Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje kroky řešení potíží a možná řešení problémů při používání komponent Apache Sparku v clusterech Azure HDInsight.
Scénář: Výjimka OutOfMemoryError pro Apache Spark
Problém
Vaše aplikace Apache Spark selhala s neošetřenou výjimkou OutOfMemoryError. Může se zobrazit chybová zpráva podobná této:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Příčina
Nejpravděpodobnější příčinou této výjimky je, že virtuálním počítačům Java (JVM) není přiděleno dostatek haldy paměti. Tyto počítače JVM se spouští jako exekutory nebo ovladače jako součást aplikace Apache Spark.
Rozlišení
Určete maximální velikost dat, která aplikace Spark zpracovává. Odhad založte na maximální velikosti vstupních dat, dočasných dat produkovaných transformací vstupních dat a výstupních dat produkovaných další transformací dočasných dat. Pokud počáteční odhad není dostatečný, mírně zvětšete velikost a iterujte, dokud chyby paměti neustoupí.
Ujistěte se, že cluster HDInsight, který se má použít, má dostatek prostředků v podobě paměti a jader k obsluze aplikace Spark. Toto lze určit zobrazením části Metriky clusteru uživatelského rozhraní YARN clusteru pro hodnoty Využité paměti vs. Celková paměť a Využitých virtuálních jader vs. Celková virtuální jádra.

Nastavte následující konfigurace Sparku na odpovídající hodnoty. Vyvažte požadavky aplikace s dostupnými prostředky v clusteru. Tyto hodnoty by neměly překročit 90 % dostupné paměti a jader podle YARN a měly by také splňovat minimální požadavek na paměť aplikace Spark:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Celková paměť používaná všemi exekutory =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Celková paměť používaná ovladačem =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Scénář: Chyba ve vyhrazeném prostoru haldy Java při pokusu o spuštění serveru historie Apache Sparku
Problém
Při otevírání událostí na serveru historie Sparku se zobrazí následující chyba:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Příčina
Příčinou tohoto problému je často nedostatek prostředků při otevírání velkých souborů spark-event. Velikost haldy Sparku je ve výchozím nastavení nastavená na 1 GB, ale velké soubory událostí Sparku můžou vyžadovat víc.
Pokud chcete ověřit velikost souborů, které se pokoušíte načíst, můžete provést následující příkazy:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Rozlišení
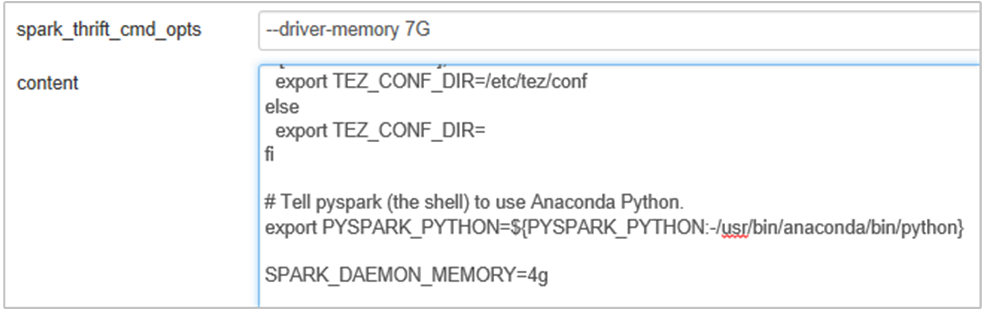
Paměť serveru historie Sparku můžete zvýšit úpravou SPARK_DAEMON_MEMORY vlastnosti v konfiguraci Sparku a restartováním všech služeb.
Můžete to udělat v uživatelském rozhraní prohlížeče Ambari výběrem oddílu Spark2/Config/Advanced spark2-env.
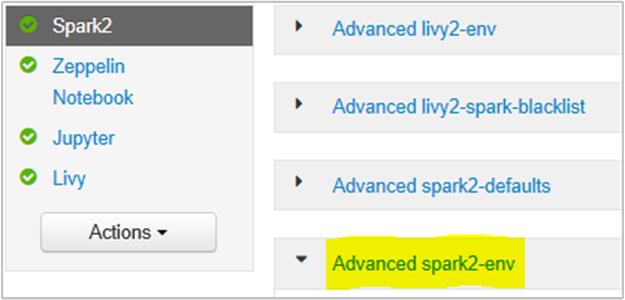
Přidejte následující vlastnost, která změní paměť serveru historie Sparku z 1g na 4g: SPARK_DAEMON_MEMORY=4g.
Nezapomeňte restartovat všechny ovlivněné služby z Ambari.
Scénář: Server Livy se nespustí v clusteru Apache Spark
Problém
Server Livy nejde spustit v Apache Sparku [(Spark 2.1 v Linuxu (HDI 3.6)]. Pokus o restartování vede k následujícímu zásobníku chyb z protokolů Livy:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Příčina
java.lang.OutOfMemoryError: unable to create new native thread zdůrazňuje, že operační systém nemůže přiřadit více nativních vláken k JVM. Potvrdilo se, že tato výjimka je způsobena porušením limitu počtu vláken pro jednotlivé procesy.
Když se Livy Server neočekávaně ukončí, ukončí se také všechna připojení ke clusterům Spark, což znamená, že dojde ke ztrátě všech úloh a souvisejících dat. Ve verzi HDP 2.6 byl zaveden mechanismus pro obnovení relace, kdy Livy ukládá podrobnosti o relaci v Zookeeperu, aby mohly být obnoveny po obnovení provozu serveru Livy.
Když je prostřednictvím Livy odeslán velký počet úloh, jako součást vysoké dostupnosti ukládá server Livy stavy relací v ZooKeeperu (na clusterech HDInsight) a obnovuje tyto relace při restartování služby Livy. Při restartu po neočekávaném ukončení Livy vytvoří jedno vlákno na každou relaci, což má za následek nashromáždění relací určených k obnově a následné vytvoření nadměrného množství vláken.
Rozlišení
Pomocí následujícího postupu odstraňte všechny položky.
Získejte IP adresy uzlů Zookeeper pomocí
grep -R zk /etc/hadoop/confPříkaz uvedený výše vypsal všechny správce pro cluster.
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Získání všech IP adres uzlů zookeeper pomocí příkazu ping Nebo se můžete také připojit k zookeeperu z hlavního uzlu pomocí názvu zookeeper.
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Jakmile se připojíte, spusťte na zookeeperu následující příkaz, který zobrazí seznam všech relací, u kterých se pokoušíte o restart.
Většina případů může být seznamem více než 8 000 relací. ####
ls /livy/v1/batchNásledující příkaz slouží k odebrání všech relací, které se mají obnovit. #####
rmr /livy/v1/batch
Počkejte, až se výše uvedený příkaz dokončí, a kurzor vrátí výzvu a pak restartujte službu Livy z Ambari, což by mělo proběhnout úspěšně.
Poznámka:
DELETE relace Livy po dokončení jejího spuštění. Sezení dávky Livy se neodstraní automaticky, jakmile se aplikace Spark dokončí, což je úmyslné. Relace Livy je entita vytvořená požadavkem POST na server Livy REST. K DELETE odstranění této entity je potřeba volání. Nebo bychom měli počkat, až se GC nakopne.
Další kroky
Pokud jste problém neviděli nebo nemůžete problém vyřešit, navštivte jeden z následujících kanálů, kde najdete další podporu:
Přehled správy paměti Sparku
Získejte odpovědi od odborníků na Azure prostřednictvím podpory komunity Azure.
Spojte se s @AzureSupport – oficiálním účtem Microsoft Azure pro zlepšení uživatelského prostředí. Propojení komunity Azure se správnými prostředky: odpovědi, podpora a odborníci.
Pokud potřebujete další pomoc, můžete odeslat žádost o podporu z webu Azure Portal. V řádku nabídek vyberte možnost Podpora nebo otevřete centrum nápovědy a podpory . Podrobnější informace najdete v tématu Vytvoření žádosti o podpora Azure. Součástí předplatného Microsoft Azure je přístup ke správě předplatného a podpora fakturace. Technická podpora se poskytuje prostřednictvím některého z plánů podpory Azure.