Použití zobrazení Ambari Hive Apache s Apache Hadoopem v HDInsight
Naučte se spouštět dotazy Hive pomocí zobrazení Apache Ambari Hive. Zobrazení Hive umožňuje vytvářet, optimalizovat a spouštět dotazy Hivu z webového prohlížeče.
Požadavky
Cluster Hadoop ve službě HDInsight. Viz Začínáme se službou HDInsight v Linuxu.
Spuštění dotazu Hive
Na webu Azure Portal vyberte váš cluster. Pokyny najdete v části Seznam a zobrazení clusterů . Cluster se otevře v novém zobrazení portálu.
Na řídicích panelech clusteru vyberte zobrazení Ambari. Po zobrazení výzvy k ověření použijte název a heslo účtu pro přihlášení ke clusteru (výchozí
admin), které jste zadali při vytváření clusteru. Můžete také přejít dohttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsprohlížeče, kdeCLUSTERNAMEje název clusteru.V seznamu zobrazení vyberte Zobrazení Hive.
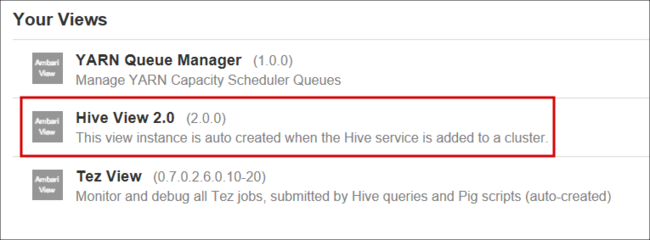
Stránka zobrazení Hive se podobá následujícímu obrázku:
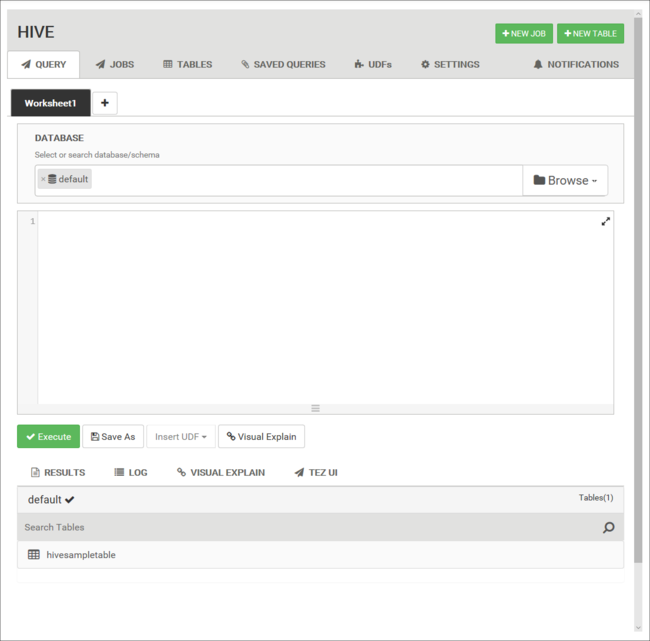
Na kartě Dotaz vložte do listu následující příkazy HiveQL:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Tyto příkazy provádějí následující akce:
Příkaz Popis DROP TABLE Odstraní tabulku a datový soubor pro případ, že tabulka již existuje. VYTVOŘENÍ EXTERNÍ TABULKY Vytvoří novou "externí" tabulku v Hive. Externí tabulky ukládají pouze definici tabulky v Hivu. Data zůstanou v původním umístění. FORMÁT ŘÁDKU Ukazuje, jak jsou data formátovaná. V tomto případě jsou pole v každém protokolu oddělena mezerou. ULOŽENÉ JAKO UMÍSTĚNÍ TEXTOVÉHO SOUBORU Ukazuje, kde jsou data uložená a že jsou uložená jako text. VÝBĚR Vybere počet všech řádků, ve kterých sloupec t4 obsahuje hodnotu [ERROR]. Důležité
Ve výchozím nastavení ponechte výběr databáze. Příklady v tomto dokumentu používají výchozí databázi, která je součástí SLUŽBY HDInsight.
Pokud chcete spustit dotaz, vyberte Spustit pod listem. Tlačítko se změní na oranžovou a text se změní na Zastavit.
Po dokončení dotazu se na kartě Výsledky zobrazí výsledky operace. Výsledkem dotazu je následující text:
loglevel count [ERROR] 3Pomocí karty LOG můžete zobrazit informace o protokolování, které úloha vytvořila.
Tip
Stáhněte nebo uložte výsledky z rozevíracího seznamu Akce pod kartou Výsledky .
Vizuální vysvětlení
Pokud chcete zobrazit vizualizaci plánu dotazu, vyberte kartu Vizuální vysvětlení pod listem.
Zobrazení vizuálního vysvětlení dotazu může být užitečné při pochopení toku složitých dotazů.
Uživatelské rozhraní Tez
Pokud chcete zobrazit uživatelské rozhraní Tez pro dotaz, vyberte kartu uživatelského rozhraní Tez pod listem.
Důležité
Tez se nepoužívá k překladu všech dotazů. Mnoho dotazů můžete vyřešit bez použití Tez.
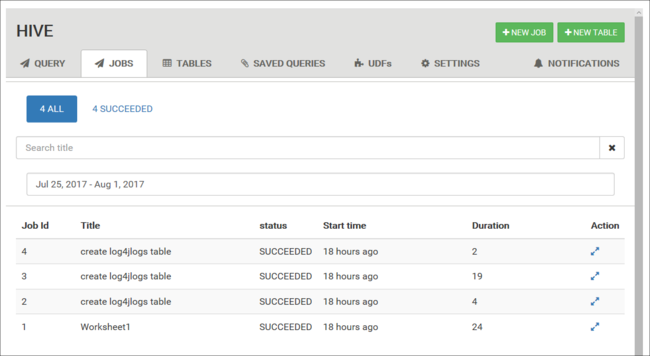
Zobrazení historie úlohy
Na kartě Úlohy se zobrazí historie dotazů Hive.
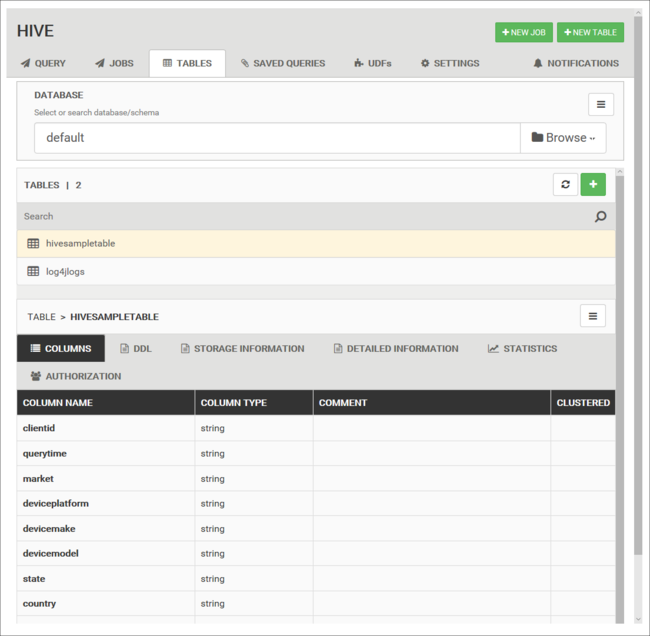
Databázové tabulky
Pomocí karty Tabulky můžete pracovat s tabulkami v databázi Hive.
Uložené dotazy
Na kartě Dotaz můžete volitelně ukládat dotazy. Po uložení dotazu ho můžete znovu použít na kartě Uložené dotazy .
Tip
Uložené dotazy se ukládají do výchozího úložiště clusteru. Uložené dotazy najdete v cestě /user/<username>/hive/scripts. Tyto soubory se ukládají jako soubory ve formátu prostého textu .hql .
Pokud cluster odstraníte, ale zachováte úložiště, můžete k načtení dotazů použít nástroj, jako je Průzkumník služby Azure Storage nebo Data Lake Průzkumník služby Storage (z webu Azure Portal).
Uživatelem definované funkce
Hive můžete rozšířit prostřednictvím uživatelem definovaných funkcí (UDF). Pomocí funkce definované uživatelem můžete implementovat funkce nebo logiku, která není snadno modelována v HiveQL.
Deklarujte a uložte sadu funkcí definované uživatelem pomocí karty UDF v horní části zobrazení Hive. Tyto funkce definované uživatelem je možné použít s Editor Power Query.
V dolní části Editor Power Query se zobrazí tlačítko Vložit udfs. Tato položka zobrazí rozevírací seznam uživatelem definovaných v zobrazení Hive. Když vyberete UDF, přidá se do dotazu příkazy HiveQL, aby bylo možné funkci definovanou uživatelem povolit.
Pokud jste například definovali UDF s následujícími vlastnostmi:
Název prostředku: myudfs
Cesta k prostředku: /myudfs.jar
Název UDF: myawesomeudf
Název třídy UDF: com.myudfs.Awesome
Pomocí tlačítka Vložit udfs zobrazíte položku s názvem myudfs s dalším rozevíracím seznamem pro každý UDF definovaný pro daný prostředek. V tomto případě je to myawesomeudf. Výběrem této položky přidáte na začátek dotazu následující položky:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Pak můžete v dotazu použít funkci definovanou uživatelem. Například SELECT myawesomeudf(name) FROM people;.
Další informace o používání UDF s Hivem ve službě HDInsight najdete v následujících článcích:
- Použití Pythonu s Apache Hivem a Apache Pigem ve službě HDInsight
- Použití UDF v Javě s Apache Hivem ve službě HDInsight
Nastavení Hivu
Můžete změnit různá nastavení Hivu, například změnit prováděcí modul pro Hive z Tez (výchozí) na MapReduce.
Další kroky
Obecné informace o Hivu ve službě HDInsight: