Nejčastější dotazy k prognózování v AutoML
PLATÍ PRO:  Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)
Tento článek odpovídá na běžné otázky týkající se prognózování v automatickém strojovém učení (AutoML). Obecné informace o metodologii prognózování v AutoML najdete v článku Přehled metod prognózování v autoML .
Návody začít vytvářet modely prognóz v AutoML?
Můžete začít tím, že si přečtete Nastavení AutoML pro trénování článku modelu prognózování časových řad. Praktické příklady najdete také v několika poznámkových blocích Jupyter:
- Příklad sdílení kol
- Prognózování s využitím hlubokého učení
- Řešení mnoha modelů
- Prognózování receptů
- Pokročilé scénáře prognózování
Proč je AutoML na mých datech pomalý?
Neustále pracujeme na rychlejším a škálovatelném autoML. Aby autoML fungovalo jako obecná platforma pro prognózování, provede rozsáhlé ověřování dat a komplexní přípravu funkcí a prohledává velký prostor modelu. Tato složitost může vyžadovat hodně času v závislosti na datech a konfiguraci.
Jedním z běžných zdrojů pomalého modulu runtime je trénování AutoML s výchozím nastavením dat, která obsahují celou řadu časových řad. Náklady na mnoho metod prognózování se škálují s počtem řad. Například metody jako Exponential Smoothing a Prorok trénují model pro každou časovou řadu v trénovacích datech.
Funkce Mnoho modelů automatického strojového učení se škáluje na tyto scénáře tím, že distribuuje trénovací úlohy napříč výpočetním clusterem. Úspěšně se použila na data s miliony časových řad. Další informace najdete v části věnované mnoha modelům . Můžete si také přečíst o úspěchu mnoha modelů v datové sadě s vysokou úrovní konkurence.
Jak můžu autoML zrychlit?
Podívejte se na článek Proč je AutoML pomalý na mých datech? Odpověď, abyste pochopili, proč může být AutoML ve vašem případě pomalé.
Zvažte následující změny konfigurace, které by mohly urychlit vaši úlohu:
- Blokovat modely časových řad, jako je ARIMA a Prorok.
- Vypněte funkce zpětného vyhledávání, jako jsou prodlevy a posuvná okna.
- Zmenšit:
- Počet pokusů/iterací.
- Vypršení časového limitu zkušební/iterace
- Časový limit experimentu
- Počet záhybů křížového ověření.
- Ujistěte se, že je povolené předčasné ukončení.
Jakou konfiguraci modelování mám použít?
Prognózování AutoML podporuje čtyři základní konfigurace:
| Konfigurace | Scénář | Výhody | Nevýhody |
|---|---|---|---|
| Výchozí autoML | Doporučuje se, pokud datová sada obsahuje malý počet časových řad, které mají zhruba podobné historické chování. | – Jednoduchá konfigurace z kódu nebo sady SDK nebo studio Azure Machine Learning. – AutoML se může učit v různých časových řadách, protože regresní modely jsou ve trénování společně všechny řady. Další informace najdete v tématu Seskupování modelů. |
– Regresní modely můžou být méně přesné, pokud časové řady v trénovacích datech mají odlišné chování. – Trénování modelů časových řad může trvat delší dobu, pokud trénovací data mají velký počet řad. Další informace najdete v tématu Proč je autoML pomalé na mých datech? Odpověď. |
| AutoML s hloubkovým učením | Doporučeno pro datové sady s více než 1 000 pozorováními a potenciálně mnoha časovými řadami, které vykazují složité vzory. Když je povolená, AutoML během trénování přemísťuje dočasné konvoluční modely neurální sítě (TCN). Další informace najdete v tématu Povolení hlubokého učení. | – Jednoduchá konfigurace z kódu nebo sady SDK nebo studio Azure Machine Learning. - Příležitosti pro křížové učení, protože TCN data jsou ve všech řadách. - Potenciálně vyšší přesnost z důvodu velké kapacity modelů hluboké neurální sítě (DNN). Další informace najdete v tématu Prognózování modelů v AutoML. |
– Trénování může trvat mnohem déle kvůli složitosti modelů DNN. - Řada s malým množstvím historie není pravděpodobné, že by z těchto modelů mohly těžit. |
| Mnoho modelů | Doporučuje se, pokud potřebujete trénovat a spravovat velký počet modelů prognózování škálovatelným způsobem. Další informace najdete v části věnované mnoha modelům . | -Škálovatelný. - Potenciálně vyšší přesnost v případě, že časová řada má odlišné chování mezi sebou. |
- Žádné učení napříč časovými řadami. – Z studio Azure Machine Learning nemůžete konfigurovat ani spouštět úlohy mnoha modelů. Aktuálně je k dispozici pouze kód nebo prostředí sady SDK. |
| Hierarchická časová řada (HTS) | Doporučuje se, pokud mají řady ve vašich datech vnořenou, hierarchickou strukturu a potřebujete vytrénovat nebo vytvářet prognózy na agregovaných úrovních hierarchie. Další informace najdete v části článku o prognózování hierarchických časových řad. | – Trénování na agregovaných úrovních může snížit šum v časových řadách uzlů typu list a potenciálně vést k modelům s vyšší přesností. – Prognózy pro libovolnou úroveň hierarchie můžete načíst agregací nebo rozdělením prognóz od úrovně trénování. |
- Potřebujete poskytnout úroveň agregace pro trénování. AutoML momentálně nemá algoritmus pro nalezení optimální úrovně. |
Poznámka:
Pokud je hluboké učení povolené, doporučujeme používat výpočetní uzly s grafickými procesory, abyste mohli co nejlépe využít vysokou kapacitu DNN. Doba trénování může být oproti uzlům s pouze procesory mnohem rychlejší. Další informace najdete v článku o velikostech virtuálních počítačů optimalizovaných pro GPU.
Poznámka:
HTS je určen pro úlohy, ve kterých se trénování nebo predikce vyžaduje na agregovaných úrovních v hierarchii. Pro hierarchická data, která vyžadují pouze trénování a predikce uzlů typu list, použijte místo toho mnoho modelů .
Jak můžu zabránit přeurčení a úniku dat?
AutoML používá osvědčené postupy strojového učení, jako je výběr křížového ověření modelu, který snižuje řadu problémů s přeurčením. Existují však další potenciální zdroje přeurčení:
Vstupní data obsahují sloupce funkcí odvozené z cíle jednoduchým vzorcem. Například funkce, která je přesným násobkem cíle, může vést k téměř dokonalému trénovacímu skóre. Model se ale pravděpodobně nezobecní na ukázková data. Doporučujeme vám prozkoumat data před trénováním modelu a vypustit sloupce, které "unikly" cílovým informacím.
Trénovací data používají funkce, které nejsou v budoucnu známé až do horizontu prognózy. Regresní modely AutoML v současné době předpokládají, že všechny funkce jsou známé horizontem prognózy. Doporučujeme, abyste data prozkoumali před trénováním a odebrali všechny sloupce funkcí, které jsou známé jen historicky.
Mezi trénováním, ověřením nebo testovacími částmi dat existují významné strukturální rozdíly (změny režimu). Představte si například účinek epidemie COVID-19 na poptávku po téměř všech dobrých obdobích během roku 2020 a 2021. Toto je klasický příklad změny režimu. Přeurčení kvůli změně režimu je nejnáročnější problém vyřešit, protože je vysoce závislý na scénáři a může vyžadovat hluboké znalosti k identifikaci.
Jako první linie obrany se pokuste rezervovat 10 až 20 procent celkové historie pro ověřovací data nebo křížové ověření dat. Pokud je historie trénování krátká, není vždy možné si toto množství ověřovacích dat rezervovat, ale je to osvědčený postup. Další informace najdete v tématu Trénování a ověření dat.
Co to znamená, když moje trénovací úloha dosáhne dokonalého skóre ověření?
Při prohlížení metrik ověření z úlohy trénování je možné zobrazit dokonalé skóre. Perfektní skóre znamená, že prognóza a skutečné hodnoty v ověřovací sadě jsou stejné nebo téměř stejné. Máte například odmocněnou střední kvadratická chyba rovna 0,0 nebo skóre R2 1,0.
Perfektní ověřovací skóre obvykle značí, že model je vážně převlékaný, pravděpodobně kvůli úniku dat. Nejlepším samozřejmě je zkontrolovat data pro úniky a vypustit sloupce, které způsobují únik.
Co když data časových řad nemají pravidelně rozmístěná pozorování?
Modely prognóz autoML vyžadují, aby trénovací data pravidelně vysílala pozorování s ohledem na kalendář. Tento požadavek zahrnuje případy, jako jsou měsíční nebo roční pozorování, ve kterých se může lišit počet dní mezi pozorováními. Data závislá na čase nemusí splňovat tento požadavek ve dvou případech:
Data mají dobře definovanou frekvenci, ale chybějící pozorování vytvářejí mezery v řadě. V tomto případě se AutoML pokusí zjistit frekvenci, vyplnit nové pozorování mezer a imputovat chybějící cílové hodnoty a hodnoty funkcí. Volitelně může uživatel nakonfigurovat metody imputace prostřednictvím nastavení sady SDK nebo webového uživatelského rozhraní. Další informace naleznete v tématu Vlastní featurizace.
Data nemají dobře definovanou frekvenci. To znamená, že doba trvání mezi pozorováními nemá rozpoznatelný vzor. Příkladem jsou transakční data, například z prodejního systému. V takovém případě můžete autoML nastavit tak, aby agregovaná data na zvolenou frekvenci. Můžete zvolit běžnou frekvenci, která nejlépe vyhovuje datům a cílům modelování. Další informace najdete v tématu Agregace dat.
Návody zvolit primární metriku?
Primární metrika je důležitá, protože její hodnota pro ověřovací data určuje nejlepší model během úklidu a výběru. Normalizované odmocněné střední kvadratické chyby (NRMSE) a normalizované střední absolutní chyby (NMAE) jsou obvykle nejlepšími volbami primární metriky v úlohách prognózování.
Pokud si chcete vybrat mezi nimi, všimněte si, že NRMSE v trénovacích datech více než NMAE penalizuje odlehlé hodnoty, protože používá druhou mocninu chyby. NMAE může být lepší volbou, pokud chcete, aby model byl méně citlivý na odlehlé hodnoty. Další informace najdete v tématu Regrese a prognózování metrik.
Poznámka:
Jako primární metriku pro prognózování nedoporučujeme použít skóre R2 nebo R2.
Poznámka:
AutoML nepodporuje vlastní ani uživatelem poskytované funkce pro primární metriku. Musíte zvolit jednu z předdefinovaných primárních metrik, které AutoML podporuje.
Jak můžu zlepšit přesnost modelu?
- Ujistěte se, že pro vaše data konfigurujete AutoML nejlépe. Další informace najdete v tématu Jakou konfiguraci modelování mám použít?
- V poznámkovém bloku s návody k prognózování najdete podrobné průvodce vytvářením a vylepšováním modelů prognóz.
- Vyhodnoťte model pomocí zpětných testů v několika cyklech prognózy. Tento postup poskytuje robustnější odhad prognózování chyby a poskytuje základní hodnoty pro měření vylepšení. Příklad najdete v poznámkovém bloku back-testing.
- Pokud jsou data hlučná, zvažte agregaci na přibližnou frekvenci, aby se zvýšil poměr signálu k šumu. Další informace najdete v tématu Četnost a agregace cílových dat.
- Přidejte nové funkce, které můžou pomoct předpovědět cíl. Odborné znalosti předmětu vám můžou pomoct při výběru trénovacích dat.
- Porovnejte hodnoty metrik ověřování a testování a určete, jestli je vybraný model nedoučením nebo přeurčením dat. Tyto znalosti vás mohou vést k lepší konfiguraci trénování. Můžete například určit, že v reakci na přeurčení potřebujete použít více křížových ověřovacích záhybů.
Vybere AutoML vždy stejný nejlepší model ze stejných trénovacích dat a konfigurace?
Proces vyhledávání modelů AutoML není deterministický, takže vždy nevybíreje stejný model ze stejných dat a konfigurace.
Návody opravit chybu nedostatku paměti?
Existují dva typy chyb paměti:
- Nedostatek paměti RAM
- Nedostatek paměti disku
Nejprve se ujistěte, že pro data konfigurujete AutoML co nejlépe. Další informace najdete v tématu Jakou konfiguraci modelování mám použít?
Pro výchozí nastavení AutoML můžete opravit chyby paměti RAM mimo paměť pomocí výpočetních uzlů s větším využitím paměti RAM. Obecně platí, že velikost volné paměti RAM by měla být alespoň 10krát větší než nezpracovaná velikost dat pro spuštění AutoML s výchozím nastavením.
Chyby nedostatku paměti disku můžete vyřešit odstraněním výpočetního clusteru a vytvořením nového clusteru.
Jaké pokročilé scénáře prognózování AutoML podporuje?
AutoML podporuje následující pokročilé scénáře předpovědi:
- Quantile forecasts
- Robustní vyhodnocení modelu prostřednictvím průběžných prognóz
- Prognózování nad rámec horizontu prognózy
- Prognózování, kdy mezi trénovacím a prognózovacím obdobím dochází k mezerám v čase
Příklady a podrobnosti najdete v poznámkovém bloku pro pokročilé scénáře prognózování.
Návody zobrazit metriky z prognózování trénovacích úloh?
Pokud chcete najít hodnoty metrik trénování a ověřování, přečtěte si informace o úlohách nebo spuštěních v sadě Studio. Metriky pro libovolný model prognózy natrénovaný v AutoML můžete zobrazit tak, že přejdete do modelu z uživatelského rozhraní úlohy AutoML v sadě Studio a vyberete kartu Metriky .
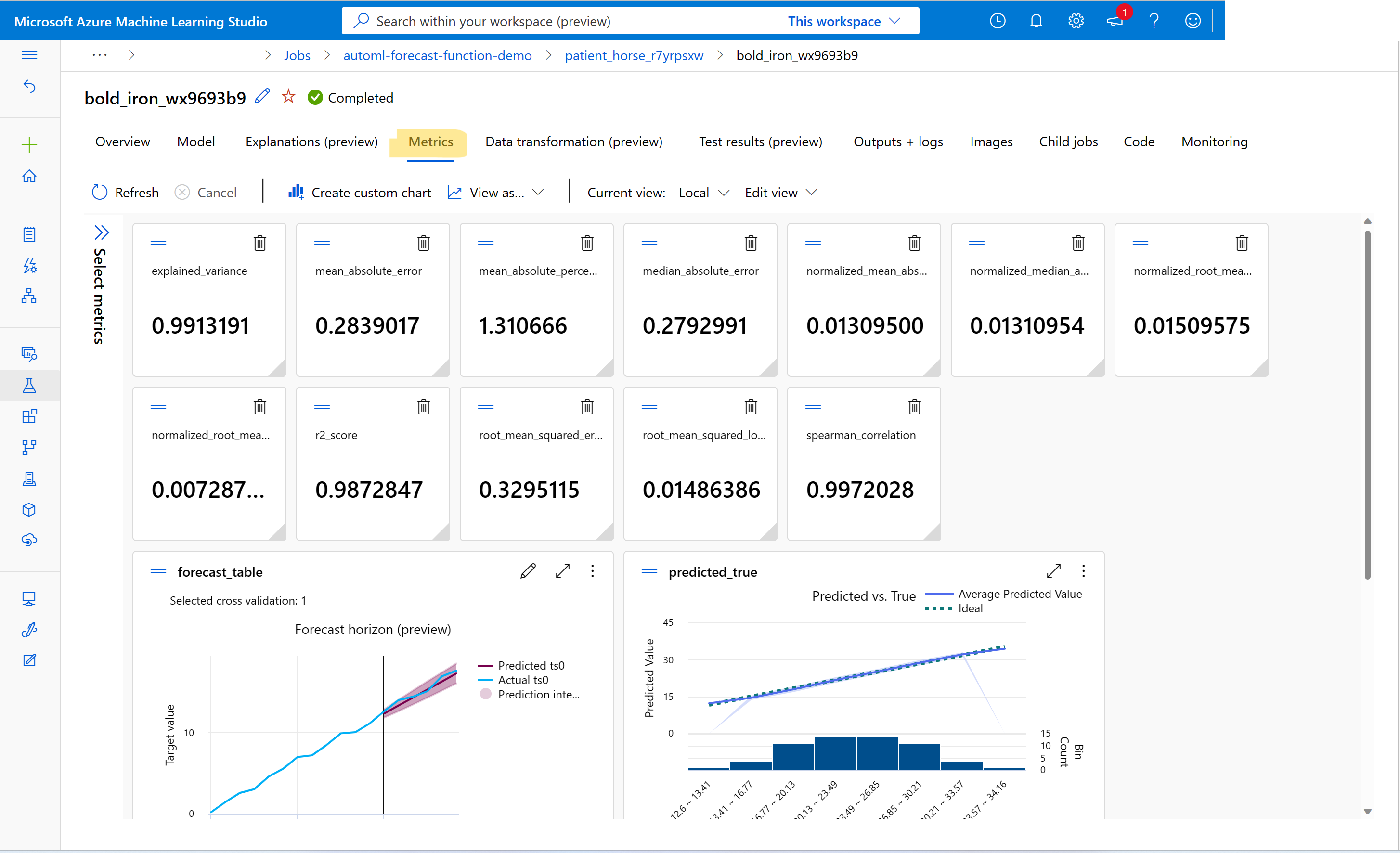
Návody selhání ladění s prognózováním trénovacích úloh?
Pokud úloha prognózování AutoML selže, může vám s diagnostikou a řešením problému pomoct chybová zpráva v uživatelském rozhraní studia. Nejlepším zdrojem informací o selhání nad rámec chybové zprávy je protokol ovladače pro úlohu. Pokyny k vyhledání protokolů ovladačů najdete v tématu Zobrazení úloh nebo spuštění informací pomocí MLflow.
Poznámka:
Pro úlohu Mnoho modelů nebo HTS je trénování obvykle na výpočetních clusterech s více uzly. Protokoly pro tyto úlohy jsou přítomné pro každou IP adresu uzlu. V takovém případě je potřeba vyhledat protokoly chyb v každém uzlu. Protokoly chyb spolu s protokoly ovladačů jsou ve složce user_logs pro každou IP adresu uzlu.
Návody nasadit model z prognózování trénovacích úloh?
Model můžete nasadit z prognózování trénovacích úloh jedním z těchto způsobů:
- Online koncový bod: Zkontrolujte soubor bodování použitý v nasazení nebo vyberte kartu Test na stránce koncového bodu v sadě Studio, abyste porozuměli struktuře vstupu, který nasazení očekává. Příklad najdete v tomto poznámkovém bloku . Další informace o online nasazení najdete v tématu Nasazení modelu AutoML do online koncového bodu.
- Koncový bod služby Batch: Tato metoda nasazení vyžaduje, abyste vytvořili vlastní bodovací skript. Příklad najdete v tomto poznámkovém bloku . Další informace o dávkovém nasazení najdete v tématu Použití dávkových koncových bodů pro dávkové vyhodnocování.
Pro nasazení uživatelského rozhraní doporučujeme použít některou z těchto možností:
- Koncový bod v reálném čase
- Koncový bod služby Batch
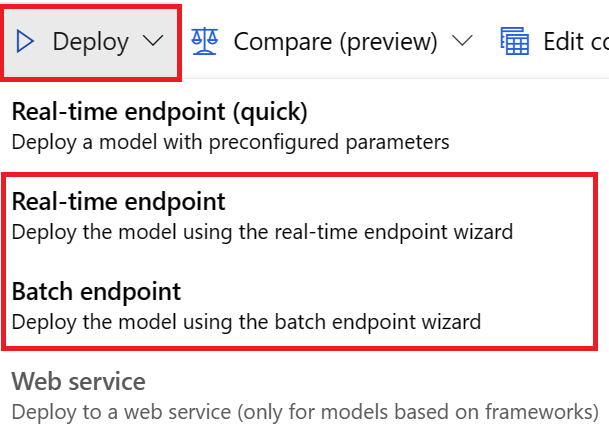
Nepoužívejte první možnost, koncový bod v reálném čase (rychlý).
Poznámka:
Odteď nepodporujeme nasazení modelu MLflow z prognózování trénovacích úloh prostřednictvím sady SDK, rozhraní příkazového řádku nebo uživatelského rozhraní. Pokud to zkusíte, zobrazí se vám chyby.
Co je pracovní prostor, prostředí, experiment, výpočetní instance nebo cíl výpočetních prostředků?
Pokud neznáte koncepty služby Azure Machine Learning, začněte s články Co je Azure Machine Learning? a Co je pracovní prostor Azure Machine Learning?
Další kroky
- Přečtěte si další informace o tom, jak nastavit AutoML pro trénování modelu prognózování časových řad.
- Seznamte se s funkcemi kalendáře pro prognózování časových řad v AutoML.
- Přečtěte si, jak AutoML používá strojové učení k vytváření modelů prognózování.
- Přečtěte si o prognózování AutoML pro opožděné funkce.