Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek popisuje komponentu Execute Python Script (Spustit skript Pythonu) v návrháři služby Azure Machine Learning.
Tato komponenta slouží ke spuštění kódu Pythonu. Další informace o architektuře a principech návrhu Pythonu najdete v tom , jak spustit kód Pythonu v návrháři služby Azure Machine Learning.
V Pythonu můžete provádět úlohy, které stávající komponenty nepodporují, například:
- Vizualizace dat pomocí .
matplotlib - Použití knihoven Pythonu k vytvoření výčtu datových sad a modelů ve vašem pracovním prostoru
- Čtení, načítání a manipulace s daty ze zdrojů, které komponenta Importovat data nepodporuje.
- Spusťte vlastní kód hlubokého učení.
Podporované balíčky Pythonu
Azure Machine Learning používá distribuci Pythonu anaconda, která zahrnuje mnoho běžných nástrojů pro zpracování dat. Automaticky aktualizujeme verzi Anaconda. Aktuální verze je:
- Distribuce Anaconda pro Python 3.10
Úplný seznam najdete v části Předinstalované balíčky Pythonu.
Pokud chcete nainstalovat balíčky, které nejsou v předinstalovaném seznamu (například scikit-misc), přidejte do skriptu následující kód:
import os
os.system(f"pip install scikit-misc")
Pomocí následujícího kódu nainstalujte balíčky pro lepší výkon, zejména pro odvozování:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Poznámka:
Pokud váš kanál obsahuje více komponent spustit skript Pythonu, které potřebují balíčky, které nejsou v předinstalovaném seznamu, nainstalujte balíčky v každé komponentě.
Upozorňující
Komponenta Excute Python Script nepodporuje instalaci balíčků, které závisí na dalších nativních knihovnách s příkazem jako apt-get, jako je Java, PyODBC a atd. Důvodem je to, že tato komponenta se spouští v jednoduchém prostředí s předinstalovaným Pythonem a s oprávněním bez oprávnění správce.
Přístup k aktuálnímu pracovnímu prostoru a registrovaným datovým sadám
Pokud chcete získat přístup k registrovaným datovým sadám ve vašem pracovním prostoru, podívejte se na následující ukázkový kód:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Nahrání souborů
Komponenta Execute Python Script podporuje nahrávání souborů pomocí sady Azure Machine Learning Python SDK.
Následující příklad ukazuje, jak nahrát soubor obrázku v komponentě Execute Python Script:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Po dokončení spuštění kanálu můžete zobrazit náhled obrázku v pravém panelu komponenty.
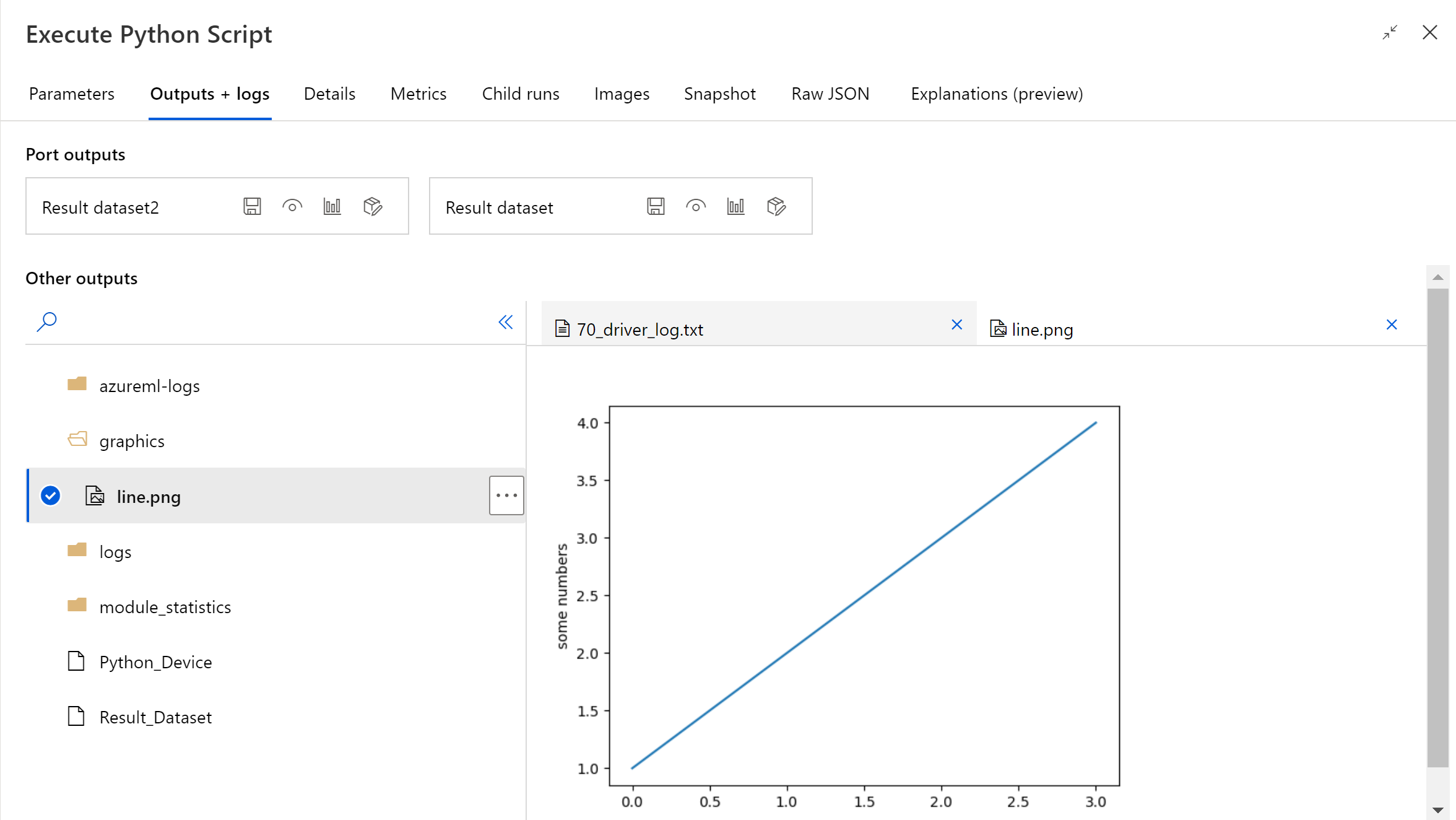
Soubor můžete také nahrát do libovolného úložiště dat pomocí následujícího kódu. Náhled souboru můžete zobrazit jenom v účtu úložiště.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Postup konfigurace spuštění skriptu Pythonu
Komponenta Execute Python Script obsahuje ukázkový kód Pythonu, který můžete použít jako výchozí bod. Pokud chcete nakonfigurovat komponentu Spustit skript Pythonu, zadejte sadu vstupů a kódu Pythonu, které se mají spustit v textovém poli skriptu Pythonu.
Přidejte do kanálu komponentu Spustit skript Pythonu .
Přidejte a připojte se k datové sadě Dataset1 z návrháře, který chcete použít pro vstup. Na tuto datovou sadu ve skriptu Pythonu můžete odkazovat jako na datový rámec DataFrame1.
Použití datové sady je volitelné. Použijte ho, pokud chcete generovat data pomocí Pythonu nebo pomocí kódu Pythonu naimportovat data přímo do komponenty.
Tato komponenta podporuje přidání druhé datové sady v datové sadě Dataset2. Na druhou datovou sadu ve skriptu Pythonu můžete odkazovat jako na datový rámec DataFrame2.
Datové sady uložené ve službě Azure Machine Learning se při načtení této komponenty automaticky převedou na datové rámce pandas.
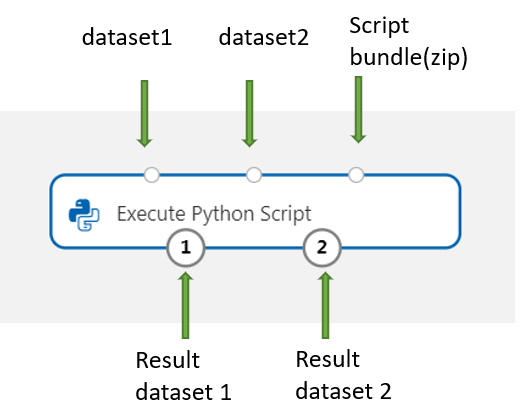
Pokud chcete zahrnout nové balíčky nebo kód Pythonu, připojte komprimovaný soubor, který obsahuje tyto vlastní prostředky, k portu sady skriptů . Nebo pokud je váš skript větší než 16 kB, použijte port Sada skriptů, abyste se vyhnuli chybám, jako je příkazový řádek, překročil limit 16597 znaků.
- Seskupte skript a další vlastní prostředky do souboru ZIP.
- Nahrajte soubor ZIP jako datovou sadu souborů do studia.
- Přetáhněte komponentu datové sady ze seznamu Datových sad v levém podokně komponent na stránce pro vytváření návrháře.
- Připojte komponentu datové sady k portu Sada skriptů komponenty Execute Python Script .
Všechny soubory obsažené v nahraném komprimovaném archivu je možné použít během provádění kanálu. Pokud archiv obsahuje adresářovou strukturu, struktura se zachová.
Důležité
Pro soubory v sadě skriptů použijte jedinečný a smysluplný název, protože některá běžná slova (například
testappatd.) jsou vyhrazená pro předdefinované služby.Následuje příklad sady skriptů, který obsahuje soubor skriptu Pythonu a soubor txt:
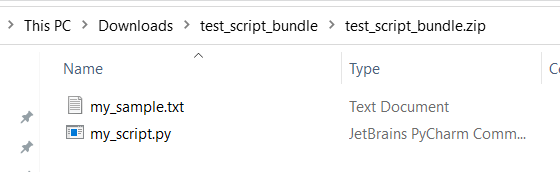
Následuje obsah
my_script.py:def my_func(dataframe1): return dataframe1Následuje ukázkový kód, který ukazuje, jak využívat soubory v sadě skriptů:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])Do textového pole skriptu Pythonu zadejte nebo vložte platný skript Pythonu.
Poznámka:
Při psaní skriptu buďte opatrní. Ujistěte se, že neexistují žádné chyby syntaxe, jako je použití nedelarovaných proměnných nebo neimportovaných součástí nebo funkcí. Věnujte zvláštní pozornost předinstalovaným seznamu komponent. Pokud chcete importovat součásti, které tu nejsou, nainstalujte do skriptu odpovídající balíčky, například:
import os os.system(f"pip install scikit-misc")Textové pole skriptu Pythonu je předem vyplněné některými pokyny v komentářích a vzorovým kódem pro přístup k datům a výstup. Tento kód musíte upravit nebo nahradit. Postupujte podle konvencí Pythonu pro odsazení a velikost velikostí:
- Skript musí obsahovat funkci pojmenovanou
azureml_mainjako vstupní bod pro tuto komponentu. - Funkce vstupního bodu musí mít dva vstupní argumenty, a
Param<dataframe1>to i v případě,Param<dataframe2>že se tyto argumenty ve skriptu nepoužívají. - Zazipované soubory připojené k třetímu vstupnímu portu se rozbalí a uloží do adresáře
.\Script Bundle, který se také přidá do Pythonusys.path.
Pokud soubor .zip obsahuje
mymodule.py, naimportujte ho pomocíimport mymodule.Dva datové sady lze vrátit návrháři, což musí být posloupnost typu
pandas.DataFrame. V kódu Pythonu můžete vytvářet další výstupy a zapisovat je přímo do úložiště Azure.Upozorňující
Nedoporučujeme se připojovat k databázi nebo jiným externím úložištím v komponentě Spustit skript Pythonu. Můžete použít komponentu Importovat data a exportovat datovou komponentu.
- Skript musí obsahovat funkci pojmenovanou
Odešlete kanál.
Pokud je komponenta dokončená, zkontrolujte výstup podle očekávání.
Pokud se komponenta nezdaří, musíte provést některé řešení potíží. Vyberte komponentu a v pravém podokně otevřete Výstupy a protokoly . Otevřete 70_driver_log.txt a vyhledejte v azureml_main a pak můžete zjistit, který řádek způsobil chybu. Například "Soubor "/tmp/tmp01_ID/user_script.py", řádek 17, v azureml_main" značí, že k chybě došlo na řádku 17 skriptu Pythonu.
Výsledky
Výsledky všech výpočtů vloženým kódem Pythonu musí být zadané jako pandas.DataFramevýsledky, které se automaticky převedou do formátu datové sady Azure Machine Learning. Výsledky pak můžete použít s dalšími komponentami v kanálu.
Komponenta vrátí dvě datové sady:
Výsledky datové sady 1 definované prvním vráceným datovým rámcem pandas ve skriptu Pythonu
Výsledná datová sada 2 definovaná druhým vráceným datovým rámcem pandas ve skriptu Pythonu
Předinstalované balíčky Pythonu
Předinstalované balíčky jsou:
- adal==1,2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1,12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- kryptografie==2,8
- cycler==0,10.0
- dill==0.3.1.1
- distro==1,4.0
- docker===4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3,8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19,9,0
- idna===2,9
- imbalanced-learn==0.4.3
- isodate==0,6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py===0.2
- jsonpickle===1.3
- jsonschema==3.0.1
- verizonsolver==1.1.0
- liac-arff==2.4.0
- lightgbm===2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1,18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0,16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2,20
- pycryptodomex==3.7.3
- pyjwt===1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0,16.0
- python-dateutil==2.8.1
- pytz===2019,3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa===4,0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy===1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1,14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0,16.1
- wheel==0,34.2
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.