Analýza protokolů telemetrie Application Insights pomocí Apache Sparku ve službě HDInsight
Naučte se používat Apache Spark ve službě HDInsight k analýze telemetrických dat Application Insights.
Visual Studio Application Insights je analytická služba, která monitoruje webové aplikace. Telemetrická data generovaná službou Application Insights je možné exportovat do Služby Azure Storage. Jakmile jsou data ve službě Azure Storage, můžete ji použít k analýze SLUŽBY HDInsight.
Požadavky
Aplikace, která je nakonfigurovaná tak, aby používala Application Insights.
Znalost vytváření clusteru HDInsight založeného na Linuxu Další informace najdete v tématu Vytvoření Apache Sparku ve službě HDInsight.
Webový prohlížeč.
Při vývoji a testování tohoto dokumentu byly použity následující zdroje informací:
Telemetrická data Application Insights se vygenerovala pomocí webové aplikace Node.js nakonfigurované tak, aby používala Application Insights.
K analýze dat se použil linuxový Spark v clusteru HDInsight verze 3.5.
Architektura a plánování
Následující diagram znázorňuje architekturu služby tohoto příkladu:
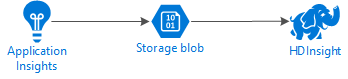
Azure Storage
Application Insights je možné nakonfigurovat tak, aby nepřetržitě exportoval telemetrické informace do objektů blob. HDInsight pak může číst data uložená v objektech blob. Existují však některé požadavky, které musíte dodržovat:
Umístění: Pokud jsou účet úložiště a HDInsight v různých umístěních, může se zvýšit latence. Zvyšuje také náklady, protože se poplatky za výchozí přenos použijí na data, která se pohybují mezi oblastmi.
Upozorňující
Použití účtu úložiště v jiném umístění než HDInsight se nepodporuje.
Typ objektu blob: HDInsight podporuje pouze objekty blob bloku. Služba Application Insights ve výchozím nastavení používá objekty blob bloku, takže by ve výchozím nastavení měla fungovat se službou HDInsight.
Informace o přidání úložiště do existujícího clusteru najdete v dokumentu Přidání dalších účtů úložiště.
Datové schéma
Application Insights poskytuje informace o exportu datového modelu pro formát telemetrických dat exportovaných do objektů blob. Kroky v tomto dokumentu používají Spark SQL k práci s daty. Spark SQL může automaticky generovat schéma pro datovou strukturu JSON protokolovanou službou Application Insights.
Export telemetrických dat
Postupujte podle kroků v části Konfigurace průběžného exportu a nakonfigurujte application Insights tak, aby exportovali telemetrické informace do objektu blob služby Azure Storage.
Konfigurace SLUŽBY HDInsight pro přístup k datům
Pokud vytváříte cluster HDInsight, přidejte účet úložiště během vytváření clusteru.
Pokud chcete přidat účet úložiště Azure do existujícího clusteru, použijte informace v dokumentu Přidat další účty úložiště.
Analýza dat: PySpark
Ve webovém prohlížeči přejděte do
https://CLUSTERNAME.azurehdinsight.net/jupyterumístění CLUSTERNAME název vašeho clusteru.V pravém horním rohu stránky Jupyter vyberte Nový a pak PySpark. Otevře se nová karta prohlížeče, která obsahuje poznámkový blok Jupyter založený na Pythonu.
Do prvního pole (označovaného jako buňka) na stránce zadejte následující text:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Tento kód nakonfiguruje Spark tak, aby rekurzivně přistupoval ke struktuře adresářů vstupních dat. Telemetrie Application Insights se protokoluje do adresářové struktury podobné
/{telemetry type}/YYYY-MM-DD/{##}/.Ke spuštění kódu použijte kombinaci kláves SHIFT+ENTER . Na levé straně buňky se mezi hranatými závorkami zobrazí znak *, který označuje, že se spouští kód v této buňce. Po dokončení se znak *změní na číslo a výstup podobný následujícímu textu se zobrazí pod buňkou:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Vytvoří se nová buňka pod první buňkou. Do nové buňky zadejte následující text. Nahraďte
CONTAINERnázev účtu služby Azure Storage aSTORAGEACCOUNTnázvem kontejneru objektů blob, který obsahuje data Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/K provedení této buňky použijte kombinaci kláves SHIFT+ENTER . Zobrazí se výsledek podobný následujícímu textu:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Vrácená cesta wasbs je umístění telemetrických dat Application Insights. Změňte čáru
hdfs dfs -lsv buňce tak, aby používala vrácenou cestu wasbs, a pak znovu spusťte buňku pomocí kombinace kláves SHIFT+ENTER . Tentokrát by se měly zobrazit adresáře, které obsahují telemetrická data.Poznámka:
Pro zbývající kroky v této části
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsse použil adresář. Vaše adresářová struktura se může lišit.Do další buňky zadejte následující kód: Nahraďte
WASB_PATHcestou z předchozího kroku.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Tento kód vytvoří datový rámec ze souborů JSON exportovaných procesem průběžného exportu. Ke spuštění této buňky použijte kombinaci kláves SHIFT+ENTER .
V další buňce zadejte a spusťte následující příkaz, abyste zobrazili schéma, které Spark vytvořil pro soubory JSON:
jsonData.printSchema()Schéma pro každý typ telemetrie se liší. Následující příklad je schéma, které se generuje pro webové požadavky (data uložená v
Requestspodadresáři):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Pomocí následujícího příkazu zaregistrujte datový rámec jako dočasnou tabulku a spusťte dotaz na data:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Tento dotaz vrátí informace o městě pro prvních 20 záznamů, kde context.location.city není null.
Poznámka:
Kontextová struktura se nachází ve všech telemetrických datech protokolovaných službou Application Insights. Prvek města nemusí být vyplněný v protokolech. Pomocí schématu můžete identifikovat další prvky, které můžete dotazovat, které mohou obsahovat data pro vaše protokoly.
Tento dotaz vrátí podobné informace jako v následujícím textu:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Analýza dat: Scala
Ve webovém prohlížeči přejděte do
https://CLUSTERNAME.azurehdinsight.net/jupyterumístění CLUSTERNAME název vašeho clusteru.V pravém horním rohu stránky Jupyter vyberte Nový a pak Scala. Zobrazí se nová karta prohlížeče obsahující poznámkový blok Jupyter založený na jazyce Scala.
Do prvního pole (označovaného jako buňka) na stránce zadejte následující text:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Tento kód nakonfiguruje Spark tak, aby rekurzivně přistupoval ke struktuře adresářů vstupních dat. Telemetrie Application Insights se protokoluje do adresářové struktury podobné
/{telemetry type}/YYYY-MM-DD/{##}/.Ke spuštění kódu použijte kombinaci kláves SHIFT+ENTER . Na levé straně buňky se mezi hranatými závorkami zobrazí znak *, který označuje, že se spouští kód v této buňce. Po dokončení se znak *změní na číslo a výstup podobný následujícímu textu se zobrazí pod buňkou:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Vytvoří se nová buňka pod první buňkou. Do nové buňky zadejte následující text. Nahraďte
CONTAINERnázev účtu služby Azure Storage aSTORAGEACCOUNTnázvem kontejneru objektů blob, který obsahuje protokoly Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/K provedení této buňky použijte kombinaci kláves SHIFT+ENTER . Zobrazí se výsledek podobný následujícímu textu:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Vrácená cesta wasbs je umístění telemetrických dat Application Insights. Změňte čáru
hdfs dfs -lsv buňce tak, aby používala vrácenou cestu wasbs, a pak znovu spusťte buňku pomocí kombinace kláves SHIFT+ENTER . Tentokrát by se měly zobrazit adresáře, které obsahují telemetrická data.Poznámka:
Pro zbývající kroky v této části
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsse použil adresář. Tento adresář nemusí existovat, pokud vaše telemetrická data nejsou určená pro webovou aplikaci.Do další buňky zadejte následující kód: Nahraďte
WASB\_PATHcestou z předchozího kroku.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Tento kód vytvoří datový rámec ze souborů JSON exportovaných procesem průběžného exportu. Ke spuštění této buňky použijte kombinaci kláves SHIFT+ENTER .
V další buňce zadejte a spusťte následující příkaz, abyste zobrazili schéma, které Spark vytvořil pro soubory JSON:
jsonData.printSchemaSchéma pro každý typ telemetrie se liší. Následující příklad je schéma, které se generuje pro webové požadavky (data uložená v
Requestspodadresáři):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Pomocí následujícího příkazu zaregistrujte datový rámec jako dočasnou tabulku a spusťte dotaz na data:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Tento dotaz vrátí informace o městě pro prvních 20 záznamů, kde context.location.city není null.
Poznámka:
Kontextová struktura se nachází ve všech telemetrických datech protokolovaných službou Application Insights. Prvek města nemusí být vyplněný v protokolech. Pomocí schématu můžete identifikovat další prvky, které můžete dotazovat, které mohou obsahovat data pro vaše protokoly.
Tento dotaz vrátí podobné informace jako v následujícím textu:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Další kroky
Další příklady použití Apache Sparku pro práci s daty a službami v Azure najdete v následujících dokumentech:
- Apache Spark s BI: Provádění interaktivní analýzy dat pomocí Sparku ve službě HDInsight s nástroji BI
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k analýze teploty budovy pomocí dat TVK
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k predikci výsledků kontroly potravin
- Analýza webových protokolů pomocí Apache Sparku ve službě HDInsight
Informace o vytváření a spouštění aplikací Spark najdete v následujících dokumentech: