Rychlý start: Spouštění dotazů Apache Hive ve službě Azure HDInsight pomocí Apache Zeppelinu
V tomto rychlém startu se dozvíte, jak pomocí Apache Zeppelinu spouštět dotazy Apache Hive ve službě Azure HDInsight. Clustery HDInsight Interactive Query zahrnují poznámkové bloky Apache Zeppelin , které můžete použít ke spouštění interaktivních dotazů Hive.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
Cluster HDInsight Interactive Query. Viz Vytvoření clusteru pro vytvoření clusteru HDInsight. Nezapomeňte zvolit typ clusteru Interactive Query .
Vytvoření poznámky Apache Zeppelin
Nahraďte
CLUSTERNAMEnázvem vašeho clusteru v následující adrese URLhttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Pak zadejte adresu URL ve webovém prohlížeči.Zadejte uživatelské jméno a heslo pro přihlášení ke clusteru. Na stránce Zeppelin můžete vytvořit novou poznámku nebo otevřít existující poznámky. HiveSample obsahuje některé ukázkové dotazy Hive.
Vyberte Vytvořit novou poznámku.
V dialogovém okně Vytvořit novou poznámku zadejte nebo vyberte následující hodnoty:
- Název poznámky: Zadejte název poznámky.
- Výchozí interpret: V rozevíracím seznamu vyberte jdbc .
Vyberte Vytvořit poznámku.
Do části kódu zadejte následující dotaz Hive a stiskněte Shift +Enter:
%jdbc(hive) show tables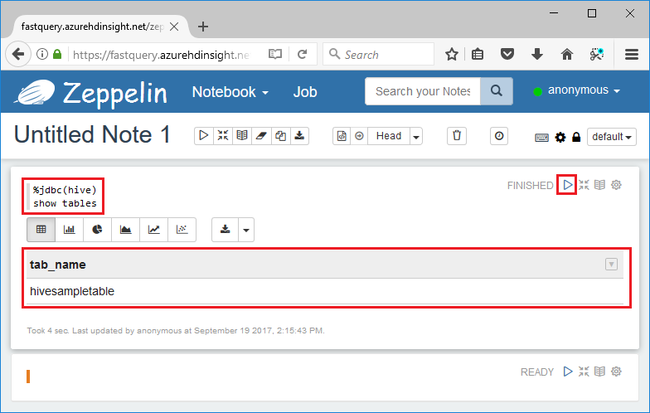
Příkaz
%jdbc(hive)na prvním řádku říká poznámkovému bloku, aby používal interpret Hive JDBC.Dotaz vrátí jednu tabulku Hive s názvem hivesampletable.
Následuje dva další dotazy Hive, které můžete spustit proti hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Ve srovnání s tradičním Hivem se výsledky dotazu vrátí mnohem rychleji.
Další příklady
Vytvoření tabulky Spusťte kód v poznámkovém bloku Zeppelin:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Načtěte data do nové tabulky. Spusťte kód v poznámkovém bloku Zeppelin:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Vložte jeden záznam. Spusťte kód v poznámkovém bloku Zeppelin:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Další syntaxi najdete v příručce jazyka Hive.
Vyčištění prostředků
Po dokončení rychlého startu možná budete chtít cluster odstranit. S HDInsight jsou vaše data uložená ve službě Azure Storage, takže můžete cluster bezpečně odstranit, když se nepoužívá. Za cluster HDInsight se vám také účtují poplatky, i když se nepoužívá. Vzhledem k tomu, že poplatky za cluster jsou mnohokrát vyšší než poplatky za úložiště, dává smysl odstranit clustery, když se nepoužívají.
Pokud chcete cluster odstranit, přečtěte si téma Odstranění clusteru HDInsight pomocí prohlížeče, PowerShellu nebo Azure CLI.
Další kroky
V tomto rychlém startu jste zjistili, jak pomocí Apache Zeppelinu spouštět dotazy Apache Hive ve službě Azure HDInsight. Další informace o dotazech Hive najdete v dalším článku, ve které se dozvíte, jak spouštět dotazy pomocí sady Visual Studio.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro