Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO:  Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)
Automatizované strojové učení, označované také jako automatizované strojové učení nebo AutoML, automatizuje časově náročné a iterativní úlohy vývoje modelů strojového učení. Díky automatizovanému strojovému učení můžou datoví vědci, analytici a vývojáři vytvářet modely strojového učení ve velkém měřítku s efektivitou a produktivitou a současně udržovat kvalitu modelu. Automatizované strojové učení ve službě Azure Machine Learning je založeno na průlomu divize Microsoft Research.
- Pro zákazníky se zkušenostmi s kódem nainstalujte sadu Azure Machine Learning Python SDK. Začínáme s kurzem: Trénování modelu rozpoznávání objektů (Preview) pomocí AutoML a Pythonu
Jak AutoML funguje?
Během trénování azure Machine Learning vytvoří paralelně mnoho kanálů, které za vás vyzkouší různé algoritmy a parametry. Služba iteruje prostřednictvím algoritmů ML spárovaných s výběry funkcí. Každá iterace vytvoří model s trénovacím skóre. Lepší skóre metriky, kterou chcete optimalizovat, tím lépe model odpovídá vašim datům. Proces se zastaví, jakmile splní kritéria ukončení definovaná v experimentu.
Pomocí služby Azure Machine Learning můžete navrhnout a spustit experimenty automatizovaného trénování ML pomocí těchto kroků:
Identifikujte problém strojového učení, který se má vyřešit: klasifikace, prognózování, regrese, počítačové zpracování obrazu nebo NLP.
Zvolte prostředí s kódem nebo webové prostředí bez kódu: Uživatelé, kteří dávají přednost prostředí založenému na kódu, můžou používat azure Machine Learning SDKv2 nebo Azure Machine Learning CLIv2. Začínáme s kurzem: Trénování modelu rozpoznávání objektů pomocí AutoML a Pythonu Uživatelé, kteří dávají přednost omezenému prostředí nebo bez kódu, můžou webové rozhraní používat v studio Azure Machine Learning na adrese https://ml.azure.com. Začínáme s kurzem: Vytvoření klasifikačního modelu pomocí automatizovaného strojového učení ve službě Azure Machine Learning
Zadejte zdroj označených trénovacích dat: Přenesení dat do služby Azure Machine Learning mnoha různými způsoby.
Nakonfigurujte parametry automatizovaného strojového učení: Nastavte počet iterací v různých modelech, nastavení hyperparametrů, pokročilé možnosti předběžného zpracování a featurizace a metriky, které se mají vyhodnotit při určování nejlepšího modelu.
Odešlete trénovací úlohu.
Zkontrolujte výsledky.
Tento proces znázorňuje následující diagram.
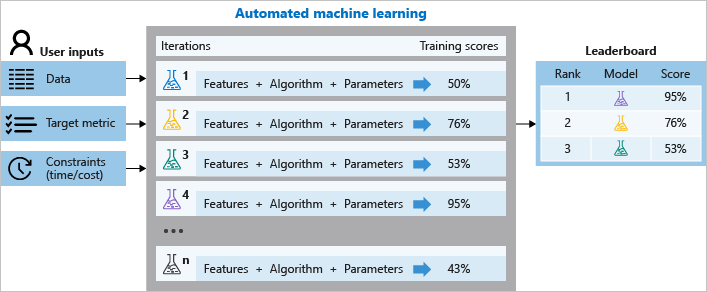
Můžete také zkontrolovat informace o protokolované úloze, které obsahují metriky shromážděné během úlohy. Trénovací úloha vytvoří serializovaný objekt Pythonu (.pkl soubor), který obsahuje předzpracování modelu a dat.
I když je sestavování modelů automatizované, můžete se také dozvědět, jak důležité nebo relevantní funkce jsou pro vygenerované modely.
Kdy použít AutoML: klasifikace, regrese, prognózování, počítačové zpracování obrazu a NLP
Použijte automatizované strojové učení, pokud chcete, aby služba Azure Machine Learning použila zadanou cílovou metrikou k trénování a ladění modelu pro vás. Automatizované strojové učení demokratizuje proces vývoje modelu strojového učení a umožňuje svým uživatelům bez ohledu na své znalosti datových věd identifikovat kompletní kanál strojového učení pro všechny problémy.
Odborníci na strojové učení a vývojáři v různých odvětvích můžou automatizované strojové učení používat k:
- Implementace řešení ML bez rozsáhlé znalosti programování
- Úspora času a prostředků
- Použití osvědčených postupů pro datové vědy
- Poskytování agilního řešení problémů
Klasifikace
Klasifikace je typ učení pod dohledem, ve kterém se modely učí používat trénovací data a aplikovat je na nová data. Azure Machine Learning nabízí extrakci příznaků speciálně pro tyto úlohy, například nástroje pro extrakci příznaků s využitím hluboké neurální sítě pro účely klasifikace. Další informace o možnostech featurizace najdete v části Featurizace dat. Seznam algoritmů podporovaných službou AutoML najdete také v podporovaných algoritmech.
Hlavním cílem klasifikačních modelů je předpovědět kategorie nových dat na základě učení z trénovacích dat. Mezi běžné příklady klasifikace patří odhalování podvodů, rozpoznávání rukopisu nebo rozpoznávání objektů.
Podívejte se na příklad klasifikace a automatizovaného strojového učení v tomto poznámkovém bloku Pythonu: Bank Marketing.
Regrese
Podobně jako klasifikace jsou regresní úlohy také běžným úkolem učení pod dohledem. Azure Machine Learning nabízí funkcionalizaci specifickou pro regresní problémy. Přečtěte si další informace o možnostech featurizace. Seznam algoritmů podporovaných službou AutoML najdete také v podporovaných algoritmech.
Liší se od klasifikace, kde predikované výstupní hodnoty jsou kategorické, regresní modely predikují číselné výstupní hodnoty na základě nezávislých prediktorů. Cílem regrese je pomoct stanovit vztah mezi proměnnými těchto nezávislých ukazatelů tím, že odhaduje, jak se jednotlivé proměnné ovlivňují. Model může například předpovědět cenu automobilů na základě funkcí, jako je například kilometry plynu a bezpečnostní hodnocení.
Podívejte se na příklad regrese a automatizovaného strojového učení pro předpovědi v těchto poznámkových blocích Pythonu: Výkon hardwaru.
Předvídání časových řad
Vytváření prognóz je nedílnou součástí každé firmy, ať už se jedná o prognózy výnosů, inventáře, prodejů nebo poptávky zákazníků. Pomocí automatizovaného strojového učení můžete kombinovat techniky a přístupy a získat doporučenou vysoce kvalitní prognózu časových řad. Seznam algoritmů podporovaných službou AutoML najdete v tématu Podporované algoritmy.
Experiment automatizované časové řady považuje problém za problém s vícevariátními regresními potížemi. Hodnoty minulých časových řad jsou "přetransformované", aby se staly více dimenzemi regresoru spolu s dalšími prediktory. Tento přístup, na rozdíl od klasických metod časových řad, má výhodu přirozeného začlenění více kontextových proměnných a jejich vztahu k sobě během trénování. Automatizované strojové učení se učí jeden, ale často interně rozvětvený model pro všechny položky v datové sadě a horizontech předpovědí. K dispozici je tedy více dat k odhadu parametrů modelu a je možné zobecnit do nezobecněných řad.
Pokročilá konfigurace prognózování zahrnuje:
- Detekce svátků a vytváření příznaků
- Časové řady a studenti DNN (Auto-ARIMA, Prorok, ForecastTCN)
- Podpora mnoha modelů prostřednictvím seskupení
- Posuvné křížové ověřování
- Konfigurovatelné prodlevy
- Agregační vlastnosti pohybujících se oken
Příklad prognózování a automatizovaného strojového učení najdete v tomto poznámkovém bloku Pythonu: Energetická poptávka.
Počítačové zpracování obrazu
Podpora úloh počítačového zpracování obrazu umožňuje snadno generovat modely natrénované na datech obrázků pro scénáře, jako je klasifikace obrázků a detekce objektů.
Díky této funkci můžete:
- Bezproblémová integrace s možností popisování dat ve službě Azure Machine Learning
- Pro generování modelů obrázků použijte označená data.
- Optimalizujte výkon modelu zadáním algoritmu modelu a laděním hyperparametrů.
- Stáhněte nebo nasaďte výsledný model jako webovou službu ve službě Azure Machine Learning.
- Zprovoznění ve velkém měřítku s využitím funkcí MlOps a ML Pipelines ve službě Azure Machine Learning
Modely AutoML pro úlohy zpracování obrazu můžete vytvářet pomocí sady Azure Machine Learning Python SDK. K výsledným úlohám experimentování, modelům a výstupům můžete přistupovat z uživatelského rozhraní nástroje Azure Machine Learning Studio.
Zjistěte, jak nastavit trénování AutoML pro modely počítačového zpracování obrazu.
 Obrázek z: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Obrázek z: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Automatizované strojové učení pro obrázky podporuje následující úlohy počítačového zpracování obrazu:
| Úkol | Popis |
|---|---|
| Klasifikace více tříd obrázků | Úkoly, ve kterých je obrázek klasifikován pouze s jedním popiskem ze sady tříd – například každý obrázek se klasifikuje jako obrázek "kočky" nebo "psa" nebo "kachny". |
| Klasifikace obrázků s více popisky | Úkoly, ve kterých může mít obrázek jeden nebo více popisků ze sady popisků – například obrázek může být označený "kočkou" i "psem". |
| Detekce objektů | Úkoly k identifikaci objektů na obrázku a vyhledání každého objektu s ohraničujícím rámečkem, například vyhledejte všechny psy a kočky na obrázku a nakreslete kolem každého ohraničujícího rámečku. |
| Segmentace instancí | Úlohy identifikace objektů na obrázku na úrovni pixelů a označení jednotlivých objektů na obrázku ohraničujícím mnohoúhelníkem |
Zpracování přirozeného jazyka: NLP
Podpora úloh zpracování přirozeného jazyka (NLP) v automatizovaném strojovém učení umožňuje snadno generovat modely natrénované na textových datech pro klasifikaci textu a scénáře rozpoznávání pojmenovaných entit. Automatizované modely NLP pro strojové učení můžete vytvářet prostřednictvím sady Azure Machine Learning Python SDK. K výsledným úlohám experimentování, modelům a výstupům můžete přistupovat z uživatelského rozhraní nástroje Azure Machine Learning Studio.
Funkce NLP podporuje:
- Kompletní trénování NLP hluboké neurální sítě s nejnovějšími předem natrénovanými modely BERT
- Bezproblémová integrace s popisky dat ve službě Azure Machine Learning
- Použití označených dat pro generování modelů NLP
- Podpora více jazyků s 104 jazyky
- Distribuované trénování s využitím Horovodu
Zjistěte, jak nastavit trénování AutoML pro modely NLP.
Trénování, ověřování a testování dat
Pomocí automatizovaného strojového učení poskytnete trénovací data pro trénování modelů ML a můžete určit, jaký typ ověření modelu se má provést. Automatizované strojové učení provádí ověření modelu jako součást trénování. To znamená, že automatizované strojové učení používá ověřovací data k ladění hyperparametrů modelu na základě použitého algoritmu k nalezení kombinace, která nejlépe vyhovuje trénovacím datům. Stejná ověřovací data se ale používají pro každou iteraci ladění, což zavádí zkreslení při vyhodnocování modelu, protože model se stále zlepšuje a přizpůsobuje se ověřovacím datům.
Aby se potvrdilo, že se taková zaujatost nevztahuje na konečný doporučený model, automatizované strojové učení podporuje použití testovacích dat k vyhodnocení konečného modelu, který na konci experimentu doporučuje. Když jako součást konfigurace experimentu AutoML zadáte testovací data, tento doporučený model se ve výchozím nastavení testuje na konci experimentu (Preview).
Důležité
Testování modelů pomocí testovací datové sady pro vyhodnocení vygenerovaných modelů je funkce preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Zjistěte, jak nakonfigurovat experimenty AutoML tak, aby používaly testovací data (Preview) se sadou SDK nebo s studio Azure Machine Learning.
Inženýrství vlastností
Příprava funkcí využívá znalosti domény dat k vytváření funkcí, které pomáhají algoritmům STROJOVÉho učení lépe se učit. V Azure Machine Learning pomáhají techniky škálování a normalizace s inženýrstvím vlastností. Souhrnně se tyto techniky a inženýrství funkcí označují jako featurizace.
U experimentů automatizovaného strojového učení se featurizace provádí automaticky, ale můžete ji také přizpůsobit na základě vašich dat. Přečtěte si další informace o tom, co je součástí funkce (SDK v1) a jak AutoML pomáhá zabránit nadměrnému přizpůsobení a nevyváženým datům ve vašich modelech.
Poznámka:
Automatizované kroky featurizace strojového učení, jako je normalizace funkcí, zpracování chybějících dat a převod textu na číselnou hodnotu, se stanou součástí základního modelu. Při použití modelu pro předpovědi se na vstupní data automaticky použijí stejné kroky featurizace použité během trénování.
Přizpůsobení featurizace
Můžete také použít jiné techniky přípravy funkcí, jako je kódování a transformace.
Povolte toto nastavení pomocí:
Azure Machine Learning Studio: Povolte Automatická tvorba funkcí v části Zobrazit další nastavenítěmito kroky.
Python SDK: Určete featurizaci v objektu úlohy AutoML. Přečtěte si další informace o povolení featurizace.
Souborové modely
Automatizované strojové učení podporuje modely souborů, které jsou ve výchozím nastavení povolené. Souborové učení zlepšuje výsledky strojového učení a prediktivní výkon kombinováním více modelů místo použití jednotlivých modelů. Iterace souboru se zobrazí jako konečné iterace vaší úlohy. Automatizované strojové učení používá pro kombinování modelů hlasovací i skládanou sadu metod:
- Hlasování: Predikuje na základě váženého průměru predikovaných pravděpodobností tříd (pro klasifikační úkoly) nebo predikovaných regresních cílů (pro regresní úkoly).
- Stacking: Kombinuje heterogenní modely a trénuje metamodel založený na výstupu jednotlivých modelů. Aktuální výchozí metamodely jsou LogisticRegression pro úlohy klasifikace a ElasticNet pro regresní a prognózovací úlohy.
Algoritmus výběru souboru Caruana s inicializací seřazeného souboru rozhoduje, které modely se mají použít v rámci souboru. Na vysoké úrovni tento algoritmus inicializuje soubor až s pěti modely s nejlepším individuálním skóre a ověří, že tyto modely jsou v rámci 5% prahové hodnoty nejlepšího skóre, aby se zabránilo špatnému počátečnímu souboru. Pak se pro každou iteraci souboru přidá nový model do existujícího souboru a výsledná skóre se vypočítá. Pokud nový model zlepší stávající skóre souboru, soubor se aktualizuje tak, aby zahrnoval nový model.
Pro informace o změně výchozího nastavení ansámblů v automatizovaném strojovém učení se podívejte na balíček AutoML.
AutoML &ONNX
Pomocí služby Azure Machine Learning můžete pomocí automatizovaného strojového učení sestavit model Pythonu a převést ho do formátu ONNX. Jakmile jsou modely ve formátu ONNX, můžete je spustit na různých platformách a zařízeních. Přečtěte si další informace o urychlení modelů ML pomocí ONNX.
V tomto příkladu poznámkového bloku Jupyter se dozvíte, jak převést na formát ONNX. Zjistěte, které algoritmy jsou podporovány v ONNX.
Modul runtime ONNX také podporuje jazyk C#, takže model vytvořený automaticky v aplikacích jazyka C# můžete používat bez nutnosti překódování nebo jakékoli latence sítě, které zavádí koncové body REST. Přečtěte si další informace o použití modelu AutoML ONNX v aplikaci .NET s ML.NET a odvozování modelů ONNX pomocí rozhraní API modulu runtime ONNX v jazyce C#.
Další kroky
K tomu, abyste mohli začít s AutoML, použijte následující zdroje.
Kurzy a články s návody
Tutoriály jsou kompletní úvodní ukázky scénářů AutoML.
Pro první zkušenosti s kódem postupujte podle kurzu: Trénování modelu rozpoznávání objektů pomocí AutoML a Pythonu.
Pro nízkokódové nebo bezkódové prostředí si přečtěte kurz: Trénování klasifikačního modelu bez kódu v prostředí AutoML ve studiu Azure Machine Learning.
Články s postupy poskytují podrobnější informace o tom, jaké funkce automatizované strojové učení nabízí. Příklad:
Konfigurace nastavení pro experimenty automatického trénování
Naučte se trénovat modely počítačového zpracování obrazu pomocí Pythonu.
Zjistěte, jak zobrazit vygenerovaný kód z automatizovaných modelů ML (SDK v1).
Ukázky poznámkového bloku Jupyter
Podrobné příklady kódu a případy použití najdete v ukázkách automatizovaného strojového učení v úložišti poznámkových bloků na GitHubu.
Referenční příručka Python SDK
Prohlubte své znalosti vzorů návrhu sady SDK a specifikací tříd pomocí referenční dokumentace ke třídě úloh AutoML.
Poznámka:
Funkce automatizovaného strojového učení jsou k dispozici také v jiných řešeních Microsoftu, jako ML.NET, HDInsight, Power BI a SQL Server.