Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Zjistěte, jak nakonfigurovat poznámkový blok Jupyter v clusteru Apache Spark ve službě HDInsight tak, aby používal externí balíčky Apache Maven, které nejsou předinstalovány v clusteru.
V úložišti Maven můžete vyhledat úplný seznam dostupných balíčků. Můžete také získat seznam dostupných balíčků z jiných zdrojů. Například úplný seznam balíčků, které byly přispěny komunitou, je k dispozici ve Spark Packages.
V tomto článku se dozvíte, jak používat balíček spark-csv s poznámkovým blokem Jupyter.
Požadavky
Cluster Apache Spark ve službě HDInsight. Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight.
Znalost používání poznámkových bloků Jupyter se Sparkem ve službě HDInsight. Další informace najdete v tématu Načtení dat a spouštění dotazů pomocí Apache Sparku ve službě HDInsight.
Schéma URI pro primární úložiště clusterů. To by bylo
wasb://pro Azure Storage,abfs://pro Azure Data Lake Storage Gen2. Pokud je pro Azure Storage nebo Data Lake Storage Gen2 povolený zabezpečený přenos, identifikátor URI by bylwasbs://neboabfss://(viz také ) zabezpečený přenos.
Použití externích balíčků s poznámkovými bloky Jupyter
Přejděte na
https://CLUSTERNAME.azurehdinsight.net/jupyter, kdeCLUSTERNAMEpředstavuje název vašeho clusteru Spark.Vytvořte nový poznámkový blok. Vyberte Nový a pak vyberte Spark.
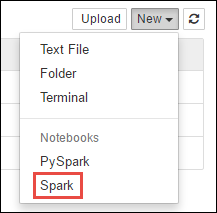
Nový poznámkový blok se vytvoří a otevře s názvem Untitled.pynb. Vyberte název poznámkového bloku nahoře a zadejte přívětivý název.

Pomocí magie nakonfigurujete
%%configurepoznámkový blok tak, aby používal externí balíček. V poznámkových blocích, které používají externí balíky, se ujistěte, že zavoláte%%configurekouzlo v první buňce kódu. Tím se zajistí, že je jádro nakonfigurované tak, aby používalo balíček před spuštěním relace.Důležité
Pokud zapomenete nakonfigurovat jádro v první buňce, můžete použít
%%configurespolu s parametrem-f, ale tím se relace restartuje a veškerý průběh bude ztracen.Verze HDInsightu Příkaz Pro HDInsight 3.5 a HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Pro HDInsight 3.3 a HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }Výše uvedený fragment kódu očekává souřadnice Mavenu pro externí balíček v centrálním úložišti Maven. V tomto fragmentu kódu
com.databricks:spark-csv_2.11:1.5.0je souřadnice Mavenu pro balíček spark-csv . Tady je postup, jak sestavíte souřadnice balíčku.a. Vyhledejte balíček v úložišti Maven. Pro účely tohoto článku používáme spark-csv.
b. Z úložiště shromážděte hodnoty GroupId, ArtifactId a Version. Ujistěte se, že hodnoty, které shromáždíte, odpovídají vašemu clusteru. V tomto případě používáme balíček Scala 2.11 a Spark 1.5.0, ale možná budete muset vybrat různé verze pro příslušnou verzi Scala nebo Spark ve vašem clusteru. Verzi Scala ve vašem clusteru můžete zjistit spuštěním
scala.util.Properties.versionStringna jádře Spark Jupyter nebo na Spark submit. Verzi Sparku ve vašem clusteru můžete zjistit spuštěnímsc.versionv poznámkových blocích Jupyter.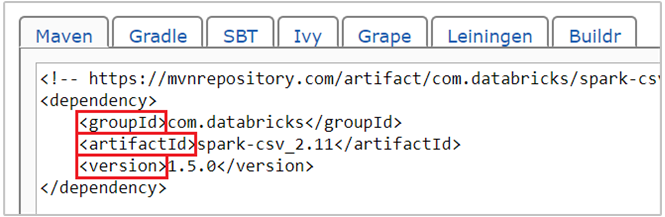
c. Zřetězení tří hodnot oddělených dvojtečkam (:).
com.databricks:spark-csv_2.11:1.5.0Spusťte buňku kódu pomocí
%%configuremagie. Tím nakonfigurujete relaci Livy, aby používala balíček, který jste poskytli. V následujících buňkách poznámkového bloku teď můžete balíček použít, jak je znázorněno níže.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Pro HDInsight 3.4 a níže byste měli použít následující fragment kódu.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Potom můžete spustit fragmenty kódu, jak je znázorněno níže, a zobrazit data z datového rámce, který jste vytvořili v předchozím kroku.
df.show() df.select("Time").count()
Viz také
Scénáře
- Apache Spark s BI: Provádění interaktivní analýzy dat pomocí Sparku ve službě HDInsight s nástroji BI
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k analýze teploty budovy pomocí dat TVK
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k predikci výsledků kontroly potravin
- Analýza webových protokolů pomocí Apache Sparku ve službě HDInsight
Vytvoření a spouštění aplikací
- Vytvoření samostatné aplikace pomocí Scala
- Vzdálené spouštění úloh v clusteru Apache Spark pomocí Apache Livy
Nástroje a rozšíření
- Použití externích balíčků Pythonu s poznámkovými bloky Jupyter v clusterech Apache Spark v HDInsight Linuxu
- Použijte plugin HDInsight Tools pro IntelliJ IDEA k vytvoření a odeslání Scala aplikací Spark
- Vzdálené ladění aplikací Apache Spark pomocí modulu plug-in nástrojů HDInsight pro IntelliJ IDEA
- Použití poznámkových bloků Apache Zeppelin s clusterem Apache Spark ve službě HDInsight
- Jádra dostupná pro Poznámkový blok Jupyter v clusteru Apache Spark pro HDInsight
- Instalace Jupyteru do počítače a připojení ke clusteru HDInsight Spark