Nastavení vývojového prostředí pomocí Azure Databricks a AutoML ve službě Azure Machine Learning
Zjistěte, jak nakonfigurovat vývojové prostředí ve službě Azure Machine Learning, které používá Azure Databricks a automatizované strojové učení.
Azure Databricks je ideální pro spouštění rozsáhlých náročných pracovních postupů strojového učení na škálovatelné platformě Apache Spark v cloudu Azure. Poskytuje prostředí založené na poznámkových blocích pro spolupráci s výpočetním clusterem založeným na procesoru nebo GPU.
Informace o dalších vývojových prostředích strojového učení najdete v tématu Nastavení vývojového prostředí Pythonu.
Požadavek
Pracovní prostor Azure Machine Learning. Pokud ho chcete vytvořit, postupujte podle kroků v článku Vytvoření prostředků pracovního prostoru .
Azure Databricks se službou Azure Machine Learning a AutoML
Azure Databricks se integruje se službou Azure Machine Learning a jeho funkcemi automatizovaného strojového učení.
Azure Databricks můžete použít:
- Trénování modelu pomocí knihovny Spark MLlib a jeho nasazení do ACI/AKS
- Funkce automatizovaného strojového učení s využitím sady Azure Machine Learning SDK
- Jako cílový výpočetní objekt z kanálu Azure Machine Learning.
Nastavení clusteru Databricks
Vytvořte cluster Databricks. Některá nastavení platí jenom v případě, že v Databricks nainstalujete sadu SDK pro automatizované strojové učení.
Vytvoření clusteru trvá několik minut.
Použijte tato nastavení:
| Nastavení | Platí pro | Hodnota |
|---|---|---|
| Název clusteru | Vždy | název_vašeho_clusteru |
| Verze modulu runtime Databricks | Vždy | 9.1 LTS |
| Python version (Verze Pythonu) | Vždy | 3 |
| Typ pracovního procesu (určuje maximální počet souběžných iterací) |
Automatizované strojové učení Pouze |
Preferovaný virtuální počítač optimalizovaný pro paměť |
| Pracovníků | Vždy | 2 nebo vyšší |
| Povolení automatického škálování | Automatizované strojové učení Pouze |
Bez zaškrtnutí |
Počkejte, až bude cluster spuštěný, a teprve pak budete pokračovat.
Přidání sady Azure Machine Learning SDK do Databricks
Jakmile je cluster spuštěný, vytvořte knihovnu pro připojení příslušného balíčku sady Azure Machine Learning SDK ke clusteru.
Pokud chcete použít automatizované strojové učení, přeskočte k části Přidání sady Azure Machine Learning SDK pomocí automatizovaného strojového učení.
Klikněte pravým tlačítkem na aktuální složku Pracovního prostoru, do které chcete knihovnu uložit. Vyberte Vytvořit>knihovnu.
Tip
Pokud máte starou verzi sady SDK, zrušte její výběr z nainstalovaných knihoven clusteru a přesuňte ji do koše. Nainstalujte novou verzi sady SDK a restartujte cluster. Pokud po restartování dojde k problému, odpojte cluster a znovu ho připojte.
Zvolte následující možnost (jiné instalace sady SDK se nepodporují).
Balíčky sdk – doplňky Zdroj Název PyPi Pro Databricks Nahrání pythonového vejce nebo PyPI azureml-sdk[databricks] Upozornění
Není možné nainstalovat žádné další doplňky sady SDK. Zvolte pouze možnost [
databricks] .- Nevybírejte možnost Připojovat automaticky ke všem clusterům.
- Vyberte Připojit vedle názvu clusteru.
Monitorujte chyby, dokud se stav nezmění na Připojeno, což může trvat několik minut. Pokud tento krok selže:
Zkuste cluster restartovat pomocí:
- V levém podokně vyberte Clustery.
- V tabulce vyberte název clusteru.
- Na kartě Knihovny vyberte Restartovat.
Úspěšná instalace vypadá takto:
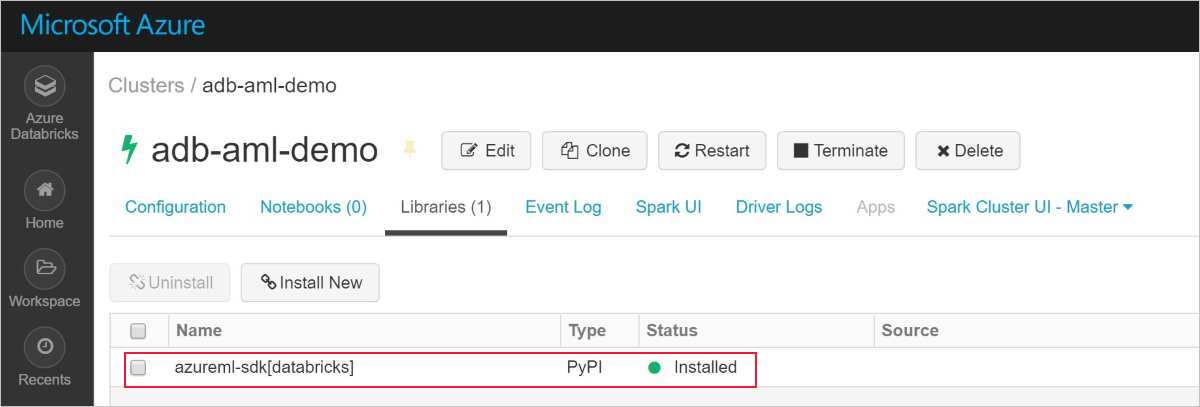
Přidání sady Azure Machine Learning SDK s autoML do Databricks
Pokud se cluster vytvořil pomocí databricks Runtime 7.3 LTS (ne ML), spuštěním následujícího příkazu v první buňce poznámkového bloku nainstalujte sadu Azure Machine Learning SDK.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
Nastavení konfigurace AutoML
V konfiguraci Automatizovaného strojového učení přidejte při použití Azure Databricks následující parametry:
max_concurrent_iterationsje založená na počtu pracovních uzlů v clusteru.spark_context=scje založená na výchozím kontextu Sparku.
Poznámkové bloky ML, které fungují s Azure Databricks
Vyzkoušejte si to:
I když je k dispozici mnoho ukázkových poznámkových bloků, s Azure Databricks fungují jenom tyto ukázkové poznámkové bloky .
Importujte tyto ukázky přímo z pracovního prostoru. Viz níže:
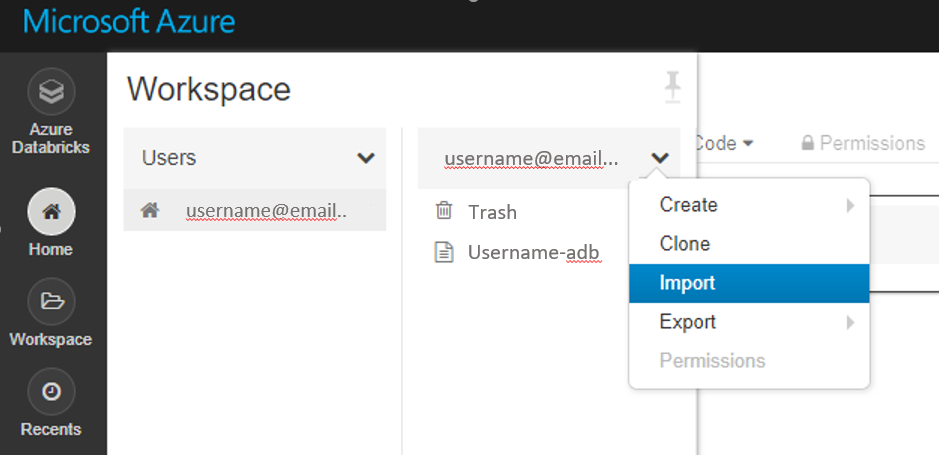
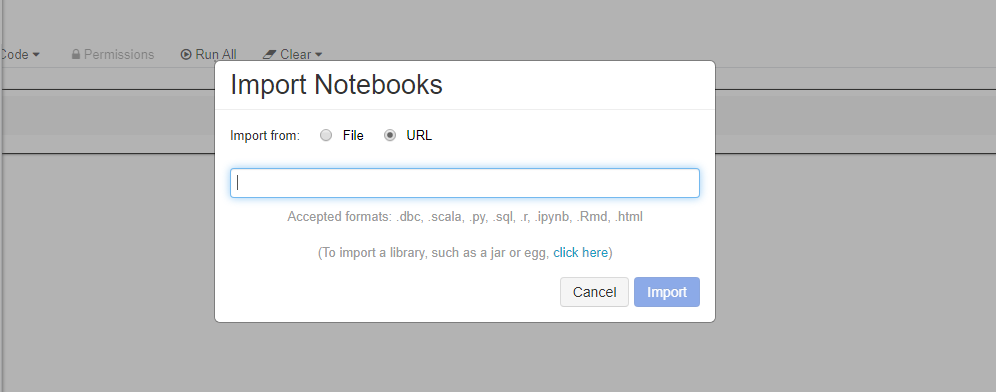
Zjistěte, jak vytvořit kanál s Databricks jako výpočetním prostředím pro trénování.
Poradce při potížích
Databricks zruší spuštění automatizovaného strojového učení: Pokud používáte funkce automatizovaného strojového učení v Azure Databricks, restartujte cluster Azure Databricks, abyste zrušili spuštění a spustili nový experiment.
Iterace Databricks >10 pro automatizované strojové učení: V nastavení automatizovaného strojového učení platí, že pokud máte více než 10 iterací, nastavíte
show_outputpři odesílání spuštění naFalsehodnotu .Widget Databricks pro sadu Azure Machine Learning SDK a automatizované strojové učení: Widget sady Azure Machine Learning SDK není v poznámkovém bloku Databricks podporovaný, protože poznámkové bloky nemůžou analyzovat widgety HTML. Widget můžete zobrazit na portálu pomocí tohoto kódu Pythonu v buňce poznámkového bloku Azure Databricks:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Selhání při instalaci balíčků
Instalace sady Azure Machine Learning SDK v Azure Databricks selže, když se nainstalují další balíčky. Některé balíčky, například
psutil, můžou způsobovat konflikty. Abyste se vyhnuli chybám instalace, nainstalujte balíčky zamrznutím verze knihovny. Tento problém souvisí s Databricks, a ne se sadou SDK služby Azure Machine Learning. K tomuto problému může docházet i u jiných knihoven. Příklad:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0Případně můžete použít inicializační skripty, pokud stále dochází k problémům s instalací knihoven Pythonu. Tento přístup se oficiálně nepodporuje. Další informace najdete v tématu Inicializační skripty v rámci clusteru.
Chyba importu: Nejde importovat název
Timedeltazpandas._libs.tslibs: Pokud se při použití automatizovaného strojového učení zobrazí tato chyba, spusťte v poznámkovém bloku následující dva řádky:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Chyba importu: Žádný modul s názvem pandas.core.indexes: Pokud se při použití automatizovaného strojového učení zobrazí tato chyba:
Spuštěním tohoto příkazu nainstalujte do clusteru Azure Databricks dva balíčky:
scikit-learn==0.19.1 pandas==0.22.0Odpojte cluster a znovu ho připojte k poznámkovému bloku.
Pokud tento postup problém nevyřeší, zkuste cluster restartovat.
FailToSendFeather: Pokud se při čtení dat v clusteru Azure Databricks zobrazí
FailToSendFeatherchyba, projděte si následující řešení:- Upgradujte
azureml-sdk[automl]balíček na nejnovější verzi. - Přidejte
azureml-dataprepverzi 1.1.8 nebo vyšší. - Přidejte
pyarrowverzi 0.11 nebo vyšší.
- Upgradujte
Další kroky
- Trénování a nasazení modelu ve službě Azure Machine Learning pomocí datové sady MNIST
- Projděte si referenční informace k sadě Azure Machine Learning SDK pro Python.