Vytváření a spouštění kanálů strojového učení pomocí komponent pomocí rozhraní příkazového řádku služby Azure Machine Learning
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)
V tomto článku se dozvíte, jak vytvářet a spouštět kanály strojového učení pomocí Azure CLI a komponent. Kanály můžete vytvářet bez použití komponent, ale komponenty nabízejí největší flexibilitu a opakované použití. Kanály Azure Machine Learning je možné definovat v JAZYCE YAML a spouštět z rozhraní příkazového řádku, vytvářet v Pythonu nebo se skládat v návrháři studio Azure Machine Learning pomocí uživatelského rozhraní pro přetahování. Tento dokument se zaměřuje na rozhraní příkazového řádku.
Požadavky
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
Pracovní prostor služby Azure Machine Learning. Vytvořte prostředky pracovního prostoru.
Nainstalujte a nastavte rozšíření Azure CLI pro Machine Learning.
Naklonujte úložiště příkladů:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Navrhované předběžné předčítání
Vytvoření prvního kanálu s komponentou
Pojďme vytvořit první kanál s komponentami pomocí příkladu. Cílem této části je inicializace toho, jak kanál a komponenta vypadají ve službě Azure Machine Learning s konkrétním příkladem.
cli/jobs/pipelines-with-components/basics V adresáři azureml-examples úložiště přejděte do 3b_pipeline_with_data podadresáře. V tomto adresáři jsou tři typy souborů. Jedná se o soubory, které je potřeba vytvořit při vytváření vlastního kanálu.
pipeline.yml: Tento soubor YAML definuje kanál strojového učení. Tento soubor YAML popisuje, jak přerušit úplnou úlohu strojového učení do pracovního postupu s více kroky. Například při zvažování jednoduché úlohy strojového učení s použitím historických dat k trénování modelu prognózování prodeje můžete chtít vytvořit sekvenční pracovní postup se zpracováním dat, trénováním modelu a postupem vyhodnocení modelu. Každý krok je komponenta, která má dobře definované rozhraní a lze ji nezávisle vyvíjet, testovat a optimalizovat. YaML kanálu také definuje, jak se podřízené kroky připojují k dalším krokům v kanálu, například krok trénování modelu vygeneruje soubor modelu a soubor modelu se předá do kroku vyhodnocení modelu.
component.yml: Tento soubor YAML definuje komponentu. Zabalí následující informace:
- Metadata: název, zobrazovaný název, verze, popis, typ atd. Metadata pomáhají popsat a spravovat komponentu.
- Rozhraní: vstupy a výstupy. Například komponenta trénování modelu přebírá jako vstup trénovací data a počet epoch a jako výstup vygeneruje trénovaný soubor modelu. Jakmile je rozhraní definováno, můžou různé týmy vyvíjet a testovat komponentu nezávisle.
- Příkaz, kód a prostředí: příkaz, kód a prostředí pro spuštění komponenty. Příkaz je příkaz prostředí pro spuštění komponenty. Kód obvykle odkazuje na adresář zdrojového kódu. Prostředí může být prostředí Azure Machine Learning (kurátorované nebo vytvořené zákazníkem), image Dockeru nebo prostředí Conda.
component_src: Toto je adresář zdrojového kódu pro konkrétní komponentu. Obsahuje zdrojový kód, který se spouští v komponentě. Můžete použít upřednostňovaný jazyk (Python, R...). Kód musí být proveden příkazem prostředí. Zdrojový kód může provést několik vstupů z příkazového řádku prostředí, abyste mohli řídit, jak se má tento krok provést. Například krok trénování může provádět trénovací data, rychlost učení, počet epoch pro řízení procesu trénování. Argument příkazu prostředí slouží k předávání vstupů a výstupů kódu.
Teď vytvoříme kanál pomocí příkladu 3b_pipeline_with_data . Podrobný význam jednotlivých souborů vysvětlujeme v následujících částech.
Nejprve vypíšete dostupné výpočetní prostředky pomocí následujícího příkazu:
az ml compute list
Pokud ho nemáte, vytvořte cluster volaný cpu-cluster spuštěním příkazu:
Poznámka:
Tento krok přeskočte, pokud chcete používat bezserverové výpočetní prostředky.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Teď pomocí následujícího příkazu vytvořte úlohu kanálu definovanou v souboru pipeline.yml. Na cílový výpočetní objekt se odkazuje v souboru pipeline.yml jako azureml:cpu-cluster. Pokud váš cílový výpočetní objekt používá jiný název, nezapomeňte ho aktualizovat v souboru pipeline.yml.
az ml job create --file pipeline.yml
Měli byste obdržet slovník JSON s informacemi o úloze kanálu, včetně následujících:
| Key | Popis |
|---|---|
name |
Název úlohy založený na identifikátoru GUID. |
experiment_name |
Název, pod kterým budou úlohy uspořádány ve studiu. |
services.Studio.endpoint |
Adresa URL pro monitorování a kontrolu úlohy kanálu. |
status |
Stav úlohy. To bude pravděpodobně Preparing v tuto chvíli. |
services.Studio.endpoint Otevřete adresu URL a zobrazte vizualizaci grafu kanálu.
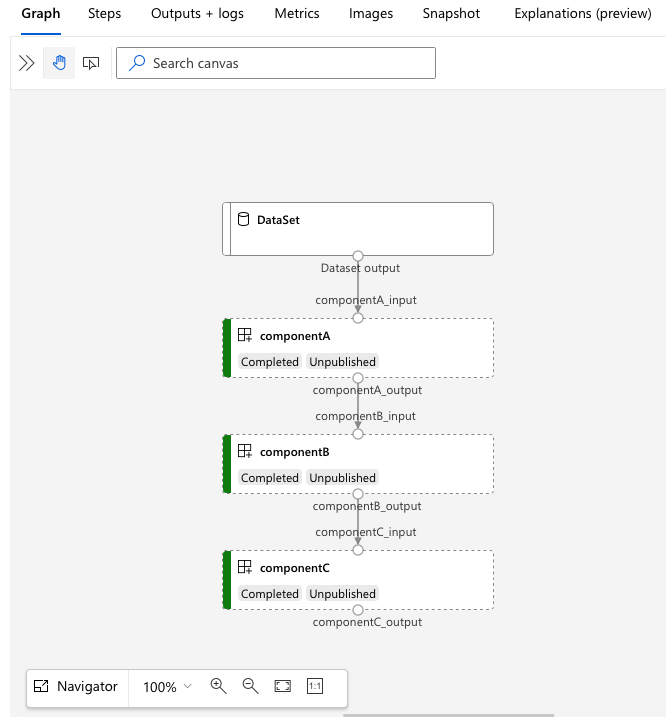
Vysvětlení definice kanálu YAML
Podívejme se na definici kanálu v souboru 3b_pipeline_with_data/pipeline.yml .
Poznámka:
Pokud chcete používat bezserverové výpočetní prostředky, nahraďte default_compute: azureml:cpu-cluster ho default_compute: azureml:serverless v tomto souboru.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
Tabulka popisuje nejběžnější použitá pole schématu YAML kanálu. Další informace najdete v úplném schématu YAML kanálu.
| key | description |
|---|---|
| type | Povinný: Typ úlohy musí být pipeline pro úlohy kanálu. |
| display_name | Zobrazovaný název úlohy kanálu v uživatelském rozhraní studia Upravitelné v uživatelském rozhraní studia Nemusí být jedinečné pro všechny úlohy v pracovním prostoru. |
| pracovní místa | Povinný: Slovník sady jednotlivých úloh, které se mají spustit jako kroky v kanálu. Tyto úlohy jsou považovány za podřízené úlohy nadřazené úlohy kanálu. V této verzi jsou command podporované typy úloh v kanálu a sweep |
| vstupy | Slovník vstupů pro úlohu kanálu Klíč je název vstupu v kontextu úlohy a hodnota je vstupní hodnota. Tyto vstupy kanálu mohou být odkazovány vstupy jednotlivých kroků úlohy v kanálu pomocí ${{ parent.vstupy.<> výraz input_name }}. |
| výstupy | Slovník výstupních konfigurací úlohy kanálu Klíč je název výstupu v kontextu úlohy a hodnota je výstupní konfigurace. Na tyto výstupy kanálu se dají odkazovat výstupy jednotlivých kroků úlohy v kanálu pomocí ${{ parents.outputs.<> výraz output_name }}. |
V 3b_pipeline_with_data příkladu jsme vytvořili kanál se třemi kroky.
- Tři kroky jsou definovány v části
jobs. Všechny tři typy kroků jsou úloha příkazu. Definice každého kroku je v odpovídajícímcomponent.ymlsouboru. Soubory YAML komponenty můžete zobrazit v adresáři 3b_pipeline_with_data . ComponentA.yml vysvětlíme v další části. - Tento kanál má závislost na datech, což je běžné ve většině skutečných kanálů. Component_a přebírá vstup dat z místní složky pod
./datařádkem 17–20 a předává výstup do componentB (řádek 29). výstup Component_a lze odkazovat jako${{parent.jobs.component_a.outputs.component_a_output}}na . - Definuje
computevýchozí výpočetní prostředky pro tento kanál. Pokud komponenta v rámcijobsdefinuje jiný výpočetní výkon pro tuto komponentu, systém respektuje konkrétní nastavení součásti.

Čtení a zápis dat v kanálu
Jedním z běžných scénářů je čtení a zápis dat v kanálu. Ve službě Azure Machine Learning používáme stejné schéma ke čtení a zápisu dat pro všechny typy úloh (úloha kanálu, úloha příkazů a úloha úklidu). Tady jsou příklady úlohy kanálu použití dat pro běžné scénáře.
- místní data
- webový soubor s veřejnou adresou URL
- Úložiště dat a cesta ke službě Azure Machine Learning
- Datový prostředek služby Azure Machine Learning
Vysvětlení definice komponenty YAML
Teď se podívejme na componentA.yml jako příklad, abychom porozuměli definici komponenty YAML.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Nejběžnější použité schéma komponenty YAML je popsáno v tabulce. Další informace najdete ve schématu YAML úplné komponenty.
| key | description |
|---|---|
| name | Požadováno. Název komponenty. Musí být jedinečný v rámci pracovního prostoru Azure Machine Learning. Musí začínat malým písmenem. Povolit malá písmena, číslice a podtržítka(_). Maximální délka je 255 znaků. |
| display_name | Zobrazovaný název komponenty v uživatelském rozhraní studia V rámci pracovního prostoru může být neunique. |
| příkaz | Vyžaduje se spuštění příkazu. |
| code | Místní cesta k adresáři zdrojového kódu, který se má nahrát a použít pro komponentu. |
| prostředí | Povinný: Prostředí, které se používá ke spuštění komponenty. |
| vstupy | Slovník vstupů komponent. Klíč je název vstupu v kontextu komponenty a hodnota je definice vstupu komponenty. Vstupy lze v příkazu odkazovat pomocí ${{ vstupů.<> výraz input_name }}. |
| výstupy | Slovník výstupů komponent Klíč je název výstupu v kontextu komponenty a hodnota je definice výstupu komponenty. Na výstupy lze v příkazu odkazovat pomocí výstupů ${{ .<> výraz output_name }}. |
| is_deterministic | Jestli se má znovu použít výsledek předchozí úlohy, pokud se vstupy součástí nezměnily. Výchozí hodnota je truetaké označována jako opakované použití ve výchozím nastavení. Běžný scénář, kdy je nastavená možnost false vynutit opětovné načtení dat z cloudového úložiště nebo adresy URL. |
V příkladu v 3b_pipeline_with_data/componentA.yml má komponentaA jeden vstup dat a jeden datový výstup, který je možné připojit k dalším krokům v nadřazené kanálu. Při odesílání úlohy kanálu se do Služby Azure Machine Learning nahrají všechny soubory code v oddílu v komponentě YAML. V tomto příkladu se nahrají soubory pod ./componentA_src (řádek 16 v componentA.yml). Nahraný zdrojový kód můžete zobrazit v uživatelském rozhraní studia: dvakrát vyberte krok ComponentA a přejděte na kartu Snímek, jak je znázorněno na následujícím snímku obrazovky. Vidíme, že se jedná o jednoduchý skript hello-world a napište aktuální datum a čas do componentA_output cesty. Komponenta přebírá vstup a výstup prostřednictvím argumentu příkazového řádku a zpracovává se v hello.py pomocí argparse.

Vstup a výstup
Vstup a výstup definují rozhraní komponenty. Vstupem a výstupem může být buď hodnota literálu (typu string,number,integer, nebo ) nebo booleanobjekt obsahující vstupní schéma.
Vstup objektu (typu uri_file, uri_folder,mltable,mlflow_model,custom_model), se může připojit k dalším krokům v úloze nadřazeného kanálu a předat data nebo model dalším krokům. V grafu kanálu se vstup typu objektu vykreslí jako tečka připojení.
Vstupy literálových hodnot (string,number,integerboolean), jsou parametry, které lze předat komponentě za běhu. Do pole můžete přidat výchozí hodnotu literálových vstupů default . Pro number a integer typ můžete také přidat minimální a maximální hodnotu akceptované hodnoty pomocí min a max polí. Pokud vstupní hodnota překročí minimální a maximální hodnotu, kanál se nezdaří při ověření. Ověření proběhne před odesláním úlohy kanálu, abyste ušetřili čas. Ověřování funguje pro rozhraní příkazového řádku, sadu Python SDK a uživatelské rozhraní návrháře. Následující snímek obrazovky ukazuje příklad ověření v uživatelském rozhraní návrháře. Podobně můžete v poli definovat povolené hodnoty enum .

Pokud chcete přidat vstup do komponenty, nezapomeňte upravit tři místa:
inputspole v YAML komponentycommandpole v komponentě YAML.- Zdrojový kód komponenty pro zpracování vstupu příkazového řádku Je označený zeleným rámečkem na předchozím snímku obrazovky.
Další informace o vstupech a výstupech najdete v tématu Správa vstupů a výstupů komponent a kanálu.
Prostředí
Prostředí definuje prostředí pro spuštění komponenty. Může se jednat o prostředí Azure Machine Learning (kurátorované nebo registrované), image Dockeru nebo prostředí Conda. Viz následující příklady.
- Zaregistrovaný prostředek prostředí služby Azure Machine Learning Odkazuje se na ni v následující
azureml:<environment-name>:<environment-version>syntaxi komponenty. - veřejná image Dockeru
- Soubor conda conda musí být použit společně se základní imagí.
Registrace komponenty pro opakované použití a sdílení
I když jsou některé komponenty specifické pro konkrétní kanál, skutečný přínos součástí pochází z opakovaného použití a sdílení. Zaregistrujte v pracovním prostoru Machine Learning komponentu, aby byla k dispozici pro opakované použití. Registrované komponenty podporují automatickou správu verzí, abyste mohli součást aktualizovat, ale ujistěte se, že kanály, které vyžadují starší verzi, budou i nadále fungovat.
V úložišti azureml-examples přejděte do cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components adresáře.
Pokud chcete zaregistrovat komponentu, použijte příkaz az ml component create :
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Po dokončení těchto příkazů uvidíte komponenty v sadě Studio v části Asset –> Components( Komponenty):

Vyberte komponentu. Zobrazí se podrobné informace pro každou verzi komponenty.
Na kartě Podrobnosti se zobrazí základní informace o komponentě, jako je název, vytvořený podle verze atd. Zobrazí se upravitelná pole pro značky a popis. Značky lze použít k rychlému vyhledávání klíčových slov. Pole popisu podporuje formátování Markdownu a mělo by se použít k popisu funkčnosti a základního použití komponenty.
Na kartě Úlohy se zobrazí historie všech úloh, které tuto komponentu používají.
Použití registrovaných komponent v souboru YAML úlohy kanálu
Pojďme si předvést 1b_e2e_registered_components , jak používat zaregistrovanou komponentu v YAML kanálu. Přejděte do 1b_e2e_registered_components adresáře a otevřete pipeline.yml soubor. Klíče a hodnoty v inputs polích outputs jsou podobné těm, které už jsou popsány. Jediným významným rozdílem je hodnota component pole v jobs.<JOB_NAME>.component položkách. Hodnota component je ve formuláři azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>. Definice train-job například určuje nejnovější verzi registrované komponenty my_train , která se má použít:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Správa komponent
Pomocí rozhraní příkazového řádku (v2) můžete zkontrolovat podrobnosti o komponentě a spravovat ji. Slouží az ml component -h k získání podrobných pokynů k příkazu komponenty. V následující tabulce jsou uvedeny všechny dostupné příkazy. Další příklady najdete v referenčních informacích k Azure CLI.
| příkazy | description |
|---|---|
az ml component create |
Vytvoření komponenty |
az ml component list |
Výpis komponent v pracovním prostoru |
az ml component show |
Zobrazení podrobností o komponentě |
az ml component update |
Aktualizujte součást. Aktualizace podpory pouze několika polí (popis, display_name) |
az ml component archive |
Archivace kontejneru komponent |
az ml component restore |
Obnovení archivované komponenty |
Další kroky
- Příklad vyzkoušení komponenty rozhraní příkazového řádku v2
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro