Součást Import dat
Tento článek popisuje komponentu v návrháři služby Azure Machine Learning.
Tato komponenta slouží k načtení dat do kanálu strojového učení z existujících cloudových datových služeb.
Poznámka:
Všechny funkce poskytované touto komponentou je možné provádět úložištěm dat a datovými sadami na cílové stránce pracovního prostoru. Doporučujeme použít úložiště dat a datovou sadu, která zahrnuje další funkce, jako je monitorování dat. Další informace najdete v článku o přístupu k datům a postupu registrace datových sad. Po registraci datové sady ji najdete v kategorii Datové sady ->My Datasets v rozhraní návrháře. Tato komponenta je vyhrazená pro uživatele sady Studio (classic) pro známé prostředí.
Součást Import Data podporuje čtení dat z následujících zdrojů:
- Adresa URL přes PROTOKOL HTTP
- Cloudová úložiště Azure prostřednictvím úložišť dat)
- Kontejner objektů blob Azure
- Sdílená složka Azure
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL Database
- Azure PostgreSQL
Před použitím cloudového úložiště musíte nejprve zaregistrovat úložiště dat v pracovním prostoru Azure Machine Learning. Další informace naleznete v tématu Přístup k datům.
Jakmile definujete požadovaná data a připojíte se ke zdroji, importuje data datový typ každého sloupce na základě hodnot, které obsahuje, a načte data do kanálu návrháře. Výstupem importu dat je datová sada, kterou lze použít s libovolným kanálem návrháře.
Pokud se zdrojová data změní, můžete datovou sadu aktualizovat a přidat nová data opětovným spuštěním importu dat.
Upozorňující
Pokud je váš pracovní prostor ve virtuální síti, musíte úložiště dat nakonfigurovat tak, aby používaly funkce vizualizace dat návrháře. Další informace o používání úložišť dat a datových sad ve virtuální síti najdete v tématu Použití studio Azure Machine Learning ve virtuální síti Azure.
Postup konfigurace importu dat
Přidejte do kanálu komponentu Importovat data . Tuto komponentu najdete v kategorii Vstup a výstup dat v návrháři.
Výběrem komponenty otevřete pravé podokno.
Vyberte Zdroj dat a zvolte typ zdroje dat. Může to být HTTP nebo úložiště dat.
Pokud zvolíte úložiště dat, můžete vybrat existující úložiště dat, která jsou už zaregistrovaná v pracovním prostoru Služby Azure Machine Learning, nebo vytvořit nové úložiště dat. Pak definujte cestu k datům, která chcete importovat do úložiště dat. Cestu můžete snadno procházet výběrem možnosti Procházet cestu.
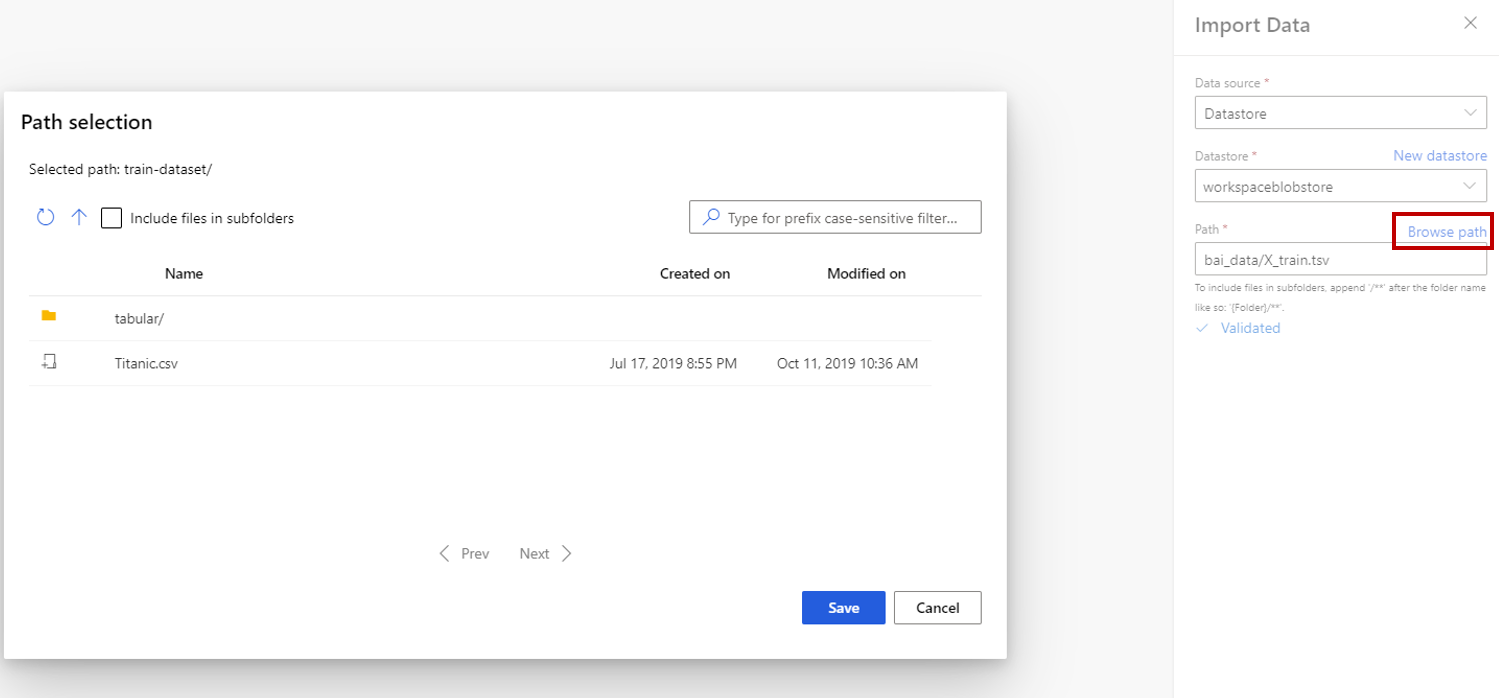
Poznámka:
Součást Import Data je určená pouze pro tabulková data. Pokud chcete importovat více tabulkových datových souborů jednou, vyžaduje následující podmínky, jinak dojde k chybám:
- Pokud chcete do složky zahrnout všechny datové soubory, musíte zadat
folder_name/**cestu. - Všechny datové soubory musí být kódovány v kódování unicode-8.
- Všechny datové soubory musí mít stejná čísla sloupců a názvy sloupců.
- Výsledkem importu více datových souborů je zřetězení všech řádků z více souborů v pořadí.
- Pokud chcete do složky zahrnout všechny datové soubory, musíte zadat
Vyberte schéma náhledu a vyfiltrujte sloupce, které chcete zahrnout. V možnostech analýzy můžete také definovat upřesňující nastavení, jako je oddělovač.
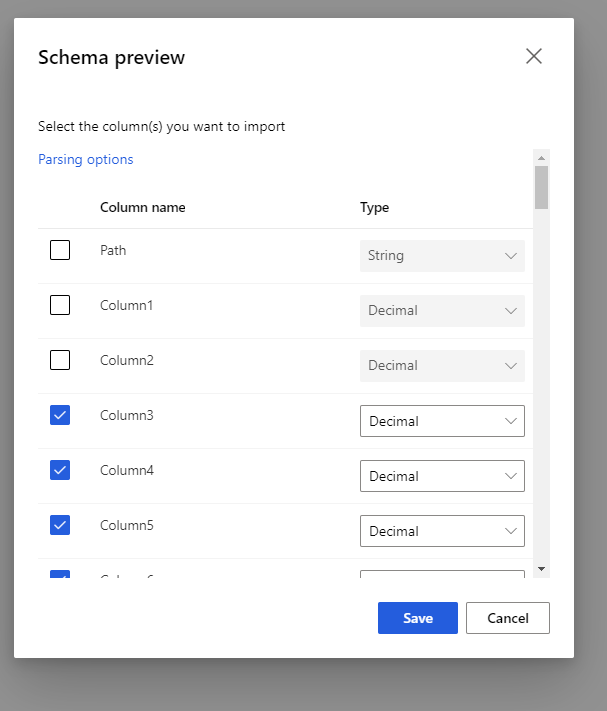
Zaškrtávací políčko Znovu vygenerovat výstup rozhoduje, zda se má komponenta spustit, aby se v době běhu znovu vygeneruje výstup.
Ve výchozím nastavení je nevybrané, což znamená, že pokud byla komponenta spuštěna se stejnými parametry dříve, systém znovu použije výstup z posledního spuštění, aby zkrátil dobu běhu.
Pokud je vybraná, systém znovu spustí komponentu, aby znovu vygenerovala výstup. Tuto možnost proto vyberte, když se podkladová data v úložišti aktualizují, může vám pomoct získat nejnovější data.
Odešlete kanál.
Při importu dat se data načtou do návrháře, odvodí datový typ každého sloupce na základě hodnot, které obsahuje, a to buď číselné, nebo kategorické.
Pokud je záhlaví k dispozici, použije se k pojmenování sloupců výstupní datové sady.
Pokud v datech nejsou žádná záhlaví sloupců, vygenerují se názvy nových sloupců pomocí sloupce ve formátu col1, col2,... , coln*.

Výsledky
Po dokončení importu klikněte pravým tlačítkem na výstupní datovou sadu a vyberte Vizualizovat , abyste zjistili, jestli se data úspěšně importovala.
Pokud chcete uložit data pro opakované použití místo importu nové sady dat při každém spuštění kanálu, vyberte ikonu Zaregistrovat datovou sadu na kartě Výstupy a protokoly v pravém panelu komponenty. Zvolte název datové sady. Uložená datová sada uchovává data v době uložení. Datová sada se při opětovném spuštění kanálu neaktualizuje, i když se datová sada v kanálu změní. To může být užitečné při pořizování snímků dat.
Po importu dat může být potřeba několik dalších příprav na modelování a analýzu:
Pomocí funkce Upravit metadata můžete změnit názvy sloupců, zpracovat sloupec jako jiný datový typ nebo označit, že některé sloupce jsou popisky nebo funkce.
Pomocí možnosti Vybrat sloupce v datové sadě vyberte podmnožinu sloupců, které chcete transformovat nebo použít při modelování. Transformované nebo odebrané sloupce se dají snadno znovu připojit k původní datové sadě pomocí komponenty Přidat sloupce .
Pomocí oddílu a ukázky rozdělte datovou sadu, proveďte vzorkování nebo získejte prvních n řádků.
Omezení
Kvůli omezení přístupu k úložišti dat se kanál odvozování obsahuje komponentu Importovat data , při nasazení do koncového bodu v reálném čase se automaticky odebere.
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.