Provozní kontinuita a zotavení po havárii pro Azure Logic Apps
Abyste snížili dopad a účinky nepředvídatelných událostí na vaše firmy a zákazníky, ujistěte se, že máte řešení zotavení po havárii (DR), abyste mohli chránit data, rychle obnovit prostředky, které podporují důležité obchodní funkce, a udržovat provoz za účelem zachování provozní kontinuity (BC). Přerušení může například zahrnovat výpadky, ztráty v základní infrastruktuře nebo komponentách, jako je úložiště, síť nebo výpočetní prostředky, nerepravovatelné selhání aplikace nebo dokonce úplná ztráta datacentra. Díky připravenému řešení provozní kontinuity a zotavení po havárii (BCDR) může vaše organizace nebo organizace rychleji reagovat na přerušení, plánované nebo neplánované a snížit prostoje pro vaše zákazníky.
Tento článek obsahuje pokyny a strategie BCDR, které můžete použít při vytváření automatizovaných pracovních postupů pomocí Azure Logic Apps. Pracovní postupy aplikací logiky usnadňují integraci a orchestraci dat mezi aplikacemi, cloudovými službami a místními systémy snížením množství kódu, který je potřeba napsat. Při plánování BCDR se ujistěte, že zvažujete nejen aplikace logiky, ale také tyto prostředky Azure, které používáte se svými aplikacemi logiky:
Připojení , která vytvoříte z pracovních postupů aplikací logiky k jiným aplikacím, službám a systémům. Další informace najdete v tématu Připojení k prostředkům dále v tomto tématu.
Místní brány dat, které jsou prostředky Azure, které vytváříte a používáte ve svých aplikacích logiky pro přístup k datům v místních systémech. Každý prostředek brány představuje samostatnou instalaci brány dat na místním počítači. Další informace najdete v části Místní brány dat dále v tomto tématu.
Účty integrace, ve kterých definujete a ukládáte artefakty, které aplikace logiky používají pro scénáře podnikové integrace B2B (Business-to-Business). Můžete například nastavit zotavení po havárii mezi oblastmi pro účty integrace.
Prostředí integrační služby (ISE), kde vytváříte aplikace logiky, které běží v izolované instanci modulu runtime Logic Apps ve virtuální síti Azure. Tyto aplikace logiky pak můžou přistupovat k prostředkům, které jsou chráněné za bránou firewall v dané virtuální síti.
Primární a sekundární umístění
Každá aplikace logiky musí určit umístění, které chcete použít pro nasazení. Toto umístění je veřejná oblast v globální azure s více tenanty, například USA – západ, nebo prostředí integrační služby (ISE), které jste dříve vytvořili a nasadili do virtuální sítě Azure. Spouštění aplikací logiky v prostředí ISE se podobá spouštění aplikací logiky v globální oblasti Azure, což znamená, že strategie zotavení po havárii se může vztahovat na oba scénáře. IsE ale mají další aspekty, jako je konfigurace přístupu k prostředkům, které jsou dostupné jenom pro ise.
Poznámka:
Pokud vaše aplikace logiky také funguje s artefakty B2B, jako jsou obchodní partneři, smlouvy, schémata, mapy a certifikáty, které jsou uložené v účtu integrace, musí váš účet integrace i aplikace logiky zadat stejné umístění.
Tato strategie zotavení po havárii se zaměřuje na nastavení primární aplikace logiky pro převzetí služeb při selhání do pohotovostní aplikace nebo aplikace logiky zálohování v alternativním umístění, kde je k dispozici také Azure Logic Apps. Pokud tak primární dojde ke ztrátám, přerušením nebo selháním, může sekundární činnost převzít. Tato strategie vyžaduje, aby vaše sekundární aplikace logiky a závislé prostředky už byly nasazené a připravené v alternativním umístění.
Pokud postupujete podle osvědčených postupů DevOps, už k definování a nasazení aplikací logiky a jejich závislých prostředků používáte šablony Azure Resource Manageru. Šablony Resource Manageru umožňují použít jednu definici nasazení a pak pomocí souborů parametrů poskytnout hodnoty konfigurace, které se mají použít pro každý cíl nasazení. Tato funkce znamená, že můžete nasadit stejnou aplikaci logiky do různých prostředí, například do vývoje, testování a produkce. Stejnou aplikaci logiky můžete nasadit také do různých oblastí Azure nebo ises, které podporují strategie zotavení po havárii, které používají spárované oblasti.
Pro strategii převzetí služeb při selhání musí vaše aplikace logiky a umístění splňovat tyto požadavky:
Sekundární instance aplikace logiky má přístup ke stejným aplikacím, službám a systémům jako primární instance aplikace logiky.
Obě instance aplikace logiky mají stejný typ hostitele. Obě instance se tedy nasadí do oblastí v globální azure s více tenanty, nebo se obě instance nasadí do ises, které umožňují aplikacím logiky přímý přístup k prostředkům ve virtuální síti Azure. Osvědčené postupy a další informace o spárovaných oblastech pro BCDR najdete v tématu Replikace mezi oblastmi v Azure: Provozní kontinuita a zotavení po havárii.
Například primární i sekundární umístění musí být ISE, když primární aplikace logiky běží v prostředí ISE a používá konektory s verzí ISE, akce HTTP k volání prostředků ve virtuální síti Azure nebo obojí. V tomto scénáři musí mít sekundární aplikace logiky také podobné nastavení v sekundárním umístění jako primární aplikace logiky.
Poznámka:
V pokročilejších scénářích můžete kombinovat azure s více tenanty i prostředí ISE jako umístění. Ujistěte se ale, že zvažujete a rozumíte rozdílům mezi tím, jak aplikace logiky běží v prostředí ISE a v Azure s více tenanty.
Pokud používáte ise, ujistěte se, že jsou škálované nebo mají dostatečnou kapacitu pro zvládnutí zatížení.
Příklad: Azure s více tenanty
Tento příklad ukazuje primární a sekundární instance aplikace logiky, které jsou nasazené do samostatných oblastí v globální azure s více tenanty pro tento scénář. Jedna šablona Resource Manageru definuje instance aplikace logiky i závislé prostředky vyžadované těmito aplikacemi logiky. Samostatné soubory parametrů určují konfigurační hodnoty, které se mají použít pro každé umístění nasazení:
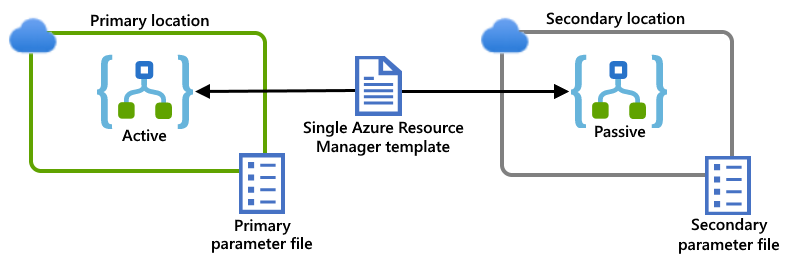
Příklad: Prostředí integrační služby
Tento příklad ukazuje předchozí primární a sekundární instance aplikace logiky, ale nasazené do samostatných isEs. Jedna šablona Resource Manageru definuje obě instance aplikace logiky, závislé prostředky vyžadované těmito aplikacemi logiky a ise jako umístění nasazení. Samostatné soubory parametrů definují konfigurační hodnoty, které se mají použít pro nasazení v každém umístění:
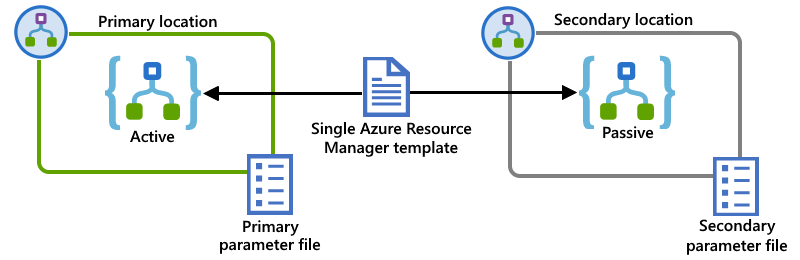
Připojení k prostředkům
Azure Logic Apps poskytuje mnoho stovek operací konektorů, které pracovní postup aplikace logiky umožňuje pracovat s jinými aplikacemi, službami, systémy a dalšími prostředky, jako jsou účty Azure Storage, databáze SQL Serveru, pracovní nebo školní e-mailové účty atd. Pokud vaše aplikace logiky potřebuje přístup k těmto prostředkům, vytvoříte připojení, která ověřují přístup k těmto prostředkům. Každé připojení je samostatný prostředek Azure, který existuje v určitém umístění a není možné ho používat v jiných umístěních.
Pro strategii zotavení po havárii zvažte umístění, kde existují závislé prostředky vzhledem k instancím aplikace logiky:
Vaše primární instance a závislé prostředky existují v různých umístěních. V takovém případě se vaše sekundární instance může připojit ke stejným závislým prostředkům nebo koncovým bodům. Měli byste ale vytvořit připojení speciálně pro vaši sekundární instanci. Pokud se tak vaše primární umístění stane nedostupným, nebudou připojení sekundárního serveru ovlivněna.
Předpokládejme například, že se vaše primární aplikace logiky připojuje k externí službě, jako je Salesforce. Dostupnost a umístění externí služby jsou obvykle nezávislé na dostupnosti vaší aplikace logiky. V takovém případě se sekundární instance může připojit ke stejné službě, ale měla by mít vlastní připojení.
Primární i závislé prostředky existují ve stejném umístění. V takovém případě by závislé prostředky měly mít zálohy nebo replikované verze v jiném umístění, aby sekundární instance měla k těmto prostředkům stále přístup.
Předpokládejme například, že se vaše primární aplikace logiky připojuje ke službě, která je ve stejném umístění nebo oblasti, například Azure SQL Database. Pokud se tato celá oblast stane nedostupnou, služba Azure SQL Database v této oblasti je pravděpodobně nedostupná. V takovém případě byste chtěli, aby sekundární instance používala replikovanou nebo záložní databázi spolu s odděleným připojením k této databázi.
Místní brány dat
Pokud vaše aplikace logiky běží v Azure s více tenanty a potřebuje přístup k místním prostředkům, jako jsou databáze SQL Serveru, musíte místní bránu dat nainstalovat na místní počítač. Potom můžete na webu Azure Portal vytvořit prostředek brány dat, aby vaše aplikace logiky při vytváření připojení k prostředku používala bránu.
Prostředek brány dat je přidružený k umístění nebo oblasti Azure, stejně jako prostředek aplikace logiky. Ve vaší strategii zotavení po havárii se ujistěte, že brána dat zůstane dostupná pro vaši aplikaci logiky, která se má použít. Vysokou dostupnost brány můžete povolit, když máte více instalací brány.
Poznámka:
Pokud vaše aplikace logiky běží v prostředí integrační služby (ISE) a používá pouze konektory isE verze pro místní zdroje dat, nepotřebujete bránu dat, protože konektory ISE poskytují přímý přístup k místnímu prostředku.
Pokud pro místní prostředek, který chcete použít, není k dispozici žádný konektor isE verze, může vaše aplikace logiky stále vytvořit připojení pomocí jiného konektoru než ISE, který běží v globální azure s více tenanty, ne ve vašem prostředí ISE. Toto připojení ale vyžaduje místní bránu dat.
Role aktivní-aktivní a aktivní-pasivní
Primární a sekundární umístění můžete nastavit tak, aby instance aplikace logiky v těchto umístěních mohly hrát tyto role:
| Primární sekundární role | Popis |
|---|---|
| Aktivní-aktivní | Instance primární a sekundární aplikace logiky v obou umístěních aktivně zpracovávají požadavky pomocí některého z těchto vzorů: - Vyrovnávání zatížení: Obě instance můžou naslouchat koncovému bodu a vyrovnávat zatížení provozu každé instance podle potřeby. - Konkurenční spotřebitelé: Obě instance mohou fungovat jako konkurenční příjemci, aby instance soutěžily o zprávy z fronty. Pokud jedna instance selže, převezme druhá instance úlohu. |
| Aktivní-pasivní | Instance primární aplikace logiky aktivně zpracovává celou úlohu, zatímco sekundární instance je pasivní (zakázaná nebo neaktivní). Sekundární čeká na signál, že primární server není dostupný nebo nefunguje kvůli přerušení nebo selhání a převezme úlohu jako aktivní instanci. |
| Kombinace | Některé aplikace logiky hrají roli aktivní-aktivní, zatímco jiné aplikace logiky hrají roli aktivní-pasivní. |
Příklady aktivní-aktivní
Tyto příklady ukazují nastavení aktivní-aktivní, kde obě instance aplikace logiky aktivně zpracovávají požadavky nebo zprávy. Některé jiné systémy nebo služby distribuují požadavky nebo zprávy mezi instance, například jednu z těchto možností:
"Fyzický" nástroj pro vyrovnávání zatížení, například kus hardwaru, který směruje provoz
"Měkký" nástroj pro vyrovnávání zatížení, jako je Azure Load Balancer nebo Azure API Management. Pomocí služby API Management můžete zadat zásady, které určují, jak vyrovnávat zatížení příchozího provozu. Nebo můžete použít službu, která podporuje sledování stavu, například Azure Service Bus.
I když tento příklad primárně ukazuje Azure Load Balancer, můžete použít možnost, která nejlépe vyhovuje potřebám vašeho scénáře:
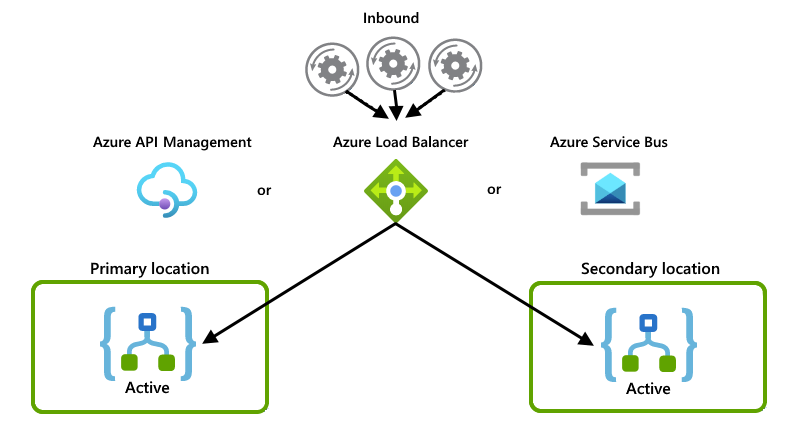
Každá instance aplikace logiky funguje jako příjemce a obě instance soutěží o zprávy z fronty:
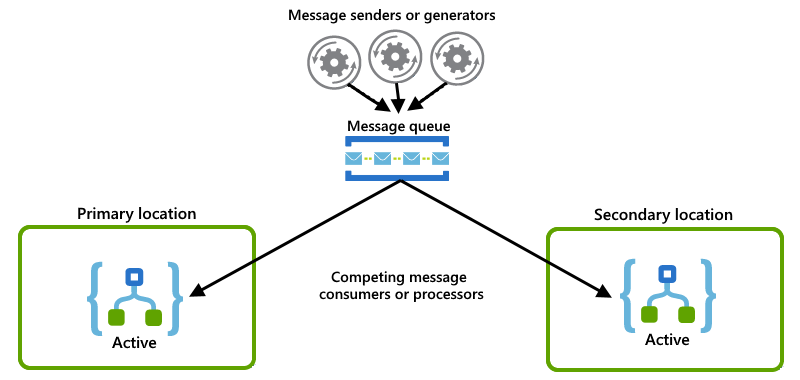
Příklady aktivní-pasivní
Tento příklad ukazuje nastavení aktivní-pasivní, kde je instance primární aplikace logiky aktivní v jednom umístění, zatímco sekundární instance zůstává neaktivní v jiném umístění. Pokud dojde k přerušení nebo selhání primárního serveru, můžete mít operátora, který spustí skript, který aktivuje sekundární, aby převzal úlohu.
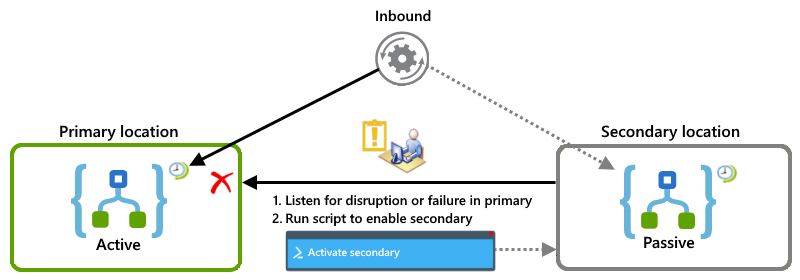
Kombinace s aktivní-aktivní a aktivní-pasivní
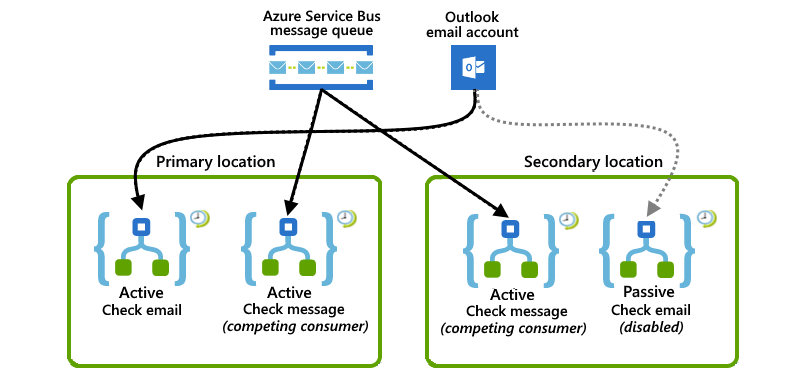
Tento příklad ukazuje kombinované nastavení, kde primární umístění má obě aktivní instance aplikace logiky, zatímco sekundární umístění má instance aplikace logiky typu aktivní-pasivní. Pokud dojde k přerušení nebo selhání primárního umístění, může aktivní aplikace logiky v sekundárním umístění, která už zpracovává částečnou úlohu, převzít celou úlohu.
V primárním umístění naslouchá aktivní aplikace logiky frontě služby Azure Service Bus pro zprávy, zatímco jiná aktivní aplikace logiky kontroluje e-maily pomocí triggeru dotazování v Office 365 Outlooku.
V sekundárním umístění pracuje aktivní aplikace logiky s aplikací logiky v primárním umístění tím, že naslouchá a konkuruje zprávům ze stejné fronty Service Bus. Pasivní neaktivní aplikace logiky mezitím čeká na pohotovostní režim, aby zkontrolovala e-maily, když primární umístění přestane být dostupné, ale je zakázané , aby se zabránilo opakovanému čtení e-mailů.
Stav a historie aplikace logiky
Když se aplikace logiky aktivuje a spustí se, stav aplikace se uloží do stejného umístění, kde se aplikace spustila a nedá se přenést do jiného umístění. Pokud dojde k selhání nebo přerušení, všechny probíhající instance pracovního postupu se opustí. Když máte nastavená primární a sekundární umístění, začnou v sekundárním umístění běžet nové instance pracovního postupu.
Omezení zrušených probíhajících instancí
Pokud chcete minimalizovat počet instancí probíhajících pracovních postupů, můžete si vybrat z různých vzorů zpráv, které můžete implementovat, například:
-
Tento podnikový vzor zpráv, který rozdělí obchodní proces do menších fází. Pro každou fázi nastavíte aplikaci logiky, která zpracovává úlohy pro danou fázi. Aplikace logiky používají k vzájemné komunikaci asynchronní protokol zasílání zpráv, jako jsou fronty nebo témata služby Azure Service Bus. Když proces rozdělíte do menších fází, snížíte počet obchodních procesů, které se můžou zaseknout na instanci aplikace logiky, která selhala. Další obecné informace o tomto modelu najdete v tématu Podnikové integrační vzory – Směrovací adresa.
Tento příklad ukazuje vzor směrovacího listu, ve kterém každá aplikace logiky představuje fázi a používá frontu Service Bus ke komunikaci s další aplikací logiky v procesu.
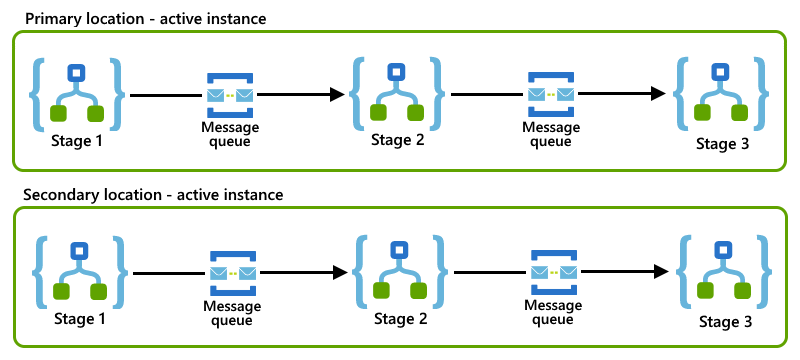
Pokud instance primární i sekundární aplikace logiky dodržují stejný vzor směrovací adresy v jejich umístěních, můžete implementovat model konkurenčních příjemců nastavením rolí aktivní-aktivní pro tyto instance.
Přístup k historii triggerů a spuštění
Pokud chcete získat další informace o minulých spuštěních pracovního postupu aplikace logiky, můžete zkontrolovat historii triggerů a spuštění aplikace. Historie spouštění aplikace logiky je uložená ve stejném umístění nebo oblasti, ve které byla aplikace logiky spuštěná, což znamená, že tuto historii nemůžete migrovat do jiného umístění. Pokud vaše primární instance převezme služby při selhání sekundární instanci, můžete přistupovat pouze k triggeru a historii spuštění jednotlivých instancí v příslušných umístěních, kde se tyto instance spustily. Informace o historii aplikace logiky ale můžete získat tak, že nastavíte aplikace logiky tak, aby odesílaly diagnostické události do pracovního prostoru Služby Azure Log Analytics. Pak můžete zkontrolovat stav a historii napříč aplikacemi logiky, které běží na několika místech.
Pokyny k typu triggeru
Typ triggeru, který používáte ve svých aplikacích logiky, určuje možnosti nastavení aplikací logiky napříč umístěními ve strategii zotavení po havárii. Tady jsou dostupné typy triggerů, které můžete použít v aplikacích logiky:
Trigger opakování
Aktivační událost Opakování je nezávislá na konkrétní službě nebo koncovém bodu a aktivuje se výhradně na základě zadaného plánu a bez dalších kritérií, například:
- Pevná frekvence a interval, například každých 10 minut
- Pokročilejší plán, například poslední pondělí každého měsíce v 17:00
Když aplikace logiky začíná triggerem Opakování, musíte nastavit primární a sekundární instance aplikace logiky s rolemi aktivní-pasivní. Chcete-li zkrátit cíl doby obnovení (RTO), který odkazuje na cílovou dobu obnovení obchodního procesu po přerušení nebo havárii, můžete nastavit instance aplikace logiky pomocí kombinace rolí aktivní-pasivní a pasivní-aktivní role. V tomto nastavení rozdělíte plán mezi umístění.
Předpokládejme například, že máte aplikaci logiky, která se musí spouštět každých 10 minut. Aplikace logiky a umístění můžete nastavit tak, aby v případě nedostupnosti primárního umístění mohly sekundární umístění převzít práci:
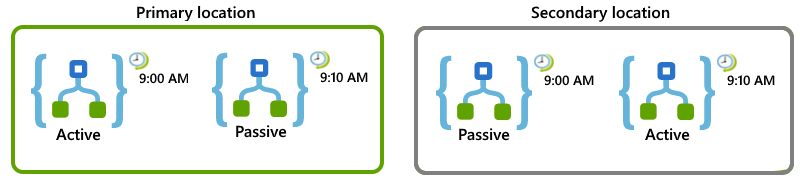
V primárním umístění nastavte role aktivní-pasivní pro tyto aplikace logiky:
U aktivní povolené aplikace logiky nastavte trigger opakování tak, aby se spustil v horní části hodiny, a opakujte každých 20 minut, například 9:00, 9:20 atd.
V případě pasivní zakázané aplikace logiky nastavte trigger opakování na stejný plán, ale zahajte 10 minut za hodinu a opakujte každých 20 minut, například 9:10, 9:30 atd.
V sekundárním umístění nastavte pasivní-aktivní pro tyto aplikace logiky:
Pro pasivní zakázanou aplikaci logiky nastavte trigger opakování na stejný plán jako aktivní aplikace logiky v primárním umístění, který je v horní části hodiny a opakuje se každých 20 minut, například 9:00, 9:10 atd.
U aktivní povolené aplikace logiky nastavte aktivační událost Opakování na stejný plán jako pasivní aplikace logiky v primárním umístění, což je zahájení v 10 minutách za hodinu a opakování každých 20 minut, například 9:10, 9:20 atd.
Pokud dojde k rušivé události v primárním umístění, aktivujte pasivní aplikaci logiky v alternativním umístění. Pokud nalezení selhání nějakou dobu trvá, omezí toto nastavení počet zmeškaných opakování během tohoto zpoždění.
Trigger dotazu
Pokud chcete pravidelně kontrolovat, jestli jsou nová data ke zpracování dostupná z konkrétní služby nebo koncového bodu, může vaše aplikace logiky použít trigger dotazování , který opakovaně volá službu nebo koncový bod na základě pevného plánu opakování. Data, která poskytuje služba nebo koncový bod, můžou mít jeden z těchto typů:
- Statická data, která popisují data, která jsou vždy k dispozici pro čtení
- Nestálá data, která popisují data, která už nejsou po přečtení k dispozici
Aby se zabránilo opakovanému čtení stejných dat, musí aplikace logiky pamatovat, která data byla dříve přečtená, a to udržováním stavu na straně klienta nebo na straně serveru, služby nebo systému.
Aplikace logiky, které pracují se stavem na straně klienta, používají triggery, které můžou udržovat stav.
Například trigger, který čte novou zprávu z doručené pošty e-mailu, vyžaduje, aby aktivační událost pamatuje naposledy přečtenou zprávu. Trigger tak spustí aplikaci logiky jenom v případě, že přijde další nepřečtená zpráva.
Aplikace logiky, které pracují se stavem serveru, služby nebo stavu na straně systému, používají hodnoty vlastností nebo nastavení, která jsou na straně serveru, služby nebo systému.
Například trigger založený na dotazu, který čte řádek z databáze, vyžaduje, aby řádek obsahuje
isReadsloupec, který je nastavený naFALSE. Pokaždé, když trigger přečte řádek, aplikace logiky aktualizuje tento řádek změnouisReadsloupce zFALSEnaTRUE.Tento přístup na straně serveru funguje podobně pro fronty služby Service Bus nebo témata, která mají sémantiku front, kde trigger může číst a zamknout zprávu, zatímco aplikace logiky zprávu zpracuje. Po dokončení zpracování aplikace logiky trigger odstraní zprávu z fronty nebo tématu.
Z hlediska zotavení po havárii se při nastavování primárních a sekundárních instancí aplikace logiky ujistěte, že k těmto chováním přihlížete na základě toho, jestli aplikace logiky sleduje stav na straně klienta nebo na straně serveru:
U aplikace logiky, která funguje se stavem na straně klienta, se ujistěte, že aplikace logiky nečte stejnou zprávu vícekrát. Aktivní instanci aplikace logiky může mít kdykoliv jenom jedno umístění. Ujistěte se, že instance aplikace logiky v alternativním umístění je neaktivní nebo zakázaná, dokud primární instance nepřesáhne služby při selhání do alternativního umístění.
Například trigger Office 365 Outlooku udržuje stav na straně klienta a sleduje časové razítko pro naposledy přečtený e-mail, aby se zabránilo čtení duplicity.
Pro aplikaci logiky, která funguje se stavem na straně serveru, můžete nastavit instance aplikace logiky tak, aby hrály role aktivní-aktivní, kde fungují jako konkurenční příjemci nebo role aktivní-pasivní , kde alternativní instance čeká, dokud primární instance nepřesáhne služby při selhání do alternativního umístění.
Například čtení z fronty zpráv, jako je fronta služby Azure Service Bus, používá stav na straně serveru, protože služba fronty udržuje zámky u zpráv, aby ostatní klienti nemohli číst stejné zprávy.
Poznámka:
Pokud vaše aplikace logiky potřebuje číst zprávy v určitém pořadí, například z fronty Service Bus, můžete použít konkurenční vzor příjemce, ale pouze v kombinaci s relacemi služby Service Bus, která se také označuje jako sekvenční vzor konvoje. Jinak musíte nastavit instance aplikace logiky s rolemi aktivní-pasivní.
Trigger požadavku
Trigger požadavku umožňuje volání aplikace logiky z jiných aplikací, služeb a systémů a obvykle se používá k poskytování těchto funkcí:
Přímé rozhraní REST API pro vaši aplikaci logiky, které můžou volat ostatní
Pomocí triggeru požadavku například spusťte aplikaci logiky, aby ostatní aplikace logiky mohly trigger volat pomocí pracovního postupu volání – akce Logic Apps .
Webhook nebo mechanismus zpětného volání pro vaši aplikaci logiky
Způsob, jak ručně spouštět uživatelské operace nebo rutiny pro volání aplikace logiky, například pomocí skriptu PowerShellu, který provádí konkrétní úlohu
Z hlediska zotavení po havárii je aktivační událost požadavku pasivním příjemcem, protože aplikace logiky neprovádí žádnou práci a čeká, dokud některá jiná služba nebo systém trigger explicitně nevolá. Jako pasivní koncový bod můžete nastavit primární a sekundární instance těmito způsoby:
Aktivní-aktivní: Obě instance aktivně zpracovávají požadavky nebo volání. Volající nebo směrovač vyrovnává nebo distribuuje provoz mezi těmito instancemi.
Aktivní-pasivní: Pouze primární instance je aktivní a zpracovává veškerou práci, zatímco sekundární instance čeká na přerušení nebo selhání primární instance. Volající nebo směrovač určuje, kdy má být volán sekundární instance.
Jako doporučenou architekturu můžete použít Azure API Management jako proxy pro aplikace logiky, které používají triggery požadavků. API Management poskytuje integrovanou odolnost mezi oblastmi a schopnost směrovat provoz napříč několika koncovými body.
Trigger Webhooku
Trigger webhooku poskytuje vaší aplikaci logiky možnost přihlásit se k odběru služby předáním adresy URL zpětného volání této službě. Aplikace logiky pak může naslouchat a čekat, až se v daném koncovém bodu služby stane konkrétní událost. Když k události dojde, služba zavolá trigger webhooku pomocí adresy URL zpětného volání, která pak spustí aplikaci logiky. Pokud je tato možnost povolená, webhook se přihlásí k odběru služby. Pokud je tato možnost zakázaná, trigger se ze služby odhlásí.
Z hlediska zotavení po havárii nastavte primární a sekundární instance, které používají triggery webhooku k přehrávání rolí aktivní-pasivní, protože z odebíraného koncového bodu by měly přijímat události nebo zprávy pouze jedna instance.
Posouzení stavu primární instance
Aby vaše strategie zotavení po havárii fungovala, potřebuje vaše řešení způsoby, jak provádět tyto úlohy:
- Kontrola dostupnosti primární instance
- Monitorování stavu primární instance
- Aktivace sekundární instance
Tato část popisuje jedno řešení, které můžete použít přímo nebo jako základ pro vlastní návrh. Tady je přehled vizuálu vysoké úrovně pro toto řešení:
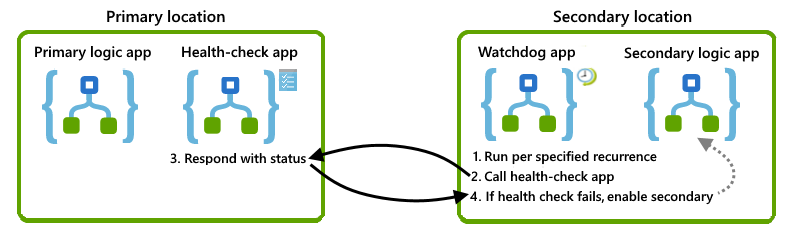
Kontrola dostupnosti primární instance
Pokud chcete zjistit, jestli je primární instance dostupná, spuštěná a schopná pracovat, můžete vytvořit aplikaci logiky kontroly stavu, která je ve stejném umístění jako primární instance. Tuto aplikaci kontroly stavu pak můžete volat z alternativního umístění. Pokud aplikace pro kontrolu stavu úspěšně reaguje, je základní infrastruktura služby Azure Logic Apps v této oblasti dostupná a funkční. Pokud aplikace pro kontrolu stavu nereaguje, můžete předpokládat, že umístění už není v pořádku.
Pro tuto úlohu vytvořte základní aplikaci logiky kontroly stavu, která provádí tyto úlohy:
Přijme volání z aplikace watchdog pomocí triggeru požadavku.
Reagujte se stavem, který označuje, jestli zaškrtnutá aplikace logiky stále funguje pomocí akce Odpověď.
Důležité
Aplikace logiky kontroly stavu musí používat akci Odpovědi, aby aplikace reagovala synchronně, ne asynchronně.
Pokud chcete dále zjistit, jestli je primární umístění v pořádku, můžete v tomto umístění využít stav všech ostatních služeb, které komunikují s cílovou aplikací logiky. Stačí rozbalit aplikaci logiky kontroly stavu a posoudit také stav těchto dalších služeb.
Vytvoření aplikace logiky watchdogu
Pokud chcete monitorovat stav primární instance a volat aplikaci logiky kontroly stavu, vytvořte aplikaci logiky "watchdog" v alternativním umístění. Aplikaci logiky watchdog můžete například nastavit tak, aby při volání logiky kontroly stavu selhala, může sledovací modul odeslat upozornění provoznímu týmu, aby mohl prošetřit selhání a proč primární instance nereaguje.
Důležité
Ujistěte se, že je vaše aplikace logiky watchdogu v umístění, které se liší od primárního umístění. Pokud u Azure Logic Apps v primárním umístění dochází k problémům, nemusí se pracovní postup aplikace logiky watchdogu spustit.
Pro tuto úlohu v sekundárním umístění vytvořte aplikaci logiky sledovacího systému, která provádí tyto úlohy:
Spuštění na základě pevného nebo plánovaného opakování pomocí triggeru Opakování.
Opakování můžete nastavit na hodnotu, která je nižší než úroveň tolerance pro cíl doby obnovení (RTO).
Pomocí akce HTTP volejte pracovní postup aplikace logiky kontroly stavu v primárním umístění.
Můžete také vytvořit sofistikovanější aplikaci logiky watchdogu, která po několika selháních volá jinou aplikaci logiky, která automaticky zpracovává přepínání do sekundárního umístění, když primární selže.
Aktivace sekundární instance
Pokud chcete sekundární instanci aktivovat automaticky, můžete vytvořit aplikaci logiky, která volá rozhraní API pro správu, jako je konektor Azure Resource Manageru, a aktivovat příslušné aplikace logiky v sekundárním umístění. Aplikaci watchdog můžete rozšířit tak, aby volala tuto aplikaci logiky aktivace, jakmile dojde k určitému počtu selhání.
Redundance zón s využitím zón dostupnosti
V každé oblasti Azure jsou zóny dostupnosti fyzicky oddělená umístění, která jsou tolerantní vůči místním selháním. Taková selhání se mohou lišit od selhání softwaru a hardwaru až po události, jako jsou zemětřesení, záplavy a požáry. Tyto zóny dosáhnou tolerance prostřednictvím redundance a logické izolace služeb Azure.
Aby byla zajištěna odolnost a distribuovaná dostupnost, existují alespoň tři samostatné zóny dostupnosti v jakékoli oblasti Azure, která podporuje a umožňuje redundanci zón. Platforma Azure Logic Apps distribuuje tyto zóny a úlohy aplikací logiky napříč těmito zónami. Tato funkce je klíčovým požadavkem na povolení odolných architektur a zajištění vysoké dostupnosti v případě selhání datacenter v určité oblasti.
V současné době je tato funkce ve verzi Preview a je dostupná pro nové aplikace logiky Consumption v konkrétních oblastech. Další informace najdete v následující dokumentaci:
- Ochrana aplikací logiky Consumption před selháními oblastí s využitím redundance zón a zón dostupnosti
- Oblasti Azure a zóny dostupnosti
Shromažďování diagnostických dat
Můžete nastavit protokolování pro spouštění aplikace logiky a odesílat výsledná diagnostická data do služeb, jako jsou Azure Storage, Azure Event Hubs a Azure Log Analytics, a provádět další zpracování a zpracování.
Pokud chcete tato data používat se službou Azure Log Analytics, můžete tato data zpřístupnit pro primární i sekundární umístění nastavením nastavení diagnostiky aplikace logiky a odesláním dat do několika pracovních prostorů služby Log Analytics. Další informace najdete v tématu Nastavení protokolů služby Azure Monitor a shromažďování diagnostických dat pro Azure Logic Apps.
Pokud chcete data odeslat do služby Azure Storage nebo azure Event Hubs, můžete data zpřístupnit pro primární i sekundární umístění nastavením geografické redundance. Další informace naleznete v těchto článcích:
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro