Ruční škálování clusterů Azure HDInsight
HDInsight poskytuje elasticitu s možnostmi vertikálního navýšení a snížení kapacity počtu pracovních uzlů v clusterech. Tato elasticita umožňuje zmenšit cluster po hodinách nebo o víkendech. A rozšiřte ho během špiček obchodních požadavků.
Vertikálně navyšte kapacitu clusteru před pravidelným dávkovém zpracováním, aby cluster získal odpovídající prostředky. Po dokončení zpracování a snížení využití můžete vertikálně snížit kapacitu clusteru HDInsight na méně pracovních uzlů.
Cluster můžete škálovat ručně pomocí jedné z následujících metod. Možnosti automatického škálování můžete také použít k automatickému vertikálnímu navýšení a snížení kapacity v reakci na určité metriky.
Poznámka:
Podporují se pouze clustery s HDInsight verze 3.1.3 nebo vyšší. Pokud si nejste jisti verzí clusteru, můžete zkontrolovat stránku Vlastnosti.
Nástroje pro škálování clusterů
Microsoft poskytuje následující nástroje pro škálování clusterů:
| Nástroj | Popis |
|---|---|
| Az PowerShellu | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Azure CLI | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Azure Classic CLI | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure Portal | Otevřete podokno clusteru HDInsight, v nabídce vlevo vyberte Velikost clusteru, pak v podokně Velikost clusteru zadejte počet pracovních uzlů a vyberte Uložit. |
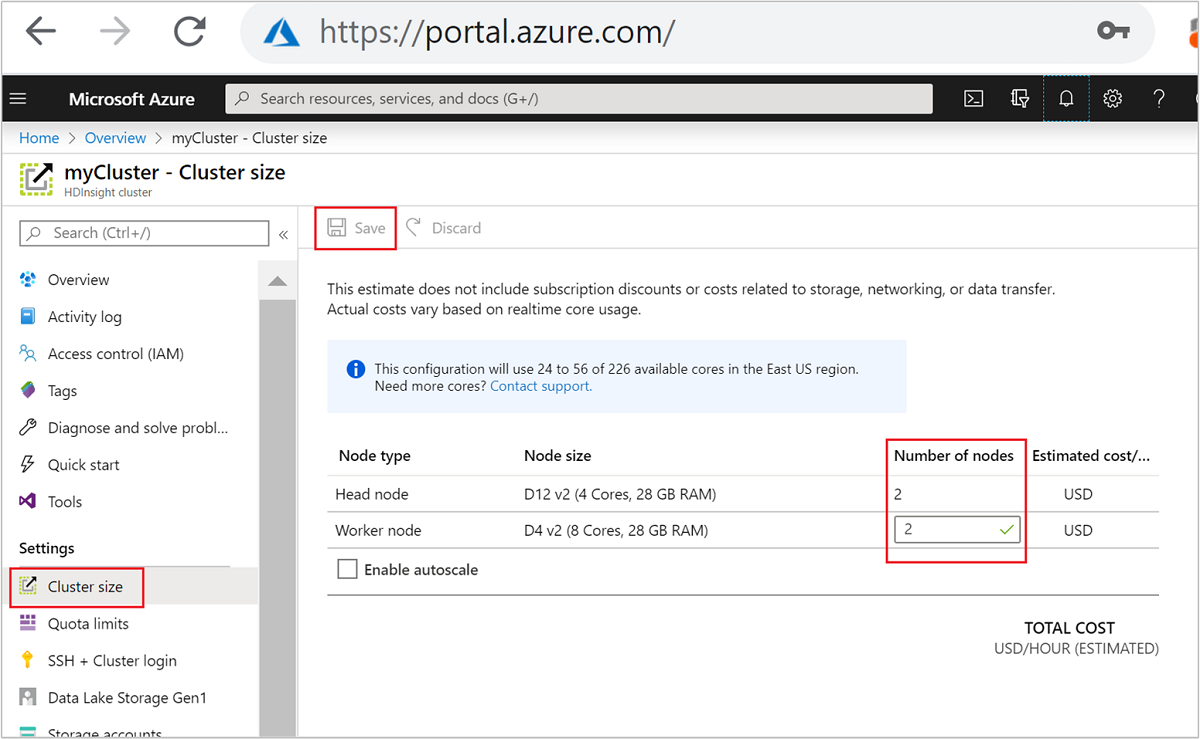
Pomocí některé z těchto metod můžete vertikálně navýšit nebo snížit kapacitu clusteru HDInsight během několika minut.
Důležité
Dopad operací škálování
Když přidáte uzly do spuštěného clusteru HDInsight (vertikální navýšení kapacity), úlohy zůstanou nedotčené. Nové úlohy je možné bezpečně odeslat, když je proces škálování spuštěný. Pokud operace škálování selže, selhání opustí cluster ve funkčním stavu.
Pokud odeberete uzly (vertikální snížení kapacity), čekající nebo spuštěné úlohy po dokončení operace škálování selžou. Příčinou této chyby je restartování některých služeb během procesu škálování. Cluster se může během ruční operace škálování zaseknout v nouzovém režimu.
Dopad změny počtu datových uzlů se u jednotlivých typů clusterů podporovaných službou HDInsight liší:
Apache Hadoop
Bez problémů můžete zvýšit počet pracovních uzlů ve spuštěném clusteru Hadoop, aniž by to mělo vliv na jakékoli úlohy. Nové úlohy je možné odeslat také během probíhající operace. Selhání v operaci škálování jsou řádně zpracována. Cluster zůstane vždy ve funkčním stavu.
Při vertikálním snížení kapacity clusteru Hadoop s menším počtem datových uzlů se některé služby restartují. Toto chování způsobí selhání všech spuštěných a čekajících úloh při dokončení operace škálování. Po dokončení operace však můžete úlohy znovu odeslat.
Apache HBase
Během běhu můžete do clusteru HBase bezproblémově přidávat nebo odebírat uzly. Regionální servery se automaticky vyrovnávají během několika minut od dokončení operace škálování. Místní servery ale můžete vyrovnávat ručně. Přihlaste se k hlavnímu uzlu clusteru a spusťte následující příkazy:
pushd %HBASE_HOME%\bin hbase shell balancerDalší informace o použití prostředí HBase naleznete v tématu Začínáme s příkladem Apache HBase v HDInsight.
Poznámka:
Nespolehlivé pro clustery Kafka.
Apache Hive LLAP
Po škálování na
Npracovní uzly služba HDInsight automaticky nastaví následující konfigurace a restartuje Hive.- Maximální celkový počet souběžných dotazů:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Počet uzlů používaných LLAP Hive:
num_llap_nodes = N - Počet uzlů pro spuštění démona Hive LLAP:
num_llap_nodes_for_llap_daemons = N
- Maximální celkový počet souběžných dotazů:
Bezpečné vertikální snížení kapacity clusteru
Vertikální snížení kapacity clusteru se spuštěnými úlohami
Pokud se chcete vyhnout selhání spuštěných úloh během operace vertikálního snížení kapacity, můžete vyzkoušet tři věci:
- Před vertikálním snížením kapacity clusteru počkejte, než se úlohy dokončí.
- Ručně ukončete úlohy.
- Po dokončení operace škálování znovu odešlete úlohy.
Pokud chcete zobrazit seznam čekajících a spuštěných úloh, můžete použít uživatelské rozhraní Resource Manageru YARN, a to takto:
Na webu Azure Portal vyberte váš cluster. Cluster se otevře na nové stránce portálu.
V hlavním zobrazení přejděte na domovskou stránku Ambari řídicích panelů clusteru>. Zadejte přihlašovací údaje ke clusteru.
V uživatelském rozhraní Ambari vyberte v seznamu služeb v nabídce vlevo YARN .
Na stránce YARN vyberte Rychlé odkazy a najeďte myší na aktivní hlavní uzel a pak vyberte uživatelské rozhraní Resource Manageru.
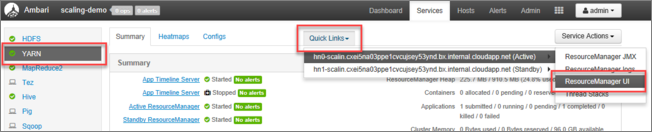
K uživatelskému rozhraní Resource Manageru můžete přistupovat přímo pomocí https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/clusternástroje .
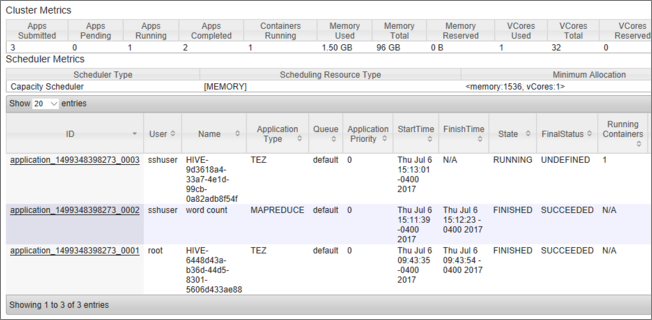
Zobrazí se seznam úloh spolu s jejich aktuálním stavem. Na snímku obrazovky je aktuálně spuštěná jedna úloha:
Spuštěním následujícího příkazu z prostředí SSH ručně ukončete spuštěnou aplikaci:
yarn application -kill <application_id>
Příklad:
yarn application -kill "application_1499348398273_0003"
Zablokování v bezpečném režimu
Při vertikálním snížení kapacity clusteru hdInsight používá rozhraní pro správu Apache Ambari k prvnímu vyřazení dalších pracovních uzlů z provozu. Uzly replikují své bloky HDFS do jiných online pracovních uzlů. Potom služba HDInsight bezpečně škáluje cluster dolů. SYSTÉM HDFS během operace škálování přejde do nouzového režimu. Po dokončení škálování se má HDFS vyjít ven. V některých případech se ale systém HDFS během operace škálování zablokuje v nouzovém režimu kvůli nedostatečné replikaci bloku souborů.
Ve výchozím nastavení je systém HDFS nakonfigurovaný s dfs.replication nastavením 1, které řídí, kolik kopií každého bloku souborů je k dispozici. Každá kopie bloku souboru je uložená na jiném uzlu clusteru.
Pokud není k dispozici očekávaný počet kopií bloku, hdFS přejde do nouzového režimu a Ambari vygeneruje výstrahy. SYSTÉM HDFS může pro operaci škálování vstoupit do nouzového režimu. Pokud se požadovaný počet uzlů pro replikaci nerozpozná, cluster se může zaseknout v nouzovém režimu.
Ukázkové chyby, když je zapnutý nouzový režim
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Můžete zkontrolovat protokoly uzlu názvů ze /var/log/hadoop/hdfs/ složky v blízkosti doby škálování clusteru a zjistit, kdy se dostal do nouzového režimu. Soubory protokolu jsou pojmenovány Hadoop-hdfs-namenode-<active-headnode-name>.*.
Původní příčinou bylo, že Hive při spouštění dotazů závisí na dočasných souborech v HDFS. Když HDFS přejde do nouzového režimu, Hive nemůže spouštět dotazy, protože nemůže zapisovat do HDFS. Dočasné soubory v HDFS jsou umístěny na místní jednotce připojené k jednotlivým virtuálním počítačům pracovních uzlů. Soubory se replikují mezi dalšími pracovními uzly na třech replikách, minimálně.
Jak zabránit zablokování služby HDInsight v nouzovém režimu
Existuje několik způsobů, jak zabránit tomu, aby služba HDInsight zůstala v nouzovém režimu:
- Před vertikálním snížením kapacity SLUŽBY HDInsight zastavte všechny úlohy Hive. Případně naplánujte proces vertikálního snížení kapacity, abyste se vyhnuli konfliktu se spouštěním úloh Hive.
- Před vertikálním snížením kapacity ručně vyčistíte pomocné
tmpsoubory adresáře Hive v HDFS. - Vertikálně navyšte kapacitu HDInsight pouze na tři pracovní uzly, minimálně. Vyhněte se tak nízkému, jako je jeden pracovní uzel.
- Spuštěním příkazu v případě potřeby ponechejte nouzový režim.
Následující části popisují tyto možnosti.
Zastavení všech úloh Hive
Před vertikálním navýšením kapacity na jeden pracovní uzel zastavte všechny úlohy Hive. Pokud je vaše úloha naplánovaná, po dokončení práce Hive spusťte vertikální snížení kapacity.
Před škálováním zastavte úlohy Hive. Pomáhá minimalizovat počet pomocné soubory ve složce tmp (pokud existuje).
Ruční vyčištění pomocných souborů Hive
Pokud Hive zůstal za dočasnými soubory, můžete tyto soubory před vertikálním snížením kapacity ručně vyčistit, abyste se vyhnuli nouzovému režimu.
Zkontrolujte, které umístění se používá pro dočasné soubory Hive, a to tak, že se podíváte na
hive.exec.scratchdirvlastnost konfigurace. Tento parametr je nastaven v:/etc/hive/conf/hive-site.xml<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Zastavte služby Hive a ujistěte se, že jsou dokončené všechny dotazy a úlohy.
Vypíše obsah pomocného adresáře, který najdete výše, a podívejte se,
hdfs://mycluster/tmp/hive/jestli obsahuje nějaké soubory:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveTady je ukázkový výstup, když existují soubory:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoPokud víte, že s těmito soubory je Hive hotová, můžete je odebrat. Ujistěte se, že Hive nemá spuštěné žádné dotazy, a to tak, že se podíváte na stránku uživatelského rozhraní Resource Manageru Yarn.
Příklad příkazového řádku pro odebrání souborů z HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Škálování SLUŽBY HDInsight na tři nebo více pracovních uzlů
Pokud se clustery často zablokují v nouzovém režimu při vertikálním snížení kapacity na méně než tři pracovní uzly, ponechte aspoň tři pracovní uzly.
Mít tři pracovní uzly je nákladnější než vertikální snížení kapacity pouze na jeden pracovní uzel. Tato akce ale brání zablokování clusteru v nouzovém režimu.
Škálování služby HDInsight dolů na jeden pracovní uzel
I když je cluster vertikálně navyšován na jeden uzel, pracovní uzel 0 stále přežije. Pracovní uzel 0 nelze nikdy vyřadit z provozu.
Spuštěním příkazu ponechte nouzový režim.
Poslední možností je spuštění příkazu nouzového režimu. Pokud systém HDFS vstoupil do nouzového režimu kvůli pod replikaci souboru Hive, spuštěním následujícího příkazu ponechte nouzový režim:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Vertikální snížení kapacity clusteru Apache HBase
Servery oblastí se po dokončení operace škálování automaticky vyrovnávají během několika minut. Pokud chcete ručně vyrovnávat servery oblastí, proveďte následující kroky:
Připojte se ke clusteru HDInsight pomocí SSH. Další informace najdete v tématu Použití SSH se službou HDInsight.
Spusťte prostředí HBase:
hbase shellK ručnímu vyvážení serverů oblastí použijte následující příkaz:
balancer
Další kroky
Konkrétní informace o škálování clusteru HDInsight najdete v tématu:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro