Trénování regresního modelu pomocí automatizovaného strojového učení a Pythonu (SDK v1)
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto článku se naučíte trénovat regresní model pomocí sady Azure Machine Learning Python SDK pomocí automatizovaného strojového učení Azure Machine Learning. Regresní model predikuje jízdné cestujících pro taxislužby provozující v New Yorku (NYC). Napíšete kód pomocí sady Python SDK pro konfiguraci pracovního prostoru s připravenými daty, vytrénujete model místně s vlastními parametry a prozkoumáte výsledky.
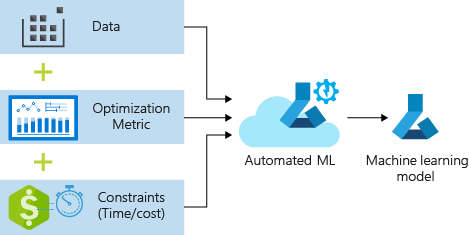
Proces přijímá trénovací data a nastavení konfigurace. Automaticky iteruje kombinacemi různých metod normalizace a standardizace funkcí, modelů a nastavení hyperparametrů, aby bylo dosaženo nejlepšího modelu. Následující diagram znázorňuje tok procesu pro trénování regresního modelu:
Požadavky
Předplatné Azure. Můžete vytvořit bezplatný nebo placený účet služby Azure Machine Learning.
Pracovní prostor nebo výpočetní instance služby Azure Machine Learning Informace o přípravě těchto prostředků najdete v tématu Rychlý start: Začínáme se službou Azure Machine Learning.
Připravte si ukázková data pro cvičení kurzu načtením poznámkového bloku do pracovního prostoru:
V studio Azure Machine Learning přejděte do svého pracovního prostoru, vyberte Poznámkové bloky a pak vyberte kartu Ukázky.
V seznamupoznámkch >>>
Vyberte poznámkový blok regrese-automated-ml.ipynb .
Pokud chcete v rámci tohoto kurzu spustit každou buňku poznámkového bloku, vyberte Klonovat tento soubor.
Alternativní přístup: Pokud chcete, můžete cvičení kurzu spustit v místním prostředí. Kurz je k dispozici v úložišti poznámkových bloků Azure Machine Learning na GitHubu. Pro tento přístup získáte požadované balíčky pomocí těchto kroků:
Spuštěním
pip install azureml-opendatasets azureml-widgetspříkazu na místním počítači získejte požadované balíčky.
Stažení a příprava dat
Balíček Open Datasets obsahuje třídu, která představuje každý zdroj dat (například NycTlcGreen) pro snadné filtrování parametrů data před stažením.
Následující kód naimportuje potřebné balíčky:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Prvním krokem je vytvoření datového rámce pro data taxislužby. Když pracujete v prostředí mimo Spark, balíček Open Datasets umožňuje stahování dat pouze jeden měsíc najednou s určitými třídami. Tento přístup pomáhá vyhnout MemoryError se problému, ke kterému může dojít u velkých datových sad.
Chcete-li stáhnout data taxislužby, iterativní načítání jeden měsíc najednou. Než k datovému green_taxi_df rámci připojíte další sadu dat, náhodně vzorek 2 000 záznamů z každého měsíce a pak zobrazí náhled dat. Tento přístup pomáhá vyhnout se haldě datového rámce.
Následující kód vytvoří datový rámec, načte data a načte je do datového rámce:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
Následující tabulka ukazuje mnoho sloupců hodnot v ukázkových datech taxislužby:
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | zlepšení Surcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 0 | 1.88 | Nic | Nic | -73.996155 | 40.690903 | -73.964287 | ... | 0 | 15.0 | 1.0 | 0.5 | 0.3 | 4,00 | 0,0 | Nic | 20.80 | 1.0 |
| 0 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 0 | 2.70 | Nic | Nic | -73.978508 | 40.687984 | -73.955116 | ... | 0 | 11.5 | 0.5 | 0.5 | 0.3 | 2.55 | 0,0 | Nic | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 0 | 3.54 | Nic | Nic | -73.957787 | 40.721779 | -73.963005 | ... | 0 | 13.5 | 0.5 | 0.5 | 0.3 | 2.80 | 0,0 | Nic | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 0 | 1.00 | Nic | Nic | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0,0 | 0.5 | 0.3 | 0,00 | 0,0 | Nic | 7.30 | 1.0 |
| 0 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 0 | 5.10 | Nic | Nic | -73.943710 | 40.825439 | -73.982964 | ... | 0 | 18.5 | 0,0 | 0.5 | 0.3 | 3.85 | 0,0 | Nic | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 0 | 7.41 | Nic | Nic | -73.940918 | 40.839714 | -73.994339 | ... | 0 | 24,0 | 0,0 | 0.5 | 0.3 | 4.80 | 0,0 | Nic | 29.60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 0 | 1,03 | Nic | Nic | -73.985718 | 40.685646 | -73.996773 | ... | 0 | 6.5 | 0,0 | 0.5 | 0.3 | 1,30 | 0,0 | Nic | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | Nic | Nic | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0,0 | 0.5 | 0.3 | 0,00 | 0,0 | Nic | 13.30 | 1.0 |
| 0 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 0 | 3.00 | Nic | Nic | -73.957939 | 40.721928 | -73.926247 | ... | 0 | 14.0 | 0.5 | 0.5 | 0.3 | 2.00 | 0,0 | Nic | 17.30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 0 | 2.31 | Nic | Nic | -73.943825 | 40.810257 | -73.943062 | ... | 0 | 10.0 | 0,0 | 0.5 | 0.3 | 2.00 | 0,0 | Nic | 12.80 | 1.0 |
Některé sloupce, které nepotřebujete pro trénování nebo vytváření dalších funkcí, je užitečné odebrat. Můžete například odebrat sloupec lpepPickupDatetime , protože automatizované strojové učení automaticky zpracovává funkce založené na čase.
Následující kód odebere z ukázkových dat 14 sloupců:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Vyčištění dat
Dalším krokem je vyčištění dat.
Následující kód spustí describe() funkci na novém datovém rámci, aby se vytvořily souhrnné statistiky pro každé pole:
green_taxi_df.describe()
Následující tabulka ukazuje souhrnné statistiky pro zbývající pole v ukázkových datech:
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 |
| znamenat | 1.777625 | 1.373625 | 2.893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| Std | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2.901199 | 1.599776 | 12.339749 |
| Min | 1,00 | 0,00 | 0,00 | -74.357101 | 0,00 | -74.342766 | 0,00 | -120.80 |
| 25% | 2.00 | 1.00 | 1.05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8,00 |
| 50% | 2.00 | 1.00 | 1.93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11.30 |
| 75% | 2.00 | 1.00 | 3.70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17.80 |
| Max | 2.00 | 8,00 | 154.28 | 0,00 | 41.109089 | 0,00 | 40.982826 | 425.00 |
Souhrnná statistika odhalí několik polí, která jsou odlehlé hodnoty, což jsou hodnoty, které snižují přesnost modelu. Pokud chcete tento problém vyřešit, vyfiltrujte pole zeměpisné šířky a délky (lat/long), aby hodnoty byly v mezích oblasti Manhattan. Tento přístup vyfiltruje delší jízdy taxíkem nebo výlety, které jsou odlehlé hodnoty vzhledem k jejich vztahu s jinými funkcemi.
Dále vyfiltrujte tripDistance pole pro hodnoty větší než nula, ale menší než 31 mil (vzdálenost haversinu mezi dvěma páry lat/long). Tato technika eliminuje dlouhé odlehlé cesty, které mají nekonzistentní náklady na cestu.
A konečně, totalAmount pole má záporné hodnoty pro jízdu taxíkem, které nedává smysl v kontextu modelu. Pole passengerCount obsahuje také chybná data, ve kterých je minimální hodnota nula.
Následující kód vyfiltruje tyto anomálie hodnot pomocí funkcí dotazu. Kód pak odebere posledních pár sloupců, které nejsou nezbytné pro trénování:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Posledním krokem v této sekvenci je opětovné volání describe() funkce na datech, aby se zajistilo, že čištění funguje podle očekávání. Teď máte připravenou a vyčištěnou sadu dat o taxi, svátku a počasí, která můžete použít pro trénování modelu strojového učení:
final_df.describe()
Konfigurace pracovního prostoru
Vytvořte objekt pracovního prostoru z existujícího pracovního prostoru. Pracovní prostor je třída, která přijímá informace o vašem předplatném a prostředcích Azure. Vytvoří také cloudový prostředek pro monitorování a sledování spuštění modelu.
Následující kód volá Workspace.from_config() funkci ke čtení souboru config.json a načtení podrobností o ověřování do objektu s názvem ws.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Objekt ws se používá ve zbytku kódu v tomto kurzu.
Rozdělení dat do trénovacích a testovacích sad
Data rozdělte na trénovací a testovací sady pomocí train_test_split funkce v knihovně scikit-learn . Tato funkce odděluje data do datové sady x (funkce) pro trénování modelu a sadu dat y (hodnoty k predikci) pro testování.
Parametr test_size určuje procento dat, která se mají přidělit k testování. Parametr random_state nastaví počáteční hodnoty náhodného generátoru tak, aby rozdělení trénovacích testů bylo deterministické.
Následující kód volá train_test_split funkci, která načte datové sady x a y:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Účelem tohoto kroku je připravit datové body k otestování hotového modelu, který se nepoužívá k trénování modelu. Tyto body se používají k měření skutečné přesnosti. Dobře natrénovaný model je model, který dokáže provádět přesné předpovědi z nezoznaných dat. Teď máte data připravená pro automatické trénování modelu strojového učení.
Automatické trénování modelu
Pokud chcete model vytrénovat automaticky, proveďte následující kroky:
Definujte nastavení pro spuštění experimentu. Připojte trénovací data ke konfiguraci a upravte nastavení, která řídí proces trénování.
Odešlete experiment pro ladění modelu. Po odeslání experimentu proces iteruje různými algoritmy strojového učení a nastavením hyperparametrů a dodržuje vaše definovaná omezení. Zvolí nejvhodnější model optimalizací metriky přesnosti.
Definování nastavení trénování
Definujte parametry experimentu a nastavení modelu pro trénování. Zobrazte úplný seznam nastavení. Odeslání experimentu s těmito výchozími nastaveními trvá přibližně 5 až 20 minut. Pokud chcete zkrátit dobu běhu, snižte experiment_timeout_hours parametr.
| Vlastnost | Hodnota v tomto kurzu | Popis |
|---|---|---|
iteration_timeout_minutes |
10 | Časový limit v minutách pro každou iteraci Zvyšte tuto hodnotu u větších datových sad, které potřebují více času pro každou iteraci. |
experiment_timeout_hours |
0.3 | Maximální doba v hodinách, kterou mohou všechny iterace zkombinovat, může trvat před ukončením experimentu. |
enable_early_stopping |
True | Příznak pro povolení předčasného ukončení, pokud se skóre v krátkodobém horizontu nezlepšuje. |
primary_metric |
spearman_correlation | Metrika, kterou chcete optimalizovat Nejvhodnější model je zvolen na základě této metriky. |
featurization |
auto | Automatická hodnota umožňuje experimentu předem zpracovat vstupní data, včetně zpracování chybějících dat, převodu textu na číselnou hodnotu atd. |
verbosity |
logging.INFO | Řídí úroveň protokolování. |
n_cross_validations |
5 | Počet rozdělení křížového ověření, které se má provést, když nejsou zadaná ověřovací data. |
Následující kód odešle experiment:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Následující kód umožňuje použít definovaná nastavení trénování jako **kwargs parametr pro AutoMLConfig objekt. Kromě toho zadáte trénovací data a typ modelu, což je regression v tomto případě.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Poznámka:
Automatizované kroky předběžného zpracování ML (normalizace funkcí, zpracování chybějících dat, převod textu na číselnou hodnotu atd.) se stanou součástí základního modelu. Při použití modelu pro předpovědi se na vstupní data automaticky použijí stejné kroky předběžného zpracování použité během trénování.
Trénování modelu automatické regrese
Vytvořte v pracovním prostoru objekt experimentu. Experiment funguje jako kontejner pro jednotlivé úlohy. Předejte definovaný automl_config objekt experimentu a nastavte výstup na Hodnotu True , aby se zobrazil průběh během úlohy.
Po spuštění experimentu se zobrazený výstup živě aktualizuje při spuštění experimentu. Pro každou iteraci uvidíte typ modelu, dobu trvání spuštění a přesnost trénování. Pole BEST sleduje nejlepší spuštěné trénovací skóre na základě vašeho typu metriky:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Tady je výstup:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Prozkoumání výsledků
Prozkoumejte výsledky automatického trénování pomocí widgetu Jupyter. Widget umožňuje zobrazit graf a tabulku všech jednotlivých iterací úloh spolu s metrikami přesnosti trénování a metadaty. Kromě toho můžete pomocí selektoru rozevíracího seznamu filtrovat různé metriky přesnosti, než je vaše primární metrika.
Následující kód vytvoří graf pro prozkoumání výsledků:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Podrobnosti o spuštění widgetu Jupyter:

Graf grafu pro widget Jupyter:

Načtení nejlepšího modelu
Následující kód umožňuje vybrat nejlepší model z iterací. Funkce get_output vrátí nejlepší běh a fitovaný model pro poslední vyvolání fitu. Pomocí přetížení funkce get_output můžete načíst nejlepší běh a fitovaný model pro všechny protokolované metriky nebo konkrétní iteraci.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Testování nejlepší přesnosti modelu
Nejlepší model použijte ke spouštění predikcí v sadě testovacích dat, abyste mohli předpovědět jízdné taxíkem. Funkce predict používá nejlepší model a předpovídá hodnoty nákladů na cestu z x_test datové sady.
Následující kód vypíše prvních 10 predikovaných hodnot nákladů ze y_predict sady dat:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
root mean squared error Výpočet výsledků y_test Převeďte datový rámec na seznam a porovnejte s predikovanými hodnotami. Funkce mean_squared_error přebírá dvě pole hodnot a vypočítá průměrnou kvadratická chybu mezi nimi. Když vezmete druhou odmocninu výsledku, zobrazí se chyba ve stejných jednotkách jako proměnná y, náklady. Udává zhruba, jak daleko jsou předpovědi jízdného taxíkem od skutečných jízdné.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Spuštěním následujícího kódu můžete vypočítat absolutní procentuální chybu (MAPE) pomocí úplných y_actual sad dat a y_predict sad dat. Tato metrika vypočítá absolutní rozdíl mezi jednotlivými predikovanými a skutečnými hodnotami a sečte všechny rozdíly. Pak tento součet vyjadřuje jako procento součtu skutečných hodnot.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Tady je výstup:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Z metrik přesnosti dvou predikcí vidíte, že model je poměrně dobrý při předpovídání jízdného taxíku od funkcí datové sady, obvykle v rozsahu +- 4,00 USD a přibližně 15 % chyby.
Tradiční proces vývoje modelů strojového učení je vysoce náročný na prostředky. K běhu a porovnání výsledků desítek modelů vyžaduje značné znalosti a časové investice do domény. Použití automatizovaného strojového učení je skvělý způsob, jak rychle otestovat mnoho různých modelů pro váš scénář.
Vyčištění prostředků
Pokud neplánujete pracovat na dalších kurzech služby Azure Machine Learning, pomocí následujících kroků odeberte prostředky, které už nepotřebujete.
Zastavení výpočetních prostředků
Pokud jste použili výpočetní prostředky, můžete virtuální počítač zastavit, když ho nepoužíváte, a snížit náklady:
V studio Azure Machine Learning přejděte do svého pracovního prostoru a vyberte Compute.
V seznamu vyberte výpočetní prostředky, které chcete zastavit, a pak vyberte Zastavit.
Až budete chtít výpočetní prostředky znovu použít, můžete virtuální počítač restartovat.
Odstranění dalších prostředků
Pokud nechcete používat prostředky, které jste vytvořili v tomto kurzu, můžete je odstranit a vyhnout se dalším poplatkům.
Pomocí následujícího postupu odeberte skupinu prostředků a všechny prostředky:
Na webu Azure Portal přejděte na stránku Skupina prostředků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili v tomto kurzu, a pak vyberte Odstranit skupinu prostředků.
V potvrzovací výzvě zadejte název skupiny prostředků a pak vyberte Odstranit.
Pokud chcete zachovat skupinu prostředků a odstranit jenom jeden pracovní prostor, postupujte takto:
Na webu Azure Portal přejděte do skupiny prostředků, která obsahuje pracovní prostor, který chcete odebrat.
Vyberte pracovní prostor, vyberte Vlastnosti a pak vyberte Odstranit.