Přehled metod prognózování v AutoML
Tento článek se zaměřuje na metody, které AutoML používá k přípravě dat časových řad a vytváření modelů prognózování. Pokyny a příklady pro trénování modelů prognóz v AutoML najdete v našem článku věnovaném nastavení AutoML pro prognózování časových řad.
AutoML používá k prognózování hodnot časových řad několik metod. Tyto metody lze zhruba přiřadit ke dvěma kategoriím:
- Modely časových řad, které používají historické hodnoty cílového množství k předpovědím do budoucnosti.
- Regrese nebo vysvětlující modely, které k prognózování hodnot cíle používají proměnné prediktoru.
Jako příklad zvažte problém prognózování denní poptávky po konkrétní značce pomerančové šťávy z obchodu s potravinami. Let $y_t$ představuje poptávku po této značce v den $t$. Model časových řad předpovídá poptávku na $t+1$ pomocí některé funkce historické poptávky.
$y_{t+1} = f(y_t, y_{t-1}, \ldots, y_{t-s})$.
Funkce $f$ má často parametry, které ladíme pomocí pozorované poptávky z minulosti. Množství historie, které $f$ používá k předpovědím, $s$, lze také považovat za parametr modelu.
Model časové řady v příkladu s oranžovou šťávou nemusí být dostatečně přesný, protože používá pouze informace o minulé poptávce. Existuje mnoho dalších faktorů, které pravděpodobně ovlivňují budoucí poptávku, jako je cena, den v týdnu, a to bez ohledu na to, jestli se jedná o dovolenou nebo ne. Zvažte regresní model, který používá tyto proměnné prediktoru.
$y = g(\text{price}, \text{day of week}, \text{holiday})$.
Opět platí, že $g$ má obecně sadu parametrů, včetně těch, které řídí regularizaci, že AutoML ladí pomocí minulých hodnot poptávky a prediktorů. Z výrazu vynecháme $t$ a zvýrazníme, že regresní model používá korelační vzory mezi souběžně definovanými proměnnými k vytváření předpovědí. To znamená, že abychom mohli předpovědět $y_{t+1}$ z $g$, musíme vědět, který den v týdnu $t+1$ spadá, zda je to dovolená, a oranžová džusová cena v den $t+1$. První dva údaje jsou vždy snadno nalezeny v kalendáři. Maloobchodní cena je obvykle nastavena předem, takže cena pomerančového džusu je pravděpodobně známa také jeden den dopředu. Nicméně, cena nemusí být známa 10 dní do budoucnosti! Je důležité si uvědomit, že nástroj této regrese je omezený tím, jak daleko do budoucnosti potřebujeme prognózy, označované také jako horizont prognózy a do jaké míry víme budoucí hodnoty prediktorů.
Důležité
Modely regrese prognózy AutoML předpokládají, že všechny funkce poskytované uživatelem jsou známé v budoucnu aspoň až do horizontu prognózy.
Modely regrese prognóz autoML je také možné rozšířit tak, aby používaly historické hodnoty cíle a prediktorů. Výsledkem je hybridní model s charakteristikami modelu časové řady a čistým regresním modelem. Historická množství jsou další proměnné prediktoru v regresi a označujeme je jako opožděné množství. Pořadí prodlevy označuje, jak daleko je hodnota známa. Například aktuální hodnota objednávky-dvě prodlevy cíle pro náš příklad pomerančové šťávy je pozorovaná poptávka od šťávy před dvěma dny.
Dalším důležitou rozdílem mezi modely časových řad a regresními modely je způsob, jakým generují prognózy. Modely časových řad jsou obecně definovány rekurzními relacemi a vytvářejí prognózy jednorázově. Pokud chcete předpovědět mnoho období do budoucnosti, iterují horizont prognózy a podle potřeby předpovídají předchozí prognózy zpět do modelu, aby vygenerovaly příští prognózu s jedním obdobím dopředu. Naproti tomu regresní modely jsou tzv . přímé prognózy , které generují všechny prognózy až do horizontu na jednom místě. Přímé prognózy můžou být vhodnější než rekurzivní, protože rekurzivní modely představují chybu složené předpovědi, když předpovídají předchozí prognózy zpět do modelu. Když jsou zahrnuty funkce prodlevy, AutoML provede některé důležité úpravy trénovacích dat, aby regresní modely mohly fungovat jako přímé prognózovací moduly. Další podrobnosti najdete v článku o funkcích prodlevy.
Modely prognózování v AutoML
Následující tabulka uvádí modely prognózy implementované v AutoML a kategorii, do které patří:
Modely v každé kategorii jsou uvedeny zhruba v pořadí složitosti vzorů, které jsou schopny začlenit, označované také jako kapacita modelu. Naivní model, který jednoduše předpovídá poslední pozorovanou hodnotu, má nízkou kapacitu, zatímco dočasná konvoluční síť (TCNForecaster), hluboké neurální sítě s potenciálně miliony tunovatelných parametrů má vysokou kapacitu.
AutoML také obsahuje souborové modely, které vytvářejí vážené kombinace modelů s nejlepším výkonem, aby se zlepšila přesnost. Pro prognózování používáme soubor s měkkým hlasováním, kde se složení a váhy nacházejí prostřednictvím Caruana Ensemble Selection Algorithm.
Poznámka:
Existují dvě důležitá upozornění pro předpovídací modelové skupiny:
- TCN nelze v současné době zahrnout do souborů.
- AutoML ve výchozím nastavení zakáže jinou metodu souboru, soubor zásobníku, který je součástí výchozí regrese a klasifikačních úloh v AutoML. Soubor zásobníku odpovídá metamodelu na nejlepší prognózy modelu k nalezení hmotnosti souboru. V interním srovnávacím testu jsme zjistili, že tato strategie má větší tendenci k datům časových řad. Výsledkem může být špatná generalizace, takže soubor zásobníku je ve výchozím nastavení zakázaný. V případě potřeby je však možné ji povolit v konfiguraci AutoML.
Jak AutoML používá vaše data
AutoML přijímá data časových řad v tabulkovém, "širokém" formátu; to znamená, že každá proměnná musí mít svůj vlastní odpovídající sloupec. AutoML vyžaduje, aby jeden ze sloupců byl časovou osou pro problém prognózy. Tento sloupec musí být parsovatelný do typu datetime. Nejjednodušší datová sada časových řad se skládá z časového sloupce a číselného cílového sloupce. Cílem je proměnná, která má v úmyslu předpovědět do budoucnosti. Následuje příklad formátu v tomto jednoduchém případě:
| časové razítko | množství. |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-02 | 97 |
| 2012-01-03 | 106 |
| ... | ... |
| 2013-12-31 | 347 |
Ve složitějších případech mohou data obsahovat další sloupce zarovnané s časovým indexem.
| časové razítko | Skladová jednotka (SKU) | price | inzerovaný | množství. |
|---|---|---|---|---|
| 2012-01-01 | JUICE1 | 3.5 | 0 | 100 |
| 2012-01-01 | BREAD3 | 5.76 | 0 | 47 |
| 2012-01-02 | JUICE1 | 3.5 | 0 | 97 |
| 2012-01-02 | BREAD3 | 5.5 | 0 | 68 |
| ... | ... | ... | ... | ... |
| 2013-12-31 | JUICE1 | 3.75 | 0 | 347 |
| 2013-12-31 | BREAD3 | 5.7 | 0 | 94 |
V tomto příkladu je skladová položka, maloobchodní cena a příznak označující, jestli byla položka inzerována kromě časového razítka a cílového množství. V této datové sadě jsou zjevně dvě řady – jedna pro skladovou položku JUICE1 a jedna pro skladovou položku BREAD3; SKU sloupec je sloupec ID časové řady, protože seskupování podle něj poskytuje dvě skupiny obsahující jednu řadu. Před úklidem modelů autoML provede základní ověření vstupní konfigurace a dat a přidá vypracované funkce.
Požadavky na délku dat
Pokud chcete vytrénovat model prognózování, musíte mít dostatek historických dat. Toto prahové množství se liší podle konfigurace trénování. Pokud jste zadali ověřovací data, minimální počet trénovacích pozorování požadovaných pro každou časnou řadu je daný:
$T_{\text{ověření uživatele}} = H + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
kde $H$ je horizont prognózy, $l_{\text{max}}$ je maximální pořadí prodlevy a $s_{\text{window}}$ je velikost okna pro kumulativní agregační funkce. Pokud používáte křížové ověření, je minimální počet pozorování:
$T_{\text{CV}} = 2H + (n_{\text{CV}} - 1) n_{\text{step}} + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
kde $n_{\text{CV}}$ je počet záhybů křížového ověření a $n_{\text{step}}$ je velikost kroku CV nebo posun mezi záhyby CV. Základní logika těchto vzorců spočívá v tom, že byste vždy měli mít alespoň horizont trénovacích pozorování pro každou časovou řadu, včetně některých odsazení prodlev a rozdělení křížového ověření. Další podrobnosti o křížové ověřování pro prognózování najdete v výběru modelu prognózy.
Chybějící zpracování dat
Modely časových řad AutoML vyžadují pravidelné řádkování pozorování v čase. V této části jsou pravidelně rozloženy případy, jako jsou měsíční nebo roční pozorování, kde se může lišit počet dní mezi pozorováními. Před modelováním musí AutoML zajistit, aby nebyly nalezeny žádné hodnoty řad a aby pozorování byla běžná. Proto existují dva případy chybějících dat:
- U některých buněk v tabulkových datech chybí hodnota.
- Chybí řádek, který odpovídá očekávanému pozorování vzhledem k frekvenci časových řad.
V prvním případě AutoML imputuje chybějící hodnoty pomocí běžných konfigurovatelných technik.
Příklad chybějícího očekávaného řádku je uvedený v následující tabulce:
| časové razítko | množství. |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-03 | 106 |
| 2012-01-04 | 103 |
| ... | ... |
| 2013-12-31 | 347 |
Tato série má zdánlivě denní frekvenci, ale pro 2. ledna 2012 neexistuje žádné pozorování. V tomto případě se AutoML pokusí vyplnit data přidáním nového řádku pro 2. ledna 2012. Nová hodnota pro quantity sloupec a všechny ostatní sloupce v datech se pak načte jako ostatní chybějící hodnoty. AutoML musí jasně znát frekvenci řad, aby bylo možné vyplnit rozdíly pozorování, jako je tato. AutoML tuto frekvenci automaticky rozpozná, případně ji uživatel může poskytnout v konfiguraci.
Metodu imputace pro vyplňování chybějících hodnot je možné nakonfigurovat ve vstupu. Výchozí metody jsou uvedeny v následující tabulce:
| Typ sloupce | Default Imputation – metoda |
|---|---|
| Cíl | Přeposlání (poslední pozorování přenesené dopředu) |
| Číselná funkce | Medián hodnoty |
Chybějící hodnoty pro kategorické funkce se zpracovávají během číselného kódování zahrnutím další kategorie odpovídající chybějící hodnotě. Imputace je v tomto případě implicitní.
Automatizované inženýrství funkcí
AutoML obecně přidává nové sloupce do uživatelských dat, aby se zvýšila přesnost modelování. Funkce navržená technikem může zahrnovat následující:
| Skupina funkcí | Výchozí nebo nepovinný |
|---|---|
| Funkce kalendáře odvozené z časového indexu (například den v týdnu) | Výchozí |
| Kategorické funkce odvozené z ID časových řad | Výchozí |
| Kódování typů kategorií na číselný typ | Výchozí |
| Indikátory pro svátky spojené s danou zemí nebo oblastí | Volitelné |
| Prodlevy cílového množství | Volitelné |
| Prodlevy sloupců funkcí | Volitelné |
| Agregace posuvného okna (například průběžný průměr) cílového množství | Volitelné |
| Sezónní rozklad (STL) | Volitelné |
Featurizace můžete nakonfigurovat ze sady AutoML SDK prostřednictvím třídy ForecastingJob nebo z webového rozhraní studio Azure Machine Learning.
Detekce a zpracování neschytných časových řad
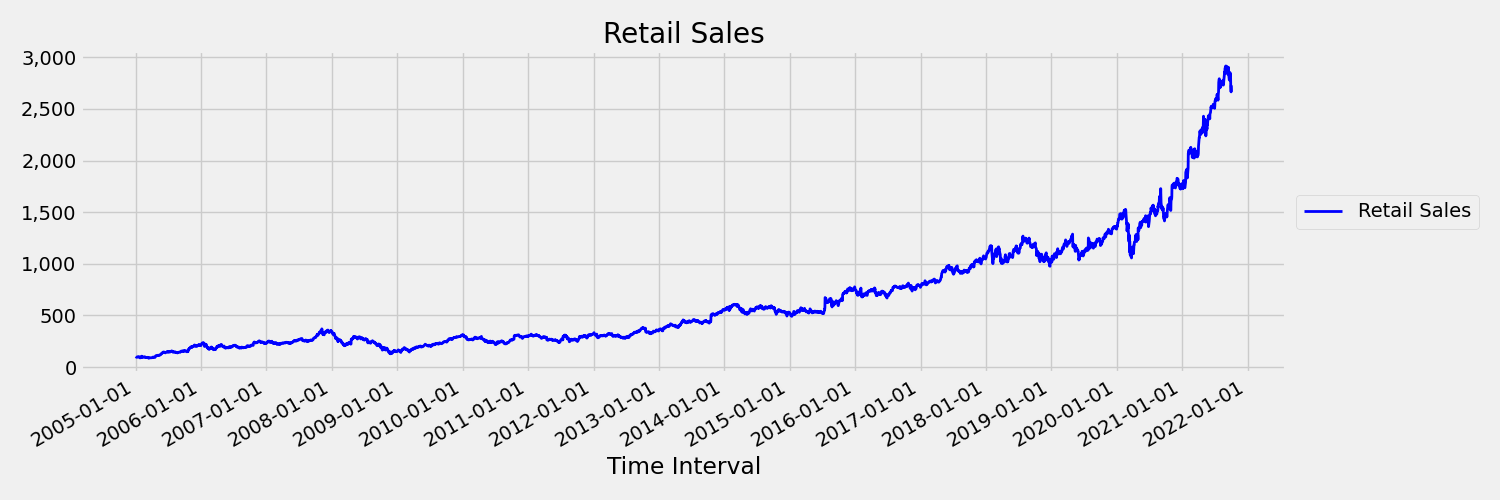
Časová řada, ve které se v průběhu času mění střední hodnota a odchylka, se nazývá neschytná. Časové řady, které vykazují stochastické trendy, jsou například neschytné přírodou. Následující obrázek znázorňuje řadu, která obvykle roste směrem nahoru. Teď vypočítá a porovná střední (průměr) hodnoty pro první a druhou polovinu řady. Jsou stejné? Zde je průměr řady v první polovině grafu výrazně menší než v druhé polovině. Skutečnost, že průměr řady závisí na časovém intervalu, na který se díváte, je příkladem časových momentů, které se liší. Tady je první okamžik průměr série.
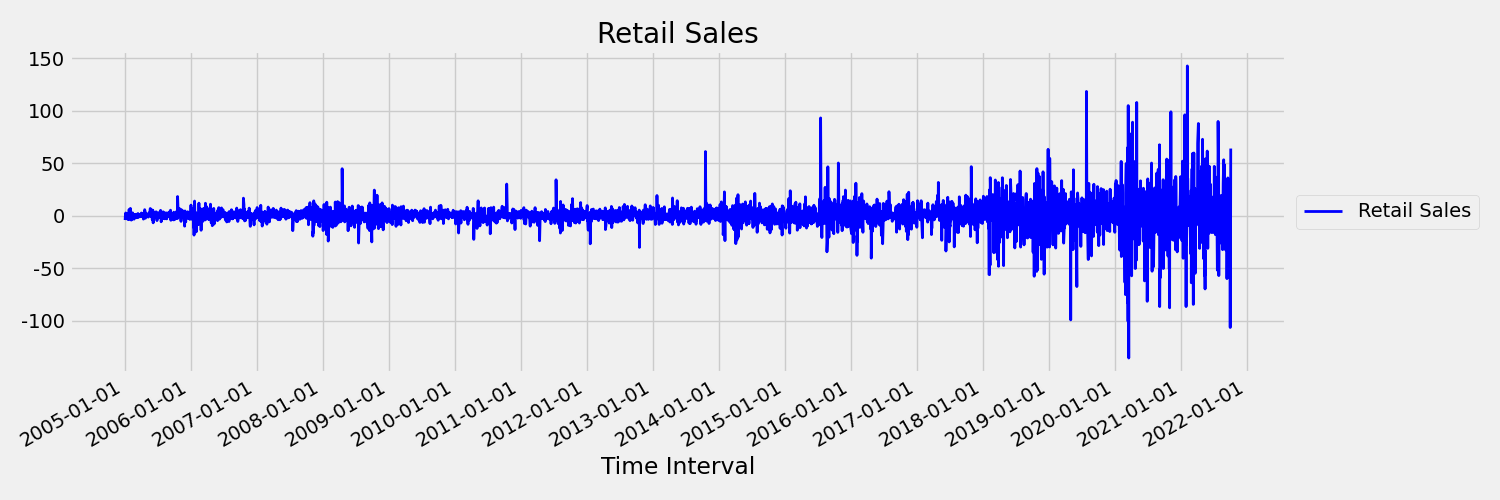
Teď se podíváme na následující obrázek, který vykreslí původní řadu v prvních rozdílech, $\Delta y_{t} = y_t – y_{t-1}$. Průměr řady je zhruba konstantní v časovém rozsahu, zatímco se rozptyl zdá být různý. Toto je tedy příklad první objednávky řady statických časů.
Modely regrese AutoML nemohou ze své podstaty řešit stochastické trendy ani jiné dobře známé problémy spojené s nestánínou časovou řadou. V důsledku toho může být přesnost předpovědí mimo výběr špatná, pokud jsou takové trendy přítomné.
AutoML automaticky analyzuje datovou sadu časových řad, aby určila staticitu. Když se zjistí nestáníná časová řada, AutoML automaticky použije rozdílovou transformaci, která zmírní dopad nestáníného chování.
Uklidování modelů
Jakmile jsou data připravená s chybějícím zpracováním dat a technikou funkcí, AutoML přemístit sadu modelů a hyperparametry pomocí služby doporučení modelu. Modely jsou seřazené na základě metrik ověření nebo křížového ověření a pak se můžou v modelu souboru použít hlavní modely. Nejlepší model nebo některý z natrénovaných modelů je možné podle potřeby zkontrolovat, stáhnout nebo nasadit, aby se vytvořily prognózy. Další podrobnosti najdete v článku o úklidu a výběru modelu.
Seskupování modelů
Pokud datová sada obsahuje více než jednu časovou řadu, jako v uvedeném příkladu dat, existují různé způsoby modelování dat. Můžeme například jednoduše seskupovat podle sloupců ID časových řad a trénovat nezávislé modely pro každou řadu. Obecnějším přístupem je rozdělení dat do skupin, které můžou obsahovat více, pravděpodobně souvisejících řad a trénování modelu na skupinu. Ve výchozím nastavení používá prognózování AutoML smíšený přístup k seskupování modelů. Modely časových řad, plus ARIMAX a Prorok, přiřazují jednu řadu k jedné skupině a další regresní modely přiřazují všechny řady k jedné skupině. Následující tabulka shrnuje seskupení modelů ve dvou kategoriích: 1:1 a M:1:
| Každá řada ve vlastní skupině (1:1) | Všechny řady v jedné skupině (N:1) |
|---|---|
| Naive, Seasonal Naive, Average, Seasonal Average, Seasonal Average, Exponential Smoothing, ARIMA, ARIMAX, Prorok | Lineární SGD, LARS LARS LASSO, Elastic Net, K Nejbližší sousedé, Rozhodovací strom, Náhodný les, Extrémně randomizované stromy, Přechodové zesílené stromy, LightGBM, XGBoost, TCNForecaster |
Obecnější seskupení modelů je možné prostřednictvím řešení M-Models autoML; podívejte se na náš poznámkový blok STROJOVÉho učení s mnoha modely– automatizované strojové učení.
Další kroky
- Další informace o modelech hlubokého učení pro prognózování v AutoML
- Přečtěte si další informace o úklidu modelů a výběru pro prognózování v AutoML.
- Přečtěte si, jak AutoML vytváří funkce z kalendáře.
- Přečtěte si, jak AutoML vytváří funkce prodlevy.
- Přečtěte si odpovědi na nejčastější dotazy týkající se prognózování v AutoML.