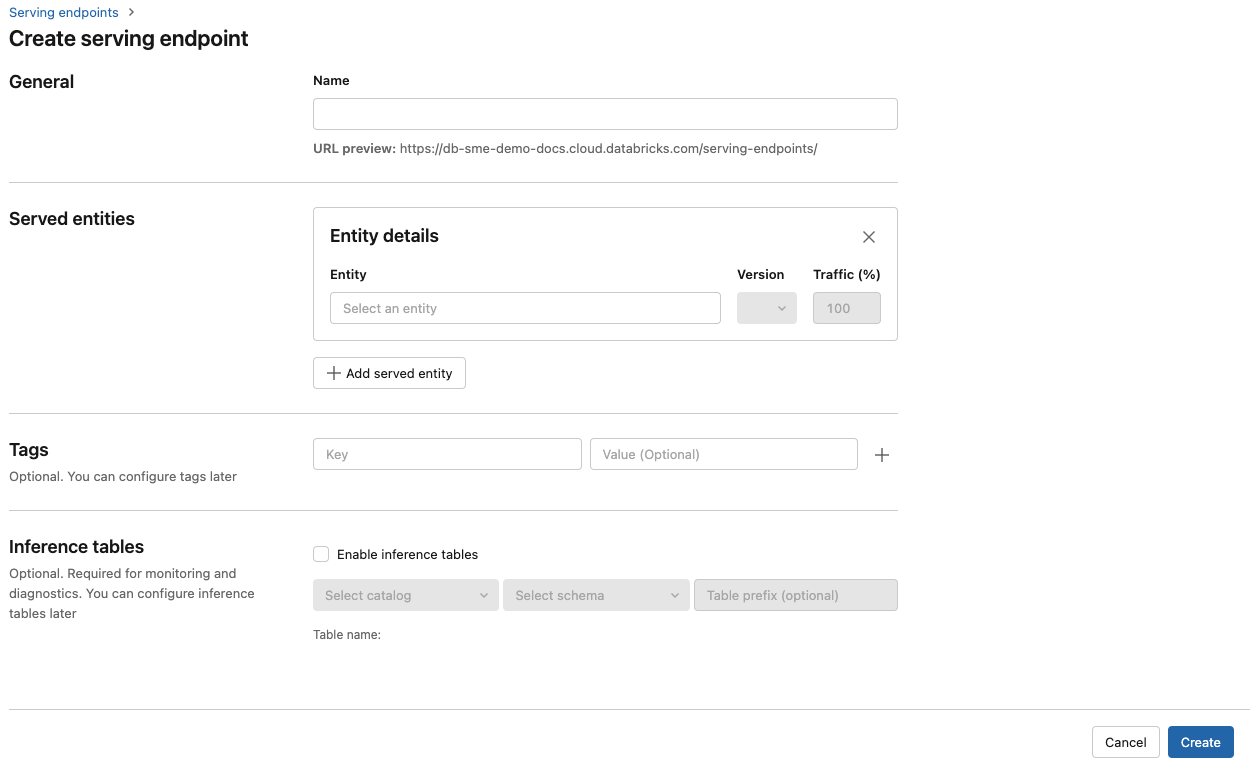
Do pole Název zadejte název koncového bodu.
V části Obsluhované entity
- Klikněte do pole Entita a otevře se formulář Výběr obsluhované entity.
- Vyberte typ modelu, který chcete nasadit. Formulář se dynamicky aktualizuje na základě vašeho výběru.
- Vyberte model a verzi modelu, kterou chcete použít.
- Vyberte procento datového provozu, které se má směrovat na váš nasazený model.
- Vyberte, jakou velikost výpočetních prostředků chcete použít.
- V části Horizontální navýšení kapacity výpočetních prostředkůvyberte velikost horizontálního navýšení kapacity výpočetních prostředků odpovídající počtu požadavků, které tento obsluhovaný model může zpracovat současně. Toto číslo by se mělo přibližně rovnat času provádění modelu QPS x.
- Dostupné velikosti jsou malé pro 0 až 4 požadavky, středně velké 8 až 16 požadavků a velké pro požadavky 16 až 64.
- Určete, zda se má koncový bod při nepoužívání škálovat na nulu.
Klikněte na Vytvořit. Stránka Obslužné koncové body se zobrazí se stavem obsluhy koncového bodu, který je zobrazený jako Nepřipravený.
Pokud dáváte přednost programovému vytvoření koncového bodu pomocí rozhraní Databricks Serving API, přečtěte si téma Vytvoření vlastních modelů obsluhujících koncové body.
Krok 3: Dotazování koncového bodu
Nejjednodušším a nejrychlejším způsobem, jak otestovat a odeslat žádosti o skórování vašemu obsluhovanému modelu, je použít Serving UI.
Na stránce Obsluha koncového bodu vyberte koncový bod dotazu.
Vložte vstupní data modelu ve formátu JSON a klikněte na Odeslat požadavek. Pokud byl model zaprotokolován pomocí vstupního příkladu, klikněte na Zobrazit příklad a načtěte příklad vstupu.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Pokud chcete odesílat žádosti o bodování, vytvořte JSON s jedním z podporovaných klíčů a objektem JSON odpovídajícím vstupnímu formátu. Viz Dotazy obsluhující koncové body pro vlastní modely pro podporované formáty a pokyny k odesílání žádostí o bodování pomocí rozhraní API.
Pokud máte v úmyslu získat přístup ke svému koncovému bodu obsluhy mimo uživatelské rozhraní služby Azure Databricks, potřebujete DATABRICKS_API_TOKEN.
Důležité
Jako osvědčený postup zabezpečení pro produkční scénáře doporučuje Databricks používat machine-to-machine OAuth tokeny pro autentizaci během produkce.
Pro účely testování a vývoje doporučuje Databricks místo uživatelů pracovního prostoru používat osobní přístupový token patřící instančním objektům . Pokud chcete vytvořit tokeny pro instanční objekty, přečtěte si téma Správa tokenů instančního objektu.
Příklady poznámkových bloků
Podívejte se na následující poznámkový blok pro obsluhu modelu MLflow transformers s obsluhou modelů.
Nasazení sešitu modelu transformerů od Hugging Face
Podívejte se na následující poznámkový blok pro obsluhu modelu MLflow pyfunc s obsluhou modelů. Další podrobnosti o přizpůsobení nasazení modelu najdete v tématu Nasazení kódu Pythonu pomocí služby Model Serving.