Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Tento článek ukazuje, jak vytvářet a spravovat datové prostředky ve službě Azure Machine Learning.
Datové prostředky vám můžou pomoct, když potřebujete:
- Správa verzí: Datové prostředky podporují správu verzí dat.
- Reprodukovatelnost: Jakmile vytvoříte verzi datového assetu, je neměnná. Nelze ho upravit ani odstranit. Proto je možné reprodukovat trénovací úlohy nebo kanály, které využívají datový asset.
- Auditovatelnost: Vzhledem k tomu, že verze datového assetu je neměnná, můžete sledovat verze assetů, kteří aktualizovali verzi a kdy došlo k aktualizacím verze.
- Rodokmen: U libovolného datového prostředku můžete zobrazit, které úlohy nebo kanály data spotřebovávají.
-
Snadné použití: Datový prostředek služby Azure Machine Learning připomíná záložky webového prohlížeče (oblíbené položky). Místo zapamatování dlouhých cest úložiště (URI), které odkazují na často používaná data ve službě Azure Storage, můžete vytvořit verzi datového prostředku a pak k této verzi prostředku přistupovat s popisným názvem (například:
azureml:<my_data_asset_name>:<version>).
Návod
Pokud chcete získat přístup k datům v interaktivní relaci (například v poznámkovém bloku) nebo úloze, nemusíte nejdřív vytvořit datový asset. K přístupu k datům můžete použít identifikátory URI úložiště dat. Identifikátory URI úložiště dat nabízejí jednoduchý způsob, jak získat přístup k datům, abyste mohli začít se službou Azure Machine Learning.
Požadavky
K vytváření a práci s datovými prostředky potřebujete:
Předplatné Azure. Pokud ho nemáte, vytvořte si bezplatný účet před tím, než začnete. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
Pracovní prostor služby Azure Machine Learning. Vytvořte prostředky pracovního prostoru.
Nainstalované rozhraní příkazového řádku nebo sady SDK služby Azure Machine Learning
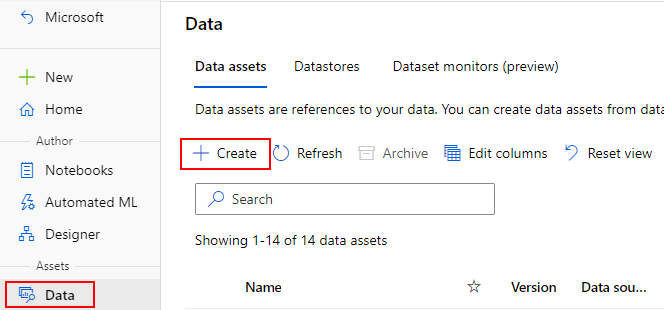
Vytváření datových prostředků
Při vytváření datového assetu je potřeba nastavit datový typ assetu. Azure Machine Learning podporuje tři typy datových prostředků:
| Typ | API | Kanonické scénáře |
|---|---|---|
|
Soubor Odkaz na jeden soubor |
uri_file |
Čtení jednoho souboru ve službě Azure Storage (soubor může mít libovolný formát). |
|
Složka Odkaz na složku |
uri_folder |
Přečtěte si složku souborů parquet/CSV do Pandas/Sparku. Čtení nestrukturovaných dat (obrázky, text, zvuk atd.) umístěné ve složce |
|
Tabulka Odkazování na tabulku dat |
mltable |
Máte složité schéma, které podléhá častým změnám, nebo potřebujete podmnožinu velkých tabulkových dat. AutoML s tabulkami Čtení nestrukturovaných dat (obrázků, textu, zvuku atd.), která jsou rozložená do více umístění úložiště. |
Poznámka:
Vložené nové spojnice v souborech CSV používejte jenom v případě, že data zaregistrujete jako tabulku MLTable. Vložené nové spojnice v souborech CSV můžou při čtení dat způsobit nesprávně zarovnané hodnoty polí. MlTable má support_multi_line parametr dostupný v read_delimited transformaci, který interpretuje konce řádků v uvozových znaménech jako jeden záznam.
Při využívání datového prostředku v úloze Azure Machine Learning můžete prostředek připojit nebo stáhnout do výpočetních uzlů. Další informace naleznete v režimech.
Musíte také zadat path parametr, který odkazuje na umístění datového assetu. Mezi podporované cesty patří:
| Umístění | Příklady |
|---|---|
| Cesta na místním počítači | ./home/username/data/my_data |
| Cesta k úložišti dat | azureml://datastores/<data_store_name>/paths/<path> |
| Cesta na veřejném serveru https | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Cesta ve službě Azure Storage | (Objekt blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS Gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS Gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Poznámka:
Když vytvoříte datový prostředek z místní cesty, automaticky se nahraje do výchozího cloudového úložiště dat Azure Machine Learning.
Vytvoření datového prostředku: Typ souboru
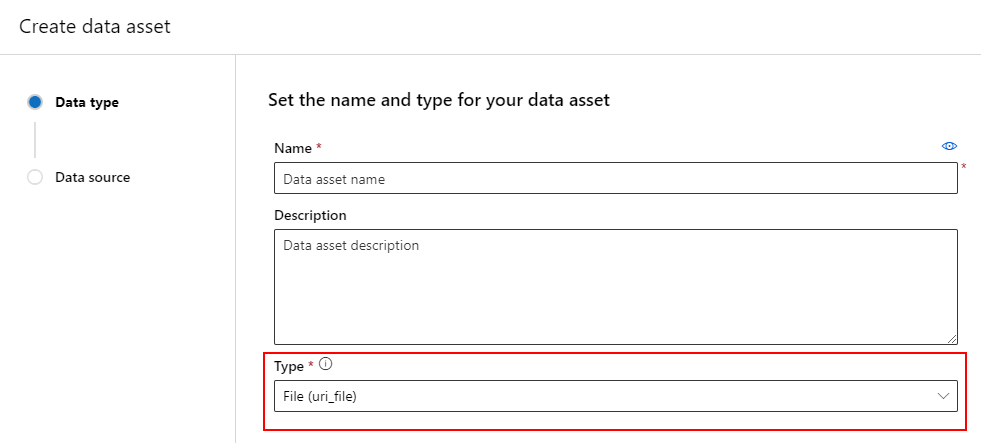
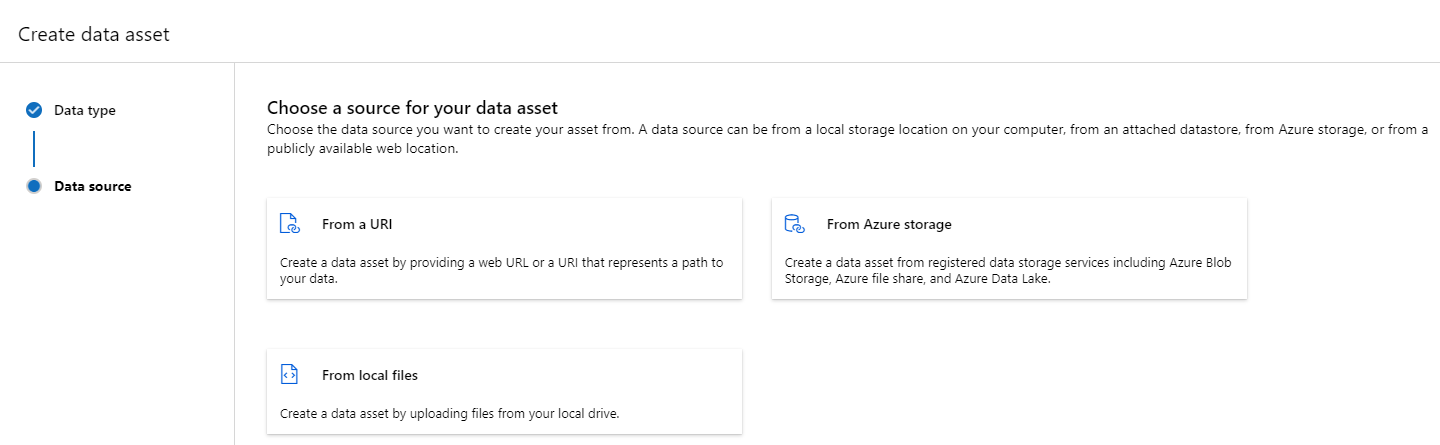
Datový prostředek typu Soubor (uri_file) odkazuje na jeden soubor v úložišti (například soubor CSV). Datový asset typu souboru můžete vytvořit pomocí:
Vytvořte soubor YAML a zkopírujte a vložte následující fragment kódu. Nezapomeňte aktualizovat <> zástupné symboly pomocí
- název datového assetu
- verze
- popis
- cesta k jednomu souboru v podporovaném umístění
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Potom v rozhraní příkazového řádku spusťte následující příkaz. Nezapomeňte zástupný symbol aktualizovat <filename> na název souboru YAML.
az ml data create -f <filename>.yml
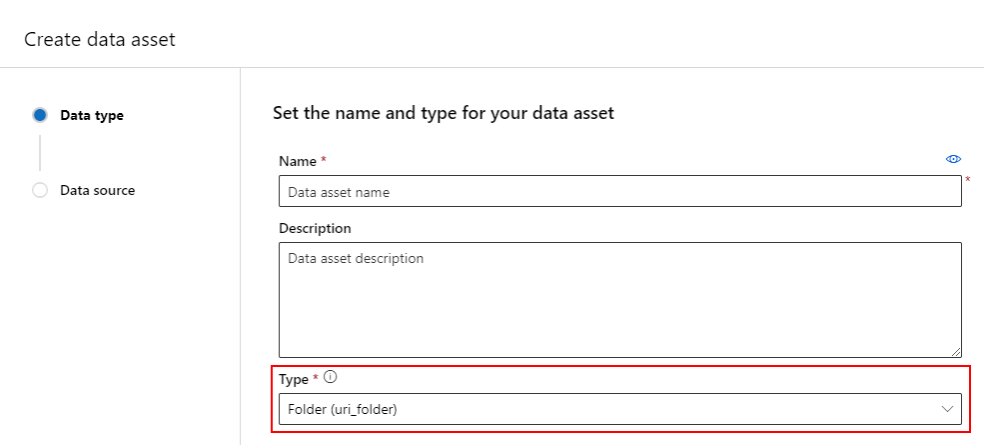
Vytvoření datového prostředku: Typ složky
Datový prostředek složky (uri_folder) odkazuje na složku v prostředku úložiště – například složka obsahující několik podsložek obrázků. Datový prostředek typu složky můžete vytvořit pomocí:
Zkopírujte a vložte následující kód do nového souboru YAML. Nezapomeňte aktualizovat <> zástupné symboly pomocí
- Název datového assetu
- Verze
- Popis
- Cesta ke složce v podporovaném umístění
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Potom v rozhraní příkazového řádku spusťte následující příkaz. Nezapomeňte zástupný symbol aktualizovat <filename> na název souboru YAML.
az ml data create -f <filename>.yml
Vytvoření datového prostředku: Typ tabulky
TabulkyMLTable Služby Azure Machine Learning mají bohaté funkce, které jsou podrobněji popsány v tématu Práce s tabulkami ve službě Azure Machine Learning. Místo opakování této dokumentace si přečtěte tento příklad, který popisuje, jak vytvořit datový prostředek typu Table s daty Titanic umístěnými na veřejně dostupném účtu Azure Blob Storage.
Nejprve vytvořte nový adresář s názvem data a vytvořte soubor s názvem MLTable:
mkdir data
touch MLTable
Dále zkopírujte a vložte následující YAML do souboru MLTable , který jste vytvořili v předchozím kroku:
Upozornění
Nepřejmenovávat MLTable soubor na MLTable.yaml nebo MLTable.yml. Azure Machine Learning očekává MLTable soubor.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
V rozhraní příkazového řádku spusťte následující příkaz. Nezapomeňte aktualizovat <> zástupné symboly názvem datového assetu a hodnotami verzí.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Důležité
Měla path by to být složka , která obsahuje platný MLTable soubor.
Vytváření datových prostředků z výstupů úloh
Datový prostředek můžete vytvořit z úlohy Azure Machine Learning. Uděláte to tak, že nastavíte name parametr ve výstupu. V tomto příkladu odešlete úlohu, která kopíruje data z veřejného úložiště objektů blob do výchozího úložiště dat služby Azure Machine Learning a vytvoří datový prostředek s názvem job_output_titanic_asset.
Vytvoření souboru YAML specifikace úlohy (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Pak odešlete úlohu pomocí rozhraní příkazového řádku:
az ml job create --file <file-name>.yml
Správa datových prostředků
Odstranění datového prostředku
Důležité
Odstranění datového assetu se záměrně nepodporuje.
Pokud azure Machine Learning povolil odstranění datového prostředku, mělo by to následující nepříznivé a negativní účinky:
- Produkční úlohy , které využívají datové prostředky, které byly později odstraněny, selžou.
- Reprodukování experimentu ML by bylo obtížnější.
- Rodokmen úlohy by se přerušil, protože by nebylo možné zobrazit verzi odstraněného datového assetu.
- Nebudete moct správně sledovat a auditovat , protože můžou chybět verze.
Neměnnost datových prostředků proto poskytuje úroveň ochrany při práci v týmu, který vytváří produkční úlohy.
Pro omylem vytvořený datový prostředek – například s nesprávným názvem, typem nebo cestou – Azure Machine Learning nabízí řešení pro zvládnutí situace bez negativních důsledků odstranění:
| Chci tento datový prostředek odstranit, protože... | Řešení |
|---|---|
| Název je nesprávný. | Archivace datového assetu |
| Tým už datový asset nepoužívá . | Archivace datového assetu |
| Zahltí výpis datového assetu. | Archivace datového assetu |
| Cesta je nesprávná. | Vytvořte novou verzi datového prostředku (se stejným názvem) se správnou cestou. Další informace najdete v tématu Vytvoření datových prostředků. |
| Má nesprávný typ. | V tuto chvíli Azure Machine Learning neumožňuje vytvoření nové verze s jiným typem v porovnání s počáteční verzí. (1) Archivace datového assetu (2) Vytvořte nový datový asset pod jiným názvem se správným typem. |
Archivace datového prostředku
Archivace datového assetu ho ve výchozím nastavení skryje v obou dotazech seznamu (například v rozhraní příkazového řádku az ml data list) a datového assetu výpisu v uživatelském rozhraní studia. V pracovních postupech můžete i nadále odkazovat na archivovaný datový asset a používat ho. Archivovat můžete:
- Všechny verze datového assetu pod daným názvem
Nebo
- Konkrétní verze datového assetu
Archivace všech verzí datového assetu
Chcete-li archivovat všechny verze datového prostředku pod daným názvem, použijte:
Proveďte následující příkaz: Nezapomeňte aktualizovat <> zástupné symboly vašimi informacemi.
az ml data archive --name <NAME OF DATA ASSET>
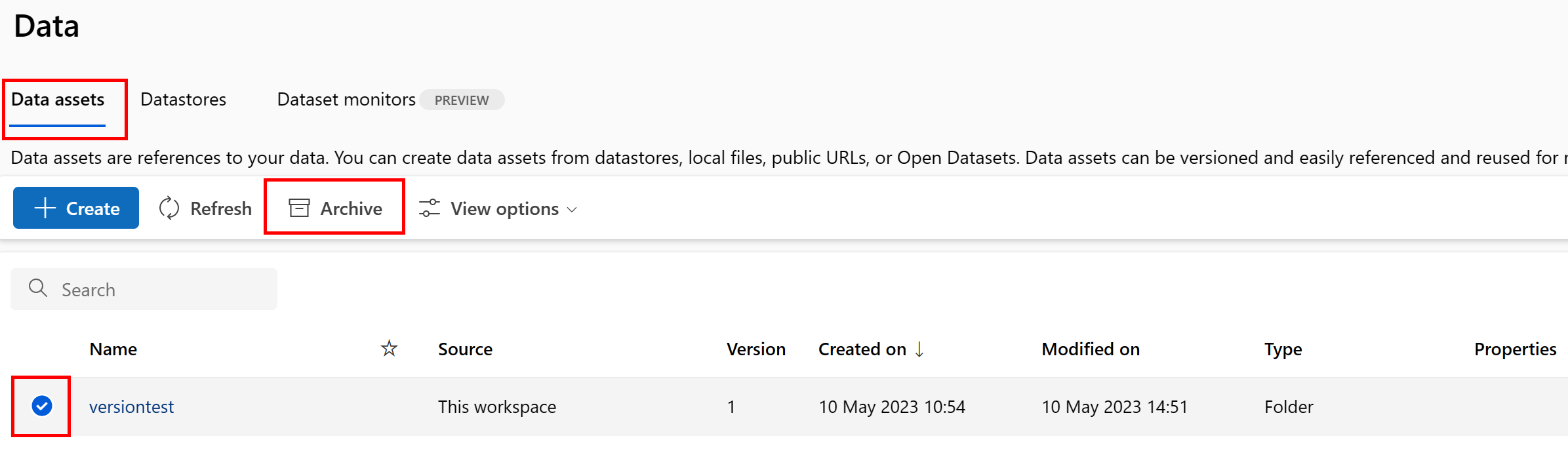
Archivace konkrétní verze datového assetu
Pokud chcete archivovat konkrétní verzi datového assetu, použijte:
Proveďte následující příkaz: Nezapomeňte aktualizovat <> zástupné symboly názvem datového assetu a verze.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Obnovení archivovaného datového prostředku
Archivovaný datový asset můžete obnovit. Pokud jsou všechny verze datového assetu archivovány, nemůžete obnovit jednotlivé verze datového assetu – musíte obnovit všechny verze.
Obnovení všech verzí datového assetu
Pokud chcete obnovit všechny verze datového assetu pod daným názvem, použijte:
Proveďte následující příkaz: Nezapomeňte zástupné symboly aktualizovat <> názvem datového assetu.
az ml data restore --name <NAME OF DATA ASSET>

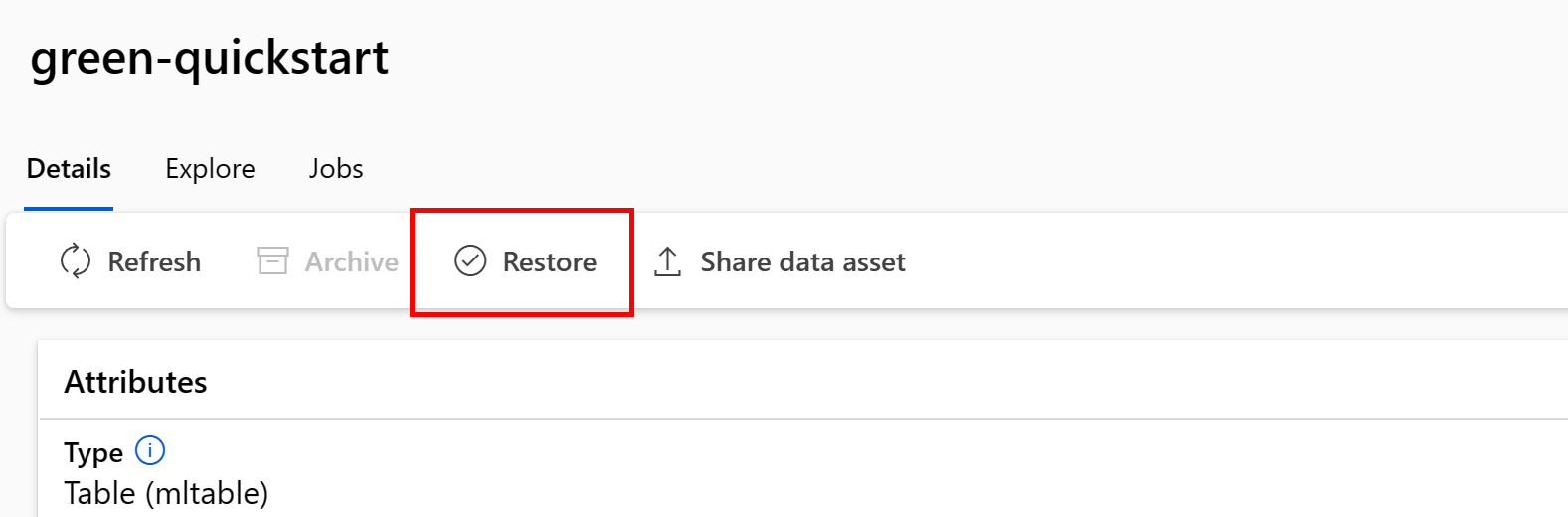
Obnovení konkrétní verze datového assetu
Důležité
Pokud byly archivovány všechny verze datových assetů, nemůžete obnovit jednotlivé verze datového assetu – musíte obnovit všechny verze.
Pokud chcete obnovit konkrétní verzi datového assetu, použijte:
Proveďte následující příkaz: Nezapomeňte aktualizovat <> zástupné symboly názvem datového assetu a verze.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Rodokmen dat
Rodokmen dat je obecně pochopen jako životní cyklus, který zahrnuje původ dat a kde se přesouvá v průběhu času napříč úložištěm. Používají se různé druhy zpětně vypadajících scénářů, například
- Řešení problému
- Původní příčiny trasování v kanálech ML
- Ladění
Scénáře analýzy kvality dat, dodržovánípředpisůch Rodokmen je znázorněn vizuálně tak, aby zobrazoval data, která se přesouvají ze zdroje do cíle, a navíc zahrnuje transformace dat. Vzhledem ke složitosti většiny podnikových datových prostředí se tato zobrazení můžou těžko pochopit bez konsolidace nebo maskováníperiferních
V kanálu Azure Machine Learning zobrazují datové prostředky původ dat a způsob zpracování dat, například:
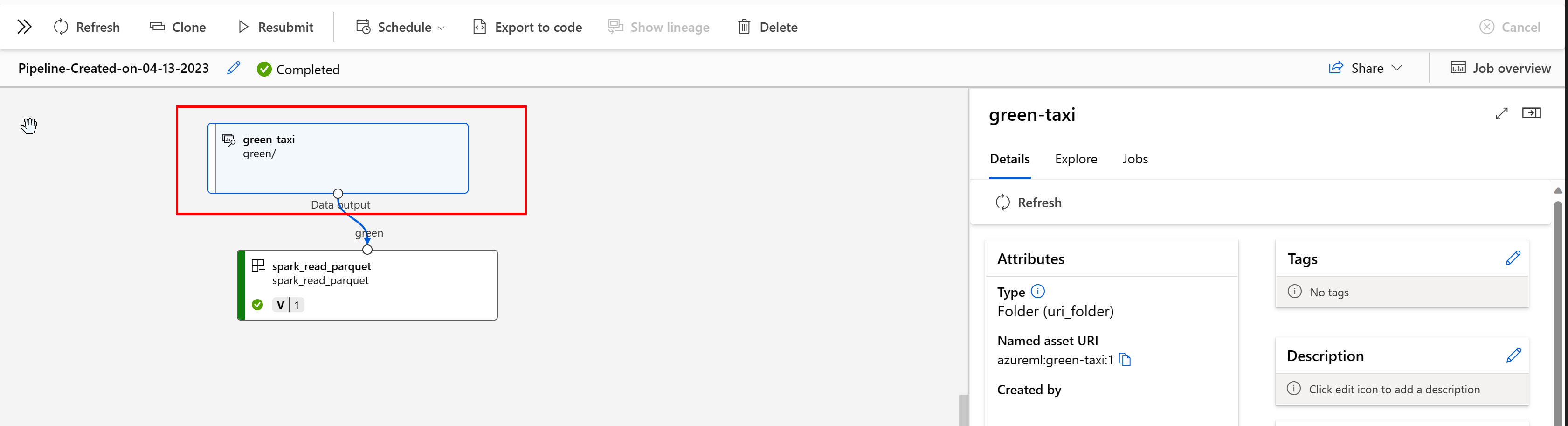
Úlohy, které spotřebovávají datový asset, můžete zobrazit v uživatelském rozhraní studia. Nejprve v nabídce vlevo vyberte Data a pak vyberte název datového assetu. Všimněte si úloh, které využívají datový asset:
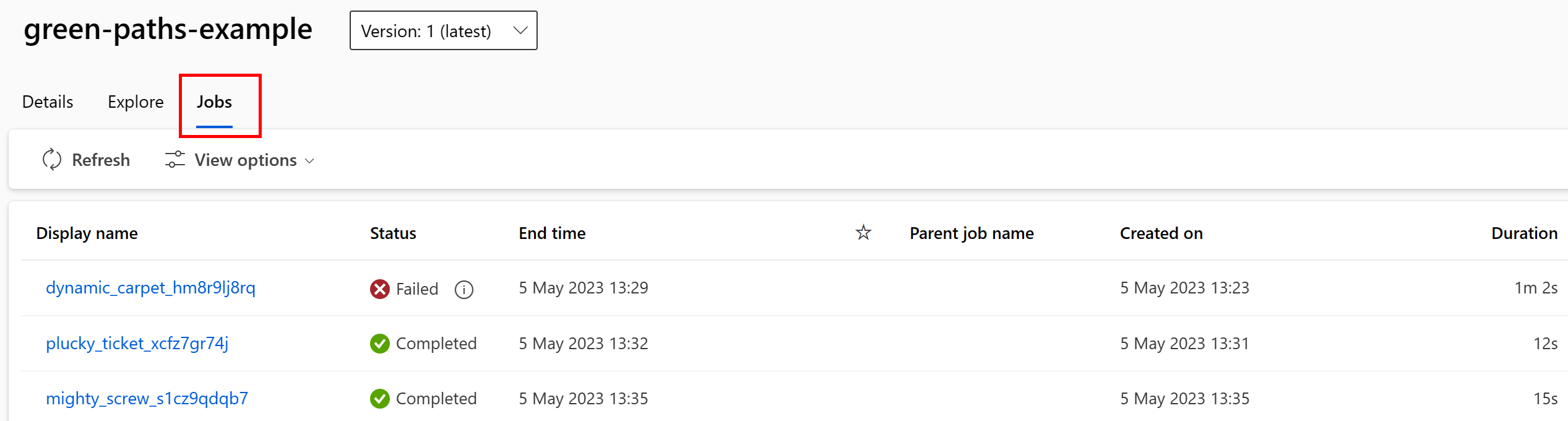
Zobrazení úloh v datových prostředcích usnadňuje vyhledání selhání úloh a analýzu původní příčiny v kanálech ML a ladění.
Označování datových assetů
Datové prostředky podporují označování, což jsou další metadata použitá u datového assetu jako pár klíč-hodnota. Označování dat přináší mnoho výhod:
- Popis kvality dat Pokud například vaše organizace používá architekturu jezera medallion, můžete prostředky označit pomocí
medallion:bronze(nezpracovaných),medallion:silver(ověřených) amedallion:gold(obohacených). - Efektivní vyhledávání a filtrování dat, které pomáhá zjišťovat data.
- Identifikace citlivých osobních údajů k řádné správě a řízení přístupu k datům. Například
sensitivity:PII/sensitivity:nonPII. - Určení, zda jsou data schválena odpovědným auditem AI (RAI). Například
RAI_audit:approved/RAI_audit:todo.
Značky můžete do datových assetů přidat jako součást jejich toku vytváření nebo můžete přidat značky do existujících datových prostředků. Tato část ukazuje obojí:
Přidání značek v rámci toku vytváření datových prostředků
Vytvořte soubor YAML a zkopírujte a vložte do tohoto souboru YAML následující kód. Nezapomeňte aktualizovat <> zástupné symboly pomocí
- název datového assetu
- verze
- popis
- tags (páry klíč-hodnota)
- cesta k jednomu souboru v podporovaném umístění
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
V rozhraní příkazového řádku spusťte následující příkaz. Nezapomeňte zástupný symbol aktualizovat <filename> na název souboru YAML.
az ml data create -f <filename>.yml
Přidání značek do existujícího datového assetu
V Azure CLI spusťte následující příkaz. Nezapomeňte aktualizovat <> zástupné symboly pomocí
- Název datového assetu
- Verze
- Pár klíč-hodnota pro značku
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Osvědčené postupy správy verzí
Procesy ETL obvykle uspořádají strukturu složek v úložišti Azure podle času, například:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
Kombinace strukturovaných složek time/version a tabulekMLTable Azure Machine Learning umožňuje vytvářet datové sady s verzemi. Hypotetický příklad ukazuje, jak dosáhnout dat s verzí pomocí tabulek Azure Machine Learning. Předpokládejme, že máte proces, který každý týden nahrává obrázky z fotoaparátu do úložiště objektů blob v Azure, v této struktuře:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Poznámka:
I když si ukážeme, jak vytvořit verzi dat (jpeg) obrázků, funguje stejný přístup pro libovolný typ souboru (například Parquet, CSV).
Pomocí tabulek Azure Machine Learning (mltable) sestavte tabulku cest, které obsahují data až do konce prvního týdne v roce 2023. Pak vytvořte datový asset:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AZUREML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Na konci následujícího týdne vaše ETL aktualizovala data tak, aby obsahovala další data:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
První verze (20230108) pokračuje pouze připojování a stahování souborů z year=2022/week=52 a year=2023/week=1 protože cesty jsou deklarovány v MLTable souboru. Tím se zajistí reprodukovatelnost experimentů. Pokud chcete vytvořit novou verzi datového prostředku, který obsahuje year=2023/week2, použijte:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AZUREML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Teď máte dvě verze dat, kde název verze odpovídá datu, kdy se obrázky nahrály do úložiště:
- 20230108: Obrázky do roku 2023-Jan-08.
- 20230115: Obrázky do 15. ledna 2023.
V obou případech mlTable vytvoří tabulku cest, které obsahují pouze obrázky až do těchto kalendářních dat.
V úloze Azure Machine Learning můžete tyto cesty připojit nebo stáhnout v tabulce MLTable s verzí do cílového výpočetního objektu pomocí těchto eval_download režimů nebo eval_mount režimů:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Poznámka:
Režimy eval_mount a eval_download režimy jsou jedinečné pro MLTable. V tomto případě funkce modulu runtime dat Azure Machine Learning vyhodnocuje MLTable soubor a připojí cesty k cílovému výpočetnímu objektu.