Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek podrobně zkoumá načítání rozšířené generace (RAG). Popisujeme práci a aspekty, které jsou potřeba pro vývojáře k vytvoření řešení RAG připraveného pro produkční prostředí.
Další informace o dvou možnostech vytvoření aplikace "chat přes data", což je jeden z nejčastějších případů použití generativní umělé inteligence ve firmách, najdete v tématu Rozšíření LLM pomocí RAG nebo doladění.
Následující diagram znázorňuje kroky nebo fáze RAG:
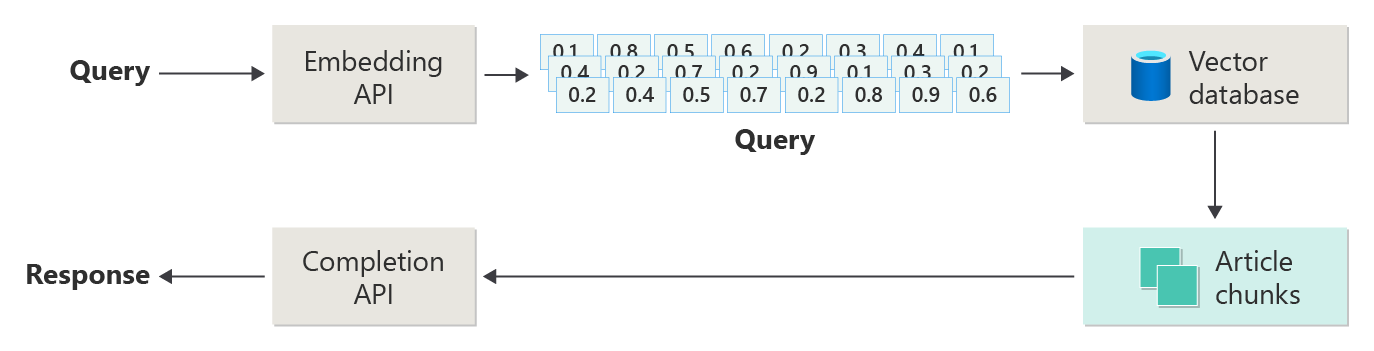
Toto znázornění se jmenuje naïve RAG. Je to užitečný způsob, jak zpočátku porozumět mechanismům, rolím a odpovědnostem potřebným k implementaci systému chatu založeného na RAG.
Implementace z reálného světa má ale mnoho dalších kroků předběžného zpracování a následného zpracování, které připraví články, dotazy a odpovědi pro použití. Následující diagram je realističtějším znázorněním RAG, někdy označovaného jako pokročilý RAG:

Tento článek obsahuje koncepční rámec pro pochopení fází předběžného zpracování a následného zpracování v chatovacím systému založeném na RAG v reálném světě.
- Fáze příjmu dat
- Fáze odvozování procesu
- Fáze vyhodnocení
Příjem dat
Příjem dat je primárně o ukládání dokumentů vaší organizace, aby je bylo možné snadno načíst a odpovědět na otázku uživatele. Výzvou je zajistit, aby se části dokumentů, které nejlépe odpovídají dotazu uživatele, nacházely a používaly při odvozování. Porovnávání se dosahuje především vektorizovanými vkládáními a hledáním kosinusové podobnosti. Porovnávání se ale usnadňuje pochopením povahy obsahu (například vzorů a formulářů) a strategie organizace dat (struktura dat, když jsou uložená v databázi vektorů).
Pro příjem dat musí vývojáři zvážit následující kroky:
- Předběžné zpracování a extrakce obsahu
- Strategie vytváření bloků dat
- Uspořádání bloků dat
- Strategie aktualizace
Předběžné zpracování a extrakce obsahu
Čistý a přesný obsah je jedním z nejlepších způsobů, jak zlepšit celkovou kvalitu chatovacího systému založeného na RAG. Pokud chcete získat čistý, přesný obsah, začněte analýzou tvaru a formy dokumentů, které se mají indexovat. Odpovídají dokumenty zadaným vzorům obsahu, jako je dokumentace? Pokud ne, na jaké typy otázek můžou dokumenty odpovědět?
Minimálně vytvořte kroky v kanálu příjmu dat a proveďte následující kroky:
- Standardizace textových formátů
- Zpracování speciálních znaků
- Odebrání nesouvisejícího, zastaralého obsahu
- Účet pro obsah s verzí
- Účet pro prostředí obsahu (karty, obrázky, tabulky)
- Extrakce metadat
Některé z těchto informací (například metadata) můžou být užitečné, pokud jsou uložené s dokumentem v databázi vektorů, které se mají použít při načítání a vyhodnocování v kanálu odvozování. Lze ji také kombinovat s textovým blokem, aby byla ovlivněna vektorová reprezentace bloku.
Strategie vytváření bloků dat
Jako vývojář se musíte rozhodnout, jak rozdělit větší dokument na menší bloky dat. Dělení do bloků může zlepšit relevanci doplňkového obsahu, který je odesílán do LLM, aby přesně odpověděl na uživatelské dotazy. Také zvažte, jak použít části po jejich načtení. Návrháři systémů by měli zkoumat běžné oborové techniky a provádět nějaké experimentování. Strategii můžete dokonce otestovat v omezené kapacitě ve vaší organizaci.
Vývojáři musí zvážit:
- optimalizace velikosti bloků dat: Určete ideální velikost bloku dat a jak určit blok dat. Podle oddílu? Podle odstavce? Podle věty?
- překrývající se a posuvné bloky oken: Určete, jestli se má obsah rozdělit na samostatné bloky dat, nebo se bloky dat překrývají? Můžete dokonce udělat obojí v návrhu posuvného okna.
- Small2Big: Když je segmentace provedena na podrobné úrovni, například jako jednotlivá věta, je obsah uspořádán tak, aby bylo snadné najít sousední věty nebo odstavec, který větu obsahuje? Načtení těchto informací a jejich poskytnutí do LLM může poskytnout více kontextu pro odpovědi na dotazy uživatelů. Další informace najdete v další části.
Uspořádání bloků dat
V systému RAG je strategicky uspořádaná data v vektorové databázi klíčem k efektivnímu načítání relevantních informací za účelem rozšíření procesu generování. Tady jsou typy strategií indexování a načítání, které byste mohli zvážit:
- hierarchických indexů: Tento přístup zahrnuje vytváření více vrstev indexů. Index nejvyšší úrovně (souhrnný index) rychle zužuje vyhledávací prostor na podmnožinu potenciálně relevantních bloků dat. Index druhé úrovně (index bloků dat) poskytuje podrobnější ukazatele na skutečná data. Tato metoda může výrazně urychlit proces načítání, protože snižuje počet položek pro prohledávání v podrobném indexu tím, že nejprve filtruje prostřednictvím souhrnného indexu.
-
specializované indexy: V závislosti na povaze dat a relacích mezi bloky dat můžete použít specializované indexy, jako jsou grafy nebo relační databáze:
- Indexy založené na grafech jsou užitečné, když bloky obsahují vzájemně propojené informace nebo vztahy, které můžou zlepšit načítání, jako jsou citační sítě nebo grafy znalostí.
- relační databáze mohou být efektivní, pokud jsou bloky dat strukturované v tabulkovém formátu. Pomocí dotazů SQL můžete filtrovat a načítat data na základě konkrétních atributů nebo relací.
- hybridní indexy: Hybridní přístup kombinuje několik metod indexování, aby se jejich silné stránky použily na vaši celkovou strategii. Můžete například použít hierarchický index pro počáteční filtrování a index založený na grafu k dynamickému zkoumání vztahů mezi bloky dat během načítání.
Optimalizace zarovnání
Pokud chcete zvýšit význam a přesnost načtených bloků dat, zarovnejte je úzce s otazníkem nebo typy dotazů, na které odpovídají. Jednou strategií je vygenerovat a vložit hypotetickou otázku pro každý blok dat, který představuje otázku, na kterou je blok dat nejvhodnější. To pomáhá několika způsoby:
- Vylepšené porovnávání: Během načítání může systém porovnat příchozí dotaz s těmito hypotetickými otázkami a najít nejlepší shodu pro zlepšení relevance načtených bloků dat.
- trénovací data pro modely strojového učení: Tyto páry otázek a bloků dat mohou být trénovacími daty, aby se zlepšily modely strojového učení, které jsou základními komponentami systému RAG. Systém RAG zjistí, na jaké typy otázek nejlépe odpovídá každý blok dat.
- zpracování přímých dotazů: Pokud skutečný uživatelský dotaz úzce odpovídá hypotetické otázce, může systém rychle načíst a použít odpovídající blok dat a zrychlit dobu odezvy.
Hypotetická otázka každého bloku funguje jako popisek, který vede algoritmus načítání, takže je více zaměřený a kontextově vědomý. Tento druh optimalizace je užitečný, když bloky dat pokrývají širokou škálu informačních témat nebo typů.
Aktualizace strategií
Pokud vaše organizace indexuje dokumenty, které se často aktualizují, je nezbytné udržovat aktualizovaný korpus, aby komponenta retrieveru získala přístup k nejaktuálnějším informacím. Komponenta retrieveru je logika v systému, která spouští dotaz na vektorovou databázi a vrací výsledky. Tady je několik strategií aktualizace vektorové databáze v těchto typech systémů:
přírůstkové aktualizace:
- Pravidelné intervaly: Naplánujte aktualizace v pravidelných intervalech (například denně nebo týdně), a to v závislosti na frekvenci změn dokumentu. Tato metoda zajišťuje, aby se databáze pravidelně aktualizovala podle známého plánu.
- aktualizace založené na triggerech: Implementujte systém, ve kterém se aktivační události aktualizace přeindexují. Jakékoli úpravy nebo přidání dokumentu například automaticky zahájí přeindexování v ovlivněných oddílech.
částečné aktualizace:
- selektivní přeindexování: Místo přeindexování celé databáze aktualizujte pouze změněné části korpusu. Tento přístup může být efektivnější než úplné přeindexování, zejména u velkých datových sad.
- Rozdílové kódování: Ukládejte pouze rozdíly mezi existujícími dokumenty a jejich aktualizovanými verzemi. Tento přístup snižuje zatížení zpracování dat tím, že se vyhne nutnosti zpracovávat nezměněná data.
verze:
- Vytváření snímků: Udržujte verze korpusu dokumentu v různých bodech v čase. Tato technika poskytuje mechanismus zálohování a umožňuje systému vrátit se k předchozím verzím nebo na tyto verze odkazovat.
- Správa verzí dokumentu: Pomocí systému správy verzí můžete systematicky sledovat změny dokumentu pro udržování historie změn a zjednodušení procesu aktualizace.
aktualizace v reálném čase:
- zpracování streamu: Pokud je časnost informací důležitá, použijte technologie zpracování datových proudů pro aktualizace vektorové databáze v reálném čase při změnách dokumentu.
- živé dotazování: Místo spoléhání výhradně na předindexované vektory použijte pro up-toodpovědi na data živé data, které by mohly být kombinovány živých dat s výsledky uloženými v mezipaměti, aby byly efektivní.
techniky optimalizace :
dávkové zpracování: Dávkové zpracování shromažďuje změny, aby byly méně často aplikovány, což optimalizuje zdroje a snižuje náklady.
hybridní přístupy: Kombinování různých strategií:
- Pro menší změny použijte přírůstkové aktualizace.
- Pro hlavní aktualizace použijte úplné přeindexování.
- Zdokumentujte strukturální změny, které jsou provedeny v korpusu.
Volba správné strategie aktualizace nebo správné kombinace závisí na konkrétních požadavcích, mezi které patří:
- Velikost korpusu dokumentu
- Četnost aktualizací
- Potřeby dat v reálném čase
- Dostupnost prostředků
Vyhodnoťte tyto faktory na základě potřeb konkrétní aplikace. Každý přístup má kompromisy v složitosti, nákladech a latenci aktualizací.
Kanál odvozování
Vaše články jsou rozdělené, vektorizované a uložené ve vektorové databázi. Teď se zaměřte na řešení problémů s dokončením.
Abyste získali co nejpřesnější a nejefektivnější dokončení, musíte počítat s mnoha faktory:
- Je dotaz uživatele napsán způsobem, jak získat výsledky, které uživatel hledá?
- Porušuje dotaz uživatele některou ze zásad organizace?
- Jak přepíšete dotaz uživatele, aby se zlepšila pravděpodobnost nalezení nejbližších shod v vektorové databázi?
- Jak vyhodnotíte výsledky dotazu, abyste zajistili, že bloky článků odpovídají dotazu?
- Jak vyhodnotíte a upravíte výsledky dotazu, než je předáte do LLM, aby se zajistilo, že do dokončení budou zahrnuty nejdůležitější podrobnosti?
- Jak vyhodnotíte odpověď LLM, abyste zajistili, že dokončení LLM odpovídá původnímu dotazu uživatele?
- Jak zajistíte, aby odpověď LLM odpovídala zásadám organizace?
Celý kanál odvozování běží v reálném čase. Neexistuje žádný správný způsob návrhu předzpracování a kroků po zpracování. Pravděpodobně zvolíte kombinaci programovací logiky a dalších volání LLM. Jedním z nejdůležitějších aspektů je kompromis mezi vytvořením nejpřesnějšího a vyhovujícího kanálu a náklady a latencí, které je potřeba k tomu, aby k tomu došlo.
Pojďme identifikovat konkrétní strategie v každé fázi kanálu odvozování.
Kroky předběžného zpracování dotazů
Předběžné zpracování dotazu proběhne okamžitě po odeslání dotazu uživatelem:

Cílem těchto kroků je zajistit, aby uživatel kladl otázky, jež jsou v souladu se záběrem vašeho systému, a připravit dotaz uživatele tak, aby se zvýšila pravděpodobnost, že vyhledá nejlepší možné části článků pomocí kosinové podobnosti nebo metody "nejbližšího souseda".
kontrola zásad: Tento krok zahrnuje logiku, která identifikuje, odebere, označí nebo odmítne určitý obsah. Mezi příklady patří odebrání osobních údajů, odebrání nadávek a identifikace pokusů o jailbreak. Odemčení odkazuje na pokusy uživatelů o obcházení nebo manipulaci s vnitřními bezpečnostními, etickými nebo provozními pravidly modelu.
přepisování dotazů: Tento krok může být cokoli od rozšíření zkratek a odebrání slangu a přepsání otázky, aby byla položena abstraktněji k extrahování konceptů a principů vysoké úrovně (vyzývání ke kroku zpět).
Varianta výzvy krok zpět je hypotetické vkládání dokumentů (HyDE). HyDE použije velký jazykový model (LLM) k zodpovězení otázky uživatele, vytvoří pro tuto odpověď vnoření (hypotetické vnoření dokumentu) a poté použije toto vnoření pro spuštění vyhledávání na vektorové databázi.
Poddotazy
Krok zpracování poddotazů je založený na původním dotazu. Pokud je původní dotaz dlouhý a složitý, může být užitečné ho programově rozdělit na několik menších dotazů a pak zkombinovat všechny odpovědi.
Například otázka týkající se vědeckých objevů ve fyzikě může být: "Kdo učinil významné příspěvky do moderní fyziky, Alberta Einsteina nebo Niels Bohru?"
Rozdělení složitých dotazů na poddotazy umožňuje jejich správu:
- Poddotaz 1: "Jaké jsou klíčové příspěvky Alberta Einsteina na moderní fyziku?"
- Poddotaz 2: "Jaké jsou klíčové příspěvky Niels Bohr do moderní fyziky?"
Výsledky těchto poddotazů podrobně uvádějí hlavní teorie a objevy každého fyzika. Příklad:
- Příspěvky Alberta Einsteina mohou zahrnovat teorii relativity, fotoelektrický efekt a E=mc^2.
- Příspěvky Bohr mohou zahrnovat Bohrův model atomu vodíku, Bohrův přínos ke kvantové mechanice a Bohrovy princip doplňkovosti.
Pokud jsou tyto příspěvky popsány, je možné je posoudit, aby bylo možné určit více poddotazů. Příklad:
- Poddotaz 3: "Jak ovlivnila teorie Einsteina vývoj moderní fyziky?"
- Poddotaz 4: "Jak bohrovská teorie ovlivnila vývoj moderní fyziky?"
Tyto poddotazy prozkoumávají vliv jednotlivých vědců na fyziku, například:
- Jak teorie Einsteina vedly k pokroku v kosmologii a kvantové teorii
- Jak bohrova práce přispěla k pochopení atomické struktury a kvantové mechaniky
Kombinace výsledků těchto poddotazů může pomoci jazykovému modelu vytvořit komplexnější odpověď na to, kdo výrazněji přispěl k moderní fyzikě na základě jejich teoretického pokroku. Tato metoda zjednodušuje původní složitý dotaz tím, že přistupuje ke konkrétnějším, srozumitelnějším komponentám a potom tato zjištění syntetizuje do koherentní odpovědi.
Směrovač dotazů
Vaše organizace se může rozhodnout rozdělit obsah do více vektorových úložišť nebo do celých systémů načítání. V tomto scénáři můžete použít směrovač dotazů. Směrovač dotazů vybere nejvhodnější databázi nebo index, aby poskytoval nejlepší odpovědi na konkrétní dotaz.
Směrovač dotazů obvykle funguje v okamžiku, kdy uživatel formuluje dotaz, ale před odesláním dotazu do systémů načítání.
Tady je zjednodušený pracovní postup pro směrovač dotazů:
- analýza dotazů: LLM nebo jiná komponenta analyzuje příchozí dotaz, aby porozuměl jeho obsahu, kontextu a typu informací, které jsou pravděpodobně potřeba.
- výběr indexu: Na základě analýzy směrovač dotazů vybere jeden nebo více indexů z potenciálně několika dostupných indexů. Každý index může být optimalizovaný pro různé typy dat nebo dotazů. Některé indexy můžou být například vhodnější pro faktické dotazy. Jiné indexy mohou vynikat v poskytování názorů nebo subjektivního obsahu.
- odeslání dotazu: Dotaz se odešle do vybraného indexu.
- agregace výsledků: Odpovědi z vybraných indexů se načtou a případně agregují nebo dále zpracovávají, aby vytvořily komplexní odpověď.
- generování odpovědí: Posledním krokem je vytvoření koherentní odpovědi na základě načtených informací, pravděpodobně integrace nebo syntetizace obsahu z více zdrojů.
Vaše organizace může pro následující případy použití použít více modulů pro načítání nebo indexů:
- specializace datových typů: Některé indexy se můžou specializovat na články o novinkách, jiné v akademických dokumentech a další v obecném webovém obsahu nebo konkrétních databázích, jako jsou lékařské nebo právní informace.
- optimalizace typu dotazu: Některé indexy můžou být optimalizované pro rychlé faktické vyhledávání (například data nebo události). Jiné můžou být vhodnější použít pro složité úlohy zdůvodnění nebo pro dotazy, které vyžadují hluboké znalosti domény.
- Algoritmické rozdíly: Různé vyhledávací algoritmy se mohou používat v různých strojích, jako jsou vektorové vyhledávání podobnosti, tradiční vyhledávání založená na klíčových slovech nebo pokročilejší modely porozumění semantice.
Představte si systém založený na RAG, který se používá v kontextu lékařského poradenství. Systém má přístup k více indexům:
- Index lékařského výzkumu optimalizovaný pro podrobné a technické vysvětlení
- Index klinické případové studie, který poskytuje příklady příznaků a léčby z reálného světa
- Obecný index informací o stavu pro základní dotazy a informace o veřejném stavu
Pokud se uživatel zeptá technické otázky týkající se biochemických účinků nového léku, může směrovač dotazů určit prioritu indexu lékařského výzkumného papíru kvůli jeho hloubkové a technické zaměření. Pro otázku o typických příznaky běžné nemoci, nicméně obecný zdravotní index může být zvolen pro jeho široký a snadno pochopitelný obsah.
Kroky následného zpracování
Zpracování po načtení probíhá poté, co komponenta retrieveru stáhne relevantní bloky obsahu z vektorové databáze:

Když se načtou bloky obsahu kandidáta, dalším krokem je ověření užitečného bloku článků při rozšíření výzvy LLM před přípravou výzvy k zobrazení výzvy llm.
Tady je několik aspektů podnětu, které je potřeba vzít v úvahu:
- Zahrnutí příliš mnoho doplňujících informací může vést k ignorování nejdůležitějších informací.
- Zahrnutí irelevantních informací může negativně ovlivnit odpověď.
Dalším aspektem je jehla v problému s haystackem, termín, který odkazuje na známou vlnu některých LLM, ve kterých obsah na začátku a na konci výzvy mají větší váhu pro LLM než obsah uprostřed.
Nakonec zvažte maximální délku kontextového okna LLM a počet tokenů potřebných k dokončení mimořádně dlouhých výzev (zejména pro dotazy ve velkém měřítku).
Při řešení těchto problémů může kanál následného načítání zahrnovat následující kroky:
- filtrování výsledků: V tomto kroku se ujistěte, že bloky článků, které vrací vektorová databáze, jsou pro dotaz relevantní. Pokud nejsou, výsledek se při vytváření výzvy LLM ignoruje.
- Přeuspořádání: Seřaďte bloky článků načtené z úložiště vektorů, aby byly relevantní podrobnosti umístěny blízko hran (začátku a konce) výchozího textu.
- komprese výzvy: Před odesláním výzvy do LLM použijte levný malý model ke komprimaci a shrnutí několika bloků článků do jediné komprimované výzvy.
Kroky zpracování po dokončení
Zpracování po dokončení probíhá po zadání dotazu uživatele a všechny bloky obsahu se odešlou do LLM:

Ověření přesnosti probíhá po dokončení úkolu modelu LLM. Kanál zpracování po dokončení může zahrnovat následující kroky:
- kontrola faktů: Záměrem je identifikovat specifická tvrzení provedená v článku, která jsou prezentována jako fakta, a pak tyto skutečnosti zkontrolovat pro zajištění přesnosti. Pokud se krok kontroly faktů nezdaří, může být vhodné znovu položit dotaz LLM v naději, že obdržíte lepší odpověď, či vrátit uživateli chybovou zprávu.
- kontrola zásad: Poslední obranná linie, která zajistí, že odpovědi neobsahují škodlivý obsah, ať už pro uživatele nebo pro organizaci.
Hodnocení
Vyhodnocení výsledků nedeterministického systému není tak jednoduché jako spouštění testů jednotek nebo integračních testů, které většina vývojářů zná. Je potřeba vzít v úvahu několik faktorů:
- Jsou uživatelé spokojení s výsledky, které dostává?
- Získávají uživatelé přesné odpovědi na své otázky?
- Jak zaznamenáte zpětnou vazbu uživatelů? Existují nějaké zásady, které omezují, jaká data můžete shromažďovat o uživatelských datech?
- Pokud chcete diagnostikovat neuspokojivé odpovědi, máte přehled o veškeré práci, která byla vykonána při odpovídání na otázku? Uchováváte protokol každé fáze v kanálu odvozování vstupů a výstupů, abyste mohli provádět analýzu původní příčiny?
- Jak můžete v systému provádět změny bez regrese nebo snížení výsledků?
Zachycení zpětné vazby uživatelů a jejich reakce
Jak bylo popsáno výše, možná budete muset spolupracovat s týmem vaší organizace na ochranu osobních údajů a navrhnout mechanismy zachycení zpětné vazby, telemetrie a protokolování pro forenzní analýzu a analýzu příčiny relace dotazu.
Dalším krokem je vývoj kanálu posouzení. Kanál hodnocení pomáhá se složitostí a časově náročným charakterem analýzy doslovné zpětné vazby a původních příčin odpovědí poskytovaných systémem AI. Tato analýza je zásadní, protože zahrnuje zkoumání každé odpovědi, abyste pochopili, jak dotaz AI vytvořil výsledky, a kontroluje vhodnost bloků obsahu, které se používají z dokumentace, a strategie použité při dělení těchto dokumentů.
Zahrnuje také zvážení jakéhokoli dalšího předběžného zpracování nebo kroků po zpracování, které by mohly zvýšit výsledky. Toto podrobné zkoumání často odhalí mezery v obsahu, zejména pokud neexistuje vhodná dokumentace pro odpověď na dotaz uživatele.
Vytvoření kanálu posouzení je nezbytné ke efektivní správě škálování těchto úloh. Efektivní kanál používá vlastní nástroje k vyhodnocení metrik, které odpovídají kvalitě odpovědí poskytovaných AI. Tento systém zjednodušuje proces určení, proč byla konkrétní odpověď udělena na otázku uživatele, které dokumenty byly použity k vygenerování této odpovědi, a efektivitu kanálu odvozování, který zpracovává dotazy.
Zlatá datová sada
Jednou ze strategií pro vyhodnocení výsledků nedeterministického systému, jako je chatovací systém RAG, je použití zlaté datové sady. zlatá datová sada je kurátorovaná sada otázek a schválených odpovědí, metadat (jako je téma a typ otázky), odkazy na zdrojové dokumenty, které můžou sloužit jako základní pravda pro odpovědi a dokonce i varianty (různé formulace umožňující zachytit rozmanitost toho, jak se uživatelé mohou ptát na stejné otázky).
Zlatá datová sada představuje "nejlepší scénář případu". Vývojáři můžou systém vyhodnotit, aby viděli, jak dobře funguje, a poté provést regresní testy při implementaci nových funkcí nebo aktualizací.
Posouzení škod
Modelování škod je metodologie zaměřená na předvídání potenciálních škod, zjišťování nedostatků v produktu, které mohou představovat rizika jednotlivcům, a vývoj proaktivních strategií pro zmírnění těchto rizik.
Nástroj navržený pro posouzení dopadu technologií, zejména systémů AI, by na základě principů modelování škod, jak je popsáno v poskytnutých prostředcích, by poskytoval několik klíčových komponent.
Mezi klíčové funkce nástroje pro vyhodnocení škod může patřit:
identifikace účastníků: Nástroj může uživatelům pomoct identifikovat a kategorizovat různé zúčastněné strany, které jsou touto technologií ovlivněny, včetně přímých uživatelů, nepřímo ovlivněných stran a dalších subjektů, jako jsou budoucí generace nebo nelidské faktory, jako jsou otázky životního prostředí.
kategorie škod a popisy: Nástroj může obsahovat úplný seznam potenciálních škod, jako je ztráta soukromí, emocionální tíseň nebo ekonomické zneužití. Nástroj může uživatele vést různými scénáři, ilustrovat, jak může technologie způsobit tyto škody, a pomoct vyhodnotit zamýšlené i nezamýšlené důsledky.
posouzení závažnosti a pravděpodobnosti: Nástroj může uživatelům pomoct vyhodnotit závažnost a pravděpodobnost každé zjištěné škody. Uživatel může určit prioritu problémů, které se mají vyřešit jako první. Mezi příklady patří kvalitativní posouzení podporovaná daty, pokud jsou k dispozici.
strategie zmírnění rizik: Nástroj může po identifikaci a vyhodnocení škod navrhnout potenciální strategie zmírnění rizik. Mezi příklady patří změny návrhu systému, přidání ochranných opatření a alternativních technologických řešení, která minimalizují zjištěná rizika.
mechanismy zpětné vazby: Nástroj by měl zahrnovat mechanismy pro shromažďování zpětné vazby od zúčastněných stran, aby proces vyhodnocování škod byl dynamický a reagoval na nové informace a perspektivy.
Dokumentace a vytváření sestav: Pro transparentnost a odpovědnost může nástroj usnadnit podrobné zprávy, které dokumentují proces hodnocení škod, výsledky a potenciální opatření ke zmírnění rizik.
Tyto funkce vám můžou pomoct identifikovat a zmírnit rizika, ale také vám pomůžou navrhnout etického a zodpovědného systému AI tím, že zváží široké spektrum dopadů od začátku.
Další informace najdete v těchto článcích:
Testování a ověření bezpečnostních opatření
Tento článek popisuje několik procesů, které jsou zaměřeny na zmírnění možnosti zneužití nebo ohrožení chatovacího systému založeného na rag. Red teaming hraje zásadní roli při zajištění účinnosti zmírnění. Red-teaming zahrnuje simulaci akcí potenciálního protivníka k odhalení potenciálních slabých míst nebo zranitelností v aplikaci. Tento přístup je zvláště důležitý při řešení významného rizika jailbreaku.
Vývojáři musí pečlivě posoudit ochranu chatovacího systému založeného na rag v různých obecných scénářích, aby je mohli efektivně testovat a ověřovat. Tento přístup nejen zajišťuje odolnost, ale také pomáhá vyladit reakce systému na přísné dodržování definovaných etických norem a provozních postupů.
Konečné aspekty návrhu aplikace
Tady je krátký seznam věcí, které je potřeba vzít v úvahu, a další poznatky z tohoto článku, které můžou mít vliv na rozhodnutí o návrhu vaší aplikace:
- Potvrďte nedeterministický charakter generující umělé inteligence ve vašem návrhu. Naplánujte proměnlivost výstupů a nastavte mechanismy pro zajištění konzistence a relevance odpovědí.
- Vyhodnoťte výhody předzpracování výzvy uživatelů proti potenciálnímu zvýšení latence a nákladů. Zjednodušení nebo úprava výzev před odesláním může zlepšit kvalitu odpovědi, ale může to zvýšit složitost a dobu odezvy.
- Pokud chcete zvýšit výkon, prozkoumejte strategie paralelizace požadavků LLM. Tento přístup může snížit latenci, ale vyžaduje pečlivou správu, aby se zabránilo zvýšené složitosti a potenciálním nákladům.
Pokud chcete začít experimentovat s vytvářením řešení generující umělé inteligence okamžitě, doporučujeme se podívat na Začít chatovat pomocí vlastní ukázky dat pro Python. Tento kurz je také k dispozici pro .NET, Javaa JavaScript.