Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Automatické škálování LakeBase je v beta verzích v následujících oblastech: eastus2, westeurope, westus.
Automatické škálování LakeBase je nejnovější verze LakeBase s automatickým škálováním výpočetních prostředků, škálováním na nulu, větvení a okamžitým obnovením. Porovnání funkcí se službou Lakebase Provisioned najdete v tématu Volba mezi verzemi.
Projekt je kontejner nejvyšší úrovně pro prostředky Lakebase, včetně větví, výpočtů, databází a rolí. Tato stránka vysvětluje, jak vytvářet projekty, porozumět jejich struktuře, konfigurovat nastavení a spravovat jejich životní cyklus.
Pokud s Lakebase teprve začínáte, začněte tím, že začnete vytvářet svůj první projekt.
Porozumění projektům
Struktura projektu
Pochopení struktury projektu Lakebase vám pomůže efektivně organizovat a spravovat prostředky. Projekt je kontejner nejvyšší úrovně pro vaše databáze, větve, výpočty a související prostředky. Každý projekt zahrnuje nastavení výchozích hodnot výpočetních prostředků, obnovení oken a aktualizací, které platí pro všechny větve v projektu.
Na nejvyšší úrovni projekt obsahuje jednu nebo více větví. V rámci projektu můžete vytvářet větve pro různá prostředí, jako je vývoj, testování, příprava a produkce. Každá větev obsahuje vlastní výpočetní prostředky, role a databáze.
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
Větve
Data se nacházejí ve větvích. Každý projekt Lakebase je vytvořen s kořenovou větví nazvanou production, kterou nelze odstranit. I když můžete vytvořit další větve a určit jinou větev jako výchozí větev, kořenovou větev nelze odstranit.
Podřízené větve můžete vytvářet z libovolné větve v projektu. Když vytvoříte podřízenou větev, dědí všechny databáze, role a data z nadřazené větve v okamžiku vytvoření. Následné změny v nadřazené větvi se automaticky nešíří do podřízené větve, což umožňuje izolovaný vývoj, testování nebo experimentování.
Každá větev může obsahovat více databází a rolí. Další informace: Správa větví
Vypočítá
Výpočetní jednotka je virtualizovaný výpočetní zdroj, který zahrnuje vCPU a paměť pro spuštění PostgreSQL. Při vytváření projektu se pro výchozí větev projektu vytvoří primární výpočetní prostředí R/W (čtení i zápis). Každá větev má jeden primární R/W výpočetní prvek. Pokud se chcete připojit k databázi, která se nachází ve větvi, musíte se připojit pomocí výpočetních prostředků R/W přidružených k této větvi.
Kromě primárního výpočetního prostředí R/W můžete do libovolné větve přidat jednu nebo více výpočetních jednotek jako repliky pro čtení (pouze ke čtení). Repliky pro čtení umožňují přesměrovat úlohy jen pro čtení z primárního výpočetního prostředí pro případy použití, jako jsou horizontální škálování čtení, dotazy analýzy a generování sestav a přístup jen pro čtení pro uživatele nebo aplikace. Další informace: Správa výpočetních prostředků, replik pro čtení
Role
Role jsou rolemi Postgres. K vytvoření a přístupu k databázi se vyžaduje role. Role náleží k větvi. Při vytváření projektu se automaticky vytvoří role Postgres pro vaši identitu Databricks (například user@databricks.com), což je vlastník výchozí databricks_postgres databáze. Každá role vytvořená v uživatelském rozhraní Lakebase se vytvoří s oprávněními databricks_superuser . Pro každou větev platí limit 500 rolí. Další informace: Správa rolí
Databáze
Databáze je kontejner pro objekty SQL, jako jsou schémata, tabulky, zobrazení, funkce a indexy. V Lakebase patří databáze do větve. Výchozí větev vašeho projektu je vytvořena s databází nazvanou databricks_postgres. Pro každou větev platí limit 500 databází. Další informace: Správa databází
Schémata
Všechny databáze v Lakebase se vytvářejí se schématem public , což je výchozí chování pro všechny standardní instance Postgres. Objekty SQL se ve výchozím nastavení vytvářejí ve schématu public .
Limity projektu
Lakebase Postgres vynucuje pro projekty následující omezení:
| Resource | Omezení |
|---|---|
| Maximální počet souběžně aktivních výpočetních prostředků | 20 |
| Maximální počet větví na projekt | 500 |
| Maximální počet rolí Postgres na větev | 500 |
| Maximální počet databází Postgres na větev | 500 |
| Maximální velikost logických dat na větev | 8 TB |
| Maximální počet projektů na pracovní prostor | 1 000 |
| Maximální počet chráněných větví | 1 |
| Maximální počet kořenových větví | 3 |
| Maximální počet nearchivovaných větví | 10 |
| Maximální počet snímků | 10 |
| Maximální doba uchovávání historie | 35 dní |
| Minimální škálování na nulu | 60 sekund |
`Limit souběžně aktivních výpočetních prostředků`
Souběžně aktivní limit výpočetních prostředků omezuje počet výpočetních prostředků, které se můžou spustit současně, aby se zabránilo vyčerpání prostředků. Tento limit chrání před náhodnými nárůsty prostředků, například spuštěním mnoha výpočetních koncových bodů najednou. Výchozí limit je 20 současně aktivních výpočtů na jeden projekt.
Důležité: Výchozí větev je z tohoto limitu vyloučená a zajišťuje, aby byla stále dostupná.
Když limit překročíte, zůstanou další výpočetní prostředky nad limit pozastavené a při pokusu o připojení k nim se zobrazí chyba. Řešení je následující:
- Pozastavte ostatní aktivní výpočetní prostředky a zkuste to znovu.
- Pokud k této chybě dochází často, obraťte se na podporu Databricks a požádejte o navýšení limitu.
Poznámka:
Výpočty s povoleným škálováním na nulu se automaticky pozastaví po určité době nečinnosti, což vám pomůže zůstat v rámci souběžně aktivního limitu výpočetních prostředků.
Availability
Dostupnost cloudu a oblasti
Automatické škálování Lakebase Postgres je k dispozici v AWS a Azure.
Oblasti AWS:
-
us-east-1(USA – východ – N. Virginie) -
us-east-2(USA – východ – Ohio) -
eu-central-1(Evropa - Frankfurt) -
eu-west-1(Evropa - Irsko) -
eu-west-2(Evropa - Londýn) -
ap-south-1(Asie Tichomoří - Bombaj) -
ap-southeast-1(Asie Tichomoří - Singapur) -
ap-southeast-2(Asie a Tichomoří - Sydney)
Oblasti Azure (beta verze):
-
eastus2(Východní USA 2) -
westeurope(Západní Evropa) -
westus(USA – západ)
Projekt Lakebase se vytvoří v oblasti pracovního prostoru Databricks.
Podpora verzí Postgres
Automatické škálování Postgres Lakebase podporuje Postgres 16 a Postgres 17.
Vytváření a správa projektů
Vytvoření projektu
V Lakebase Postgres můžete vytvořit více projektů, abyste zajistili úplné oddělení aplikací nebo zákazníků a zajistili tak čisté oddělení dat a prostředků.
Vytvoření projektu:
uživatelské rozhraní
- Kliknutím na přepínač aplikací v pravém horním rohu otevřete aplikaci Lakebase.
- Klikněte na Nový projekt.
- Konfigurace nastavení projektu:
-
Název projektu: Zadejte popisný název projektu. Mezi běžné vzory pojmenování patří pojmenování podle aplikace (například
my-analytics-app) nebo podle zákazníka či nájemce, kterému projekt slouží (napříkladacme-corp-db). - Verze Postgres: Vyberte verzi Postgres, kterou chcete použít.
-
Název projektu: Zadejte popisný název projektu. Mezi běžné vzory pojmenování patří pojmenování podle aplikace (například
Dialogové okno Vytvořit projekt zobrazuje možnosti konfigurace projektu.
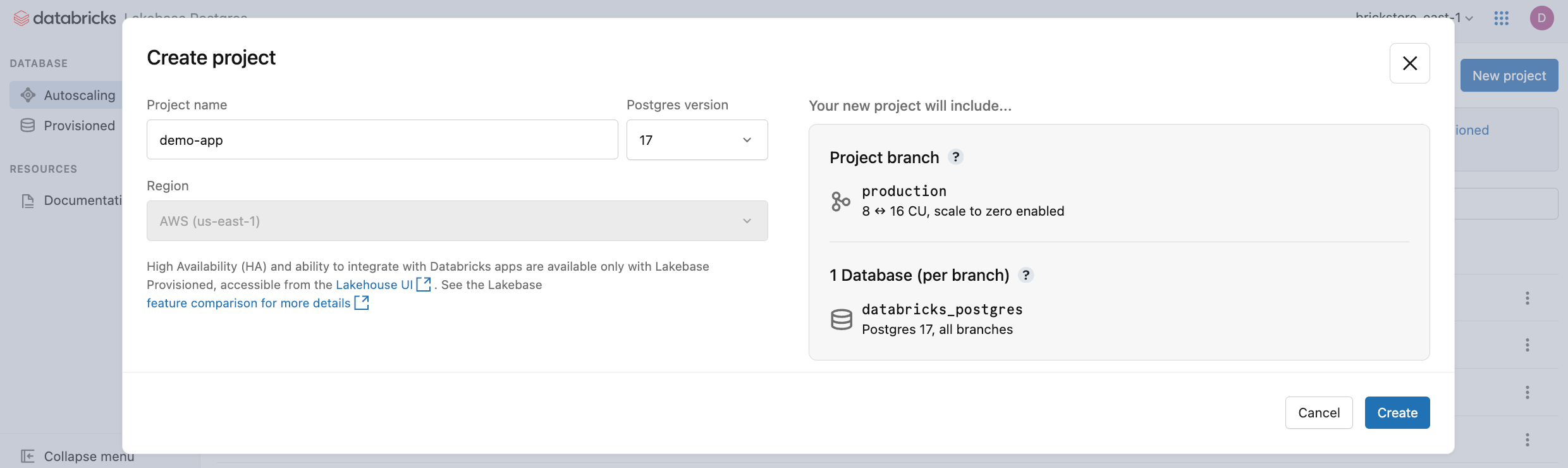
Oblast projektu Lakebase je nastavená na oblast pracovního prostoru Databricks a nelze ji upravit.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version="17"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
CLI
# Create a project with a custom project ID
databricks postgres create-project \
--project-id my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": "17"
}
}'
kroucení
Vytvořte projekt s vlastním ID projektu.
project_id je zadán jako parametr v dotazu a stává se součástí názvu zdroje projektu (například projects/my-app).
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": "17"
}
}' | jq
Jedná se o dlouhotrvající operaci. Odpověď obsahuje název operace, kterou můžete použít ke kontrole stavu. Operace se obvykle dokončí během několika sekund.
Je vyžadován parametr project_id.
Nový projekt ve výchozím nastavení obsahuje následující zdroje:
Jedna
productionvětev (výchozí větev)Jeden primární výpočetní výkon pro čtení i zápis přidružený k větvi s následujícím výchozím nastavením:
Branch Výpočetní jednotky (CU) paměť RAM Autoscaling Škálování na nulu production8 - 32 CU 16 –64 GB Enabled Disabled Když vytvoříte projekt, vytvoří se větev s výpočetním prostředkem
production, který má ve výchozím nastavení zakázáno škálování na nulu, což znamená, že výpočetní prostředek zůstává aktivní neustále. V případě potřeby můžete pro tento výpočetní objekt povolit škálování na nulu.Databáze Postgres (pojmenovaná
databricks_postgres)Role Postgres pro vaši identitu Databricks (například
user@databricks.com)
Pokud chcete změnit nastavení výpočetních prostředků pro existující projekt, přečtěte si téma Konfigurace nastavení projektu. Pokud chcete upravit výchozí nastavení výpočetních prostředků pro nové projekty, přečtěte si téma Výchozí nastavení výpočetních prostředků v části Konfigurace nastavení projektu.
Získání podrobností o projektu
Načtěte podrobnosti pro konkrétní projekt.
uživatelské rozhraní
- Kliknutím na přepínač aplikací v pravém horním rohu otevřete aplikaci Lakebase.
- Výběrem projektu ze seznamu projektů zobrazíte jeho podrobnosti.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
CLI
# Get project details
databricks postgres get-project projects/my-project
kroucení
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Odpověď zahrnuje:
-
name: Název prostředku (projects/my-project) -
status: Konfigurace projektu a aktuální stav (display_name, pg_version, stav atd.)
Poznámka: Pole spec není vyplněno pro GET operace. V poli status se vrátí všechny vlastnosti zdroje.
Výpis projektů
Zobrazí seznam všech projektů v pracovním prostoru.
uživatelské rozhraní
- Kliknutím na přepínač aplikací v pravém horním rohu otevřete aplikaci Lakebase.
- V seznamu projektů se zobrazí všechny projekty, ke kterým máte přístup.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
CLI
# List all projects
databricks postgres list-projects
kroucení
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Formát odpovědi:
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": "17",
"state": "READY"
}
}
]
}
Konfigurace nastavení projektu
Po vytvoření projektu můžete změnit různá nastavení z řídicího panelu projektu tak, že přejdete na Nastavení:
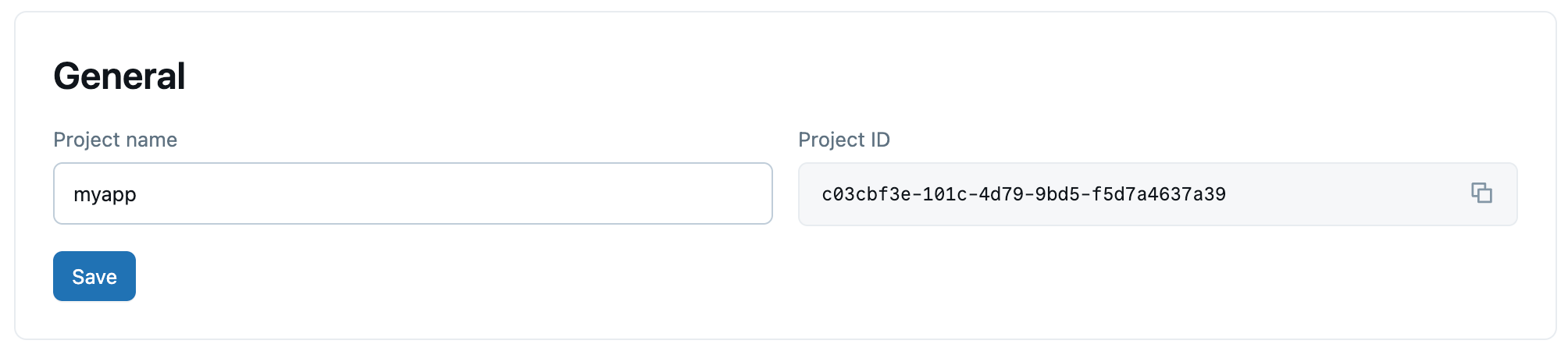
Obecná nastavení
Název projektu můžete aktualizovat. ID projektu nelze změnit.
uživatelské rozhraní
CLI
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
kroucení
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
Jedná se o dlouhotrvající operaci. Odpověď obsahuje název operace, kterou můžete použít ke kontrole stavu.
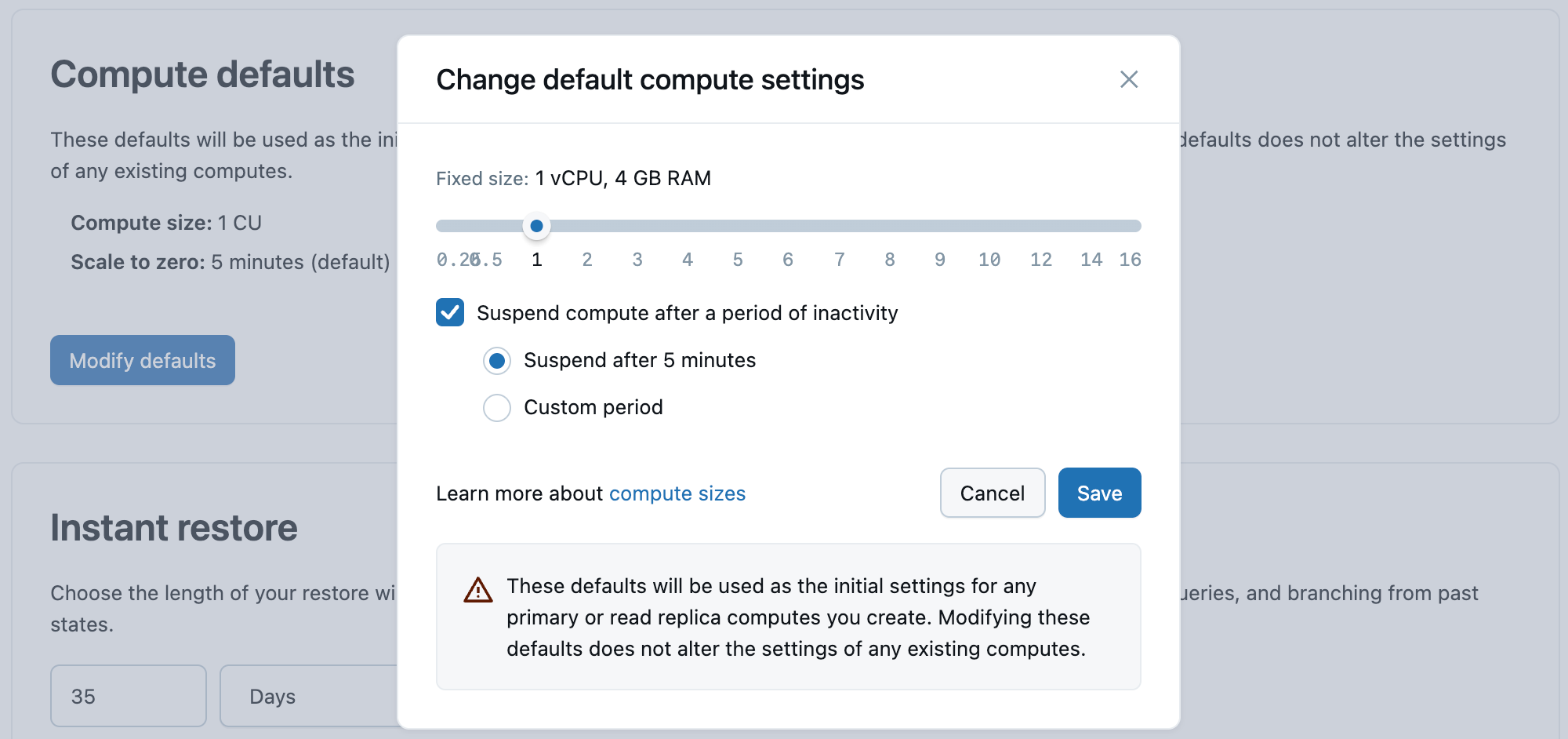
Výchozí nastavení výpočtů
Nastavte počáteční nastavení pro primární výpočetní prostředky, včetně:
- Velikost výpočetních prostředků (měřená ve výpočetních jednotkách)
- Vypršení časového limitu škálování na nulu (výchozí hodnota je 5 minut)
Tato nastavení se používají při vytváření nových primárních výpočetních prostředků.
Poznámka:
Pokud chcete upravit nastavení existujícího výpočetního prostředí, přečtěte si téma Správa výpočetních prostředků.
Lakebase Postgres podporuje výpočetní velikosti od 0,5 CU do 112 CU. Automatické škálování je k dispozici pro výpočty až 32 CU (0,5, pak celé číslo: 1, 2, 3... 16, pak 24, 28, 32). Větší výpočetní prostředky s pevnou velikostí jsou dostupné od 36 CU do 112 CU (36, 40, 44, 48, 52, 56, 60, 64, 72, 80, 88, 96, 104, 112). Každá výpočetní jednotka (CU) poskytuje 2 GB paměti RAM.
Poznámka:
Lakebase Zřízeno vs. Automatické škálování: Ve zřízeném Lakebase má každá výpočetní jednotka přiděleno přibližně 16 GB paměti RAM. V případě automatického škálování LakeBase přidělí každá CU 2 GB paměti RAM. Tato změna poskytuje podrobnější možnosti škálování a kontrolu nákladů.
Reprezentativní velikosti:
| Výpočetní jednotky | paměť RAM |
|---|---|
| 0,5 CU | 1 GB |
| 1 CU | 2 GB |
| 4 CU | 8 GB |
| 16 výpočetních jednotek (CU) | 32 GB |
| 32 výpočetních jednotek (CU) | 64 GB |
| 64 jednotek CU | 128 GB |
| 112 CU | 224 GB |
- Chcete-li povolit automatické škálování, nastavte pomocí posuvníku rozsah velikosti výpočetního výkonu. Automatické škálování dynamicky upravuje výpočetní prostředky na základě poptávky po úlohách. Další informace: Automatické škálování
- Upravte nastavení škálování na nulu, aby se zvýšilo nebo snížilo množství neaktivního výpočetního času před pozastavením výpočetních prostředků. U vždy aktivních výpočetních prostředků můžete také zakázat škálování na nulu . Další informace: Škálování na nulu
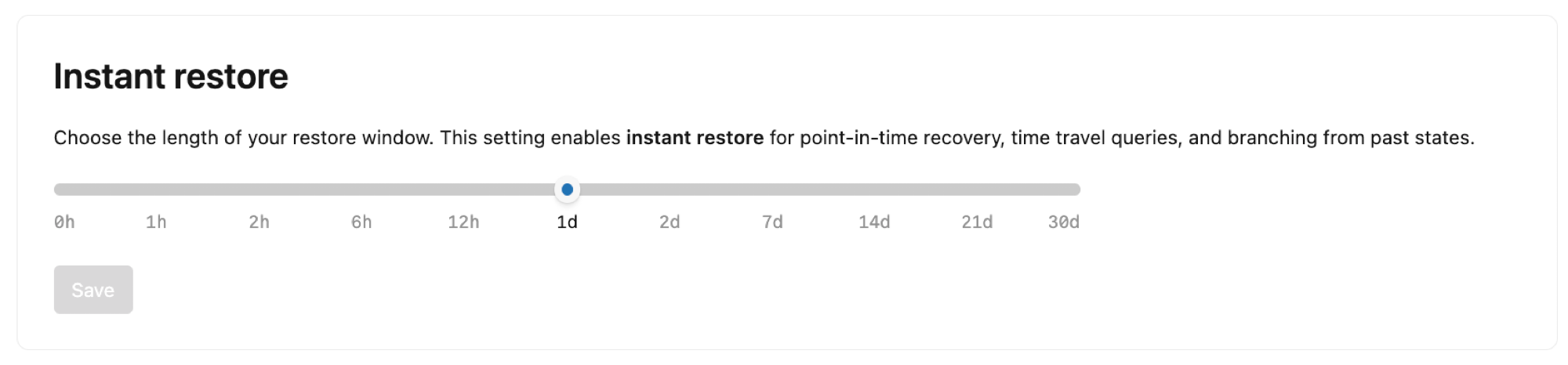
Okamžité obnovení
Nakonfigurujte délku okna obnovení pro váš projekt. Lakebase ve výchozím nastavení uchovává historii změn kořenových větví v projektu, což umožňuje obnovení ztracených dat k určitému časovému bodu, dotazování na data v konkrétním časovém okamžiku pro zkoumání problémů s daty a větvení z minulých stavů pro vývojové pracovní postupy.
Okno obnovení můžete nastavit od 2 dnů až do 35 dnů. Všimněte si, že:
- Rozšíření okna obnovení zvyšuje úložiště.
- Nastavení okna obnovení má vliv na všechny větve v projektu.
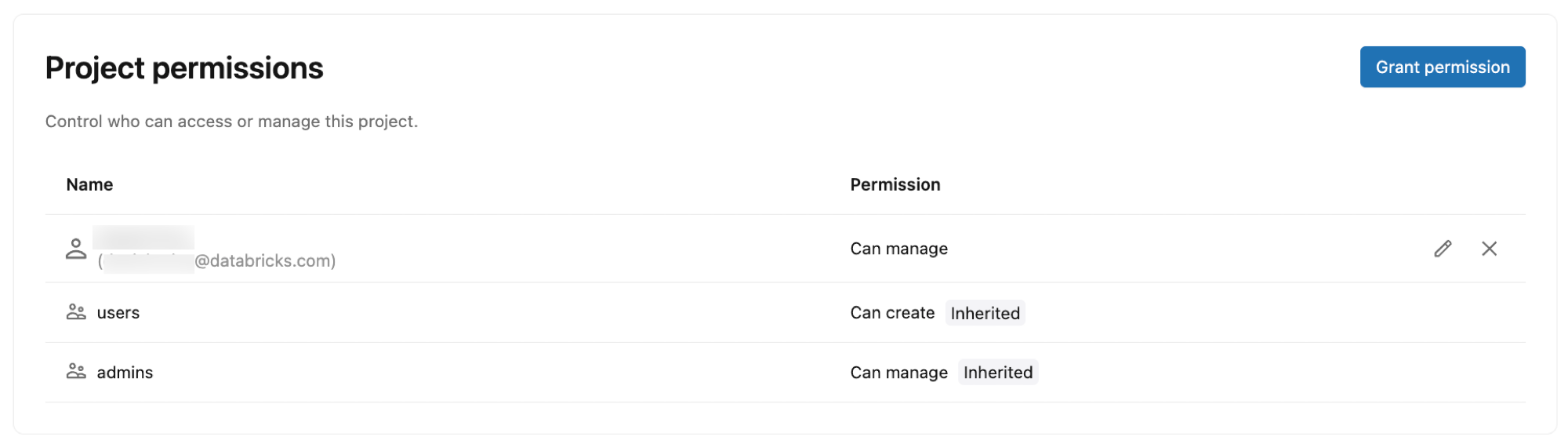
Oprávnění projektu
Určete, kdo může přistupovat k projektu Lakebase a spravovat ho tím, že udělíte oprávnění identitám, skupinám a instančním objektům Azure Databricks. Oprávnění projektu určují, jaké akce můžou uživatelé v rámci projektu provádět, jako jsou vytváření větví, správa výpočetních prostředků a zobrazení podrobností o připojení.
Typy oprávnění:
- MŮŽE VYTVOŘIT: Zobrazení a vytvoření zdrojů projektu
- CAN USE: Zobrazení a používání zdrojů projektu (seznam, zobrazení, připojení a provádění určitých operací větve) bez vytváření nebo odstraňování projektů nebo větví
- MŮŽE SPRAVOVAT: Úplná kontrola nad konfigurací projektu a zdroji
Výchozí oprávnění:
Při vytváření projektu se automaticky přiřadí následující oprávnění:
- Vlastník projektu (uživatel, který projekt vytvořil): MŮŽE SPRAVOVAT (úplné řízení)
- Uživatelé pracovního prostoru: MOHOU VYTVOŘIT (můžou zobrazovat a vytvářet projekty)
- Správci pracovních prostorů: MŮŽOU SPRAVOVAT (úplné řízení)
Pokud chcete udělit přístup jiným uživatelům, přečtěte si téma Správa oprávnění projektu.
Poznámka:
Oprávnění projektu a přístup k databázi jsou oddělená
Oprávnění projektu řídí akce platformy Lakebase, zatímco přístup k databázi je řízen rolemi Postgres a jejich přidruženými oprávněními. Viz Vytvoření rolí Postgres a Správa oprávnění databáze.
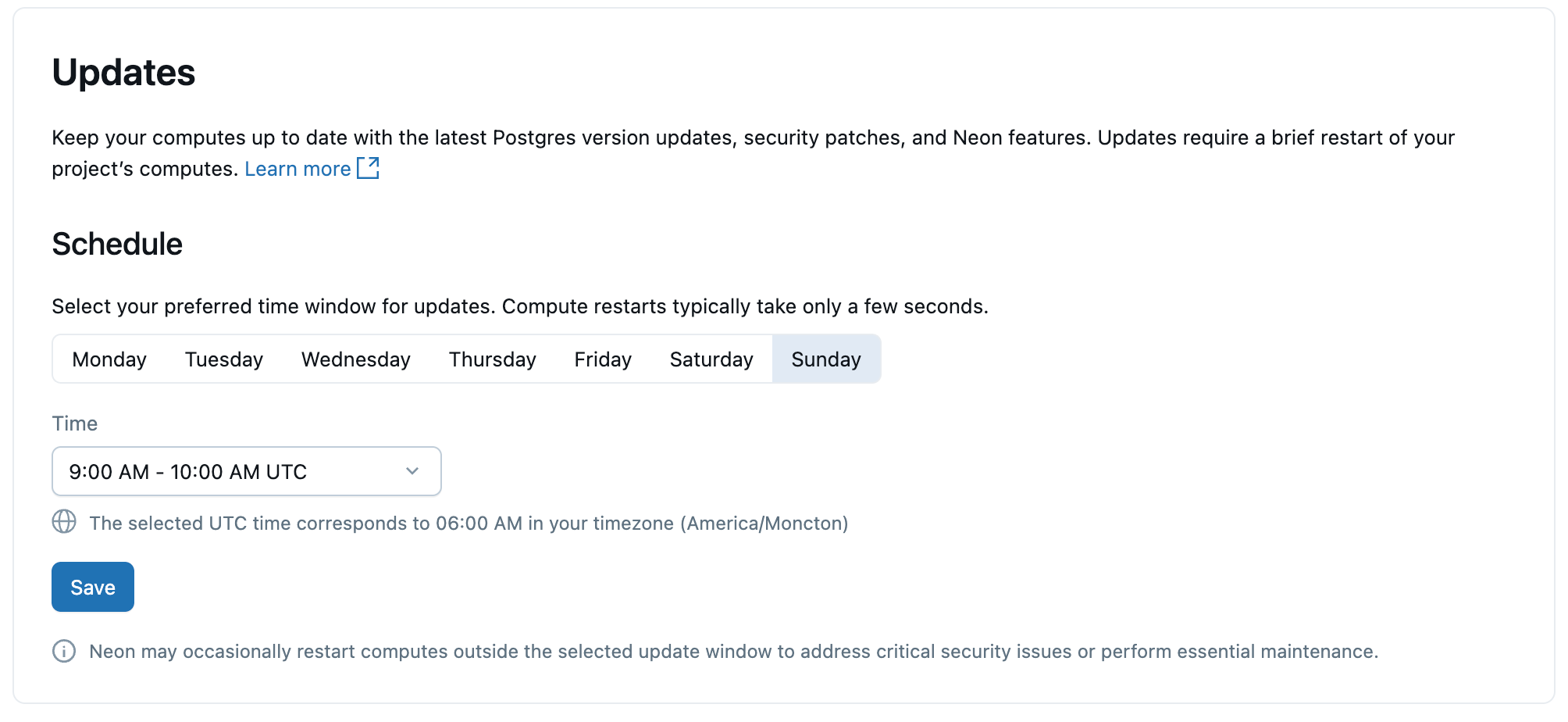
Aktualizace
Aby byly výpočetní prostředky Lakebase a instance Postgres aktuální, lakebase automaticky použije plánované aktualizace, které zahrnují upgrady podverze Postgres, opravy zabezpečení a funkce platformy. Aktualizace se použijí na výpočetní prostředky v rámci projektu a vyžadují krátké restartování výpočetních prostředků, které trvá několik sekund.
Aktualizace se použijí automaticky, ale u aktualizací můžete nastavit upřednostňovaný den a čas. Restartování probíhá v rámci vybraného časového intervalu.
Podrobné informace o aktualizacích najdete v tématu Správa aktualizací.
Odstranění projektu
Odstranění projektu je trvalá akce, která také odstraní všechny výpočty, větve, databáze, role a data, která patří do projektu.
Důležité
Tuto akci nelze vrátit zpět. Při odstraňování projektu buďte opatrní, protože tím odstraníte všechny přidružené větve a data.
Před odstraněním
Databricks doporučuje před odstraněním projektu odstranit všechny přidružené katalogy Unity a synchronizované tabulky. V opačném případě při pokusu o zobrazení katalogů nebo spuštění dotazů SQL odkazujících na ně dojde k chybám.
Pokud nejste vlastníkem tabulek nebo katalogů, musíte vlastnictví před odstraněním znovu přiřadit sami sobě.
Poznámka:
V automatickém škálování Lakebase může jakákoli identita Databricks, která má přístup k pracovnímu prostoru, kde byl projekt vytvořen, odstranit projekty.
Odstranění projektu
Odstranění projektu:
uživatelské rozhraní
- Přejděte do nastavení projektu v aplikaci Lakebase.
- V části Odstranit projekt klikněte na Odstranit a zadáním názvu projektu potvrďte odstranění.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name}")
Jedná se o dlouhotrvající operaci. Projekt a všechny jeho prostředky (větve, koncové body, databáze, role, data) se odstraní.
Java SDK
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
Jedná se o dlouhotrvající operaci. Projekt a všechny jeho prostředky (větve, koncové body, databáze, role, data) se odstraní.
CLI
# Delete a project
databricks postgres delete-project projects/my-project
Tento příkaz se provede okamžitě. Projekt a všechny jeho zdroje budou odstraněny.
kroucení
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Jedná se o dlouhotrvající operaci. Odpověď obsahuje název operace, kterou můžete použít ke kontrole stavu odstranění.