Techniky CI/CD se složkami Git a Databricks Git (Repos)
Naučte se používat složky Gitu Databricks v pracovních postupech CI/CD. Konfigurací složek Git Databricks v pracovním prostoru můžete použít správu zdrojového kódu pro soubory projektu v úložištích Git a integrovat je do svých kanálů přípravy dat.
Následující obrázek znázorňuje přehled technik a pracovních postupů.
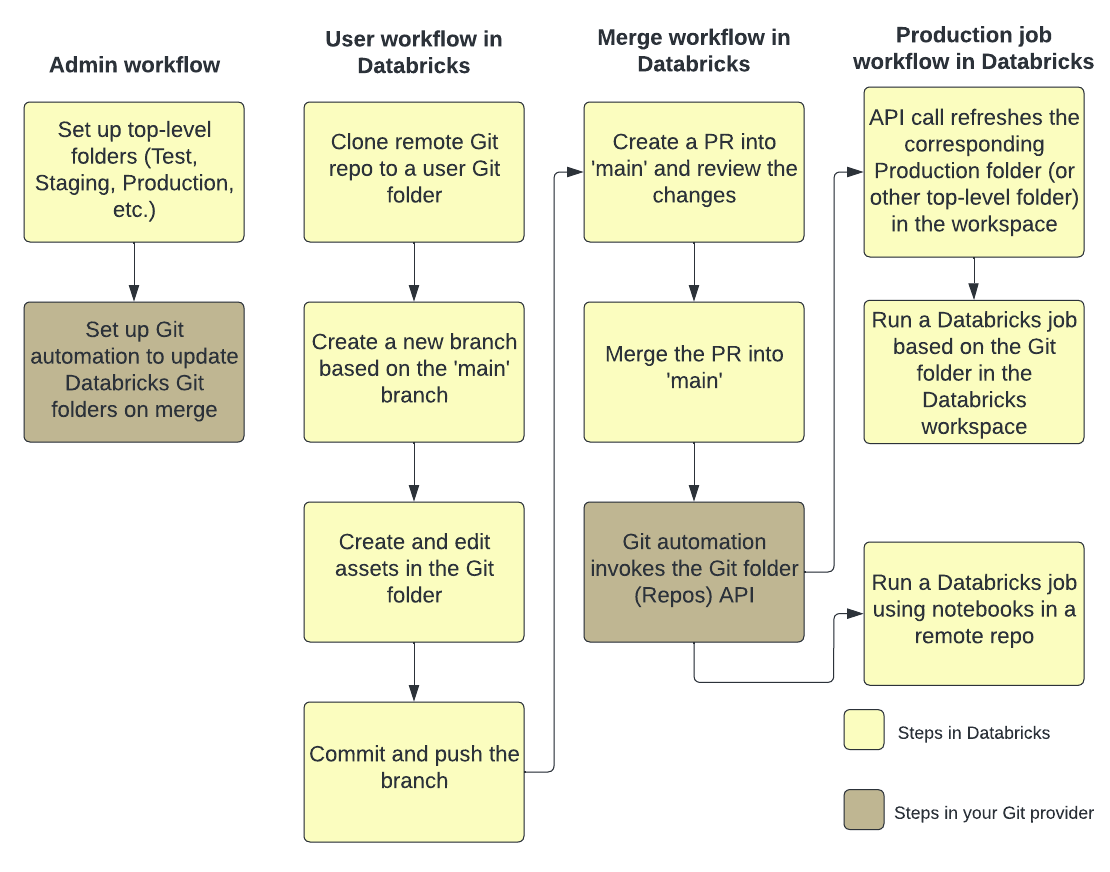
Přehled CI/CD s Azure Databricks najdete v tématu Co je CI/CD v Azure Databricks?.
Vývojový tok
Složky Gitu databricks mají složky na úrovni uživatele. Složky na úrovni uživatele se automaticky vytvoří, když uživatelé poprvé naklonují vzdálené úložiště. Složky Gitu Databricks si můžete představit jako místní pokladny, které jsou pro každého uživatele individuální a kde uživatelé provádějí změny v kódu.
Ve složce uživatele ve složkách Databricks Git naklonujte vzdálené úložiště. Osvědčeným postupem je vytvořit novou větev funkcí nebo vybrat dříve vytvořenou větev pro vaši práci místo přímého potvrzení a nasdílení změn do hlavní větve. V této větvi můžete provádět změny, potvrzení a nasdílení změn. Až budete připraveni sloučit kód, můžete to udělat v uživatelském rozhraní složek Gitu.
Požadavky
Tento pracovní postup vyžaduje, abyste už nastavili integraci Gitu.
Poznámka:
Databricks doporučuje, aby každý vývojář pracoval ve své vlastní větvi funkcí. Informace o řešení konfliktů při slučování naleznete v tématu Řešení konfliktů při slučování.
Spolupráce ve složkách Gitu
Následující pracovní postup používá větev, feature-b která je založená na hlavní větvi.
- Naklonujte existující úložiště Git do pracovního prostoru Databricks.
- Pomocí uživatelského rozhraní složek Gitu vytvořte větev funkcí z hlavní větve. V tomto příkladu se pro zjednodušení používá jedna větev
feature-bfunkcí. K práci můžete vytvořit a použít více větví funkcí. - Upravte poznámkové bloky Azure Databricks a další soubory v úložišti.
- Potvrďte a nasdílejte změny poskytovateli Gitu.
- Přispěvatelé teď můžou úložiště Git naklonovat do své vlastní uživatelské složky.
- Při práci na nové větvi udělá spolupracovník změny v poznámkových blocích a dalších souborech ve složce Git.
- Přispěvatel potvrdí a nasdílí změny poskytovateli Gitu.
- Pokud chcete sloučit změny z jiných větví nebo změnit základ větve feature-b v Databricks, použijte v uživatelském rozhraní složek Gitu jeden z následujících pracovních postupů:
- Sloučit větve. Pokud nedojde ke konfliktu, sloučení se odešle do vzdáleného úložiště Git pomocí
git push. - Změna základu v jiné větvi.
- Sloučit větve. Pokud nedojde ke konfliktu, sloučení se odešle do vzdáleného úložiště Git pomocí
- Až budete připraveni sloučit svou práci do vzdáleného úložiště Git a
mainvětve, použijte uživatelské rozhraní složek Git ke sloučení změn z feature-b. Pokud chcete, můžete místo toho sloučit změny přímo do úložiště Git, které zálohuje složku Git.
Pracovní postup produkční úlohy
Složky Gitu databricks poskytují dvě možnosti pro spouštění produkčních úloh:
- Možnost 1: Zadejte vzdálený odkaz Gitu v definici úlohy. Například spusťte konkrétní poznámkový blok ve
mainvětvi úložiště Git. - Možnost 2: Nastavte produkční úložiště Git a volejte rozhraní API pro úložiště Repos, aby se aktualizovala programově. Spusťte úlohy ve složce Git Databricks, která klonuje toto vzdálené úložiště. Volání rozhraní API úložiště by mělo být prvním úkolem v úloze.
Možnost 1: Spouštění úloh pomocí poznámkových bloků ve vzdáleném úložišti
Zjednodušte proces definice úlohy a udržujte jediný zdroj pravdy spuštěním úlohy Azure Databricks pomocí poznámkových bloků umístěných ve vzdáleném úložišti Git. Tento odkaz na Git může být potvrzení Gitu, značka nebo větev a poskytuje ho v definici úlohy.
To pomáhá zabránit neúmyslným změnám v produkční úloze, například když uživatel provede místní úpravy v produkčním úložišti nebo přepne větve. Také automatizuje krok CD, protože nemusíte vytvářet samostatnou produkční složku Git v Databricks, spravovat oprávnění pro něj a udržovat ji aktualizovanou.
Viz Použití zdrojového kódu řízeného verzí v úloze Azure Databricks.
Možnost 2: Nastavení produkční složky Git a automatizace Gitu
V této možnosti nastavíte produkční složku Git a automatizaci pro aktualizaci složky Git při sloučení.
Krok 1: Nastavení složek nejvyšší úrovně
Správce vytvoří složky nejvyšší úrovně bez uživatele. Nejběžnějším případem použití těchto složek nejvyšší úrovně je vytvoření vývojových, přípravných a produkčních složek, které obsahují složky Git Databricks pro příslušné verze nebo větve pro vývoj, přípravu a produkci. Pokud například vaše společnost používá main větev pro produkční prostředí, musí mít složka Git " main production" rezervovanou větev.
Oprávnění k těmto složkám nejvyšší úrovně jsou obvykle jen pro čtení pro všechny uživatele, kteří nejsou správci v rámci pracovního prostoru. U takových složek nejvyšší úrovně doporučujeme poskytovat pouze instanční objekty s oprávněními CAN EDIT a CAN MANAGE, abyste zabránili náhodným úpravám produkčního kódu uživateli pracovního prostoru.
Krok 2: Nastavení automatizovaných aktualizací složek Databricks Git pomocí rozhraní API složek Git
Pokud chcete zachovat složku Gitu v Databricks v nejnovější verzi, můžete nastavit automatizaci Gitu tak, aby volala rozhraní API Pro úložiště. Ve vašem poskytovateli Gitu nastavte automatizaci, která po každém úspěšném sloučení žádosti o přijetí změn do hlavní větve volá koncový bod rozhraní API Repos v příslušné složce Gitu, aby se aktualizoval na nejnovější verzi.
Například na GitHubu toho můžete dosáhnout pomocí GitHub Actions. Další informace najdete v rozhraní API úložiště.
Pokud chcete volat jakékoli rozhraní REST API Databricks z buňky poznámkového bloku Databricks, nejprve nainstalujte sadu Databricks SDK s rozhraním %pip install databricks-sdk --upgrade (pro nejnovější rozhraní REST API Databricks) a potom naimportujte ApiClient z databricks.sdk.core.
Poznámka:
Pokud %pip install databricks-sdk --upgrade vrátí chybu, že balíček nebyl nalezen, databricks-sdk balíček nebyl dříve nainstalován. Znovu spusťte příkaz bez příznaku --upgrade : %pip install databricks-sdk.
Můžete také spustit rozhraní API sady Databricks SDK z poznámkového bloku a načíst instanční objekty pro váš pracovní prostor. Tady je příklad použití Pythonu a sady Databricks SDK pro Python.
Můžete také použít nástroje, jako curlje Postman nebo Terraform. Nemůžete použít uživatelské rozhraní Azure Databricks.
Další informace o instančních objektech v Azure Databricks najdete v tématu Správa instančních objektů. Informace o instančních objektech a CI/CD najdete v tématu Instanční objekty ci/CD. Další podrobnosti o používání sady Databricks SDK z poznámkového bloku najdete v tématu Použití sady Databricks SDK pro Python z poznámkového bloku Databricks.
Použití instančního objektu se složkami Git Databricks
Spuštění výše uvedených pracovních postupů s instančními objekty:
- Vytvořte instanční objekt pomocí Azure Databricks.
- Přidejte přihlašovací údaje Gitu: Pro instanční objekt použijte PAT zprostředkovatele Gitu.
Nastavení instančních objektů a přidání přihlašovacích údajů zprostředkovatele Git:
- Vytvořte instanční objekt. Viz Spuštění úloh s instančními objekty.
- Vytvořte token ID Microsoft Entra pro instanční objekt.
- Po vytvoření instančního objektu ho přidáte do pracovního prostoru Azure Databricks pomocí rozhraní API instančních objektů.
- Přidejte přihlašovací údaje zprostředkovatele Git do pracovního prostoru pomocí tokenu MICROSOFT Entra ID a rozhraní API pro přihlašovací údaje Gitu.
Integrace Terraformu
Složky Gitu Databricks můžete spravovat také v plně automatizovaném nastavení pomocí Terraformu a databricks_repo:
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
Pokud chcete k přidání přihlašovacích údajů Gitu do instančního objektu použít Terraform, přidejte následující konfiguraci:
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
Konfigurace automatizovaného kanálu CI/CD se složkami Databricks Git
Tady je jednoduchá automatizace, která se dá spustit jako Akce GitHubu.
Požadavky
- Vytvořili jste složku Gitu v pracovním prostoru Databricks, který sleduje sloučení základní větve.
- Máte balíček Pythonu, který vytvoří artefakty, které se umístí do umístění DBFS. Váš kód musí:
- Aktualizujte úložiště přidružené k upřednostňované větvi (například
development) tak, aby obsahovalo nejnovější verze poznámkových bloků. - Sestavte všechny artefakty a zkopírujte je do cesty knihovny.
- Nahraďte poslední verze artefaktů sestavení, abyste nemuseli ručně aktualizovat verze artefaktů ve vaší úloze.
- Aktualizujte úložiště přidružené k upřednostňované větvi (například
Kroky
Poznámka:
Krok 1 musí provést správce úložiště Git.
Nastavte tajné kódy, aby váš kód mohl přistupovat k pracovnímu prostoru Databricks. Do úložiště GitHub přidejte následující tajné kódy:
- DEPLOYMENT_TARGET_URL: Nastavte ji na adresu URL pracovního prostoru, ale nezahrnujte
/?opodřetětěr. - DEPLOYMENT_TARGET_TOKEN: Zadejte hodnotu tokenu PAT (Personal Access Token) Databricks. Databricks PAT můžete vygenerovat podle pokynů v tématu Konfigurace přihlašovacích údajů Gitu a připojení vzdáleného úložiště k Azure Databricks.
- DEPLOYMENT_TARGET_URL: Nastavte ji na adresu URL pracovního prostoru, ale nezahrnujte
Přejděte na kartu Akce úložiště Git a klikněte na tlačítko Nový pracovní postup . V horní části stránky vyberte Nastavit pracovní postup sami a vložte tento skript:

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest env: DBFS_LIB_PATH: dbfs:/path/to/libraries/ REPO_PATH: /Repos/path/here LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v2 - name: Setup Python uses: actions/setup-python@v2 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 - name: Install mods run: | pip install databricks-cli pip install pytest setuptools wheel - name: Configure CLI run: | echo "${{ secrets.DEPLOYMENT_TARGET_URL }} ${{ secrets.DEPLOYMENT_TARGET_TOKEN }}" | databricks configure --token - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update --path ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks workspace DBFS location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with itAktualizujte následující hodnoty proměnných prostředí vlastními hodnotami:
- DBFS_LIB_PATH: Cesta v DBFS ke knihovnám (kolečka
dbfs:), kterou použijete v této automatizaci, která začíná . Napříkladdbfs:/mnt/myproject/libraries. - REPO_PATH: Cesta v pracovním prostoru Databricks ke složce Git, kde se poznámkové bloky aktualizují. Například
/Repos/Develop. - LATEST_WHEEL_NAME: Název posledního zkompilovaného souboru kola Pythonu (
.whl). Používá se k tomu, aby se zabránilo ruční aktualizaci verzí kol v úlohách Databricks. Napříkladyour_wheel-latest-py3-none-any.whl.
- DBFS_LIB_PATH: Cesta v DBFS ke knihovnám (kolečka
Vyberte Potvrdit změny... a potvrďte skript jako pracovní postup GitHub Actions. Po sloučení žádosti o přijetí změn pro tento pracovní postup přejděte na kartu Akce v úložišti Git a ověřte, že akce jsou úspěšné.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro