Přehled streamování Apache Sparku
Streamování Apache Sparku poskytuje zpracování datových proudů v clusterech HDInsight Spark. Se zárukou, že každá vstupní událost je zpracována přesně jednou, i když dojde k selhání uzlu. Spark Stream je dlouhotrvající úloha, která přijímá vstupní data z široké škály zdrojů, včetně Azure Event Hubs. Také: Azure IoT Hub, Apache Kafka, Apache Flume, Twitter, , ZeroMQnezpracované sokety TCP nebo z monitorování systémů souborů Apache Hadoop YARN. Na rozdíl od výhradně procesu řízeného událostmi služba Spark Stream dávková vstupní data do časových oken. Například dvousekundový řez a pak transformuje každou dávku dat pomocí operací mapování, redukce, spojení a extrakce. Spark Stream pak zapíše transformovaná data do systémů souborů, databází, řídicích panelů a konzoly.
Aplikace Spark Streaming musí před odesláním této dávky ke zpracování počkat zlomek sekundy, aby shromáždily každou micro-batch událost. Naproti tomu aplikace řízená událostmi zpracovává každou událost okamžitě. Latence streamování Sparku je obvykle za několik sekund. Výhody mikrodávkového přístupu jsou efektivnější zpracování dat a jednodušší agregační výpočty.
Představení DStreamu
Spark Streaming představuje průběžný datový proud příchozích dat pomocí diskretizovaného datového proudu označovaného jako DStream. DStream lze vytvořit ze vstupních zdrojů, jako jsou Event Hubs nebo Kafka. Nebo použitím transformací v jiném DStreamu.
DStream poskytuje vrstvu abstrakce nad nezpracovaná data událostí.
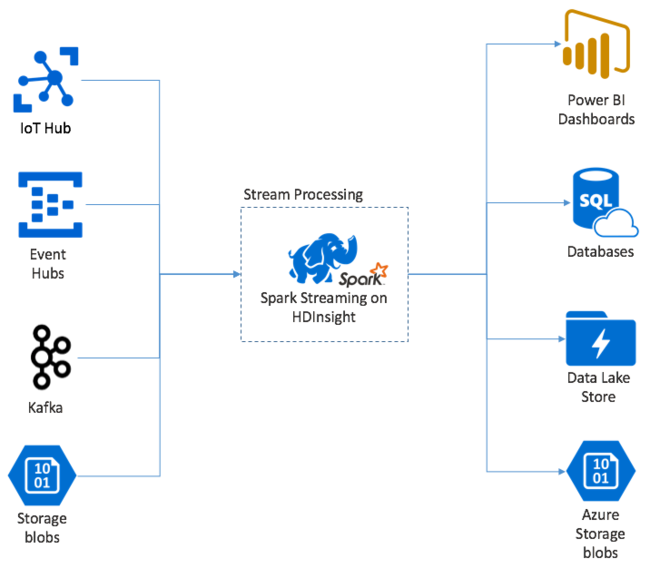
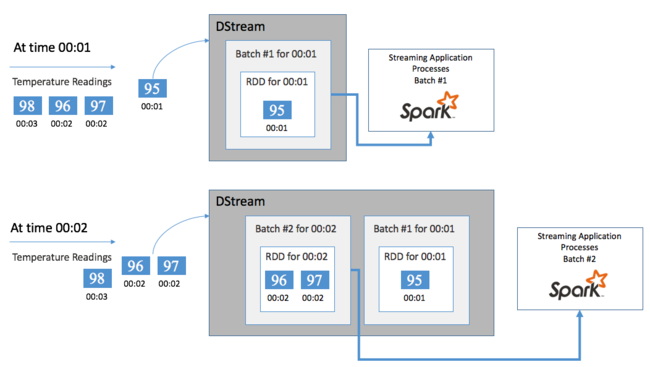
Začněte s jednou událostí, například teplotou čtení z připojeného termostatu. Když tato událost dorazí do vaší aplikace Spark Streaming, událost se uloží spolehlivým způsobem, kde se replikuje na více uzlech. Tato odolnost proti chybám zajišťuje, že selhání jakéhokoli jednoho uzlu nezpůsobí ztrátu vaší události. Jádro Sparku používá datovou strukturu, která distribuuje data mezi více uzlů v clusteru. Kde každý uzel obvykle udržuje svá vlastní data v paměti pro zajištění nejlepšího výkonu. Tato datová struktura se nazývá odolná distribuovaná datová sada (RDD).
Každá sada RDD představuje události shromážděné v rámci uživatelem definovaného časového rámce označovaného jako interval dávky. Vzhledem k tomu, že každý interval dávky uplynul, vytvoří se nová sada RDD, která obsahuje všechna data z daného intervalu. Průběžná sada sad RDD se shromažďuje do DStreamu. Pokud je například interval dávky o jednu sekundu dlouhý, váš DStream vygeneruje dávku každou sekundu obsahující jednu sadu RDD, která obsahuje všechna data přijatá během této sekundy. Při zpracování DStream se v jedné z těchto dávek zobrazí událost teploty. Aplikace Spark Streaming zpracovává dávky, které obsahují události, a nakonec funguje na datech uložených v každé sadě RDD.
Struktura aplikace Spark Streaming
Aplikace Spark Streaming je dlouhotrvající aplikace, která přijímá data ze zdrojů ingestování. Použije transformace ke zpracování dat a pak je odešle do jednoho nebo více cílů. Struktura aplikace Spark Streaming má statickou část a dynamickou část. Statická část definuje, odkud data pocházejí, jaké zpracování se má s daty provádět. A kam by měly jít výsledky. Dynamická část spouští aplikaci po neomezenou dobu a čeká na signál zastavení.
Například následující jednoduchá aplikace obdrží řádek textu přes soket TCP a spočítá, kolikrát se každé slovo zobrazí.
Definování aplikace
Definice logiky aplikace má čtyři kroky:
- Vytvořte StreamContext.
- Vytvořte DStream z StreamContextu.
- Použití transformací na DStream.
- Vypíše výsledky.
Tato definice je statická a dokud nespustíte aplikaci, nezpracují se žádná data.
Vytvoření streamovacíhocontextu
Vytvořte StreamContext ze SparkContextu, který odkazuje na váš cluster. Při vytváření streamovacíhocontextu zadáte velikost dávky v sekundách, například:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Vytvoření DStreamu
S instancí StreamingContext vytvořte vstupní DStream pro váš vstupní zdroj. V tomto případě aplikace sleduje vzhled nových souborů ve výchozím připojeném úložišti.
val lines = ssc.textFileStream("/uploads/Test/")
Použití transformací
Zpracování implementujete použitím transformací na DStream. Tato aplikace obdrží jeden řádek textu najednou ze souboru a rozdělí každý řádek na slova. Potom pomocí vzoru redukce mapy spočítá počet výskytů jednotlivých slov.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Výstupní výsledky
Nasdílejte výsledky transformace do cílových systémů použitím výstupních operací. V tomto případě se výsledek každého spuštění pro výpočet vytiskne ve výstupu konzoly.
wordCounts.print()
Spuštění aplikace
Spusťte streamovací aplikaci a spusťte ji, dokud se neobdrží signál ukončení.
ssc.start()
ssc.awaitTermination()
Podrobnosti o rozhraní API sparkového streamu najdete v průvodci programováním streamování Apache Sparku.
Následující ukázková aplikace je samostatná, takže ji můžete spustit v poznámkovém bloku Jupyter. Tento příklad vytvoří napodobení zdroje dat ve třídě DummySource, která vypíše hodnotu čítače a aktuální čas v milisekundách každých pět sekund. Nový objekt StreamingContext má dávkový interval 30 sekund. Při každém vytvoření dávky aplikace streamování prozkoumá vytvořenou sadu RDD. Potom převede RDD na datový rámec Sparku a vytvoří dočasnou tabulku nad datovým rámcem.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Počkejte asi 30 sekund po spuštění výše uvedené aplikace. Potom můžete datový rámec pravidelně dotazovat, abyste viděli aktuální sadu hodnot, které jsou přítomné v dávce, například pomocí tohoto dotazu SQL:
%%sql
SELECT * FROM demo_numbers
Výsledný výstup vypadá jako následující výstup:
| hodnota | čas |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Existuje šest hodnot, protože DummySource vytvoří hodnotu každých 5 sekund a aplikace generuje dávku každých 30 sekund.
Posuvná okna
Pokud chcete agregovat výpočty u DStreamu v určitém časovém období, například abyste získali průměrnou teplotu za poslední dvě sekundy, použijte sliding window operace zahrnuté ve Spark Streamingu. Posuvné okno má dobu trvání (délku okna) a interval, během kterého se obsah okna vyhodnotí (interval snímku).
Posuvná okna se můžou překrývat, například můžete definovat okno s délkou dvou sekund, které se posune každou sekundu. Tato akce znamená, že při každém výpočtu agregace bude okno obsahovat data z poslední sekundy předchozího okna. A všechna nová data v další sekundě.
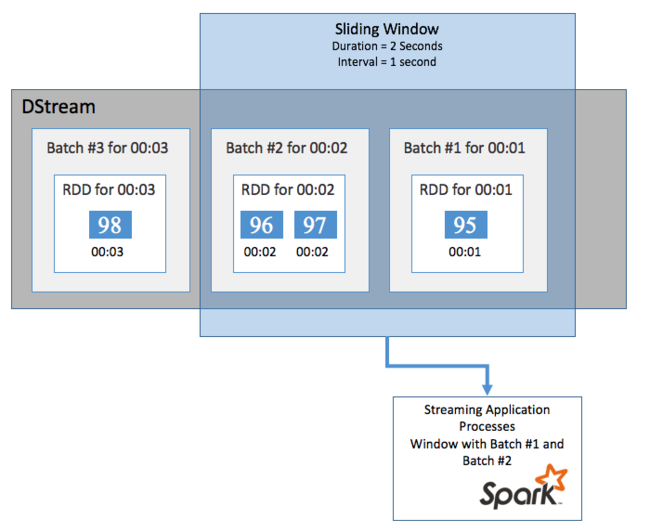
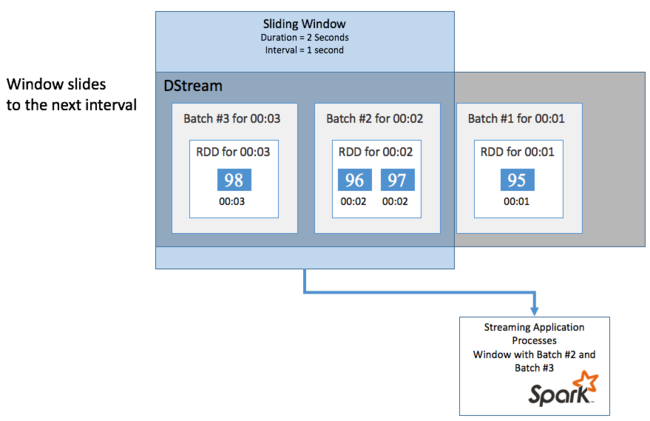
Následující příklad aktualizuje kód, který používá DummySource, ke shromáždění dávek do okna s minutovou dobou trvání a jedním minutovým snímkem.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Po první minutě je 12 položek – šest položek z každé ze dvou dávek shromážděných v okně.
| hodnota | čas |
|---|---|
| 0 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
Funkce posuvného okna dostupné v rozhraní API pro streamování Sparku zahrnují okno, countByWindow, reduceByWindow a countByValueAndWindow. Podrobnosti o těchto funkcích najdete v tématu Transformace v DStreams.
Vytváření kontrolních bodů
Aby bylo možné zajistit odolnost a odolnost proti chybám, streamování Sparku spoléhá na vytváření kontrolních bodů, aby bylo zajištěno, že zpracování datových proudů může pokračovat bez přerušení, a to i v případě selhání uzlů. Spark vytváří kontrolní body pro trvalé úložiště (Azure Storage nebo Data Lake Storage). Tyto kontrolní body ukládají metadata streamované aplikace, jako je konfigurace, a operace definované aplikací. Také všechny dávky, které byly zařazeny do fronty, ale ještě nezpracovány. Kontrolní body někdy také budou zahrnovat ukládání dat do sad RDD, aby bylo možné rychleji znovu sestavit stav dat z toho, co se nachází ve sadách RDD spravovaných Sparkem.
Nasazení aplikací Spark Streaming
Aplikaci Spark Streaming obvykle sestavíte místně do souboru JAR. Potom ho nasaďte do Sparku ve službě HDInsight zkopírováním souboru JAR do výchozího připojeného úložiště. Aplikaci můžete spustit pomocí rozhraní LIVY REST API dostupných v clusteru pomocí operace POST. Text POST obsahuje dokument JSON, který poskytuje cestu k vašemu souboru JAR. A název třídy, jejíž hlavní metoda definuje a spouští streamovací aplikaci, a volitelně požadavky na prostředky úlohy (například počet exekutorů, paměť a jádra). Všechna nastavení konfigurace, která váš kód aplikace vyžaduje.
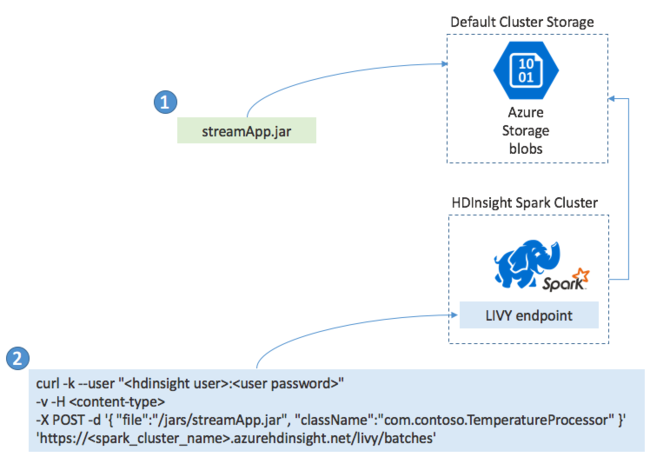
Stav všech aplikací lze také zkontrolovat pomocí požadavku GET na koncový bod LIVY. Nakonec můžete ukončit spuštěnou aplikaci tak, že vydáte požadavek DELETE na koncový bod LIVY. Podrobnosti o rozhraní LIVY API najdete v tématu Vzdálené úlohy s Apache LIVY.
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro