Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro:![]() IoT Edge 1.1
IoT Edge 1.1
Důležité
Datum ukončení podpory ioT Edge 1.1 bylo 13. prosince 2022. Informace o tom, jak se tento produkt, služba, technologie nebo rozhraní API podporují, najdete v životním cyklu produktů Společnosti Microsoft . Další informace o aktualizaci na nejnovější verzi IoT Edge najdete v tématu Aktualizace IoT Edge.
Aplikace IoT si často přejí využít inteligentní cloud a inteligentní edge. V tomto kurzu vás provedeme trénováním modelu strojového učení s daty shromážděnými ze zařízení IoT v cloudu, nasazením tohoto modelu do IoT Edge a pravidelnou údržbou a upřesněním modelu.
Poznámka:
Koncepty v této sadě kurzů platí pro všechny verze IoT Edge, ale ukázkové zařízení, které vytvoříte k vyzkoušení scénáře, běží IoT Edge verze 1.1.
Hlavním cílem tohoto kurzu je představit zpracování dat IoT pomocí strojového učení, zejména na okrajových zařízeních. Přestože se dotkneme mnoha aspektů obecného pracovního postupu strojového učení, tento kurz není zamýšlený jako podrobný úvod do strojového učení. V tomto případě se v tomto případě nepokoušáme vytvořit vysoce optimalizovaný model pro případ použití – stačí jen ilustrovat proces vytváření a používání realizovatelného modelu pro zpracování dat IoT.
Tato část kurzu popisuje:
- Předpoklady pro dokončení dalších částí kurzu.
- Cílová cílová skupina kurzu.
- Případ použití, který kurz simuluje.
- Celkový proces, který tento kurz sleduje, aby byl splněn případ použití.
Pokud ještě nemáte předplatné Azure, vytvořte si bezplatný účet Azure , než začnete.
Požadavky
K dokončení kurzu potřebujete přístup k předplatnému Azure, ve kterém máte práva vytvářet prostředky. Za několik služeb používaných v tomto kurzu se účtují poplatky za Azure. Pokud ještě nemáte předplatné Azure, možná budete moct začít s bezplatným účtem Azure.
Potřebujete také počítač s nainstalovaným PowerShellem, kde můžete spouštět skripty pro nastavení virtuálního počítače Azure jako vývojového počítače.
V tomto dokumentu používáme následující sadu nástrojů:
Azure IoT Hub pro zachytávání dat
Azure Notebooks jako hlavní front-end pro přípravu dat a experimentování strojového učení Spuštění kódu v Pythonu v poznámkovém bloku na podmnožině ukázkových dat je skvělý způsob, jak během přípravy dat dosáhnout rychlé iterativní a interaktivní zpětné vazby. Poznámkové bloky Jupyter je také možné použít k přípravě skriptů pro spouštění ve velkém měřítku ve výpočetním back-endu.
Azure Machine Learning jako back-end pro strojové učení ve velkém měřítku a pro generování imagí strojového učení. Back-end služby Azure Machine Learning řídíme pomocí skriptů připravených a otestovaných v poznámkových blocích Jupyter.
Azure IoT Edge pro mimo cloudovou aplikaci image strojového učení
Samozřejmě, jsou k dispozici další možnosti. V některých scénářích se například IoT Central dá použít jako alternativa bez kódu k zachycení počátečních trénovacích dat ze zařízení IoT.
Cílová skupina a role
Tato sada článků je určená pro vývojáře bez předchozích zkušeností s vývojem IoT nebo strojovém učením. Nasazení strojového učení na okraji vyžaduje znalosti o tom, jak propojit širokou škálu technologií. Tento kurz se proto zabývá celým komplexním scénářem, který ukazuje jeden způsob spojení těchto technologií pro řešení IoT. V reálném prostředí můžou být tyto úlohy rozděleny mezi několik lidí s různými specializacemi. Vývojáři by se například zaměřili na zařízení nebo cloudový kód, zatímco datoví vědci navrhli analytické modely. Abychom individuálnímu vývojáři umožnili úspěšné dokončení tohoto kurzu, poskytli jsme doplňkové pokyny s přehledy a odkazy na další informace, které doufáme, že jsou dostatečné k pochopení toho, co se dělá, a také proč.
Případně se můžete spojit se spolupracovníky z různých oddělení, abyste se společně zúčastnili kurzu, využili své odborné znalosti a jako tým pochopili, jak vše spolu souvisí.
V obou případech vám pomůže orientovat čtenáře, každý článek v tomto kurzu označuje roli uživatele. Mezi tyto role patří:
- Vývoj cloudu (včetně cloudového vývojáře pracujícího v kapacitě DevOps)
- Analýza dat
Případ použití: Prediktivní údržba
Tento scénář vycházíme z případu použití, který jsme představili na konferenci o prognostice a správě stavu (PHM08) v roce 2008. Cílem je předpovědět zbývající životnost (RUL) sady motorů v letadlech s turbofanem. Tato data byla generována pomocí C-MAPSS, komerční verze softwaru MAPSS (Modular Aero-Propulsion System Simulation). Tento software poskytuje flexibilní prostředí pro simulaci motoru turbofanu, které umožňuje pohodlně simulovat parametry stavu, řízení a motoru.
Data použitá v tomto kurzu jsou převzata ze sady simulačních dat poruchy motoru typu Turbofan .
Ze souboru readme:
Experimentální scénář
Datové sady se skládají z několika multivariátních časových řad. Každá datová sada je dále rozdělená na trénovací a testovací podmnožiny. Každá časová řada je z jiného motoru – tj. data mohou být považována za flotilu motorů stejného typu. Každý motor začíná různými stupni počátečního opotřebení a výrobní variace, která je pro uživatele neznámá. Toto opotřebení a variace se považují za normální, tj. není považováno za chybný stav. Existují tři provozní nastavení, která mají významný vliv na výkon motoru. Tato nastavení jsou také součástí dat. Data jsou kontaminována šumem senzoru.
Motor funguje normálně na začátku každé časové série a v určitém okamžiku během série dochází k závadě. V trénovací sadě se chyba rozrůstá až do selhání systému. V testovací sadě časová řada končí určitou dobu před selháním systému. Cílem soutěže je předpovědět počet zbývajících provozních cyklů v testovací sadě před selháním, tj. počet provozních cyklů po posledním cyklu, ve kterém bude motor nadále fungovat. Poskytuje také vektor hodnot true Remaining Useful Life (RUL) pro testovací data.
Vzhledem k tomu, že data byla publikována pro hospodářskou soutěž, bylo nezávisle publikováno několik přístupů k odvození modelů strojového učení. Zjistili jsme, že studie příkladů je užitečná při pochopení procesu a odůvodnění při vytváření konkrétního modelu strojového učení. Příklad:
Model predikce selhání leteckého motoru uživatelem GitHubu jancervenka
Zhoršení turbovrtulového motoru uživatelem GitHubu hankroark.
Proces
Následující obrázek znázorňuje přibližné kroky, které v tomto kurzu sledujeme:
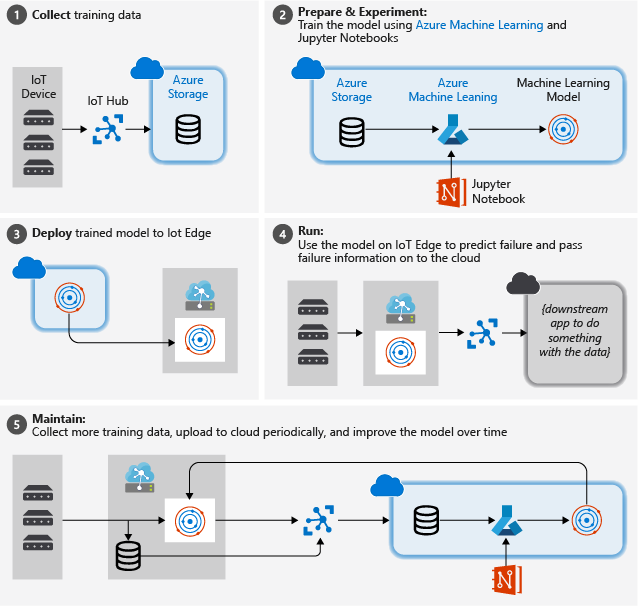
Shromažďování trénovacích dat: Proces začíná shromažďováním trénovacích dat. V některých případech už byla data shromážděna a jsou k dispozici v databázi nebo ve formě datových souborů. V jiných případech, zejména ve scénářích IoT, je potřeba data shromažďovat ze zařízení a senzorů IoT a ukládat je v cloudu.
Předpokládáme, že nemáte kolekci turbofanových motorů, takže soubory projektu zahrnují jednoduchý simulátor zařízení, který odesílá data zařízení NASA do cloudu.
Příprava dat Ve většině případů budou nezpracovaná data shromážděná ze zařízení a senzorů vyžadovat přípravu na strojové učení. Tento krok může zahrnovat vyčištění dat, přeformátování dat nebo předběžné zpracování za účelem vložení dalších informací, které strojové učení může využít.
Pro naše data z motoru letadla zahrnuje příprava dat výpočet explicitních časů do selhání pro každý datový bod ve vzorku na základě skutečných pozorování dat. Tyto informace umožňují algoritmus strojového učení najít korelace mezi skutečnými vzory dat snímačů a očekávanou zbývající dobou života modulu. Tento krok je vysoce specifický pro doménu.
Vytvoření modelu strojového učení Na základě připravených dat teď můžeme experimentovat s různými algoritmy strojového učení a parametrizací pro trénování modelů a porovnání výsledků s ostatními.
V tomto případě při testování porovnáme predikovaný výsledek vypočítaný modelem s reálným výstupem pozorovanými na sadě motorů. Ve službě Azure Machine Learning můžeme spravovat různé iterace modelů, které vytvoříme v registru modelů.
Nasaďte model. Jakmile máme model, který splňuje naše kritéria úspěchu, můžeme přejít na nasazení. To zahrnuje zabalení modelu do aplikace webové služby, která přijímá data použitím volání REST a vrací výsledky analýzy. Aplikace webové služby se pak zabalí do kontejneru Dockeru, který se pak dá nasadit buď v cloudu, nebo jako modul IoT Edge. V tomto příkladu se zaměříme na nasazení do IoT Edge.
Udržujte a upřesněte model. Naše práce nekončí po nasazení modelu. V mnoha případech chceme pokračovat ve shromažďování dat a pravidelně nahrávat tato data do cloudu. Tato data pak můžeme použít k opětovnému trénování a upřesnění modelu, který pak můžeme znovu nasadit do IoT Edge.
Uklidit zdroje
Tento kurz je součástí sady, kde každý článek vychází z práce provedené v předchozích článcích. Prosím, počkejte s vyčištěním všech prostředků, dokud nedokončíte závěrečný tutoriál.
Další kroky
Tento kurz je rozdělený do následujících částí:
- Nastavte vývojový počítač a služby Azure.
- Vygenerujte trénovací data pro modul strojového učení.
- Trénujte a nasaďte modul strojového učení.
- Nakonfigurujte zařízení IoT Edge tak, aby fungovalo jako transparentní brána.
- Vytvoření a nasazení modulů IoT Edge
- Odešlete data do zařízení IoT Edge.
Pokračujte dalším článkem a nastavte vývojový počítač a zřiďte prostředky Azure.