Jak používat replikaci Apache Hivu v clusterech Azure HDInsight
V kontextu databází a skladů je replikace proces duplikování entit z jednoho skladu do druhého. Duplikace se může vztahovat na celou databázi nebo na menší úroveň, jako je tabulka nebo oddíl. Cílem je mít repliku, která se změní při každé změně základní entity. Replikace na Apache Hive se zaměřuje na zotavení po havárii a nabízí jednosměrnou replikaci primární kopie. V clusterech HDInsight je možné replikaci Hive použít k jednosměrné replikaci metastoru Hive a přidruženého podkladového datového jezera v Azure Data Lake Storage Gen2.
Replikace Hive se v průběhu let vyvinula s novějšími verzemi, které poskytují lepší funkce a jsou rychlejší a méně náročné na prostředky. V tomto článku probereme replikaci Hive (Replv2), která je podporována v clusterech HDInsight 3.6 i HDInsight 4.0.
Výhody replv2
Hive ReplicationV2 (označované také jako Replv2) má následující výhody oproti první verzi replikace Hive, která používala Hive IMPORT-EXPORT:
- Přírůstková replikace založená na událostech
- Replikace k určitému bodu v čase
- Snížené požadavky na šířku pásma
- Snížení počtu zprostředkujících kopií
- Stav replikace se udržuje.
- Omezená replikace
- Podpora hvězdicového modelu
- Podpora tabulek ACID (v HDInsight 4.0)
Fáze replikace
Replikace založená na událostech Hive se konfiguruje mezi primárním a sekundárním clusterem. Tato replikace se skládá ze dvou různých fází: spouštění a přírůstkových spuštění.
Bootstrapping
Bootstrapping je určen ke spuštění jednou pro replikaci základního stavu databází z primární do sekundární. V případě potřeby můžete nakonfigurovat spouštění tak, aby zahrnovalo podmnožinu tabulek v cílové databázi, kde je potřeba povolit replikaci.
Přírůstková spuštění
Po spuštění se přírůstková spuštění automatizují v primárním clusteru a události vygenerované během těchto přírůstkových spuštění se přehrají v sekundárním clusteru. Když sekundární cluster zachytí primární cluster, sekundární se stane konzistentní s událostmi primárního clusteru.
Příkazy replikace
Hive nabízí sadu příkazů REPL – DUMP, LOADa STATUS - pro orchestraci toku událostí. Příkaz DUMP vygeneruje místní protokol všech událostí DDL/DML v primárním clusteru. Příkaz LOAD je přístup k lazily kopírování metadat a dat zaprotokolovaných do výstupu výpisu extrahované replikace a provádí se v cílovém clusteru. Příkaz STATUS se spustí z cílového clusteru a poskytne nejnovější ID události, které se úspěšně replikovalo s nejnovějším zatížením replikace.
Nastavení zdroje replikace
Než začnete s replikací, ujistěte se, že je databáze, která se má replikovat, nastavená jako zdroj replikace. Pomocí příkazu můžete DESC DATABASE EXTENDED <db_name> určit, jestli je parametr repl.source.for nastavený s názvem zásady.
Pokud je zásada naplánovaná a repl.source.for parametr není nastavený, musíte nejprve tento parametr nastavit pomocí ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Výpis metadat do datového jezera
Příkaz REPL DUMP [database name]. => location / event_id se používá ve fázi bootstrap k výpisu relevantních metadat do Azure Data Lake Storage Gen2. Určuje event_id minimální událost, do které byla v Azure Data Lake Storage Gen2 vložena příslušná metadata.
repl dump tpcds_orc;
Příklad výstupu:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeeed4c5dd0 | 2925 |
Načtení dat do cílového clusteru
Příkaz REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } slouží k načtení dat do cílového clusteru pro spouštěcí i přírůstkové fáze replikace. Může [database name] být stejný jako zdroj nebo jiný název v cílovém clusteru. Představuje [location] umístění z výstupu předchozího REPL DUMP příkazu. To znamená, že cílový cluster by měl být schopný komunikovat se zdrojovým clusterem. Klauzule WITH byla primárně přidána, aby se zabránilo restartování cílového clusteru, což umožňuje replikaci.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Výstup posledního replikovaného ID události
Příkaz REPL STATUS [database name] se spustí v cílových clusterech a výstupy poslední replikované event_id. Příkaz také umožňuje uživatelům zjistit, do jakého stavu se cílový cluster replikuje. Výstupem tohoto příkazu můžete vytvořit další REPL DUMP příkaz pro přírůstkovou replikaci.
repl status tpcds_orc;
Příklad výstupu:
| last_repl_id |
|---|
| 2925 |
Výpis relevantních dat a metadat do datového jezera
Příkaz REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } slouží k výpisu relevantních metadat a dat do Azure Data Lake Storage. Tento příkaz se používá v přírůstkové fázi a spouští se ve zdrojovém skladu. Vyžaduje FROM [event-id] se pro přírůstkovou fázi a hodnotu event-id lze odvodit spuštěním REPL STATUS [database name] příkazu v cílovém skladu.
repl dump tpcds_orc from 2925;
Příklad výstupu:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
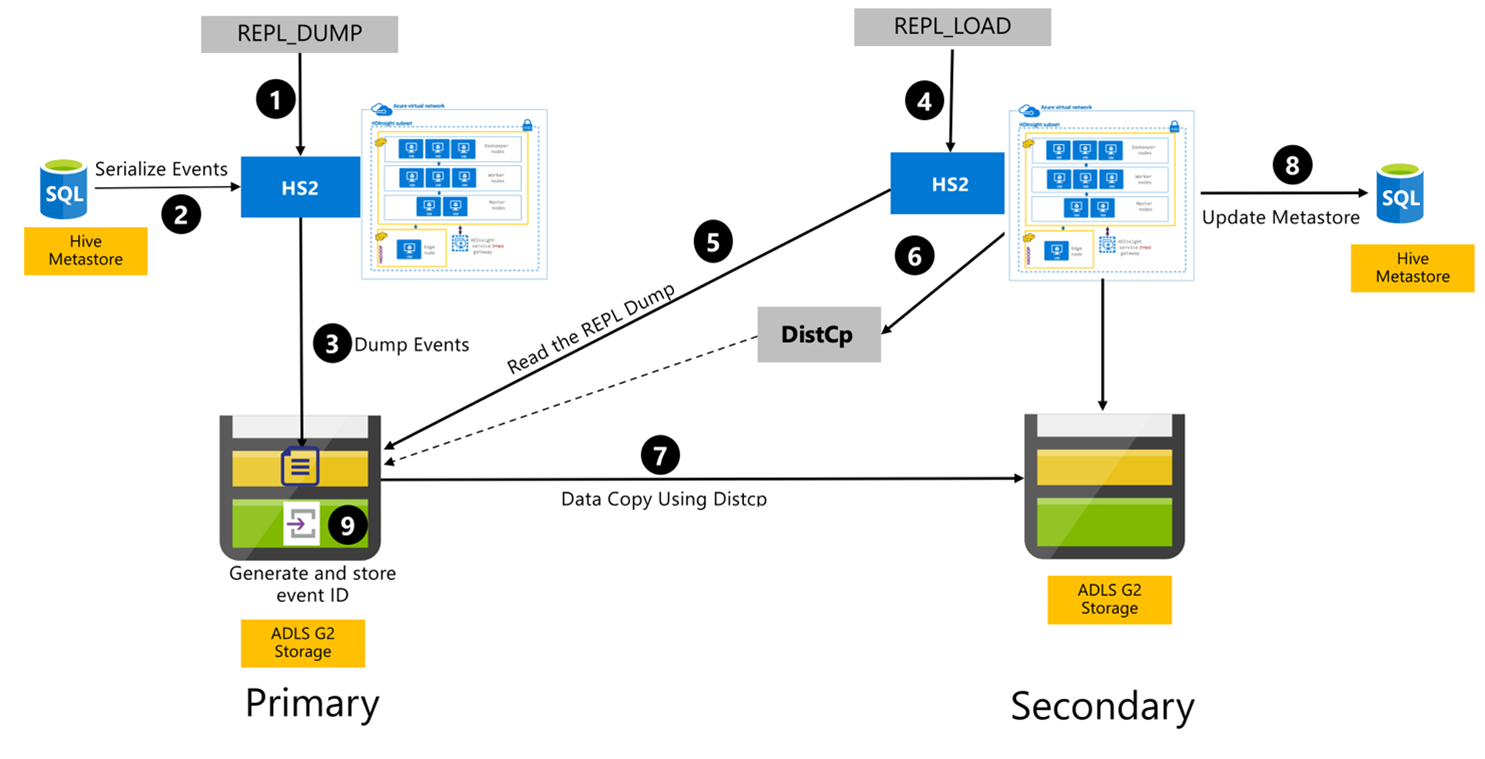
Proces replikace Hive
Následující kroky jsou postupné události, které probíhají během procesu replikace Hive.
Ujistěte se, že jsou tabulky, které se mají replikovat, nastavené jako zdroj replikace pro určitou zásadu.
Příkaz
REPL_DUMPse vydá primárnímu clusteru s přidruženými omezeními, jako je název databáze, rozsah ID události a adresa URL úložiště Azure Data Lake Storage Gen2.Systém serializuje výpis všech sledovaných událostí z metastoru na nejnovější. Tento výpis paměti je uložený v účtu úložiště Azure Data Lake Storage Gen2 v primárním clusteru na adrese URL, kterou určuje
REPL_DUMP.Primární cluster zachovává metadata replikace do úložiště Azure Data Lake Storage Gen2 primárního clusteru. Cesta je konfigurovatelná v uživatelském rozhraní konfigurace Hive v Ambari. Tento proces poskytuje cestu, kde jsou metadata uložena, a ID nejnovější sledované události DML/DDL.
Příkaz
REPL_LOADse vydává ze sekundárního clusteru. Příkaz odkazuje na cestu nakonfigurovanou v kroku 3.Sekundární cluster přečte soubor metadat se sledovanými událostmi vytvořenými v kroku 3. Ujistěte se, že sekundární cluster má síťové připojení k úložišti Azure Data Lake Storage Gen2 primárního clusteru, ze
REPL_DUMPkterého se ukládají sledované události.Sekundární cluster vytváří distribuované výpočetní prostředky kopírování (
DistCP).Sekundární cluster kopíruje data z úložiště primárního clusteru.
Metastor v sekundárním clusteru se aktualizuje.
Id poslední sledované události je uloženo v primárním metastoru.
Přírůstková replikace se řídí stejným procesem a jako vstup vyžaduje poslední replikované ID události. To vede k přírůstkové kopii od poslední události replikace. Přírůstkové replikace se obvykle automatizují s předem určenou frekvencí pro dosažení požadovaných cílů bodu obnovení (RPO).
Vzory replikace
Replikace se obvykle konfiguruje jednosměrně mezi primárním a sekundárním serverem, kde primární zajišťuje požadavky na čtení a zápis. Sekundární cluster zajišťuje pouze požadavky na čtení. Zápisy jsou povoleny na sekundárním serveru, pokud dojde k havárii, ale zpětnou replikaci je potřeba nakonfigurovat zpět na primární server.
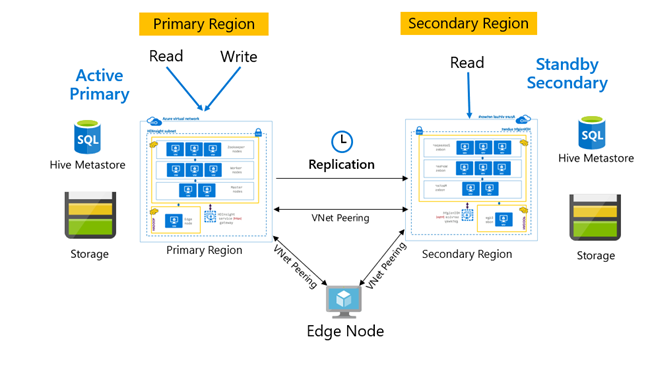
Existuje mnoho vzorů vhodných pro replikaci Hive, včetně primární – sekundární, hvězdicové a přenosové služby.
V hdInsight Active Primary – Standby Secondary je běžný model provozní kontinuity a zotavení po havárii (BCDR) a HiveReplicationV2 může tento model používat s regionálně oddělenými clustery HDInsight Hadoop s partnerskými vztahy virtuálních sítí. K hostování skriptů pro automatizaci replikace je možné použít společný partnerský vztah virtuálního počítače s oběma clustery. Další informace o možnýchvzorch
Replikace Hivu s balíčkem zabezpečení podniku
V případech, kdy je replikace Hive plánovaná na clusterech HDInsight Hadoop s balíčkem zabezpečení podniku, musíte u metastoru Ranger a služby Microsoft Entra Domain Services zahrnout do mechanismů replikace.
Pomocí funkce sady replik služby Microsoft Entra Domain Services vytvořte více než jednu sadu replik služby Microsoft Entra Domain Services na tenanta Microsoft Entra napříč více oblastmi. Každá jednotlivá sada replik musí být v příslušných oblastech v partnerském vztahu s virtuálními sítěmi HDInsight. V této konfiguraci se změny služby Microsoft Entra Domain Services, včetně konfigurace, identity uživatele a přihlašovacích údajů, skupin, objektů zásad skupiny, objektů počítačů a dalších změn, použijí na všechny sady replik ve spravované doméně pomocí replikace služby Microsoft Entra Domain Services.
Zásady Rangeru je možné pravidelně zálohovat a replikovat z primární do sekundární pomocí funkce Import-Export rangeru. V závislosti na úrovni autorizací, které chcete implementovat v sekundárním clusteru, můžete replikovat všechny zásady Rangeru nebo podmnožinu zásad Rangeru.
Ukázkový kód
Následující posloupnost kódu poskytuje příklad, jak je možné implementovat bootstrapping a přírůstkovou replikaci do ukázkové tabulky s názvem tpcds_orc.
Nastavte tabulku jako zdroj pro zásady replikace.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Výpis paměti bootstrap v primárním clusteru
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Příklad výstupu:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Zatížení bootstrap v sekundárním clusteru.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';REPLZkontrolujte stav v sekundárním clusteru.repl status tpcds_orc;last_repl_id 2925 Přírůstkový výpis paměti v primárním clusteru
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Příklad výstupu:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Přírůstkové zatížení v sekundárním clusteru
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Zkontrolujte
REPLstav v sekundárním clusteru.repl status tpcds_orc;last_repl_id 2960
Další kroky
Další informace o položkách probíraných v tomto článku najdete tady:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro