Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje komponentu v návrháři služby Azure Machine Learning.
Naučte se používat komponentu Vytvořit model Pythonu k vytvoření nenatrénovaného modelu ze skriptu Pythonu. Model můžete založit na libovolném learneru, který je součástí balíčku Pythonu v prostředí návrháře služby Azure Machine Learning.
Po vytvoření modelu můžete pomocí trénování modelu natrénovat model na datové sadě, stejně jako jakýkoli jiný žák ve službě Azure Machine Learning. Vytrénovaný model lze předat modelu skóre, aby bylo možné vytvářet předpovědi. Potom můžete trénovaný model uložit a publikovat pracovní postup vyhodnocování jako webovou službu.
Upozorňující
V současné době není možné tuto komponentu připojit k komponentě Tune Model Hyperparameters ani předat výsledky vyhodnoceného modelu Pythonu k vyhodnocení modelu. Pokud potřebujete vyladit hyperparametry nebo vyhodnotit model, můžete pomocí komponenty Execute Python Script napsat vlastní skript Pythonu.
Konfigurace komponenty
Použití této komponenty vyžaduje středně pokročilé nebo odborné znalosti Pythonu. Tato komponenta podporuje použití libovolného learneru, který je součástí balíčků Pythonu, které už jsou nainstalované ve službě Azure Machine Learning. Podívejte se na předinstalovaný seznam balíčků Pythonu v části Spustit skript Pythonu.
Poznámka:
Při psaní skriptu buďte velmi opatrní a ujistěte se, že nedošlo k žádné chybě syntaxe, jako je použití ne deklarovaného objektu nebo neimportované komponenty.
Poznámka:
Věnujte také zvláštní pozornost seznamu předinstalovaných komponent v příkazu Execute Python Script. Importujte pouze předinstalované součásti. Do tohoto skriptu neinstalujte další balíčky, jako je například pip install xgboost, jinak se při čtení modelů v komponentách down-streamu vygenerují chyby.
Tento článek ukazuje, jak používat vytvoření modelu Pythonu s jednoduchým kanálem. Tady je diagram kanálu:
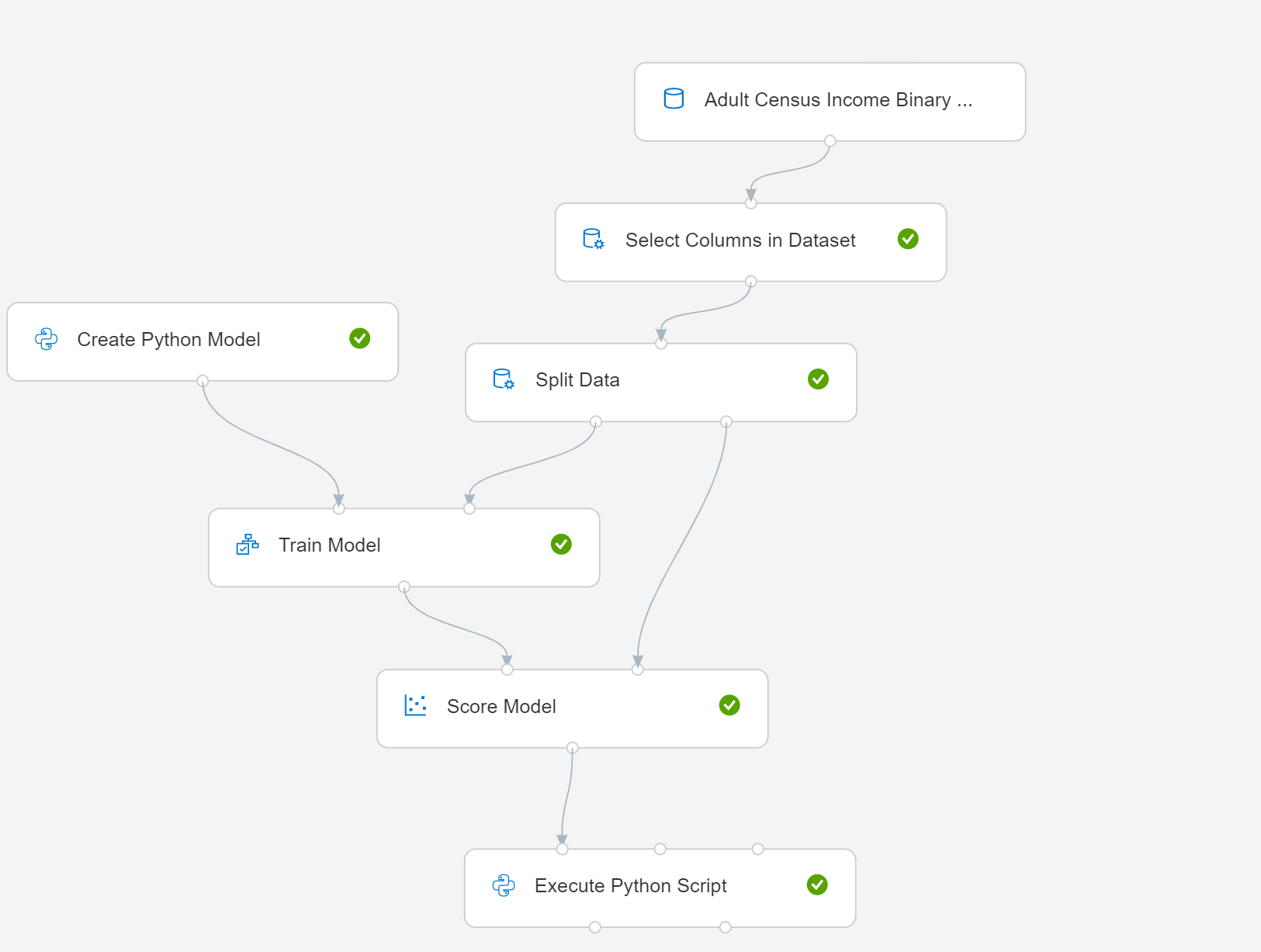
- Vyberte Vytvořit model Pythonu a upravte skript pro implementaci procesu modelování nebo správy dat. Model můžete založit na libovolném learneru, který je součástí balíčku Pythonu v prostředí Azure Machine Learning.
Poznámka:
Věnujte prosím pozornost komentářům ve vzorovém kódu skriptu a ujistěte se, že váš skript striktně dodržuje požadavek, včetně názvu třídy, metod a podpisu metody. Porušení povede k výjimkám. Vytvoření modelu Pythonu podporuje pouze vytváření modelu založeného na sklearnu, který se bude trénovat pomocí trénování modelu.
Následující ukázkový kód klasifikátoru Naive Bayes ve dvou třídách používá oblíbený balíček sklearn :
# The script MUST define a class named Azure Machine LearningModel.
# This class MUST at least define the following three methods:
# __init__: in which self.model must be assigned,
# train: which trains self.model, the two input arguments must be pandas DataFrame,
# predict: which generates prediction result, the input argument and the prediction result MUST be pandas DataFrame.
# The signatures (method names and argument names) of all these methods MUST be exactly the same as the following example.
# Please do not install extra packages such as "pip install xgboost" in this script,
# otherwise errors will be raised when reading models in down-stream components.
import pandas as pd
from sklearn.naive_bayes import GaussianNB
class AzureMLModel:
def __init__(self):
self.model = GaussianNB()
self.feature_column_names = list()
def train(self, df_train, df_label):
# self.feature_column_names records the column names used for training.
# It is recommended to set this attribute before training so that the
# feature columns used in predict and train methods have the same names.
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
def predict(self, df):
# The feature columns used for prediction MUST have the same names as the ones for training.
# The name of score column ("Scored Labels" in this case) MUST be different from any other columns in input data.
return pd.DataFrame(
{'Scored Labels': self.model.predict(df[self.feature_column_names]),
'probabilities': self.model.predict_proba(df[self.feature_column_names])[:, 1]}
)
Připojte komponentu Vytvořit model Pythonu, kterou jste právě vytvořili pro trénování modelu a určení skóre modelu.
Pokud potřebujete model vyhodnotit, přidejte komponentu Execute Python Script a upravte skript Pythonu.
Následující skript je ukázkový zkušební kód:
# The script MUST contain a function named azureml_main # which is the entry point for this component. # imports up here can be used to import pandas as pd # The entry point function MUST have two input arguments: # Param<dataframe1>: a pandas.DataFrame # Param<dataframe2>: a pandas.DataFrame def azureml_main(dataframe1 = None, dataframe2 = None): from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve import pandas as pd import numpy as np scores = dataframe1.ix[:, ("income", "Scored Labels", "probabilities")] ytrue = np.array([0 if val == '<=50K' else 1 for val in scores["income"]]) ypred = np.array([0 if val == '<=50K' else 1 for val in scores["Scored Labels"]]) probabilities = scores["probabilities"] accuracy, precision, recall, auc = \ accuracy_score(ytrue, ypred),\ precision_score(ytrue, ypred),\ recall_score(ytrue, ypred),\ roc_auc_score(ytrue, probabilities) metrics = pd.DataFrame(); metrics["Metric"] = ["Accuracy", "Precision", "Recall", "AUC"]; metrics["Value"] = [accuracy, precision, recall, auc] return metrics,
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.