Řešení potíží s Apache Hadoop YARN pomocí služby Azure HDInsight
Seznamte se s hlavními problémy a jejich řešeními při práci s datovými částmi Apache Hadoop YARN v Apache Ambari.
Návody vytvořit novou frontu YARN v clusteru?
Kroky řešení
Pomocí následujících kroků v Ambari vytvořte novou frontu YARN a pak vyrovnejte přidělení kapacity mezi všechny fronty.
V tomto příkladu se změní dvě existující fronty (výchozí a thriftsvr) z 50% kapacity na 25 %, což dává nové frontě (Spark) 50% kapacitu.
| Fronta | Kapacita | Maximální kapacita |
|---|---|---|
| default | 25 % | 50 % |
| thrftsvr | 25 % | 50 % |
| Spark | 50 % | 50 % |
Vyberte ikonu zobrazení Ambari a pak vyberte vzor mřížky. Dále vyberte Správce front YARN.
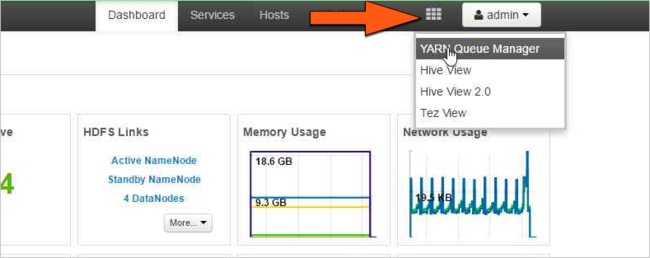
Vyberte výchozí frontu.
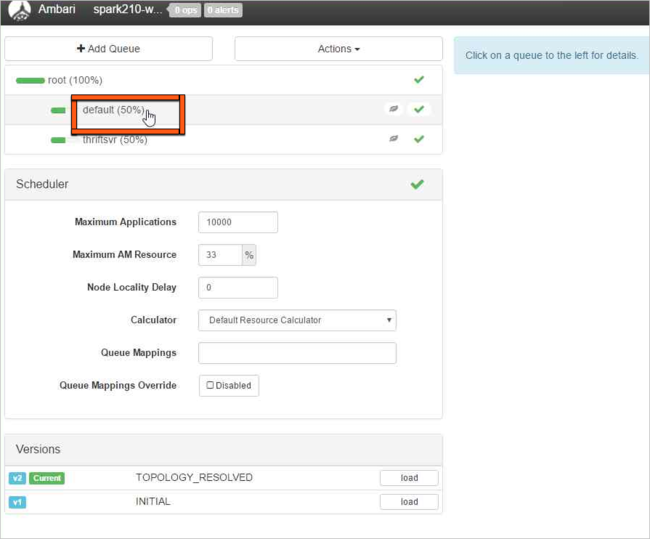
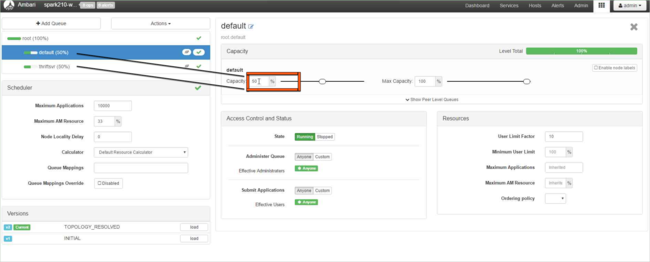
U výchozí fronty změňte kapacitu z 50 % na 25 %. U fronty thriftsvr změňte kapacitu na 25 %.
Pokud chcete vytvořit novou frontu, vyberte Přidat frontu.
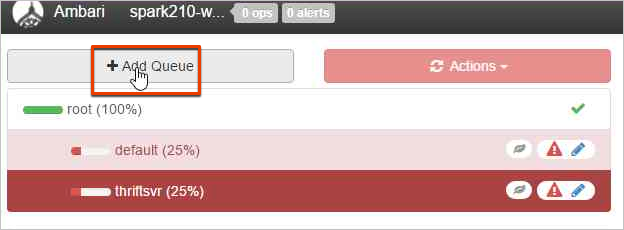
Pojmenujte novou frontu.
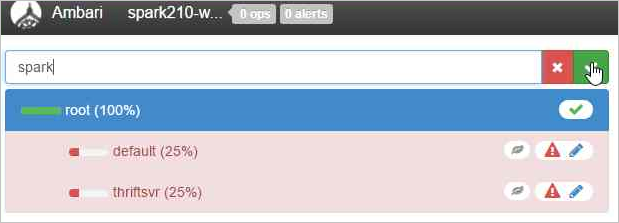
Hodnoty kapacity ponechte na 50 % a pak vyberte tlačítko Akce.
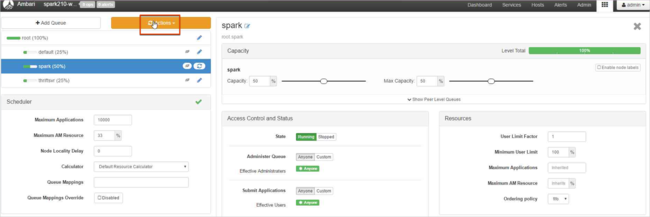
Vyberte Uložit a aktualizovat fronty.
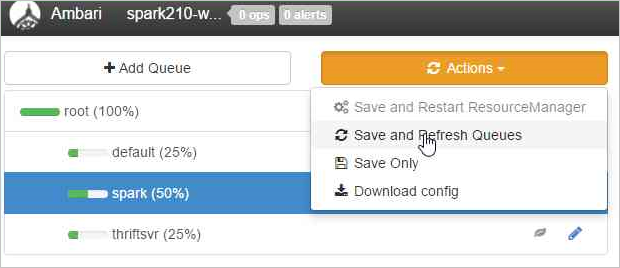
Tyto změny jsou viditelné okamžitě v uživatelském rozhraní plánovače YARN.
Další texty
Návody stáhnout protokoly YARN z clusteru?
Kroky řešení
Připojení ke clusteru HDInsight pomocí klienta SSH (Secure Shell). Další informace najdete v tématu Další informace.
Pokud chcete zobrazit seznam všech ID aplikací YARN, které jsou aktuálně spuštěné, spusťte následující příkaz:
yarn topID jsou uvedená ve sloupci APPLICATIONID . Protokoly si můžete stáhnout ze sloupce APPLICATIONID .
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerPokud chcete stáhnout protokoly kontejneru YARN pro všechny hlavní servery aplikací, použijte následující příkaz:
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtTento příkaz vytvoří soubor protokolu s názvem amlogs.txt.
Pokud chcete stáhnout protokoly kontejneru YARN pouze pro nejnovější hlavní server aplikací, použijte následující příkaz:
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtTento příkaz vytvoří soubor protokolu s názvem latestamlogs.txt.
Pokud chcete stáhnout protokoly kontejneru YARN pro první dva hlavní servery aplikací, použijte následující příkaz:
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtTento příkaz vytvoří soubor protokolu s názvem first2amlogs.txt.
Ke stažení všech protokolů kontejneru YARN použijte následující příkaz:
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtTento příkaz vytvoří soubor protokolu s názvem logs.txt.
Pokud chcete stáhnout protokol kontejneru YARN pro konkrétní kontejner, použijte následující příkaz:
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtTento příkaz vytvoří soubor protokolu s názvem containerlogs.txt.
Další čtení
Návody zkontrolovat informace o diagnostice aplikací Yarn?
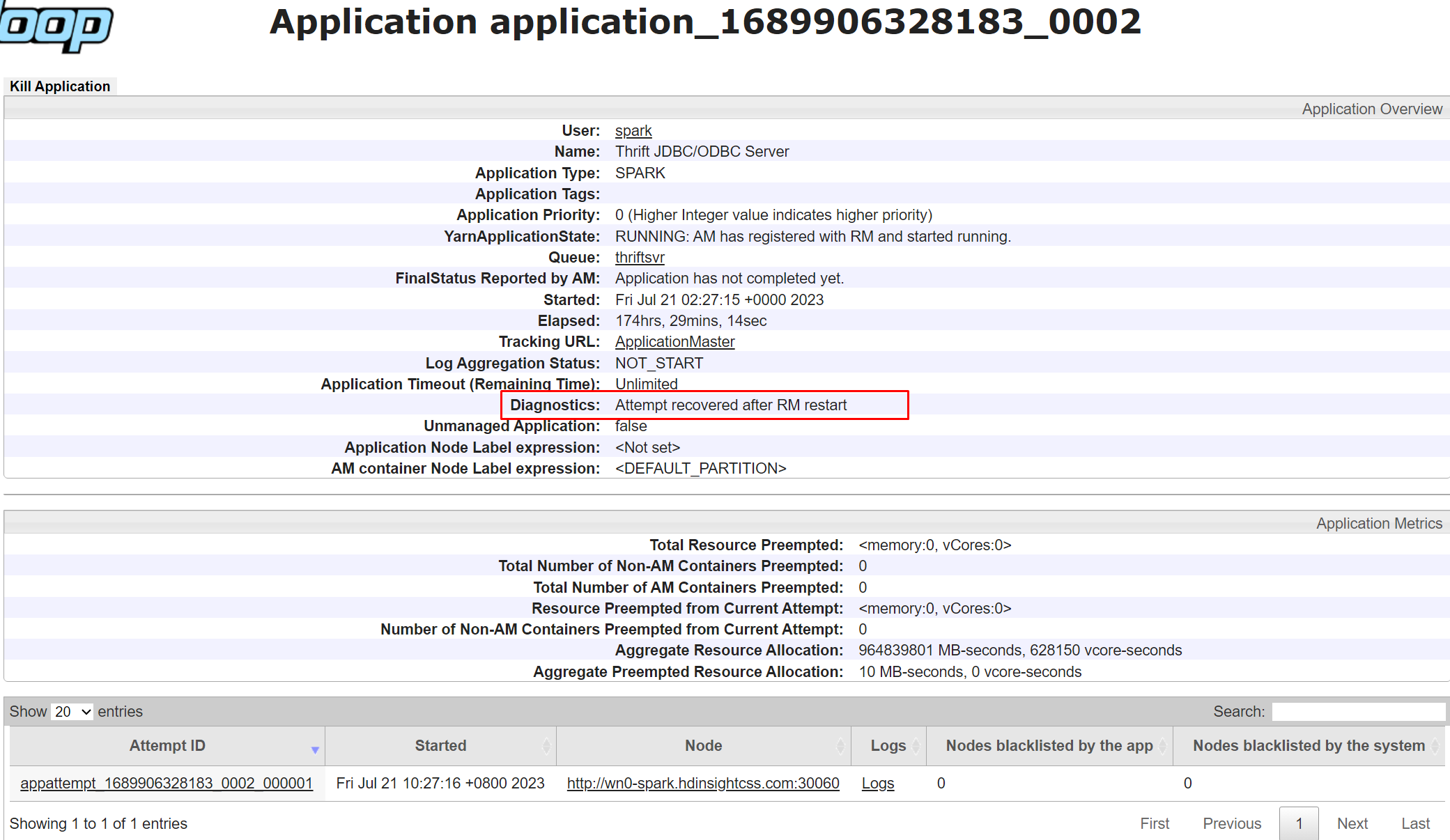
Diagnostika v uživatelském rozhraní Yarn je funkce, která umožňuje zobrazit stav a protokoly aplikací spuštěných na Yarn. Diagnostika vám může pomoct s řešením potíží a laděním aplikací a také monitorovat jejich výkon a využití prostředků.
Pokud chcete zobrazit diagnostiku konkrétní aplikace, můžete kliknout na ID aplikace v seznamu aplikací. Na stránce s podrobnostmi aplikace můžete také zobrazit seznam všech pokusů o spuštění aplikace. Kliknutím na libovolný pokus můžete zobrazit další podrobnosti, jako je ID pokusu, ID kontejneru, ID uzlu, čas spuštění, čas dokončení a diagnostika.
Návody řešení běžných problémů s YARN?
Uživatelské rozhraní Yarn se nenačítá
Pokud se vaše uživatelské rozhraní YARN nenačítá nebo je nedostupné a vrátí chybu HTTP 502.3 – Chybná brána, důrazně značí, že vaše služba Resource Manager není v pořádku. Pokud chcete tento problém zmírnit, postupujte následovně:
- Přejděte na Ambari UI>YARN>SUMMARY a zkontrolujte, jestli je ve stavu Spuštěno jenom aktivní Resource Manager. Pokud ne, zkuste zmírnit restartováním špatného stavu nebo zastaveným Resource Managerem.
- Pokud krok 1 problém nevyřeší, SSH aktivní hlavní uzel Resource Manageru a zkontrolujte stav uvolňování paměti pomocí
jstat -gcutil <Resource Manager pid> 1000 100. Pokud se během několika sekund výrazně zvýší FGCT , znamená to, že Resource Manager je zaneprázdněný v úplném uvolňování paměti a nemůže zpracovat ostatní požadavky. - Přejděte do části Uživatelské rozhraní Ambari>YARN>KONFIGURACE>Upřesnit a zvyšte hodnotu nastavení
Resource Manager java heap size. - V uživatelském rozhraní Ambari restartujte požadované služby.
Oba správci prostředků jsou v pohotovostním režimu.
- Zkontrolujte protokol Resource Manageru a zjistěte, jestli existuje podobná chyba.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
Pokud se tato chyba vyskytne, zkontrolujte, jestli jsou některé soubory v replikaci nebo jestli v systému HDFS nechybí bloky. Můžete spustit
hdfs fsck hdfs://mycluster/.Spusťte
hdfs fsck hdfs://mycluster/ -deletepříliš vynucené vyčištění HDFS a zbavte se problému s pohotovostním RM. Případně spusťte PatchYarnNodeLabel na jednom z hlavních uzlů a opravte cluster.
Další kroky
Pokud jste problém neviděli nebo nemůžete problém vyřešit, navštivte jeden z následujících kanálů, kde najdete další podporu:
Získejte odpovědi od odborníků na Azure prostřednictvím podpory komunity Azure.
Připojení s @AzureSupport – oficiálním účtem Microsoft Azure pro zlepšení zkušeností zákazníků. Připojení komunity Azure k správným prostředkům: odpovědi, podpora a odborníci.
Pokud potřebujete další pomoc, můžete odeslat žádost o podporu z webu Azure Portal. V řádku nabídek vyberte možnost Podpora nebo otevřete centrum nápovědy a podpory . Podrobnější informace najdete v tématu Vytvoření žádosti o podpora Azure. Součástí předplatného Microsoft Azure je přístup ke správě předplatného a podpora fakturace. Technická podpora se poskytuje prostřednictvím některého z plánů podpory Azure.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro