Architektury provozní kontinuity ve službě Azure HDInsight
Tento článek obsahuje několik příkladů architektur kontinuity podnikových procesů, které můžete zvážit pro Azure HDInsight. Tolerance pro omezenou funkčnost během havárie je obchodní rozhodnutí, které se liší od jedné aplikace po další. Může být přijatelné, aby některé aplikace byly nedostupné nebo částečně dostupné s omezenou funkčností nebo zpožděným zpracováním po určité období. U jiných aplikací by všechny omezené funkce mohly být nepřijatelné.
Poznámka:
Architektury uvedené v tomto článku nejsou nijak vyčerpávající. Jakmile vytvoříte objektivní rozhodnutí ohledně očekávané kontinuity podnikových procesů, provozní složitosti a nákladů na vlastnictví, měli byste navrhnout vlastní jedinečné architektury.
Apache Hive a Interaktivní dotaz
Replikace Hive V2 se doporučuje pro provozní kontinuitu v clusterech HDInsight Hive a Interaktivní dotazy. Trvalé části samostatného clusteru Hive, který je potřeba replikovat, jsou vrstva úložiště a metastore Hive. Clustery Hive ve scénáři s více uživateli s balíčkem zabezpečení podniku potřebují službu Microsoft Entra Domain Services a Metastore Ranger.
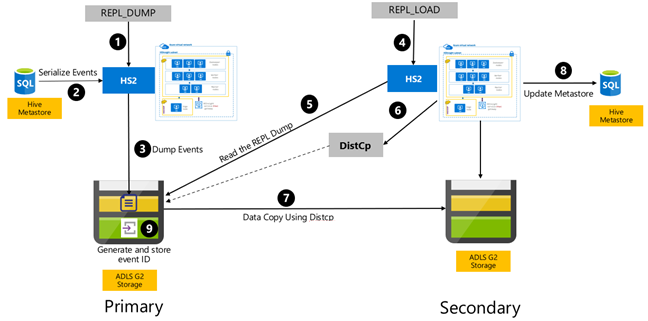
Replikace založená na událostech Hive se konfiguruje mezi primárním a sekundárním clusterem. Skládá se ze dvou různých fází, spouštění a přírůstkových spuštění:
Spuštění replikuje celý sklad Hive, včetně informací metastoru Hive z primárního do sekundárního.
Přírůstková spuštění jsou v primárním clusteru automatizovaná a události vygenerované během přírůstkových spuštění se přehrávají v sekundárním clusteru. Sekundární cluster zachytí události vygenerované z primárního clusteru a zajistí, aby sekundární cluster byl konzistentní s událostmi primárního clusteru po spuštění replikace.
Sekundární cluster je potřeba pouze v době replikace ke spuštění distribuované kopie, DistCpale úložiště a metastory musí být trvalé. Před replikací můžete spustit skriptovaný sekundární cluster na vyžádání, spustit na něm skript replikace a potom ho po úspěšné replikaci vypnout.
Sekundární cluster je obvykle jen pro čtení. Sekundární cluster můžete provést pro čtení i zápis, ale tím se zvyšuje složitost, která zahrnuje replikaci změn ze sekundárního clusteru do primárního clusteru.
RPO a RTO replikace na základě událostí Hive
RPO: Ztráta dat je omezená na poslední úspěšnou událost přírůstkové replikace z primární na sekundární.
RTO: Doba mezi selháním a obnovením upstreamových a podřízených transakcí se sekundární.
Architektury Apache Hive a Interactive Query
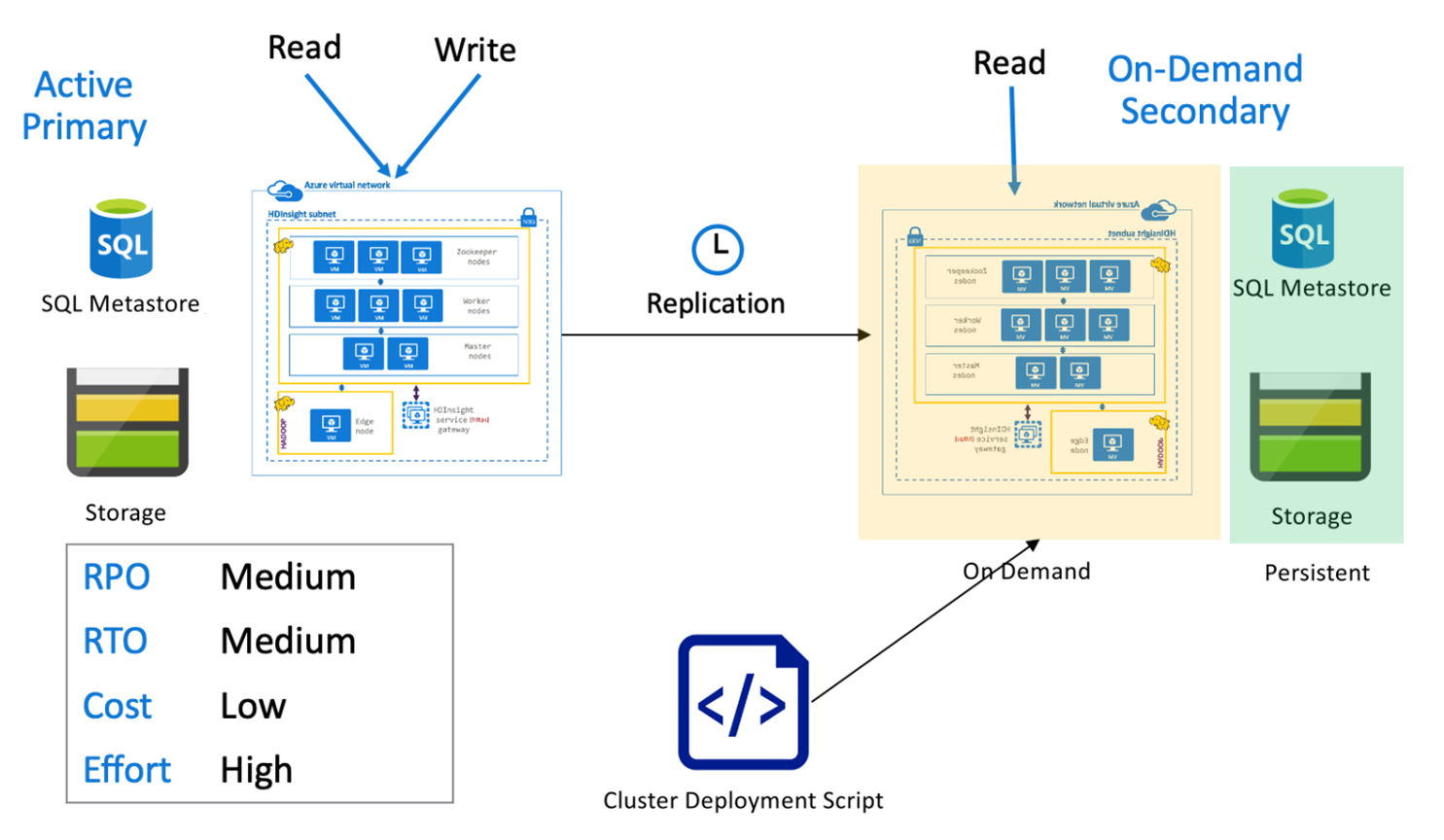
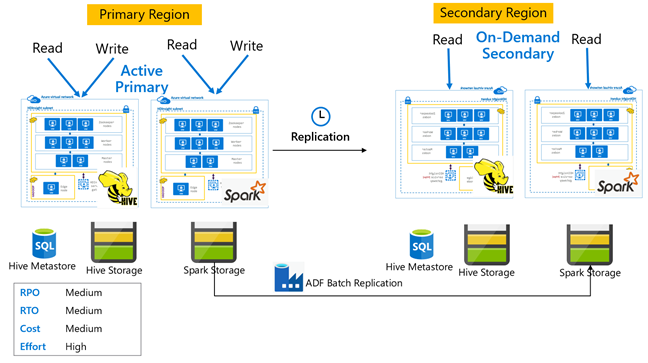
Hive – aktivní primární s sekundárním serverem na vyžádání
V aktivní primární s sekundární architekturou na vyžádání zapisují aplikace do aktivní primární oblasti, zatímco během normálních operací se v sekundární oblasti nezřídí žádný cluster. Metastor SQL a úložiště v sekundární oblasti jsou trvalé, zatímco cluster HDInsight je skriptovaný a nasazený na vyžádání pouze před plánovaným spuštěním replikace Hive.
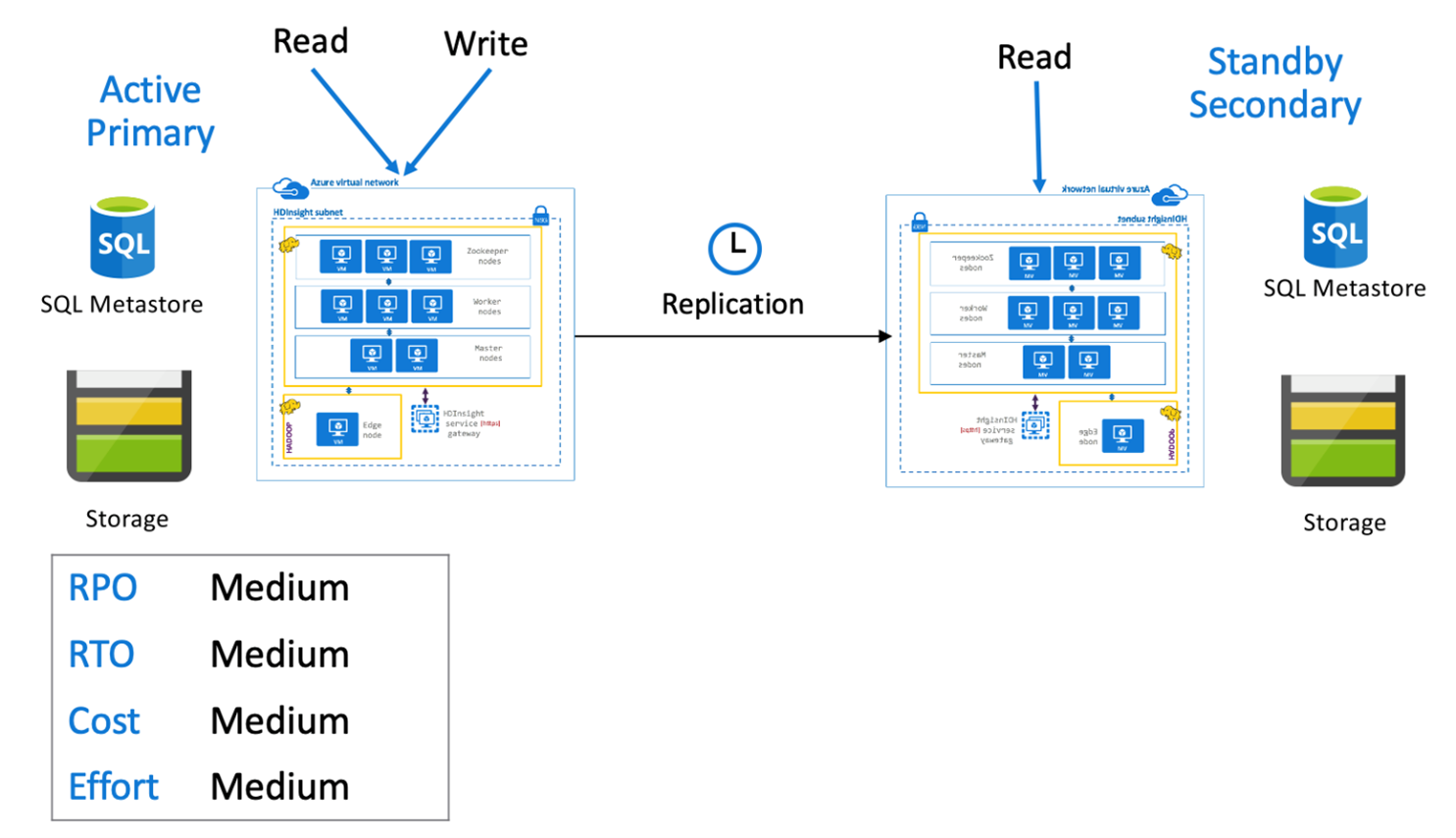
Hive aktivní primární s pohotovostním sekundárním režimem
V aktivní primární s pohotovostním sekundárním režimem aplikace zapisuje do aktivní primární oblasti, zatímco pohotovostní cluster v režimu jen pro čtení běží během normálních operací. Během normálních operací můžete zvolit přesměrování zpracování operací čtení specifických pro danou oblast na sekundární.
Další informace o replikaci Hivu a ukázkách kódu najdete v replikaci Apache Hivu v clusterech Azure HDInsight.
Apache Spark
Úlohy Sparku můžou nebo nemusí zahrnovat komponentu Hive. Pokud chcete úlohám Spark SQL povolit čtení a zápis dat z Hivu, clustery HDInsight Spark sdílejí vlastní metastory Hive z clusterů Hive nebo Interaktivní dotazy ve stejné oblasti. V takových scénářích musí replikace úloh Sparku napříč oblastmi také doprovázet replikaci metastorů Hive a úložiště. Scénáře převzetí služeb při selhání v této části platí pro obě:
- Spark SQL v tabulkách ACID pomocí nastavení hive Warehouse Připojení or(HWC) pomocí clusteru HDInsight Interactive Query.
- Úloha Spark SQL v tabulkách bez acid pomocí clusteru HDInsight Hadoop
V situacích, kdy Spark funguje v samostatném režimu, musí být kurátorovaná data a uložené soubory Jar Sparku (pro úlohy Livy) replikovány z primární oblasti do sekundární oblasti pravidelně pomocí služby Azure Data Factory DistCP.
Doporučujeme používat systémy správy verzí k ukládání poznámkových bloků a knihoven Sparku, kde je můžete snadno nasadit na primární nebo sekundární clustery. Ujistěte se, že jsou řešení založená na poznámkových blocích a jiných než poznámkových blocích připravená k načtení správných připojení dat v primárním nebo sekundárním pracovním prostoru.
Pokud existují knihovny specifické pro zákazníky, které jsou nad rámec toho, co HDInsight poskytuje nativně, musí být sledovány a pravidelně načteny do pohotovostního sekundárního clusteru.
RPO a RTO replikace Apache Sparku
RPO: Ztráta dat je omezená na poslední úspěšnou přírůstkovou replikaci (Spark a Hive) z primární do sekundární.
RTO: Doba mezi selháním a obnovením upstreamových a podřízených transakcí se sekundární.
Architektury Apache Sparku
Aktivní primární Spark se sekundárním serverem na vyžádání
Aplikace čtou a zapisují do clusterů Spark a Hive v primární oblasti, zatímco během normálních operací se v sekundární oblasti nezřídí žádné clustery. Metastore SQL, Úložiště Hive a Spark Storage jsou trvalé v sekundární oblasti. Clustery Spark a Hive se skriptují a nasazují na vyžádání. Replikace Hive se používá k replikaci metastorů Hive Storage a Hive, zatímco službu Azure Data Factory DistCP je možné použít ke kopírování samostatného úložiště Spark. Clustery Hive je potřeba nasadit před každým spuštěním replikace Hive kvůli výpočetním prostředkům závislostí DistCp .
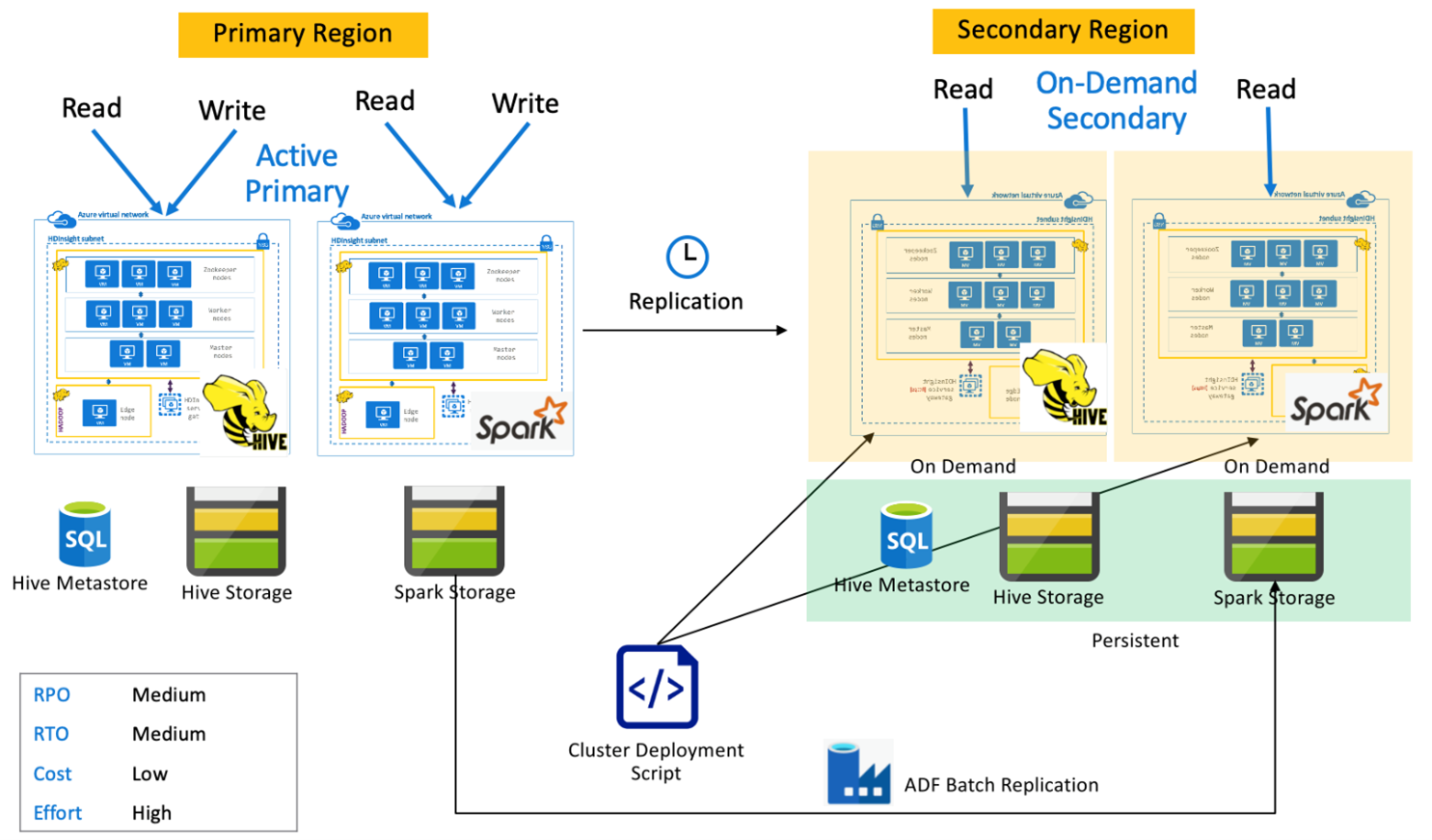
Aktivní primární Spark se sekundárním pohotovostním režimem
Aplikace čtou a zapisují do clusterů Spark a Hive v primární oblasti, zatímco pohotovostní clustery Hive a Spark v režimu jen pro čtení běží v sekundární oblasti během normálních operací. Během normálních operací můžete zvolit přesměrování zpracování operací čtení v konkrétní oblasti Hive a Sparku do sekundární.
Apache HBase
Export HBase a replikace HBase jsou běžnými způsoby povolení provozní kontinuity mezi clustery HDInsight HBase.
Export HBase je proces dávkové replikace, který používá nástroj HBase Export k exportu tabulek z primárního clusteru HBase do základního úložiště Azure Data Lake Storage Gen2. Exportovaná data je pak možné získat přístup ze sekundárního clusteru HBase a importovat je do tabulek, které musí existovat v sekundárním prostředí. I když export HBase nabízí členitost na úrovni tabulky, v situacích přírůstkové aktualizace řídí modul automatizace exportu rozsah přírůstkových řádků, které se mají zahrnout do každého spuštění. Další informace naleznete v tématu HDInsight HBase Zálohování a replikace.
Replikace HBase využívá replikaci téměř v reálném čase mezi clustery HBase plně automatizovaným způsobem. Replikace se provádí na úrovni tabulky. Všechny tabulky nebo konkrétní tabulky je možné cílit na replikaci. Replikace HBase je nakonec konzistentní, což znamená, že nedávné úpravy tabulky v primární oblasti nemusí být dostupné pro všechny sekundáře okamžitě. Sekundární je zaručeno, že se nakonec stanou konzistentní s primárním serverem. Replikaci HBase je možné nastavit mezi dvěma nebo více clustery HDInsight HBase, pokud:
- Primární a sekundární jsou ve stejné virtuální síti.
- Primární a sekundární jsou v různých partnerských virtuálních sítích ve stejné oblasti.
- Primární a sekundární jsou v různých partnerských virtuálních sítích v různých oblastech.
Další informace najdete v tématu Nastavení replikace clusteru Apache HBase ve virtuálních sítích Azure.
Existuje několik dalších způsobů zálohování clusterů HBase, jako je kopírování složky hbase, kopírování tabulek a snímků.
RPO & RTO HBase
HBase Export
- RPO: Ztráta dat je omezena na poslední úspěšný přírůstkový import sekundárním z primárního serveru.
- RTO: Doba mezi selháním primární a obnovením vstupně-výstupních operací na sekundárním serveru.
Replikace HBase
- RPO: Ztráta dat je omezená na poslední zásilku WalEdit přijatou v sekundární.
- RTO: Doba mezi selháním primární a obnovením vstupně-výstupních operací na sekundárním serveru.
Architektury HBase
Replikaci HBase je možné nastavit ve třech režimech: Leader-Follower, Leader-Leader a Cyklické.
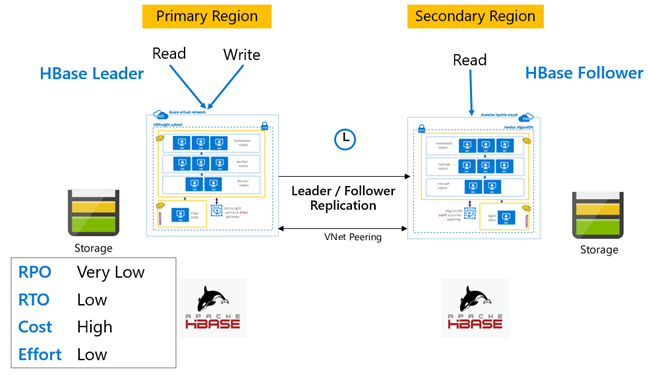
Replikace HBase: Leader – model sledujících
V tomto nastavení mezi oblastmi je replikace jednosměrná z primární oblasti do sekundární oblasti. Pro jednosměrnou replikaci je možné identifikovat všechny tabulky nebo konkrétní tabulky na primárním serveru. Během normálních operací lze sekundární cluster použít k obsluhě žádostí o čtení ve své vlastní oblasti.
Sekundární cluster funguje jako normální cluster HBase, který může hostovat vlastní tabulky a může obsluhovat čtení a zápisy z regionálních aplikací. Zápisy do replikovaných tabulek nebo tabulek, které jsou nativní pro sekundární, se ale nereplikují zpět na primární.
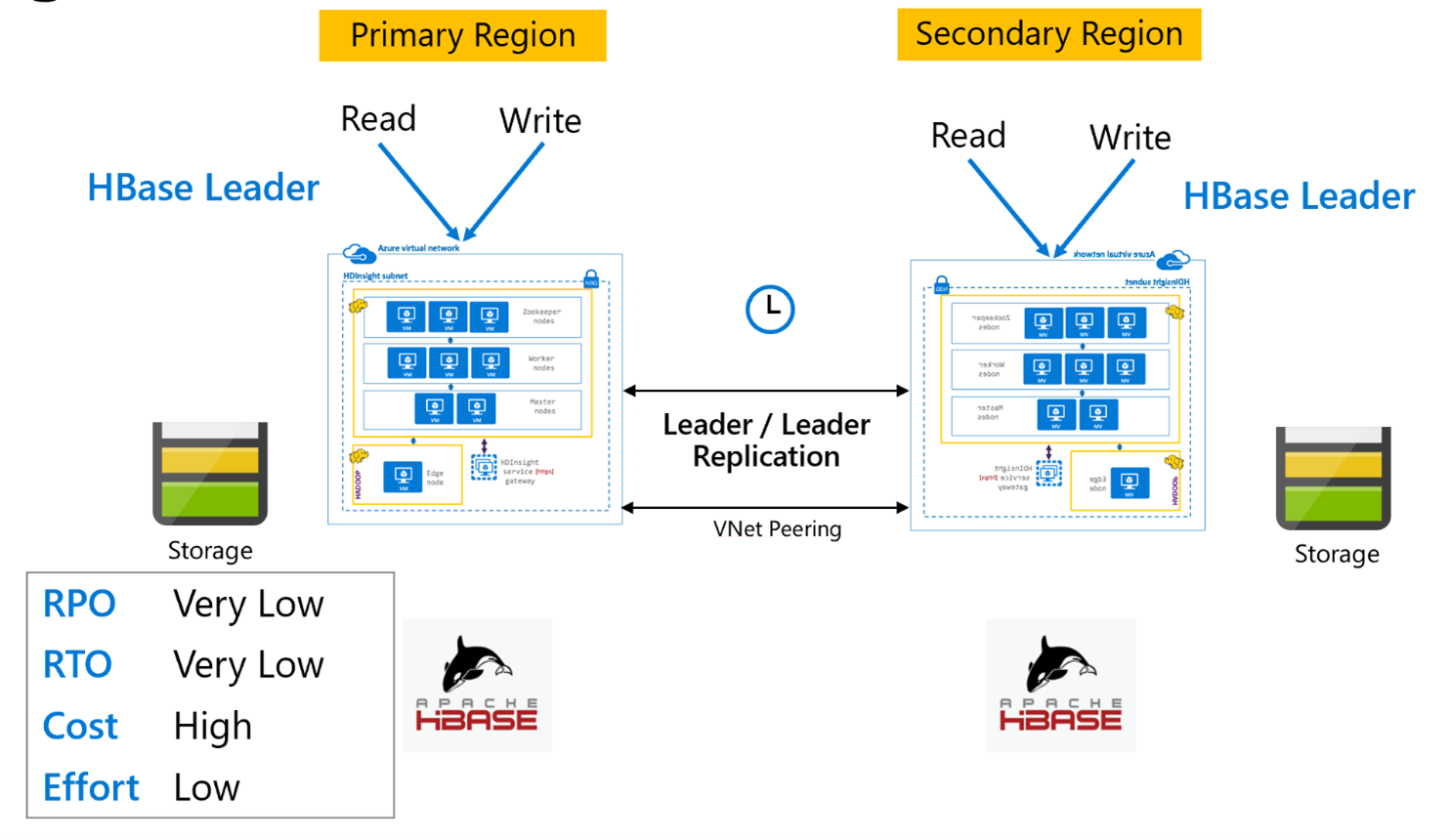
Replikace HBase: Leader – model Leader
Nastavení mezi oblastmi je velmi podobné jednosměrné nastavení s tím rozdílem, že replikace probíhá obousměrně mezi primární oblastí a sekundární oblastí. Aplikace můžou používat clustery v režimech čtení i zápisu a aktualizace asynchronně mezi nimi.
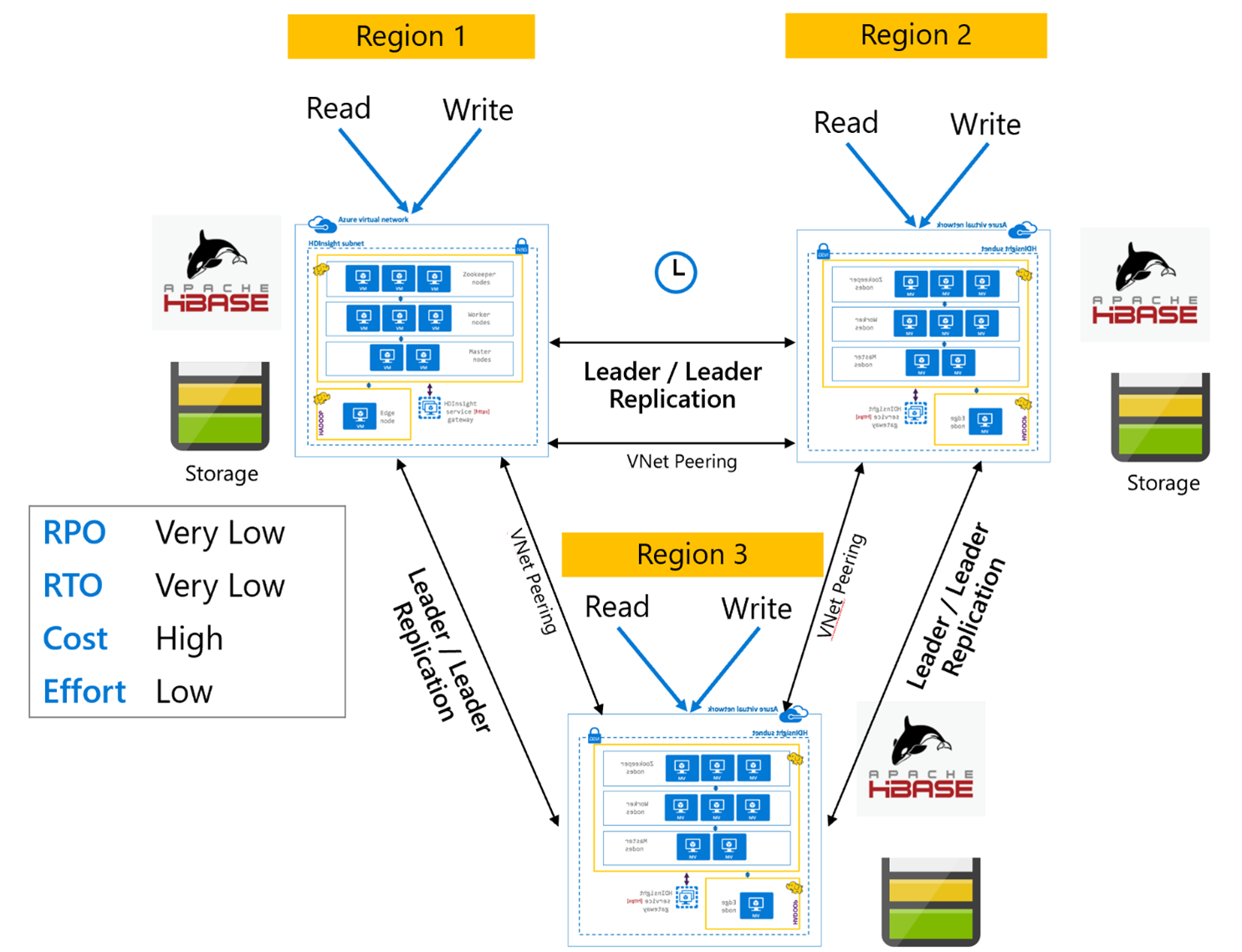
Replikace HBase: Více oblastí nebo cyklická
Model replikace více oblastí nebo cyklických replikací je rozšíření replikace HBase a lze ho použít k vytvoření globálně redundantní architektury HBase s více aplikacemi, které čtou a zapisují do clusterů HBase pro konkrétní oblast. V závislosti na obchodních požadavcích je možné clustery nastavit v různých kombinacích vodicích faktorů Leader/Leader/Follower.
Apache Kafka
Pokud chcete povolit dostupnost mezi oblastmi, HDInsight 4.0 podporuje Kafka MirrorMaker, který se dá použít k údržbě sekundární repliky primárního clusteru Kafka v jiné oblasti. MirrorMaker funguje jako pár producenta na vysoké úrovni, využívá z konkrétního tématu v primárním clusteru a vytváří téma se stejným názvem v sekundárním clusteru. Replikace mezi clustery pro zotavení po havárii s vysokou dostupností pomocí MirrorMakeru se předpokládá, že producenti a spotřebitelé potřebují převzít služby při selhání clusteru repliky. Další informace najdete v tématu Použití MirrorMakeru k replikaci témat Apache Kafka se systémem Kafka ve službě HDInsight.
V závislosti na době života tématu při spuštění replikace může replikace tématu MirrorMaker vést k různým posunům mezi tématy zdroje a repliky. Clustery HDInsight Kafka také podporují replikaci oddílů tématu, což je funkce vysoké dostupnosti na úrovni jednotlivých clusterů.
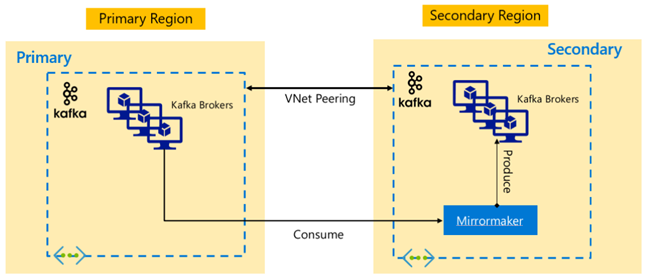
Architektury Apache Kafka
Replikace Kafka: Aktivní – pasivní
Nastavení aktivní-pasivní umožňuje asynchronní jednosměrné zrcadlení z aktivní na pasivní. Producenti a spotřebitelé musí vědět o existenci aktivního a pasivního clusteru a musí být připraveni převzít služby při selhání pasivním v případě selhání aktivního clusteru. Níže jsou uvedeny některé výhody a nevýhody nastavení aktivní-pasivní.
Výhody:
- Latence sítě mezi clustery nemá vliv na výkon aktivního clusteru.
- Jednoduchost jednosměrné replikace
Nevýhody:
- Pasivní cluster může zůstat nevyužitý.
- Složitost návrhu začlenění povědomí o převzetí služeb při selhání v producentech aplikací a spotřebitelích
- Možné ztráty dat během selhání aktivního clusteru
- Konečná konzistence mezi tématy mezi aktivními a pasivními clustery
- Navrácení služeb po obnovení na primární může vést k nekonzistence zpráv v tématech.
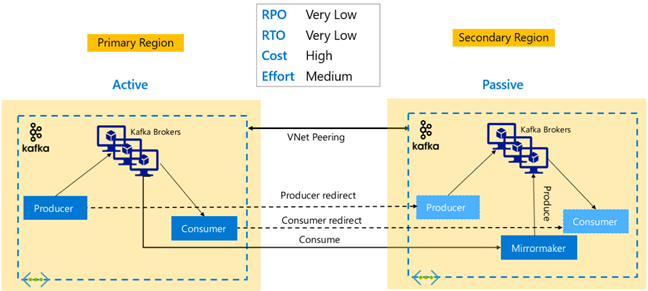
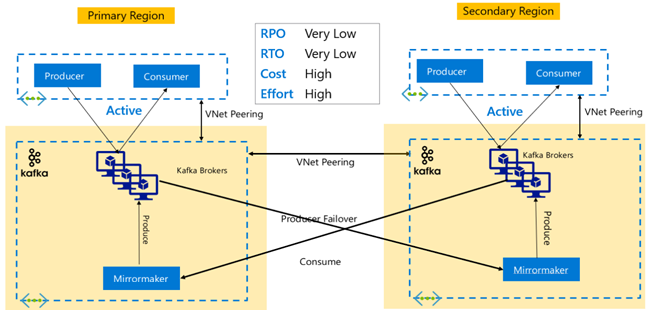
Replikace Kafka: Aktivní – aktivní
Nastavení Active-Active zahrnuje dva regionálně oddělené clustery HDInsight Kafka v partnerském vztahu virtuálních sítí s obousměrnou asynchronní replikací pomocí MirrorMakeru. V tomto návrhu jsou zprávy spotřebované spotřebiteli v primárním prostředí zpřístupněny také příjemcům v sekundární a naopak. Níže jsou uvedeny některé výhody a nevýhody nastavení aktivní-aktivní.
Výhody:
- Kvůli jejich duplicitnímu stavu je jednodušší provést převzetí služeb při selhání a navrácení služeb po obnovení.
Nevýhody:
- Nastavení, správa a monitorování jsou složitější než aktivní-pasivní.
- Problém cyklických replikací je potřeba vyřešit.
- Obousměrná replikace vede k vyšším nákladům na výchozí přenos dat v jednotlivých oblastech.
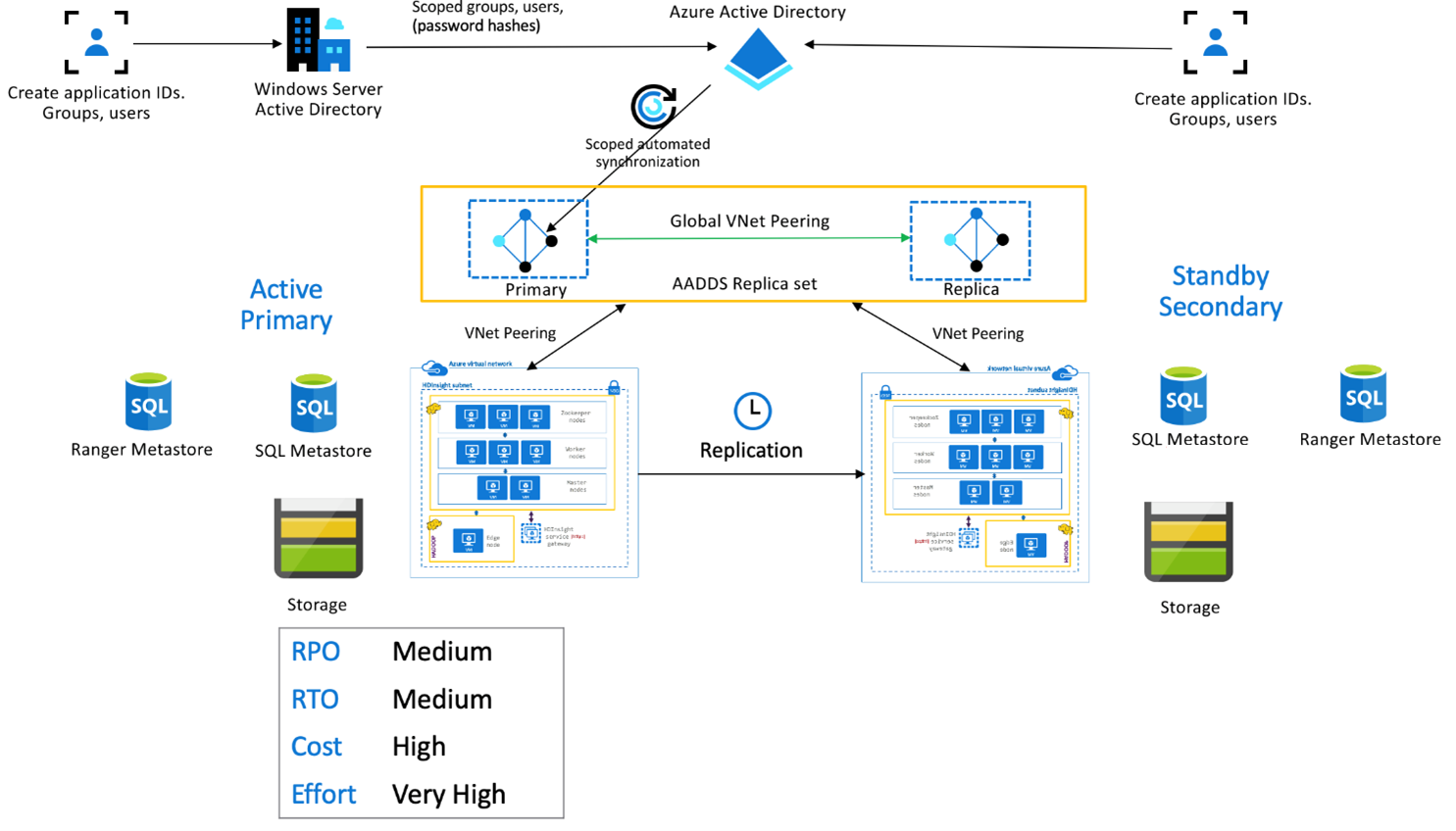
Balíček zabezpečení služby HDInsight Enterprise
Tato sada se používá k povolení víceuživatelské funkce v primární i sekundární, stejně jako sady replik služby Microsoft Entra Domain Services, aby se uživatelé mohli ověřit v obou clusterech. Během normálních operací je potřeba nastavit zásady Ranger v sekundárním systému, aby se zajistilo, že uživatelé budou omezeni na operace čtení. Následující architektura vysvětluje, jak může vypadat nastavení esp s podporou Hive Active Primary – Standby Secondary.
Replikace metastoru Ranger:
Metastor Ranger se používá k trvalému ukládání a obsluhování zásad Rangeru pro řízení autorizace dat. Doporučujeme udržovat nezávislé zásady Ranger v primární a sekundární a sekundární a sekundární jako repliku pro čtení.
Pokud je potřeba zachovat zásady Rangeru synchronizované mezi primárním a sekundárním serverem, použijte k pravidelnému zálohování a importu zásad Rangeru z primárního do sekundárního rozsahu.
Replikace zásad Rangeru mezi primárním a sekundárním serverem může způsobit, že sekundární se povolí zápis, což může vést k neúmyslným zápisům na sekundární straně, což vede k nekonzistenci dat.
Další kroky
Další informace o položkách probíraných v tomto článku najdete tady: