Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Automatické škálování LakeBase je v beta verzích v následujících oblastech: eastus2, westeurope, westus.
Automatické škálování LakeBase je nejnovější verze LakeBase s automatickým škálováním výpočetních prostředků, škálováním na nulu, větvení a okamžitým obnovením. Porovnání funkcí se službou Lakebase Provisioned najdete v tématu Volba mezi verzemi.
Začněte používat Lakebase Postgres během několika minut. Vytvořte svůj první projekt, připojte se k databázi a prozkoumejte klíčové funkce, včetně integrace katalogu Unity.
Vytvoření prvního projektu
Otevřete aplikaci Lakebase z přepínače aplikací.
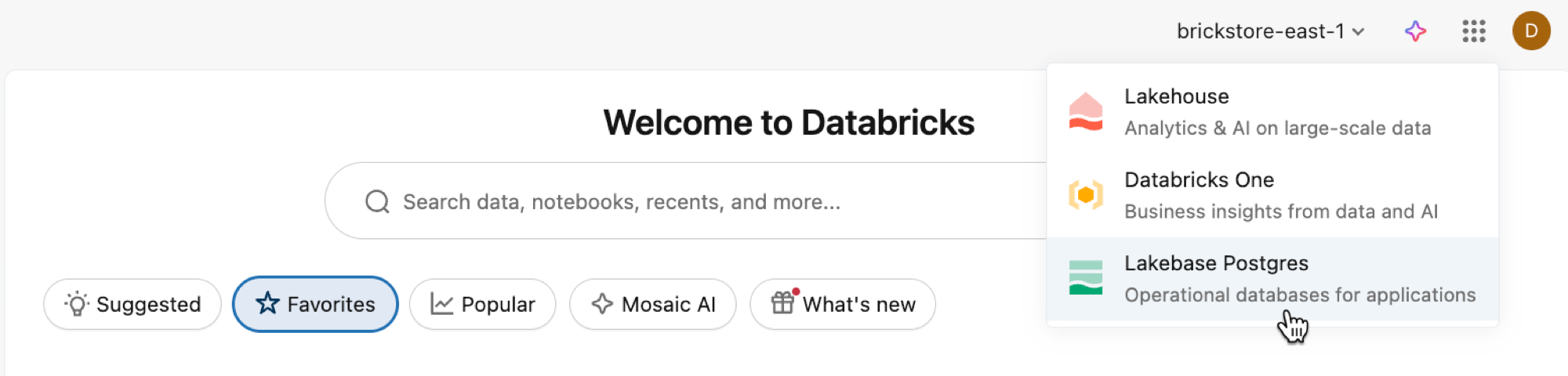
Pokud chcete získat přístup k uživatelskému rozhraní automatického škálování LakeBase, vyberte automatické škálování .
Klikněte na Nový projekt. Pojmenujte projekt a vyberte verzi Postgres. Projekt se vytvoří s jednou production větví, výchozí databricks_postgres databází a výpočetními prostředky nakonfigurovanými pro větev.
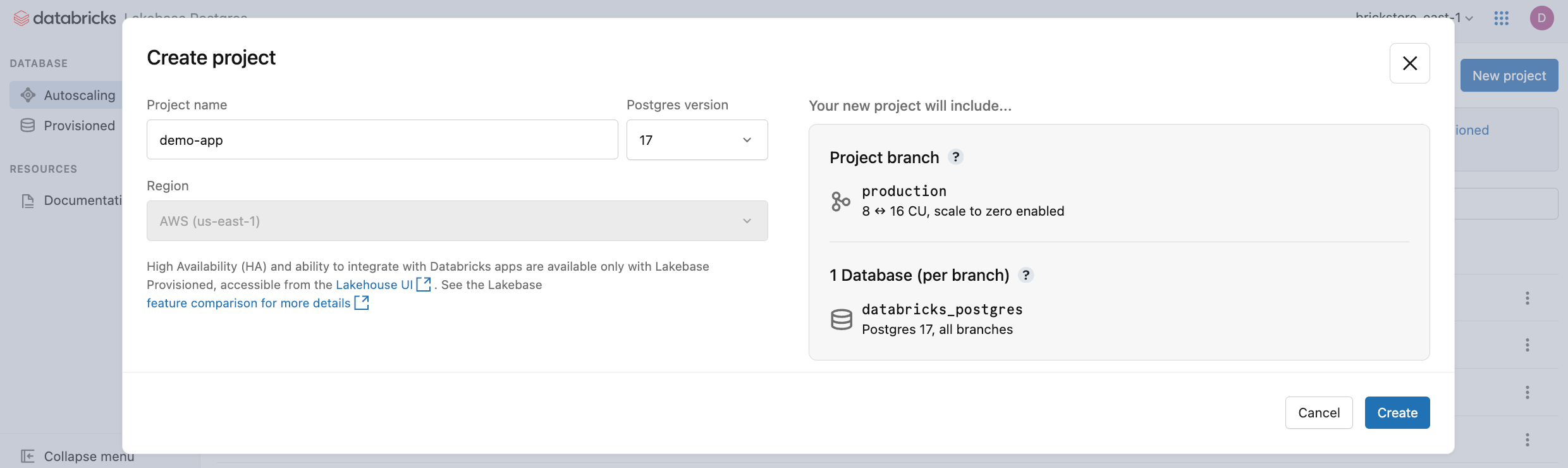
Aktivace vašeho počítače může trvat několik momentů. Výpočty pro production větev jsou ve výchozím nastavení vždy zapnuté (škálování na nulu je zakázané), ale v případě potřeby můžete toto nastavení nakonfigurovat.
Oblast projektu se automaticky nastaví na vaši oblast pracovního prostoru. Podrobné možnosti konfigurace najdete v tématu Vytvoření projektu.
Připojení k databázi
V projektu vyberte produkční větev a klikněte na Připojit. Můžete se připojit pomocí identity Databricks s ověřováním OAuth nebo vytvořit nativní roli hesla Postgres. Připojovací řetězce pracují se standardními klienty Postgres, jako jsou psql, pgAdmin nebo jakýkoli nástroj kompatibilní s Postgres.
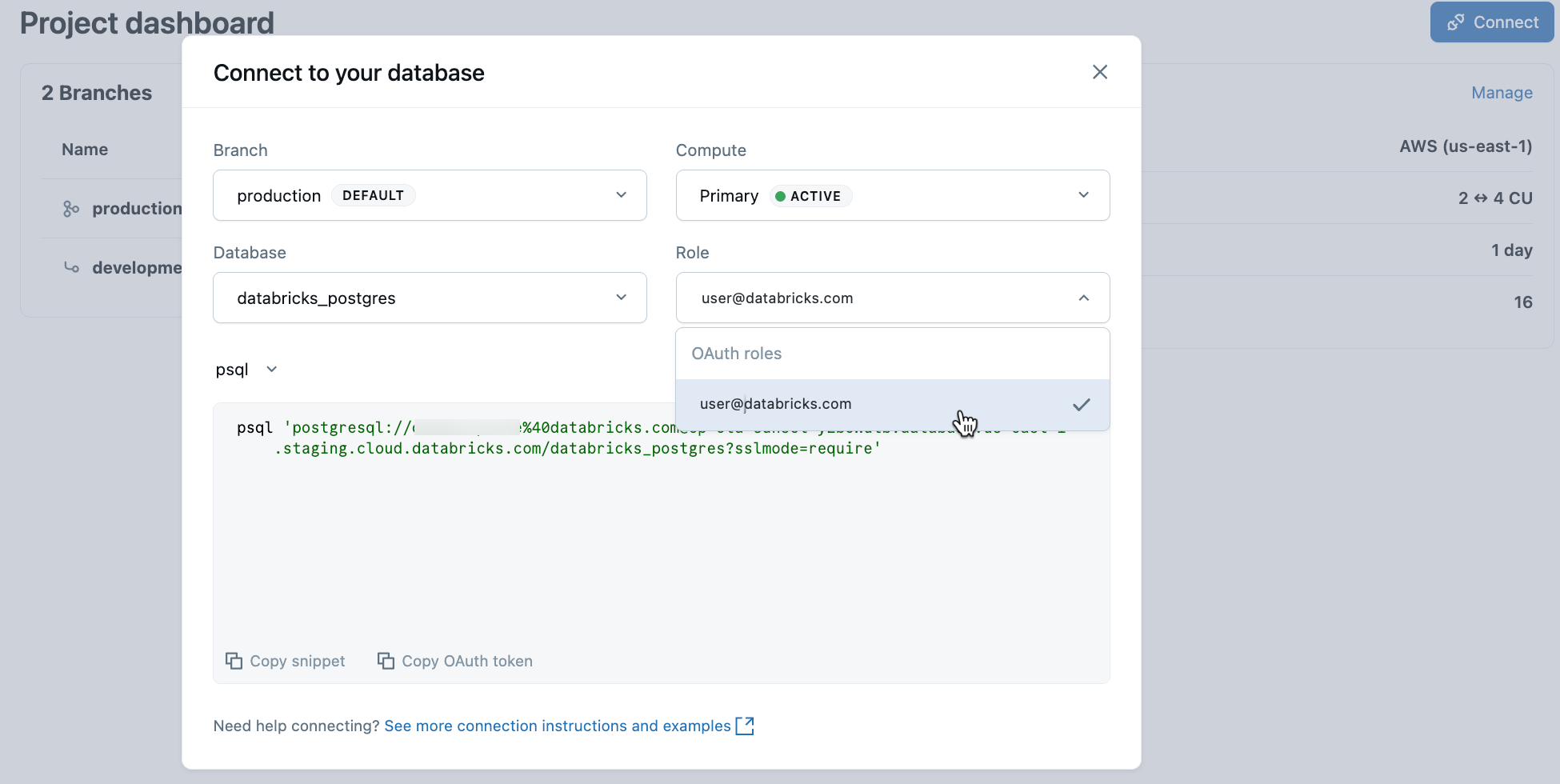
Při vytváření projektu se automaticky vytvoří role Postgres pro vaši identitu Databricks (například user@databricks.com). Tato role vlastní výchozí databricks_postgres databázi a je členem databricks_superusera poskytuje jí široká oprávnění ke správě databázových objektů.
Pokud se chcete připojit pomocí identity Databricks s OAuth, zkopírujte psql fragment připojení z dialogového okna připojení.
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Po zadání příkazu psql připojení v terminálu se zobrazí výzva k zadání tokenu OAuth. Získejte token kliknutím na možnost Kopírovat token OAuth v dialogovém okně připojení.
Podrobnosti o připojení a možnosti ověřování najdete v rychlém startu.
Vytvoření první tabulky
Editor SQL Lakebase je předem naplněný ukázkovými SQL, které vám pomohou začít. V projektu vyberte produkční větev, otevřete Editor SQL a spusťte poskytnuté příkazy pro vytvoření playing_with_lakebase tabulky a vložení ukázkových dat. Editor tabulek můžete také použít ke správě vizuálních dat nebo se připojit k externím klientům Postgres.
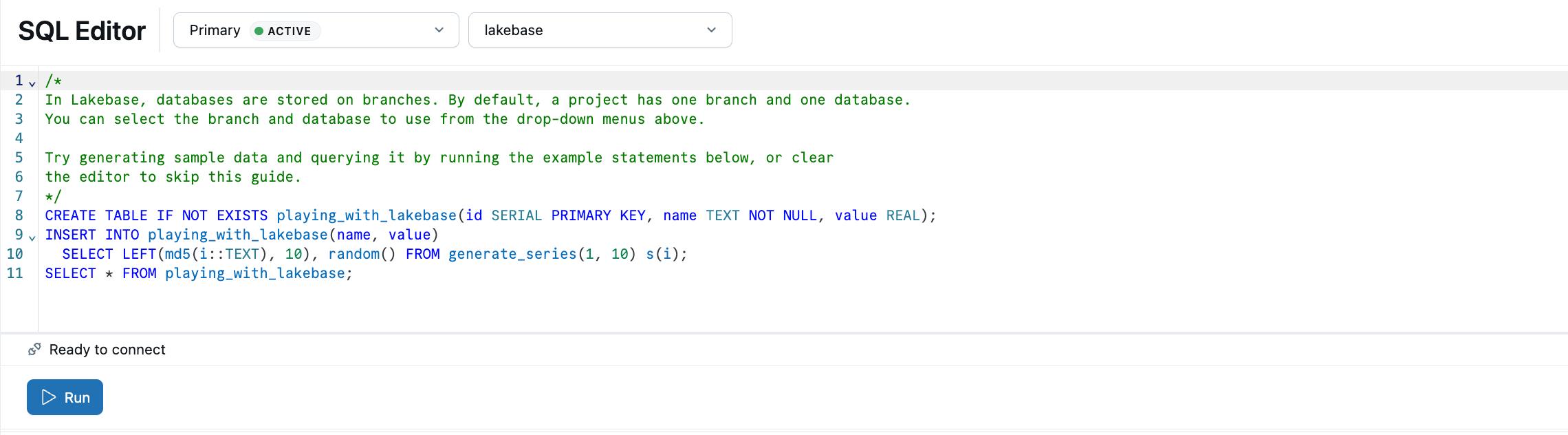
Další informace o možnostech dotazování:Klienti Postgres | |
Registrace v katalogu Unity
Teď, když jste vytvořili tabulku v produkční větvi, zaregistrujeme databázi v katalogu Unity, abyste mohli tato data dotazovat z Editoru SQL Databricks.
- Pomocí přepínače aplikací přejděte na Lakehouse.
- V Průzkumníku katalogu klikněte na ikonu plus a vytvořte katalog.
- Zadejte název katalogu (například
lakebase_catalog). - Jako typ katalogu vyberte Lakebase Postgres a povolte možnost automatického škálování .
- Vyberte projekt,
productionvětev adatabricks_postgresdatabázi. - Klikněte na Vytvořit.
Registrace databáze LKB v katalogu Unity
Teď můžete dotazovat playing_with_lakebase tabulku, kterou jste právě vytvořili z Editoru SQL Databricks, pomocí SQL Warehouse:
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
To umožňuje federované dotazy, které propojují transakční data Lakebase s analýzami lakehouse. Podrobnosti najdete v tématu Registrace v katalogu Unity.
Synchronizace dat pomocí reverse ETL
Právě jste viděli, jak se data Lakebase dají dotazovat v katalogu Unity. Lakebase funguje také v opačném směru: přenesení spravovaných analytických dat z Unity Catalog do databáze Lakebase. To je užitečné, když máte obohacená data, vlastnosti strojového učení nebo agregované metriky vypočítané ve vašem lakehouse, které musí podporovat aplikace s transakčními dotazy s nízkou latencí.
Nejprve vytvořte tabulku v katalogu Unity, která představuje analytická data. Otevřete SQL Warehouse nebo poznámkový blok a spusťte:
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Teď synchronizujte tuto tabulku s databází Lakebase:
- V Průzkumníku katalogu Lakehouse přejděte na main>default>user_segments.
- Klikněte na Vytvořit>synchronizovanou tabulku.
- Konfigurace synchronizace:
-
Název tabulky: Enter
user_segments_synced. - Typ databáze: Vyberte Bezserverovou databázi Lakebase (automatické škálování).
- Režim synchronizace: Zvolte snímek pro jednorázovou synchronizaci dat.
- Vyberte projekt, produkční větev a
databricks_postgresdatabázi.
-
Název tabulky: Enter
- Klikněte na Vytvořit.
Po dokončení synchronizace se tabulka zobrazí v databázi Lakebase. Proces synchronizace vytvoří default schéma v Postgres, aby odpovídalo schématu katalogu Unity, takže main.default.user_segments_synced se stane default.user_segments_synced. Přejděte zpět na Lakebase pomocí přepínače aplikací a dotazujte se na něj v Editoru SQL Lakebase:
SELECT * FROM "default"."user_segments_synced" WHERE "engagement" = 'high';
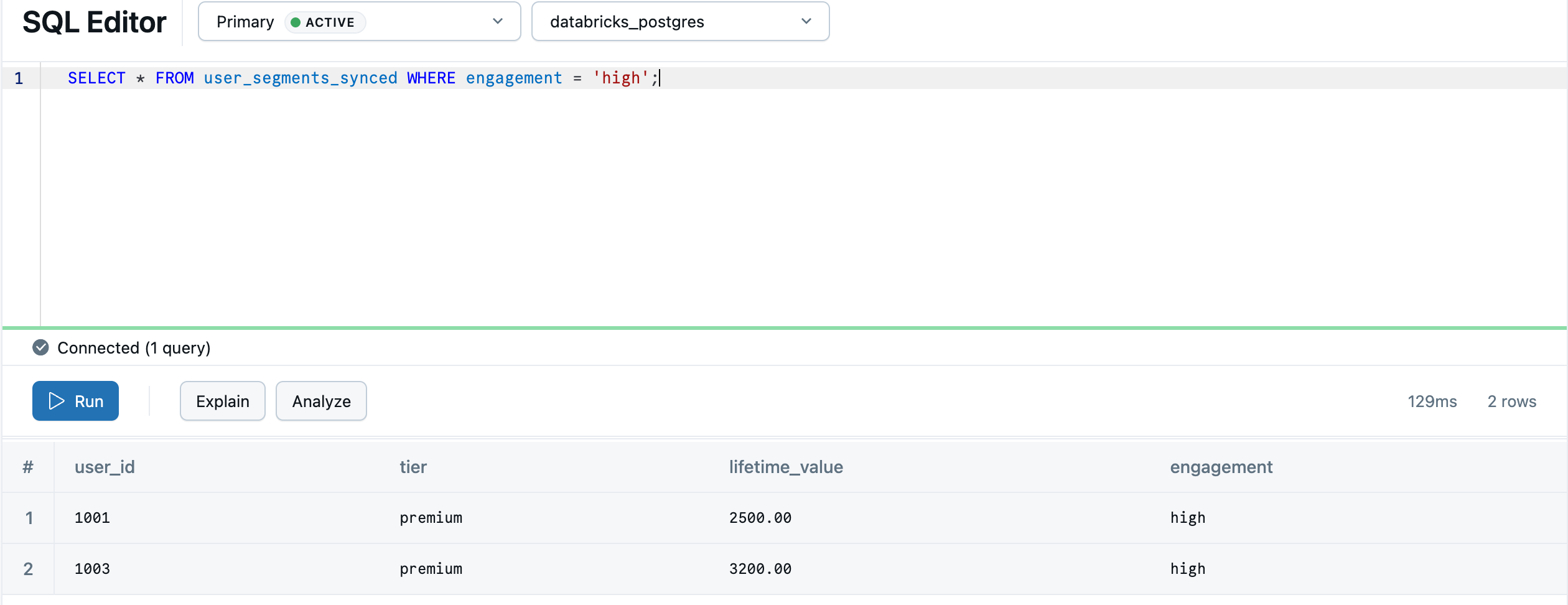
Analýzy lakehouse jsou teď k dispozici pro poskytování v transakčních databázích v reálném čase. Informace o průběžné synchronizaci, pokročilých konfiguracích a mapování datových typů najdete v tématu Reverse ETL.