Příklad registru modelu pracovního prostoru
Poznámka:
Tato dokumentace se zabývá registrem modelů pracovního prostoru. Azure Databricks doporučuje používat modely v katalogu Unity. Modely v katalogu Unity poskytují centralizované zásady správného řízení modelu, přístup mezi pracovními prostory, rodokmen a nasazení. Registr modelů pracovního prostoru bude v budoucnu zastaralý.
Tento příklad ukazuje, jak pomocí registru modelů pracovního prostoru vytvořit aplikaci strojového učení, která předpovídá denní výkon větrné farmy. Příklad ukazuje, jak:
- Sledování a protokolování modelů pomocí MLflow
- Registrace modelů v registru modelů
- Popis modelů a přechody fází verze modelu
- Integrace registrovaných modelů s produkčními aplikacemi
- Vyhledávání a zjišťování modelů v registru modelů
- Archivace a odstraňování modelů
Tento článek popisuje, jak provést tyto kroky pomocí rozhraní API a rozhraní API registru modelů MLflow a MLflow.
Poznámkový blok, který provádí všechny tyto kroky pomocí rozhraní API pro sledování MLflow a Registry, najdete v ukázkovém poznámkovém bloku Registru modelů.
Načtení datové sady, trénování modelu a sledování pomocí MLflow Tracking
Než budete moct zaregistrovat model v registru modelů, musíte model nejprve vytrénovat a protokolovat během spuštění experimentu. Tato část ukazuje, jak načíst datovou sadu větrné farmy, vytrénovat model a protokolovat trénovací běh do MLflow.
Načtení datové sady
Následující kód načte datovou sadu obsahující informace o počasí a výstupu napájení pro větrnou farmu v USA. Datová sada obsahuje wind direction, wind speeda air temperature funkce vzorkované každých šest hodin (jednou na 00:00, najednou 08:00a jednou na 16:00), stejně jako denní agregační výkon (power) za několik let.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Trénování modelu
Následující kód trénuje neurální síť pomocí TensorFlow Kerasu k predikci výstupu napájení na základě funkcí počasí v datové sadě. MLflow se používá ke sledování hyperparametrů modelu, metrik výkonu, zdrojového kódu a artefaktů.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Registrace a správa modelu pomocí uživatelského rozhraní MLflow
V této části:
- Vytvoření nového registrovaného modelu
- Seznámení s uživatelským rozhraním registru modelů
- Přidání popisů modelu
- Přechod verze modelu
Vytvoření nového registrovaného modelu
Na bočním panelu Spuštění experimentu MLflow klikněte na ikonu
 Experiment na pravém bočním panelu poznámkového bloku Azure Databricks.
Experiment na pravém bočním panelu poznámkového bloku Azure Databricks.
Vyhledejte běh MLflow odpovídající trénovací relaci modelu TensorFlow Keras a otevřete ho v uživatelském rozhraní spuštění MLflow kliknutím na ikonu Zobrazit podrobnosti spuštění.
V uživatelském rozhraní MLflow se posuňte dolů do části Artefakty a klikněte na adresář pojmenovaný model. Klikněte na tlačítko Zaregistrovat model , které se zobrazí.

V rozevírací nabídce vyberte Vytvořit nový model a zadejte následující název modelu:
power-forecasting-model.Klikněte na Zaregistrovat. Tím se zaregistruje nový volaný
power-forecasting-modelmodel a vytvoří novou verzi modelu:Version 1.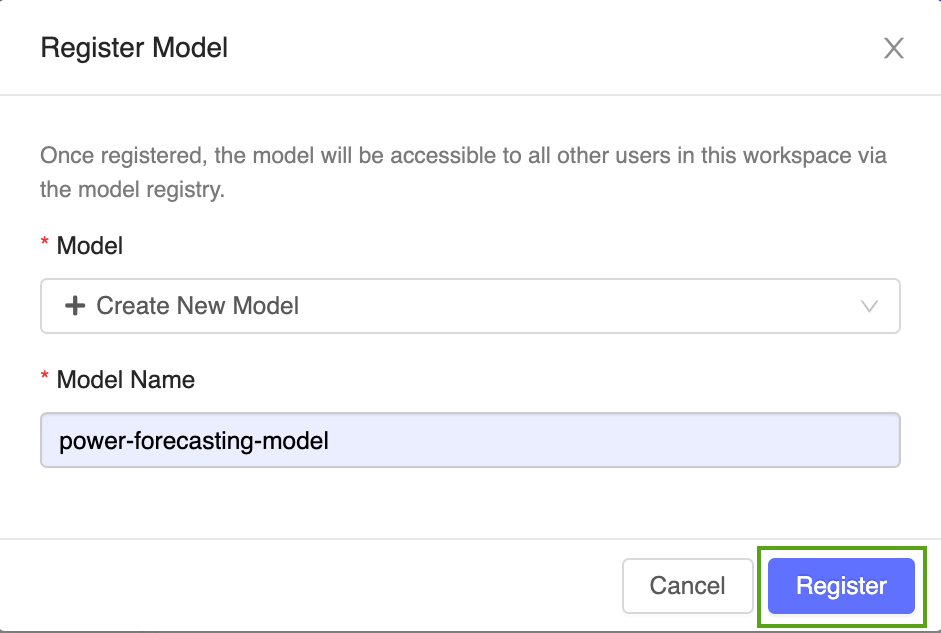
Po chvíli se v uživatelském rozhraní MLflow zobrazí odkaz na nový registrovaný model. Na tomto odkazu otevřete novou verzi modelu v uživatelském rozhraní registru modelů MLflow.
Seznámení s uživatelským rozhraním registru modelů
Stránka verze modelu v uživatelském rozhraní registru modelů MLflow poskytuje informace o Version 1 registrovaném modelu prognózování, včetně jejího autora, času vytvoření a aktuální fáze.
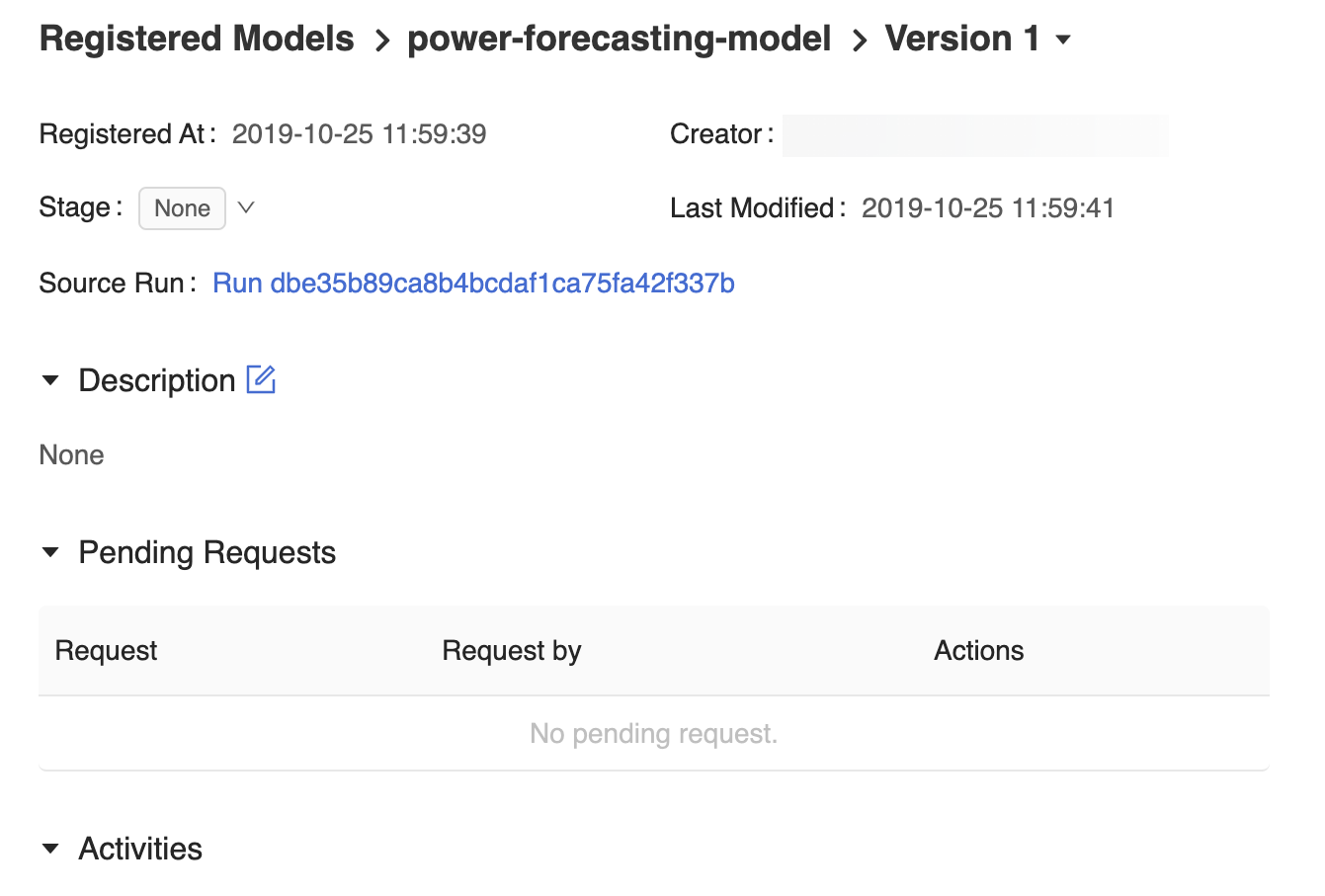
Stránka verze modelu obsahuje také odkaz Na zdrojové spuštění , který otevře běh MLflow, který byl použit k vytvoření modelu v uživatelském rozhraní MLflow Run. V uživatelském rozhraní MLflow Run můžete získat přístup k odkazu na zdrojový poznámkový blok a zobrazit snímek poznámkového bloku Azure Databricks, který se použil k trénování modelu.


Chcete-li přejít zpět do registru modelů MLflow, klepněte na tlačítko ![]() Modely na bočním panelu.
Modely na bočním panelu.
Výsledná domovská stránka registru modelů MLflow zobrazí seznam všech registrovaných modelů v pracovním prostoru Azure Databricks, včetně jejich verzí a fází.
Kliknutím na odkaz modelu power-forecasting-model otevřete registrovanou stránku modelu, která zobrazí všechny verze modelu prognózování.
Přidání popisů modelu
Popisy můžete přidat k registrovaným modelům a verzím modelů. Popisy registrovaných modelů jsou užitečné pro zaznamenávání informací, které platí pro více verzí modelu (např. obecný přehled problému modelování a datové sady). Popisy verzí modelu jsou užitečné pro podrobné popisy jedinečných atributů konkrétní verze modelu (např. metodologie a algoritmus použitý k vývoji modelu).
Přidejte do registrovaného modelu prognózování výkonu popis vysoké úrovně. Klikněte na
 ikonu a zadejte následující popis:
ikonu a zadejte následující popis:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.
Klikněte na Uložit.
Kliknutím na odkaz verze 1 ze stránky registrovaného modelu přejděte zpět na stránku verze modelu.
Klikněte na
ikonu a zadejte následující popis:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.
Klikněte na Uložit.
Přechod verze modelu
Registr modelů MLflow definuje několik fází modelu: None, Staging, Production a Archived. Každá fáze má jedinečný význam. Příprava je například určená pro testování modelů, zatímco produkční je určená pro modely, které dokončily testování nebo kontroly procesů a byly nasazeny do aplikací.
Kliknutím na tlačítko Fáze zobrazíte seznam dostupných fází modelu a dostupných možností přechodu fáze.
Vyberte Přechod do –> Produkční a stisknutím ok v potvrzovacím okně přechodu fáze převést model do produkčního prostředí.

Po přechodu verze modelu do produkčního prostředí se v uživatelském rozhraní zobrazí aktuální fáze a do protokolu aktivit se přidá položka, která bude odrážet přechod.


Registr modelů MLflow umožňuje více verzím modelu sdílet stejnou fázi. Při odkazování na model podle fáze používá registr modelů nejnovější verzi modelu (verze modelu s největším ID verze). Na stránce zaregistrovaného modelu se zobrazí všechny verze konkrétního modelu.

Registrace a správa modelu pomocí rozhraní API MLflow
V této části:
- Definování názvu modelu prostřednictvím kódu programu
- Registrace modelu
- Přidání popisů verzí modelu a modelu pomocí rozhraní API
- Převod verze modelu a načtení podrobností pomocí rozhraní API
Definování názvu modelu prostřednictvím kódu programu
Teď, když je model zaregistrovaný a převedený do produkčního prostředí, můžete na něj odkazovat pomocí programových rozhraní API MLflow. Název registrovaného modelu definujte následujícím způsobem:
model_name = "power-forecasting-model"
Registrace modelu
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Přidání popisů verzí modelu a modelu pomocí rozhraní API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Převod verze modelu a načtení podrobností pomocí rozhraní API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Načtení verzí registrovaného modelu pomocí rozhraní API
Komponenta MLflow Models definuje funkce pro načítání modelů z několika architektur strojového učení. Slouží například mlflow.tensorflow.load_model() k načtení modelů TensorFlow uložených ve formátu MLflow a mlflow.sklearn.load_model() slouží k načtení modelů scikit-learn uložených ve formátu MLflow.
Tyto funkce můžou načítat modely z registru modelů MLflow.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Prognózování výstupu napájení pomocí produkčního modelu
V této části se produkční model používá k vyhodnocení dat předpovědi počasí pro větrnou farmu. Aplikace forecast_power() načte nejnovější verzi modelu prognózování ze zadané fáze a použije ji k prognózování výroby energie během následujících pěti dnů.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Vytvoření nové verze modelu
Klasické techniky strojového učení jsou také efektivní pro prognózování výkonu. Následující kód trénuje náhodný model doménové struktury pomocí knihovny scikit-learn a zaregistruje ho v registru modelů MLflow prostřednictvím mlflow.sklearn.log_model() funkce.
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Načtení id nové verze modelu pomocí vyhledávání registru modelů MLflow
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Přidání popisu do nové verze modelu
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Přechod nové verze modelu na přípravnou a otestování modelu
Před nasazením modelu do produkční aplikace je často osvědčeným postupem ho otestovat v přípravném prostředí. Následující kód přeloží novou verzi modelu na přípravnou a vyhodnotí její výkon.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Nasazení nové verze modelu do produkčního prostředí
Po ověření, že nová verze modelu funguje dobře při přípravě, následující kód model přepíná do produkčního prostředí a použije stejný kód aplikace z výstupu výkonu prognózy s částí produkčního modelu k vytvoření prognózy výkonu.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
V produkční fázi jsou teď dvě verze modelu prognózování: verze modelu natrénovaná v modelu Keras a verze natrénovaná v scikit-learn.

Poznámka:
Při odkazování na model podle fáze registr modelů MLflow automaticky používá nejnovější produkční verzi. To vám umožní aktualizovat produkční modely beze změny kódu aplikace.
Archivace a odstraňování modelů
Pokud už verzi modelu nepoužíváte, můžete ji archivovat nebo odstranit. Můžete také odstranit celý registrovaný model; tím se odeberou všechny jeho přidružené verze modelu.
Archiv Version 1 modelu prognózování výkonu
Archiv Version 1 modelu prognózování výkonu, protože se už nepoužívá. Modely můžete archivovat v uživatelském rozhraní registru modelů MLflow nebo prostřednictvím rozhraní API MLflow.
Archivace Version 1 v uživatelském rozhraní MLflow
Archivace Version 1 modelu prognózování výkonu:
Otevřete odpovídající stránku verze modelu v uživatelském rozhraní registru modelů MLflow:

Klikněte na tlačítko Fáze a vyberte Přechod na –> Archivováno:

V potvrzovacím okně přechodu fáze stiskněte OK .

Archivace Version 1 pomocí rozhraní API MLflow
Následující kód používá MlflowClient.update_model_version() funkci k archivaci Version 1 modelu prognózování výkonu.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Odstranění Version 1 modelu prognózování výkonu
K odstranění verzí modelu můžete použít také uživatelské rozhraní MLflow nebo rozhraní API MLflow.
Upozorňující
Odstranění verze modelu je trvalé a nelze ji vrátit zpět.
Odstranění Version 1 v uživatelském rozhraní MLflow
Version 1 Odstranění modelu prognózování výkonu:
Otevřete odpovídající stránku verze modelu v uživatelském rozhraní registru modelů MLflow.
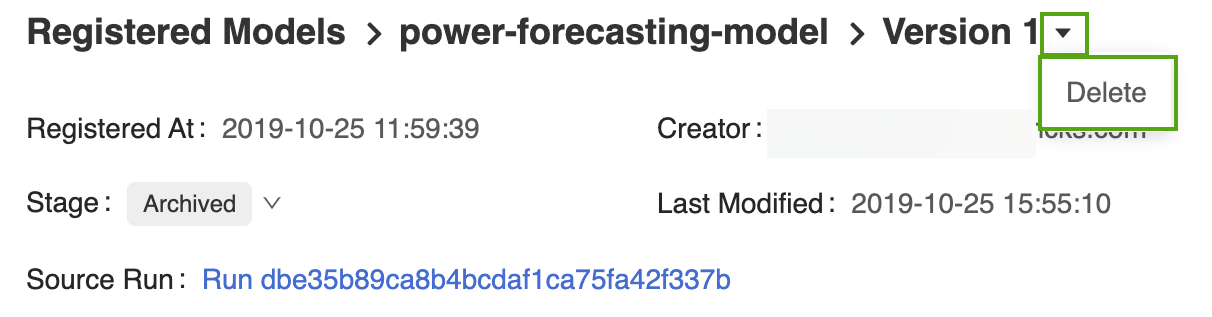
Vyberte šipku rozevíracího seznamu vedle identifikátoru verze a klikněte na Odstranit.
Odstranění Version 1 pomocí rozhraní API MLflow
client.delete_model_version(
name=model_name,
version=1,
)
Odstranění modelu pomocí rozhraní API MLflow
Nejprve je nutné převést všechny zbývající fáze verze modelu na None (Žádné ) nebo Archived (Archivováno).
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)