Modely základu dotazů
V tomto článku se dozvíte, jak formátovat požadavky na dotazy na základní modely a odesílat je do koncového bodu obsluhy modelu.
Požadavky na dotazy tradičních modelů ML nebo Pythonu najdete v tématu Dotaz obsluhující koncové body pro vlastní modely.
Databricks Model Serving podporuje rozhraní API základních modelů a externí modely pro přístup k základním modelům a používá jednotné rozhraní API kompatibilní s OpenAI a sadu SDK pro jejich dotazování. Díky tomu můžete experimentovat se základními modely pro produkční prostředí napříč podporovanými cloudy a poskytovateli a přizpůsobovat je.
Služba Databricks Model Serving poskytuje následující možnosti pro odesílání žádostí o bodování do základních modelů:
| Metoda | Podrobnosti |
|---|---|
| Klient OpenAI | Dotazování modelu hostovaného koncovým bodem obsluhy modelu Databricks pomocí klienta OpenAI Zadejte model obsluhující název koncového model bodu jako vstup. Podporované modely chatu, vkládání a dokončování, které jsou dostupné rozhraními API modelu Foundation nebo externími modely. |
| Obsluha uživatelského rozhraní | Na stránce Obsluha koncového bodu vyberte koncový boddotazu. Vložte vstupní data modelu formátu JSON a klikněte na Odeslat požadavek. Pokud má model zaprotokolovaný vstupní příklad, načtěte ho pomocí příkazu Zobrazit příklad . |
| REST API | Volání a dotazování modelu pomocí rozhraní REST API Podrobnosti najdete v tématu POST /serving-endpoints/{name}/invocations . Žádosti o bodování na koncové body obsluhující více modelů najdete v tématu Dotazování jednotlivých modelů za koncovým bodem. |
| Sada SDK pro nasazení MLflow | K dotazování modelu použijte funkci predict() sady SDK pro nasazení MLflow. |
| Databricks GenAI SDK | Databricks GenAI SDK je vrstva nad rozhraním REST API. Zpracovává podrobnosti nízké úrovně, jako je ověřování a mapování ID modelů na adresy URL koncových bodů, což usnadňuje interakci s modely. Sada SDK je navržená tak, aby se používala z poznámkových bloků Databricks. |
| Funkce SQL | Vyvolání odvozování modelu přímo z SQL pomocí ai_query funkce SQL Viz Dotaz na model obsluhované pomocí ai_query(). |
Požadavky
- Model obsluhující koncový bod
- Pracovní prostor Databricks v podporované oblasti
- Pokud chcete odeslat žádost o bodování prostřednictvím klienta OpenAI, rozhraní REST API nebo sady SDK pro nasazení MLflow, musíte mít token rozhraní API Databricks.
Důležité
Jako osvědčený postup zabezpečení pro produkční scénáře doporučuje Databricks používat tokeny OAuth počítače pro ověřování během produkčního prostředí.
Pro účely testování a vývoje doporučuje Databricks místo uživatelů pracovního prostoru používat osobní přístupový token patřící instančním objektům . Pokud chcete vytvořit tokeny pro instanční objekty, přečtěte si téma Správa tokenů instančního objektu.
Instalace balíčků
Po výběru metody dotazování musíte nejprve nainstalovat příslušný balíček do clusteru.
Klient Openai
Pokud chcete použít klienta OpenAI, musí být balíček openai nainstalovaný ve vašem clusteru. V poznámkovém bloku nebo místním terminálu spusťte následující příkaz:
!pip install openai
Následující informace se vyžadují jenom při instalaci balíčku do poznámkového bloku Databricks.
dbutils.library.restartPython()
Rozhraní REST API
Přístup k rozhraní REST API pro obsluhu je k dispozici v Databricks Runtime pro Učení počítače.
Sada SDK pro nasazení Mlflow
!pip install mlflow
Následující informace se vyžadují jenom při instalaci balíčku do poznámkového bloku Databricks.
dbutils.library.restartPython()
Sada Databricks Genai SDK
!pip install databricks-genai
Následující informace se vyžadují jenom při instalaci balíčku do poznámkového bloku Databricks.
dbutils.library.restartPython()
Dotazování modelu dokončování chatu
Tady jsou příklady pro dotazování modelu chatu.
Příklad dávkového odvozování najdete v tématu Dávkové odvozování pomocí rozhraní API základního modelu.
Klient Openai
Následuje žádost o chat pro model DBRX Instruct, který zpřístupnil koncový bod databricks-dbrx-instruct rozhraní API základního modelu s průběžnými platbami za token ve vašem pracovním prostoru.
Pokud chcete použít klienta OpenAI, zadejte jako vstup model obsluhující název koncového model bodu. Následující příklad předpokládá, že máte token rozhraní API Databricks a openai na výpočetní prostředky nainstalovaný. K připojení klienta OpenAI k Databricks k Databricks potřebujete také instanci pracovního prostoru Databricks.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
Rozhraní REST API
Důležité
Následující příklad používá parametry rozhraní REST API k dotazování obsluhujících koncové body, které obsluhují základní modely. Tyto parametry jsou ve verzi Public Preview a definice se může změnit. Viz POST /serving-endpoints/{name}/invocations.
Následuje žádost o chat pro model DBRX Instruct, který zpřístupnil koncový bod databricks-dbrx-instruct rozhraní API základního modelu s průběžnými platbami za token ve vašem pracovním prostoru.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": " What is a mixture of experts model?"
}
]
}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-dbrx-instruct/invocations \
Sada SDK pro nasazení Mlflow
Důležité
Následující příklad používá predict() rozhraní API ze sady SDK pro nasazení MLflow.
Následuje žádost o chat pro model DBRX Instruct, který zpřístupnil koncový bod databricks-dbrx-instruct rozhraní API základního modelu s průběžnými platbami za token ve vašem pracovním prostoru.
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
chat_response = client.predict(
endpoint="databricks-dbrx-instruct",
inputs={
"messages": [
{
"role": "user",
"content": "Hello!"
},
{
"role": "assistant",
"content": "Hello! How can I assist you today?"
},
{
"role": "user",
"content": "What is a mixture of experts model??"
}
],
"temperature": 0.1,
"max_tokens": 20
}
)
Sada Databricks Genai SDK
Následuje žádost o chat pro model DBRX Instruct, který zpřístupnil koncový bod databricks-dbrx-instruct rozhraní API základního modelu s průběžnými platbami za token ve vašem pracovním prostoru.
from databricks_genai_inference import ChatCompletion
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
response = ChatCompletion.create(model="databricks-dbrx-instruct",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user","content": "What is a mixture of experts model?"}],
max_tokens=128)
print(f"response.message:{response.message}")
Langchain
Pokud chcete dotazovat základní koncový bod modelu pomocí jazyka LangChain, můžete provést jednu z následujících akcí:
- Importujte
Databrickstřídu LLM a zadejte aendpoint_nametransform_input_fn. - Naimportujte
ChatDatabrickstřídu ChatModel a zadejteendpoint.
Následující příklad používá Databricks LLM třídy v LangChain k dotazování rozhraní API základního modelu pay-per-token koncový bod, databricks-dbrx-instruct. Rozhraní API základního modelu očekávají messages ve slovníku požadavků, zatímco jazyk LangChain Databricks LLM ve výchozím nastavení poskytuje prompt ve slovníku požadavků. transform_input Pomocí funkce připravte slovník požadavků do očekávaného formátu.
from langchain.llms import Databricks
from langchain_core.messages import HumanMessage, SystemMessage
def transform_input(**request):
request["messages"] = [
{
"role": "user",
"content": request["prompt"]
}
]
del request["prompt"]
return request
llm = Databricks(endpoint_name="databricks-dbrx-instruct", transform_input_fn=transform_input)
llm("What is a mixture of experts model?")
Následující příklad používá ChatDatabricks ChatModel třídy a určuje endpoint.
from langchain.chat_models import ChatDatabricks
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="You're a helpful assistant"),
HumanMessage(content="What is a mixture of experts model?"),
]
chat_model = ChatDatabricks(endpoint="databricks-dbrx-instruct", max_tokens=500)
chat_model.invoke(messages)
SQL
Důležité
Následující příklad používá integrovanou funkci SQL ai_query. Tato funkce je ve verzi Public Preview a definice se může změnit. Viz Dotaz na model obsluhované pomocí ai_query().
Následuje žádost o chat, llama-2-70b-chat kterou zpřístupnil koncový bod databricks-llama-2-70b-chat rozhraní API základního modelu s průběžnými platbami za token ve vašem pracovním prostoru.
Poznámka:
Funkce ai_query() nepodporuje koncové body dotazů, které obsluhují dbRX nebo model DBRX Instruct.
SELECT ai_query(
"databricks-llama-2-70b-chat",
"Can you explain AI in ten words?"
)
Následuje očekávaný formát žádosti pro model chatu. U externích modelů můžete zahrnout další parametry platné pro daného poskytovatele a konfiguraci koncového bodu. Viz Další parametry dotazu.
{
"messages": [
{
"role": "user",
"content": "What is a mixture of experts model?"
}
],
"max_tokens": 100,
"temperature": 0.1
}
Následuje očekávaný formát odpovědi:
{
"model": "databricks-dbrx-instruct",
"choices": [
{
"message": {},
"index": 0,
"finish_reason": null
}
],
"usage": {
"prompt_tokens": 7,
"completion_tokens": 74,
"total_tokens": 81
},
"object": "chat.completion",
"id": null,
"created": 1698824353
}
Relace chatu
Sada Databricks GenAI SDK poskytuje ChatSession třídu pro správu konverzací v chatu s více kruhy. Poskytuje následující funkce:
| Function | Zpět | Popis |
|---|---|---|
reply (string) |
Přebírá novou zprávu uživatele. | |
last |
string | Poslední zpráva od asistenta |
history |
seznam diktování | Zprávy v historii chatu, včetně rolí |
count |
int | Počet dosud provedených chatovacích kol. |
K inicializaci ChatSessionpoužijete stejnou sadu argumentů jako ChatCompletiona tyto argumenty se použijí v průběhu chatové relace.
from databricks_genai_inference import ChatSession
chat = ChatSession(model="llama-2-70b-chat", system_message="You are a helpful assistant.", max_tokens=128)
chat.reply("Knock, knock!")
chat.last # return "Hello! Who's there?"
chat.reply("Guess who!")
chat.last # return "Okay, I'll play along! Is it a person, a place, or a thing?"
chat.history
# return: [
# {'role': 'system', 'content': 'You are a helpful assistant.'},
# {'role': 'user', 'content': 'Knock, knock.'},
# {'role': 'assistant', 'content': "Hello! Who's there?"},
# {'role': 'user', 'content': 'Guess who!'},
# {'role': 'assistant', 'content': "Okay, I'll play along! Is it a person, a place, or a thing?"}
# ]
Dotazování modelu vkládání
Následuje žádost o vložení modelu bge-large-en zpřístupněného rozhraními API základního modelu.
Klient Openai
Pokud chcete použít klienta OpenAI, zadejte jako vstup model obsluhující název koncového model bodu. Následující příklad předpokládá, že máte v clusteru nainstalovaný token openai rozhraní API Databricks.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.embeddings.create(
model="databricks-bge-large-en",
input="what is databricks"
)
Rozhraní REST API
Důležité
Následující příklad používá parametry rozhraní REST API k dotazování obsluhujících koncové body, které obsluhují základní modely. Tyto parametry jsou ve verzi Public Preview a definice se může změnit. Viz POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{ "input": "Embed this sentence!"}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-bge-large-en/invocations
Sada SDK pro nasazení Mlflow
Důležité
Následující příklad používá predict() rozhraní API ze sady SDK pro nasazení MLflow.
import mlflow.deployments
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
embeddings_response = client.predict(
endpoint="databricks-bge-large-en",
inputs={
"input": "Here is some text to embed"
}
)
Sada Databricks Genai SDK
from databricks_genai_inference import Embedding
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
response = Embedding.create(
model="bge-large-en",
input="3D ActionSLAM: wearable person tracking in multi-floor environments")
print(f'embeddings: {response.embeddings}')
Langchain
Pokud chcete použít model rozhraní API modelu Modelu Foundation Databricks v jazyce LangChain jako model vkládání, naimportujte DatabricksEmbeddings třídu a zadejte endpoint parametr následujícím způsobem:
from langchain.embeddings import DatabricksEmbeddings
embeddings = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
embeddings.embed_query("Can you explain AI in ten words?")
SQL
Důležité
Následující příklad používá integrovanou funkci SQL ai_query. Tato funkce je ve verzi Public Preview a definice se může změnit. Viz Dotaz na model obsluhované pomocí ai_query().
SELECT ai_query(
"databricks-bge-large-en",
"Can you explain AI in ten words?"
)
Následuje očekávaný formát požadavku pro model vkládání. U externích modelů můžete zahrnout další parametry platné pro daného poskytovatele a konfiguraci koncového bodu. Viz Další parametry dotazu.
{
"input": [
"embedding text"
]
}
Následuje očekávaný formát odpovědi:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": []
}
],
"model": "text-embedding-ada-002-v2",
"usage": {
"prompt_tokens": 2,
"total_tokens": 2
}
}
Dotazování modelu dokončování textu
Následuje žádost o databricks-mpt-30b-instruct dokončení modelu zpřístupněného rozhraními API základního modelu. Parametry a syntaxe najdete v části Úloha dokončení.
Klient Openai
Pokud chcete použít klienta OpenAI, zadejte jako vstup model obsluhující název koncového model bodu. Následující příklad předpokládá, že máte v clusteru nainstalovaný token openai rozhraní API Databricks.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
completion = client.completions.create(
model="databricks-mpt-30b-instruct",
prompt="what is databricks",
temperature=1.0
)
Rozhraní REST API
Důležité
Následující příklad používá parametry rozhraní REST API k dotazování obsluhujících koncové body, které obsluhují základní modely. Tyto parametry jsou ve verzi Public Preview a definice se může změnit. Viz POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"prompt": "What is a quoll?", "max_tokens": 64}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-mpt-30b-instruct/invocations
Sada SDK pro nasazení Mlflow
Důležité
Následující příklad používá predict() rozhraní API ze sady SDK pro nasazení MLflow.
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
completions_response = client.predict(
endpoint="databricks-mpt-30b-instruct",
inputs={
"prompt": "What is the capital of France?",
"temperature": 0.1,
"max_tokens": 10,
"n": 2
}
)
Sada Databricks Genai SDK
from databricks_genai_inference import Completion
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
response = Completion.create(
model="databricks-mpt-30b-instruct",
prompt="Write 3 reasons why you should train an AI model on domain specific data sets.",
max_tokens=128)
print(f"response.text:{response.text:}")
SQL
Důležité
Následující příklad používá integrovanou funkci SQL ai_query. Tato funkce je ve verzi Public Preview a definice se může změnit. Viz Dotaz na model obsluhované pomocí ai_query().
SELECT ai_query(
"databricks-mpt-30b-instruct",
"Can you explain AI in ten words?"
)
Následuje očekávaný formát požadavku pro model dokončení. U externích modelů můžete zahrnout další parametry platné pro daného poskytovatele a konfiguraci koncového bodu. Viz Další parametry dotazu.
{
"prompt": "What is mlflow?",
"max_tokens": 100,
"temperature": 0.1,
"stop": [
"Human:"
],
"n": 1,
"stream": false,
"extra_params":{
"top_p": 0.9
}
}
Následuje očekávaný formát odpovědi:
{
"id": "cmpl-8FwDGc22M13XMnRuessZ15dG622BH",
"object": "text_completion",
"created": 1698809382,
"model": "gpt-3.5-turbo-instruct",
"choices": [
{
"text": "MLflow is an open-source platform for managing the end-to-end machine learning lifecycle. It provides tools for tracking experiments, managing and deploying models, and collaborating on projects. MLflow also supports various machine learning frameworks and languages, making it easier to work with different tools and environments. It is designed to help data scientists and machine learning engineers streamline their workflows and improve the reproducibility and scalability of their models.",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 83,
"total_tokens": 88
}
}
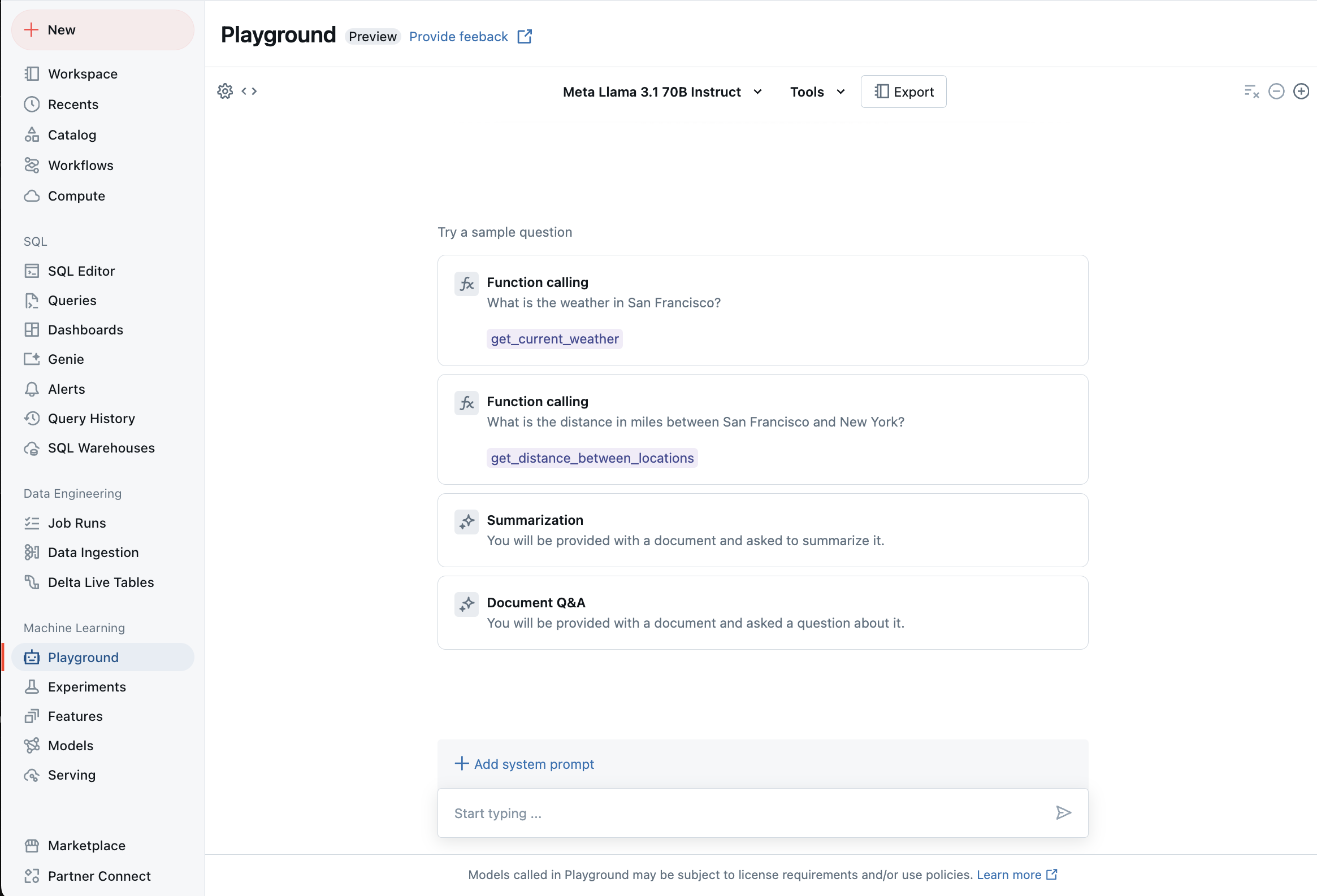
Chat s podporovanými LLM pomocí AI Playground
S podporovanými velkými jazykovými modely můžete pracovat pomocí AI Playgroundu. AI Playground je prostředí podobné chatu, ve kterém můžete testovat, zobrazovat výzvy a porovnávat LLM z pracovního prostoru Azure Databricks.
Další materiály
- Odvozování tabulek pro monitorování a ladění modelů
- Dávkové odvozování s využitím rozhraní API základního modelu
- Rozhraní API modelu Databricks Foundation
- Externí modely ve službě Databricks Model Serving
- Podporované modely pro platby za token
- Referenční informace k rozhraní REST API základního modelu
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro