Optimalizace Apache Hivu s využitím Apache Ambari ve službě Azure HDInsight
Apache Ambari je webové rozhraní pro správu a monitorování clusterů HDInsight. Úvod do webového uživatelského rozhraní Ambari najdete v tématu Správa clusterů HDInsight pomocí webového uživatelského rozhraní Apache Ambari.
Následující části popisují možnosti konfigurace pro optimalizaci celkového výkonu Apache Hivu.
- Pokud chcete upravit parametry konfigurace Hive, vyberte Hive na bočním panelu Služby.
- Přejděte na kartu Konfigurace .
Nastavení prováděcího modulu Hive
Hive poskytuje dva prováděcí moduly: Apache Hadoop MapReduce a Apache TEZ. Tez je rychlejší než MapReduce. Clustery HDInsight Linux mají Tez jako výchozí spouštěcí modul. Změna prováděcího modulu:
Na kartě Konfigurace Hive zadejte do pole filtru prováděcí modul.
Výchozí hodnota vlastnosti Optimization je Tez.

Ladění mapovačů
Hadoop se pokusí rozdělit (mapovat) jeden soubor do více souborů a zpracovat výsledné soubory paralelně. Počet mapovačů závisí na počtu rozdělení. Následující dva parametry konfigurace řídí počet rozdělení pro prováděcí modul Tez:
tez.grouping.min-size: Nižší limit velikosti seskupeného rozdělení s výchozí hodnotou 16 MB (16 777 216 bajtů).tez.grouping.max-size: Horní limit velikosti seskupeného rozdělení s výchozí hodnotou 1 GB (1 073 741 824 bajtů).
Jako vodítko výkonu snižte oba tyto parametry, aby se zlepšila latence, aby se zvýšila propustnost.
Pokud například chcete nastavit čtyři úkoly mapperu pro velikost dat 128 MB, nastavili byste oba parametry na 32 MB každý (33 554 432 bajtů).
Pokud chcete upravit parametry omezení, přejděte na kartu Konfigurace služby Tez. Rozbalte panel Obecné a vyhledejte
tez.grouping.max-sizeparametry.tez.grouping.min-sizeNastavte oba parametry na 33 554 432 bajtů (32 MB).

Tyto změny ovlivňují všechny úlohy Tez na celém serveru. Pokud chcete získat optimální výsledek, zvolte odpovídající hodnoty parametrů.
Ladění reduktorů
Apache ORC i Snappy nabízejí vysoký výkon. Hive ale může mít ve výchozím nastavení příliš málo reduktorů, což způsobuje kritické body.
Řekněme například, že máte velikost vstupních dat 50 GB. Tato data ve formátu ORC s kompresí Snappy jsou 1 GB. Hive odhaduje počet reduktorů potřebných takto: (počet bajtů vstupu do mapperů / hive.exec.reducers.bytes.per.reducer).
Ve výchozím nastavení je tento příklad čtyři reduktory.
Parametr hive.exec.reducers.bytes.per.reducer určuje počet bajtů zpracovaných na redukci. Výchozí hodnota je 64 MB. Optimalizace této hodnoty zvyšuje paralelismus a může zlepšit výkon. Příliš nízké ladění by také mohlo způsobit příliš mnoho reduktorů, což může nepříznivě ovlivnit výkon. Tento parametr vychází z vašich konkrétních požadavků na data, nastavení komprese a dalších faktorů prostředí.
Pokud chcete parametr upravit, přejděte na kartu Konfigurace Hive a na stránce Nastavení vyhledejte parametr Data per Reducer.
Vyberte Upravit , pokud chcete upravit hodnotu na 128 MB (134 217 728 bajtů) a stisknutím klávesy Enter uložte.
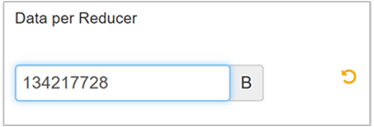
Vzhledem k velikosti vstupu 1 024 MB s 128 MB dat na redukční nástroj existuje osm reduktorů (1024/128).
Nesprávná hodnota parametru Data per Reducer může mít za následek velký počet reduktorů, což nepříznivě ovlivňuje výkon dotazů. Pokud chcete omezit maximální počet reduktorů, nastavte
hive.exec.reducers.maxna odpovídající hodnotu. Výchozí hodnota je 1009.
Povolení paralelního spouštění
Dotaz Hive se provádí v jedné nebo více fázích. Pokud se nezávislé fáze dají spustit paralelně, zvýší se tím výkon dotazů.
Pokud chcete povolit paralelní provádění dotazů, přejděte na kartu Konfigurace Hive a vyhledejte
hive.exec.parallelvlastnost. Výchozí hodnota je false. Změňte hodnotu na true a stisknutím klávesy Enter hodnotu uložte.Chcete-li omezit počet spuštěných úloh paralelně, upravte
hive.exec.parallel.thread.numbervlastnost. Výchozí hodnota je 8.
Povolení vektorizace
Hive zpracovává řádek dat po řádku. Vektorizace směruje Hive ke zpracování dat v blocích 1 024 řádků místo jednoho řádku najednou. Vektorizace se vztahuje pouze na formát souboru ORC.
Pokud chcete povolit vektorizované spuštění dotazu, přejděte na kartu Konfigurace Hive a vyhledejte
hive.vectorized.execution.enabledparametr. Výchozí hodnota platí pro Hive 0.13.0 nebo novější.Pokud chcete povolit vektorizované spouštění pro stranu redukce dotazu, nastavte
hive.vectorized.execution.reduce.enabledparametr na hodnotu true. Výchozí hodnota je false.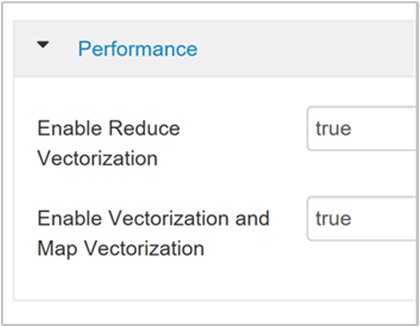
Povolení optimalizace na základě nákladů (CBO)
Hive ve výchozím nastavení používá sadu pravidel pro vyhledání jednoho optimálního plánu provádění dotazů. Optimalizace založená na nákladech (CBO) vyhodnocuje několik plánů pro spuštění dotazu. A přiřadí každému plánu náklady a pak určí nejlevnější plán pro provedení dotazu.
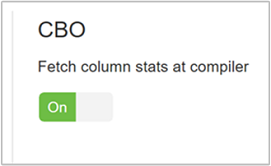
Pokud chcete povolit CBO, přejděte na Konfigurace> Hive>Nastavení a vyhledejte Enable Cost Based Optimizer a pak přepněte přepínač na Zapnuto.

Následující další parametry konfigurace zvyšují výkon dotazů Hive při povolení CBO:
hive.compute.query.using.statsPokud je nastavena hodnota true, Hive používá statistiky uložené v metastoru k zodpovězení jednoduchých dotazů, jako je
count(*).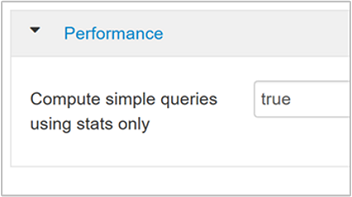
hive.stats.fetch.column.statsStatistiky sloupců se vytvoří, když je povolený CBO. Hive používá statistiky sloupců, které jsou uložené v metastoru, k optimalizaci dotazů. Načtení statistiky sloupců pro každý sloupec trvá déle, když je počet sloupců vysoký. Pokud je nastavená hodnota false, toto nastavení zakáže načítání statistik sloupců z metastoru.
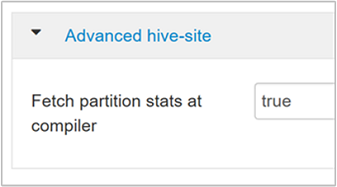
hive.stats.fetch.partition.statsZákladní statistiky oddílů, jako je počet řádků, velikost dat a velikost souboru, se ukládají do metastoru. Pokud je nastavená hodnota true, statistiky oddílů se načítají z metastoru. Pokud je hodnota false, velikost souboru se načte ze systému souborů. A počet řádků se načte ze schématu řádků.
Další informace najdete v blogovém příspěvku optimalizace na základě nákladů Hive v Analýze na blogu Azure.
Povolení zprostředkující komprese
Úkoly mapování vytvářejí zprostředkující soubory, které používají úkoly redukce. Zprostředkující komprese zmenší velikost zprostředkujícího souboru.
Úlohy Hadoopu jsou obvykle kritické pro vstupně-výstupní operace. Komprese dat může urychlit vstupně-výstupní operace a celkový přenos sítě.
Dostupné typy komprese:
| Formát | Nástroj | Algoritmus | Přípona souboru | Rozdělitelné? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLACI | .gz |
No |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Ano |
| LZO | Lzop |
LZO | .lzo |
Ano, pokud je indexováno |
| Elegantní | – | Elegantní | Elegantní | No |
Obecně platí, že rozdělení metody komprese je důležité, jinak se vytvoří několik mapperů. Pokud jsou vstupní data text, bzip2 je nejlepší volbou. U formátu ORC je funkce Snappy nejrychlejší možností komprese.
Pokud chcete povolit zprostředkující kompresi, přejděte na kartu Konfigurace Hive a nastavte
hive.exec.compress.intermediateparametr na true. Výchozí hodnota je false.
Poznámka:
Chcete-li komprimovat zprostředkující soubory, zvolte kodek komprese s nižšími náklady na procesor, i když kodek nemá vysoký výstup komprese.
Chcete-li nastavit kodek zprostředkující komprese, přidejte do souboru nebo
mapred-site.xmlvlastní vlastnost.mapred.map.output.compression.codechive-site.xmlPřidání vlastního nastavení:
a. Přejděte na Konfigurace>Hive>Advanced Custom>Hive-site.
b. Vyberte Přidat vlastnost... v dolní části podokna Vlastní podregistr-web.
c. V okně Přidat vlastnost zadejte
mapred.map.output.compression.codecjako klíč aorg.apache.hadoop.io.compress.SnappyCodechodnotu.d. Vyberte Přidat.
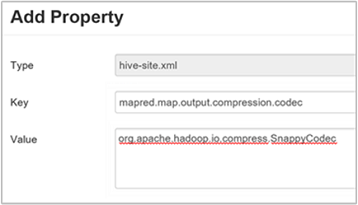
Toto nastavení zkomprimuje zprostředkující soubor pomocí komprese Snappy. Po přidání vlastnosti se zobrazí v podokně Vlastní podregistr-web.
Poznámka:
Tento postup upraví
$HADOOP_HOME/conf/hive-site.xmlsoubor.
Komprese konečného výstupu
Konečný výstup Hive lze také zkomprimovat.
Pokud chcete zkomprimovat konečný výstup Hive, přejděte na kartu Konfigurace Hive a nastavte
hive.exec.compress.outputparametr na true. Výchozí hodnota je false.Pokud chcete zvolit kodek komprese výstupu, přidejte
mapred.output.compression.codecvlastní vlastnost do podokna Vlastní podregistr-web, jak je popsáno v kroku 3 předchozí části.
Povolení spekulativního spouštění
Spekulativní spuštění spustí určitý počet duplicitních úloh, které detekují a zamítnou seznam pomalého sledování úloh. Při zlepšování celkového provádění úlohy optimalizací výsledků jednotlivých úkolů.
Spekulativní spouštění by nemělo být zapnuté u dlouhotrvajících úloh MapReduce s velkými objemy vstupu.
Pokud chcete povolit spekulativní spuštění, přejděte na kartu Konfigurace Hive a nastavte
hive.mapred.reduce.tasks.speculative.executionparametr na true. Výchozí hodnota je false.
Ladění dynamických oddílů
Hive umožňuje vytvářet dynamické oddíly při vkládání záznamů do tabulky bez předdefinování každého oddílu. Tato schopnost je výkonná funkce. I když může vést k vytvoření velkého počtu oddílů. A velký počet souborů pro každý oddíl.
Aby Hive dělal dynamické oddíly, hodnota parametru
hive.exec.dynamic.partitionby měla být pravdivá (výchozí).Změňte režim dynamického oddílu na striktní. V přísném režimu musí být alespoň jeden oddíl statický. Toto nastavení zabraňuje dotazům bez filtru oddílů v klauzuli WHERE, to znamená, že striktní zabraňuje dotazům, které kontrolují všechny oddíly. Přejděte na kartu Konfigurace Hive a pak nastavte
hive.exec.dynamic.partition.modestriktní nastavení. Výchozí hodnota není omezena.Pokud chcete omezit počet dynamických oddílů, které se mají vytvořit, upravte
hive.exec.max.dynamic.partitionsparametr. Výchozí hodnota je 5000.Chcete-li omezit celkový počet dynamických oddílů na uzel, upravte
hive.exec.max.dynamic.partitions.pernode. Výchozí hodnota je 2000.
Povolení místního režimu
Místní režim umožňuje Hivu provádět všechny úkoly úlohy na jednom počítači. Nebo někdy v jednom procesu. Toto nastavení zlepšuje výkon dotazů, pokud jsou vstupní data malá. A režijní náklady na spouštění úloh pro dotazy spotřebovávají značné procento celkového provádění dotazů.
Pokud chcete povolit místní režim, přidejte hive.exec.mode.local.auto parametr na panel Vlastní podregistr-web, jak je vysvětleno v kroku 3 oddílu Povolit zprostředkující kompresi .
Nastavení jedné skupiny MapReduce MultiGROUP BY
Pokud je tato vlastnost nastavena na hodnotu true, dotaz MultiGROUP BY s běžnými klíči seskupit podle vygeneruje jednu úlohu MapReduce.
Chcete-li toto chování povolit, přidejte hive.multigroupby.singlereducer parametr do podokna Vlastní podregistr-web, jak je vysvětleno v kroku 3 části Povolení zprostředkující komprese .
Další optimalizace Hivu
Následující části popisují další optimalizace související s Hivem, které můžete nastavit.
Optimalizace spojení
Výchozí typ spojení v Hivu je náhodné spojení. Ve službě Hive načtou speciální mappery vstup a vygenerují dvojici klíč/hodnota spojení do zprostředkujícího souboru. Hadoop tyto páry seřadí a sloučí do fáze náhodného prohazování. Tato fáze náhodného prohazu je nákladná. Výběr správného spojení na základě vašich dat může výrazně zvýšit výkon.
| Typ spojení | Když | Jak | Nastavení Hivu | Komentáře |
|---|---|---|---|---|
| Shuffle Join |
|
|
Není potřeba žádné významné nastavení Hivu. | Funguje pokaždé |
| Připojení k mapě |
|
|
hive.auto.confvert.join=true |
Rychlé, ale omezené |
| Seřadit slučovací kbelík | Pokud jsou obě tabulky:
|
Každý proces:
|
hive.auto.convert.sortmerge.join=true |
Efektivita |
Optimalizace prováděcího modulu
Další doporučení pro optimalizaci modulu spouštění Hive:
| Nastavení | Doporučené | Výchozí nastavení služby HDInsight |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = bezpečnější, pomalejší; false = rychlejší | false (nepravda) |
tez.am.resource.memory.mb |
Horní mez 4 GB pro většinu | Automatické ladění |
tez.session.am.dag.submit.timeout.secs |
300 a více | 300 |
tez.am.container.idle.release-timeout-min.millis |
20 000 a více | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40 000 a více | 20 000 |